前期介绍了通过GRPO的方式解决多模态大模型OCR幻觉的思路《GRPO强化学习缓解多模态大模型OCR任务的幻觉思路及数据生成思路》。
由于多模态大模型的OCR感知能力不是特别强,容易像LLM一样产生幻觉-即生成输入图像中并不存在的词汇。LVLMs 设计用于通用目的,在OCR 任务上的表现往往不如在特定领域数据集上训练的专家模型。
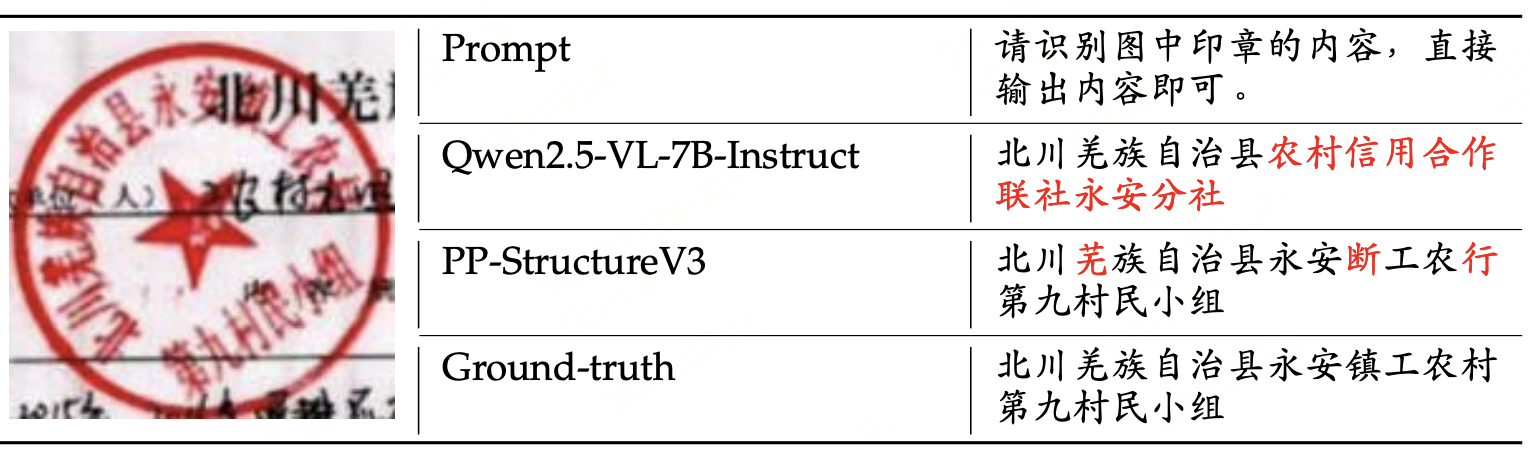
下面来看一个方案,首先通过利用自身的 OCR 能力识别输入图像中的内容,然后调用
其他工具(即其他专家模型)获取其结果作为参考,最后"再看一眼"图像并重新思考推理过程,以提供最终的识别结果,从而减轻 LVLMs 幻觉问题。
方法
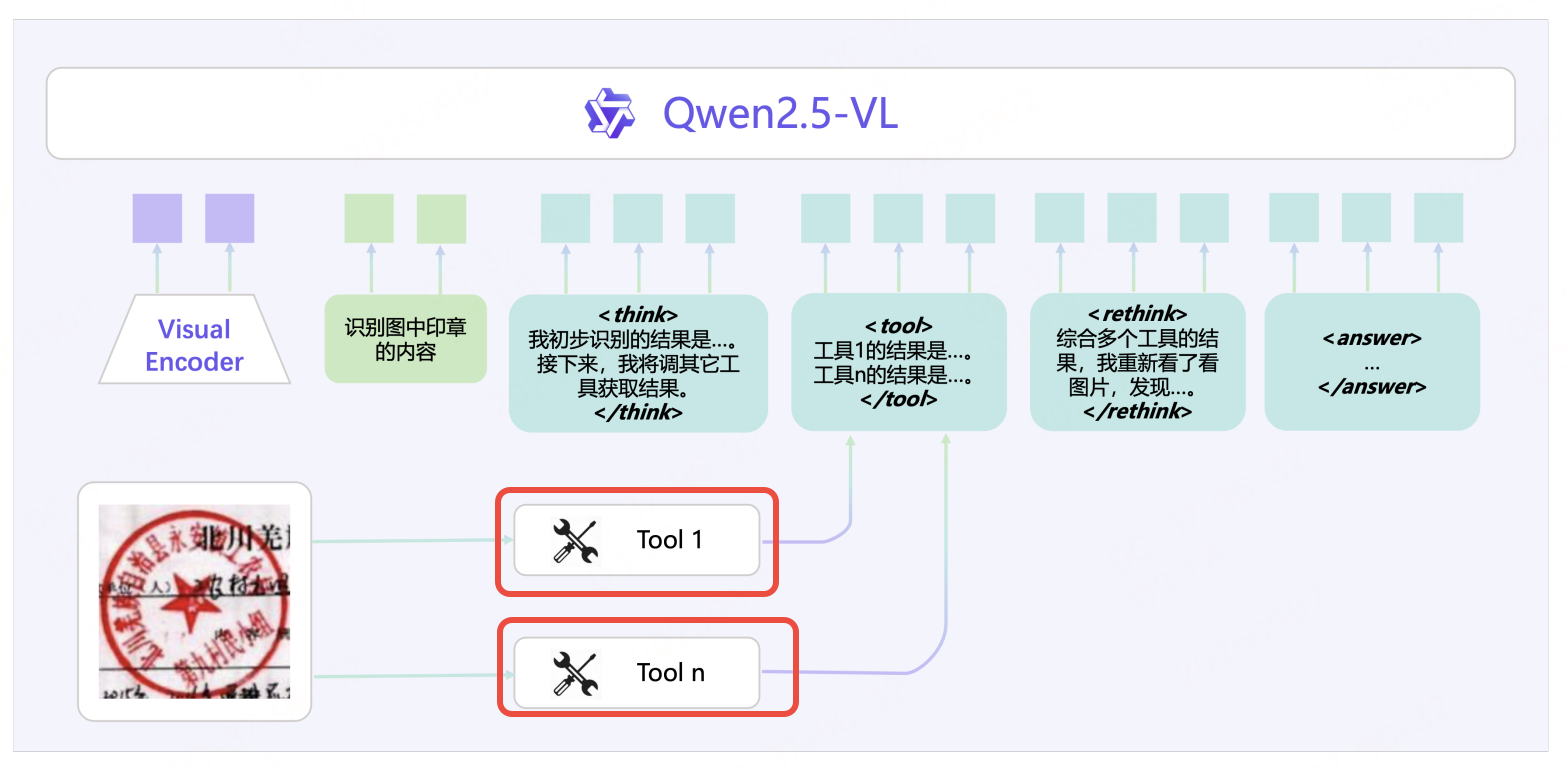
给定一张图像和一个文本问题,DianJin-OCR-R1 首先利用自身的 OCR 能力识别输入图像中的相关内容。随后,它调用其他专家模型或工具,并将其结果作为参考或补充信息。接着,模型"再次审视"图像,综合分析自身结果及其他模型的结果,反思在识别过程中是否出现错误或遗漏。最后,模型提供最终的识别内容。
数据构建
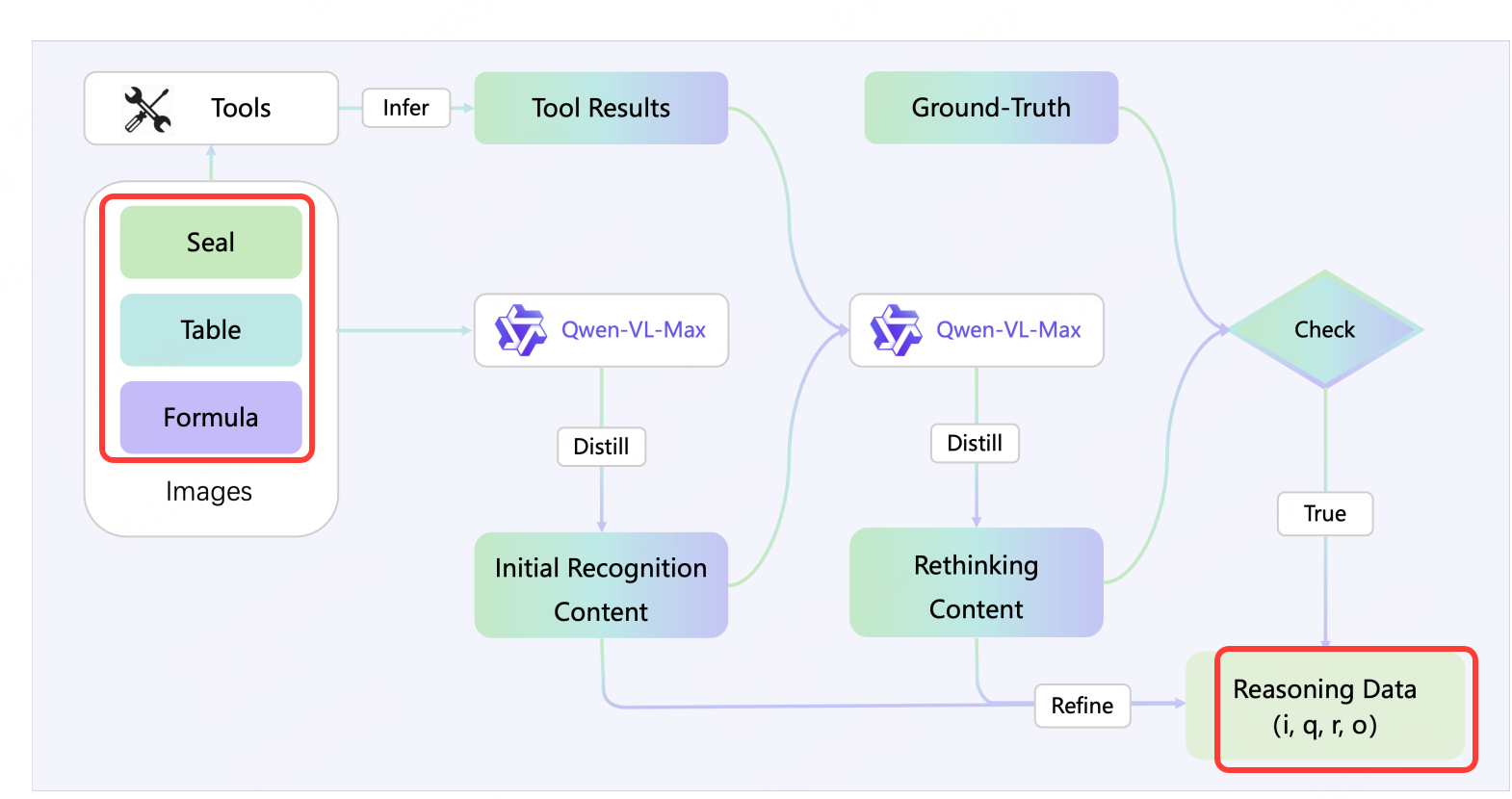
在印章、表格、公式三类OCR任务上生成推理数据,格式:
- 印章识别:文本
- 表格识别:HTML代码(需包含单元格合并标记
colspan/rowspan,确保结构与图像完全一致); - 公式识别:LaTeX代码。
三个任务的prompt:



数据构建的核心 是生成包含"推理过程"和"正确结果"的结构化样本 ,选用Qwen-VL-Max作为"推理链生成器"。
推理链( r i r_i ri)的结构:模型自身识别的内容用 < think>< /think> 标签包围,多个工具响应用 < tool>< /tool> 标签包围,反思内容用 < rethink>< /rethink> 标签包围。生成的输出用 < answer>< /answer> 标签包围。
数据集来源
-
印章识别
ReST数据集(ICDAR 2023印章标题识别竞赛数据集),含5000张训练图、5000张测试图(因测试集无标注,仅用训练集);
参考工具:PP-StructureV3(专家OCR模型,低幻觉)、Qwen-VL-OCR(专家VLM,适配印章文本识别)。
-
表格识别
表格需同时覆盖"语言多样性"(中/英文)和"结构复杂性"(合并单元格、多层表头);
-
内部数据集(补充未公开的复杂表格场景,如合并单元格、跨页表格);
-
TabRecSet(公开双语表格数据集,含38.1k表格,20.4k英文+17.7k中文);
-
参考工具 :PP-StructureV3(表格结构解析,如
colspan/rowspan识别)、MonkeyOCR-3B(LVLM,优化表格内容提取,适配双语场景)。
-
-
公式识别
数据集:UniMER-1M
参考工具:PP-StructureV3(PP-FormulaNet模块,优化公式结构解析)、MonkeyOCR-3B(擅长公式字符识别,减少符号错误)。
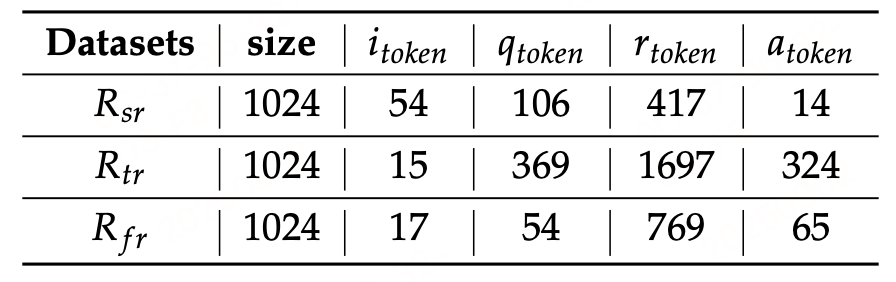
经过处理,构建了三类任务的推理数据集,统一表示为:
R s r / R t r / R f r = ( i i , q i , r i , o i ) R_{sr}/R_{tr}/R_{fr} = (i_i, q_i, r_i, o_i) Rsr/Rtr/Rfr=(ii,qi,ri,oi)
其中 R s r R_{sr} Rsr(印章推理数据集)、 R t r R_{tr} Rtr(表格推理数据集)、 R f r R_{fr} Rfr(公式推理数据集)的规模均为1024条样本(样本量均衡,避免某类任务过拟合);
模型训练及奖励概述
- Qwen2.5-VL-7B-Instruct 作为训练底座,
- SFT掌握推理流程
- RFT优化精度与格式:
- 格式奖励:推理链需严格包含< recognition>、< tool>、< rethink>、`` 标签,且无额外内容 → 奖励 1.0;否则 → 奖励 0.0
- 准确率奖励:(1)印章:完全匹配→1.0,否则 0.0;(2)表格:奖励 = TEDS(结构 + 内容相似度);(3)公式:奖励 = CDM(字符匹配度),CDM=1.0 时额外加 0.5(鼓励完美结果)。
实验效果
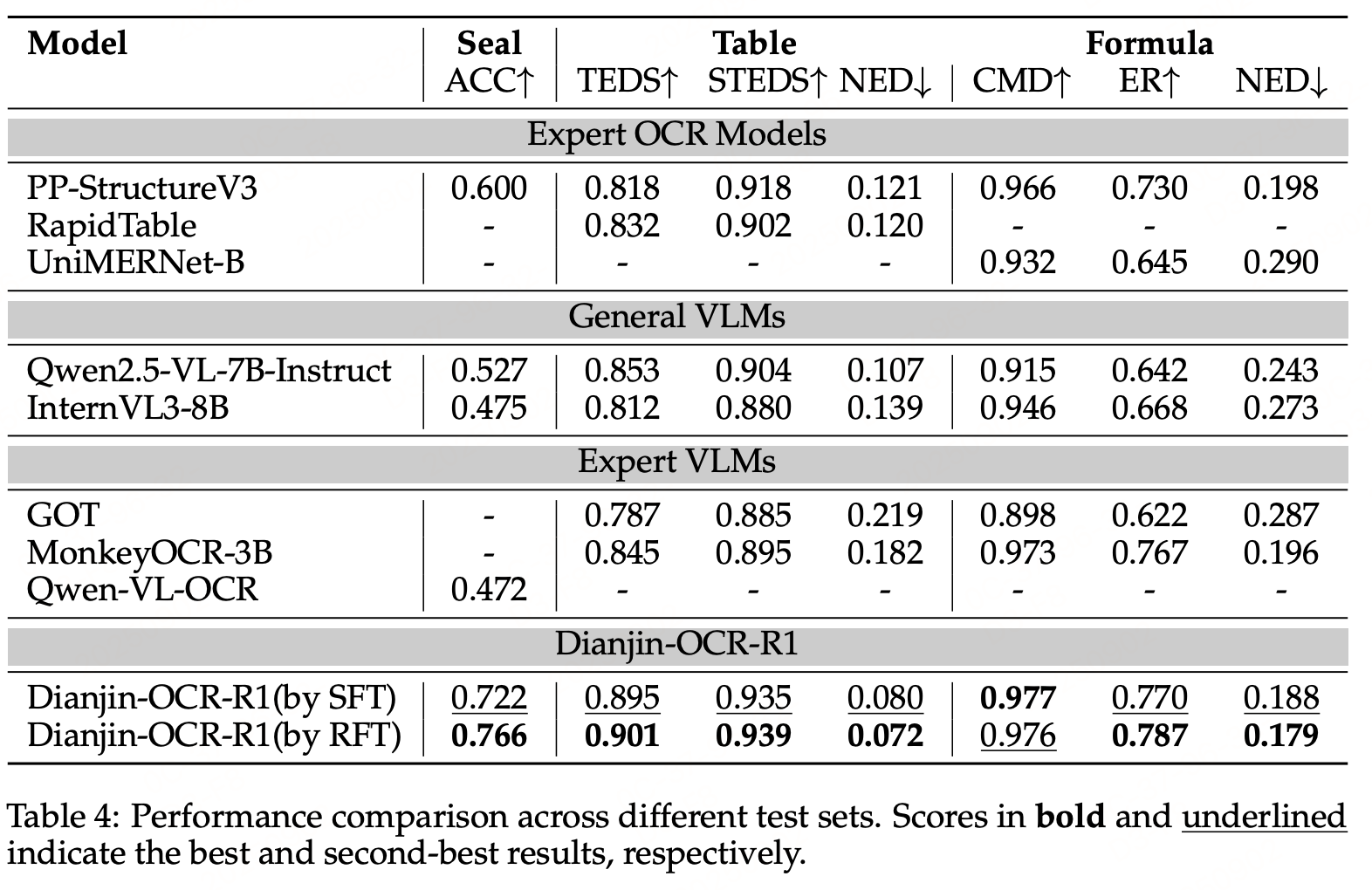
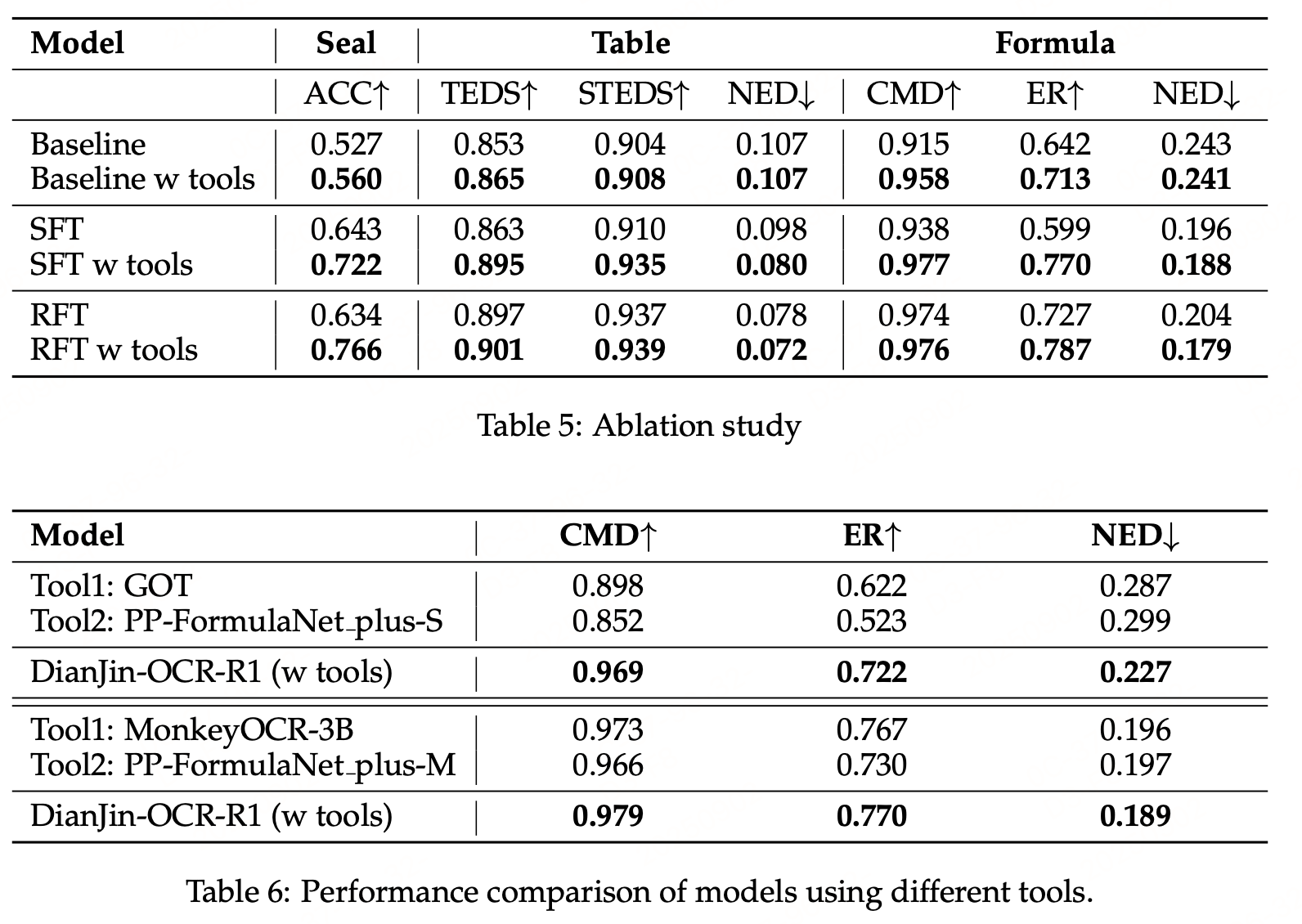
参考文献:DianJin-OCR-R1: Enhancing OCR Capabilities via a
Reasoning-and-Tool Interleaved Vision-Language Model,https://www.arxiv.org/pdf/2508.13238