> 💡 原创经验总结,禁止AI洗稿!转载需授权
> 声明:本文所有观点均基于多个领域的真实项目落地经验总结,数据说话,拒绝空谈!
目录
[1.1 "杀手锏":专为IoT而生的文件格式 TsFile](#1.1 “杀手锏”:专为IoT而生的文件格式 TsFile)
[1.2 持续进化:在存储压缩上"压榨"到极致](#1.2 持续进化:在存储压缩上“压榨”到极致)
[2.1 "稳定器":从容应对乱序写入与高压负载](#2.1 “稳定器”:从容应对乱序写入与高压负载)
[2.2 "杀手级应用":无缝的端、边、云一体化协同](#2.2 “杀手级应用”:无缝的端、边、云一体化协同)
[2.3 "建模直觉":天然同构的树状模型](#2.3 “建模直觉”:天然同构的树状模型)
[三、维度三:AI 与分析](#三、维度三:AI 与分析)
[3.1 "数据库原生":让异常检测和可视化不再"慢半拍"](#3.1 “数据库原生”:让异常检测和可视化不再“慢半拍”)
[3.2 "终极形态":当SQL可以直接调用AI模型](#3.2 “终极形态”:当SQL可以直接调用AI模型)
[4.1 无缝融入大数据生态](#4.1 无缝融入大数据生态)
[4.2 算一笔"经济账":TCO为何成为关键胜负手?](#4.2 算一笔“经济账”:TCO为何成为关键胜负手?)
引言:从ZB到YB时代,你的数据底座跟上时序洪流了吗?
**我们正处在数据爆炸时代,全球年数据量已从ZB(10²¹字节)迈向YB(10²⁴字节)级别。**这场数字洪流里,超80%新增数据是时序数据------来自无处不在的传感器、设备与系统,记录着物理与数字世界的脉搏。
智慧能源场站的百万测点并发写入、车联网PB级轨迹数据存储、高端制造产线的毫秒级振动数据分析,已是正在发生的现实。这也对作为数据底座的时序数据库(TSDB)提出关键拷问:
(1)面对百万级测点7x24小时数据轰炸,你的数据库是游刃有余还是濒临崩溃?
(2)业务需在数千亿数据点中聚合分析时,它能否毫秒响应,而非让用户看着"菊花"等待?
(3)数年历史数据归档,能否在不牺牲查询能力的前提下,把存储成本压到最低?
(4)面对网络抖动的"数据乱序"、设备激增的"高基数"难题,你的数据库是优雅化解还是手忙脚乱?
如果无法正面回答这四个问题的TSDB,在大数据与AI 浪潮下注定成为业务的瓶颈。今天,我们就从这四个维度出发,深入剖析主流开源选手是如何做的:Apache IoTDB------Apache基金会顶级项目,为海量工业物联网(IIoT)而生的原生分布式架构时序数据库。
一、维度一:架构基因
数据库的底层架构,是其能力的上限。一个为通用场景设计的数据库,无论如何优化,都难以在特定领域战胜一个"原生"选手。
1.1 "杀手锏":专为IoT而生的文件格式 TsFile
Apache IoTDB 从诞生之初,其基因就是为了解决工业时序数据的存储难题。它的核心武器,就是自研的、专为IoT设计的时序文件格式 `TsFile`。
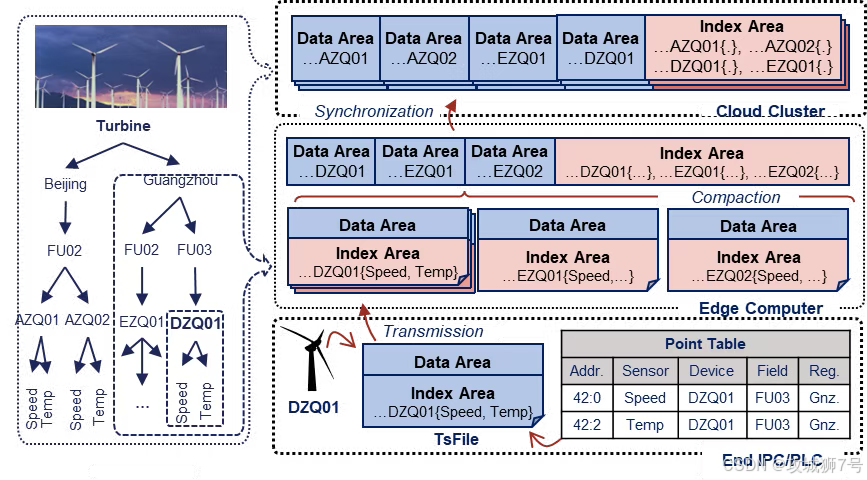
`TsFile` 并非对现有文件格式的修补,而是一种全新的设计哲学。它深刻洞察了物联网"一个设备、多个测点、时间有序"的核心特性,将数据按设备组织成高度聚集的数据块(Chunk)。这种原生设计,带来了两大"断层式"优势:
(1)极致的压缩比,直接冲击存储成本: `TsFile` 内部集成了Delta、GORILLA、RLE等多种针对不同数据类型(数值、文本、枚举)的最优压缩算法,并能自动选择。效果如何?在某新能源项目中,10TB的原始数据,经IoTDB压缩后仅占用800GB,直接节省了92%的存储成本!对于需要数据依法保留数年的行业,这每年可以节省数十万甚至上百万的硬件和云存储费用。
(2)为聚合而生的查询效率:`TsFile` 的索引结构(Chunk-level和Page-level)同样为时序查询"量身定制"。当执行一个时间范围的聚合查询(如`AVG()` `MAX()`)时,查询引擎可以利用元数据信息,精准地只读取相关的数据块,跳过海量无关数据,其效率远非通用文件格式所能比拟。
1.2 持续进化:在存储压缩上"压榨"到极致
IoTDB的存储优化并未止步于 `TsFile`。它进一步展示了其在存储层"压榨"每一个比特的决心。IoTDB 的 REGER 提出了一种创新的数据点重排序方法,通过打破严格的时间顺序,让数据在数值上变得更"平滑",从而让回归编码的效果更好,进一步降低残差的存储空间。这代表了IoTDB在核心技术上的持续探索和领先地位。
**结论:**在需要管理大规模、长周期、成本敏感的工业数据场景,以 `TsFile` 为基石的IoTDB原生架构,是根正苗红、效果最佳的选择。
二、维度二:引擎韧性与生命周期管理
工业现场的网络环境复杂多变,数据延迟、乱序到达是常态。一个脆弱的数据库引擎,在这种环境下很快就会因为频繁的数据整理而性能崩溃。
2.1 "稳定器":从容应对乱序写入与高压负载
IoTDB采用的LSM-tree 架构,天然适合高频写入。但更关键的是,它针对工业场景的"顽疾"做了深度优化。
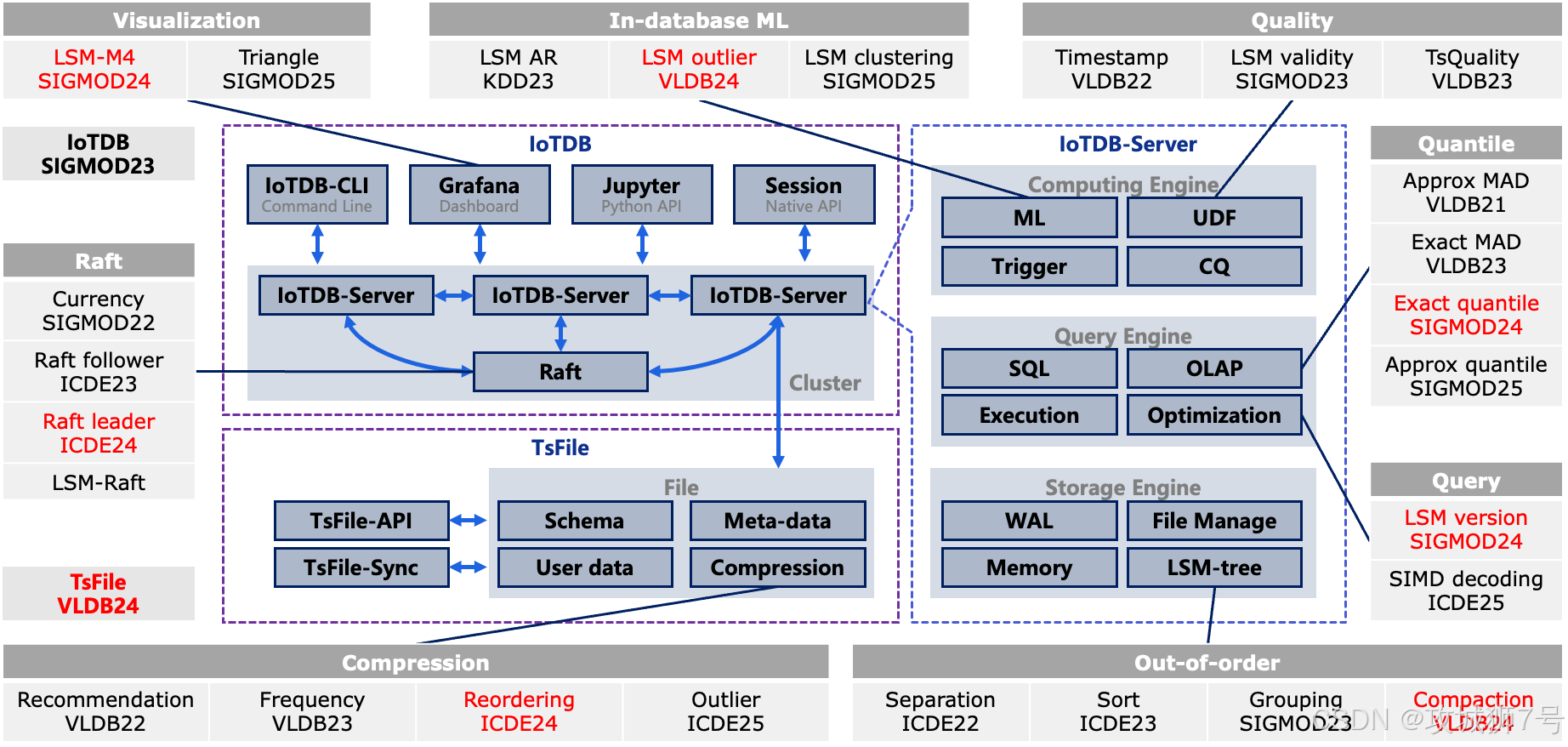
**(1)优雅处理乱序:**通过成熟的顺乱序数据分离处理机制,IoTDB可以高效地将乱序数据写入独立的存储结构中,并在后台异步、优雅地进行合并,对前台写入性能影响极小。
**(2)攻克空间放大难题:**LSM-tree在多列频繁更新下,容易产生空间放大(Space Amplification)问题,导致磁盘空间浪费。IoTDB提出的多列合并(MCC)策略,正是为了解决这一核心痛点,确保数据库在高压下依然能保持"瘦身"和高效。
**(3)金融级分布式高可用:**在分布式集群中,数据一致性至关重要。关于 `Raft 共识协议在物联网中的优化` 的研究,展示了IoTDB如何通过对分布式协议的深度调优,在高吞吐的物联网场景下保证集群的稳定性和性能,提供金融级别的数据可靠性。
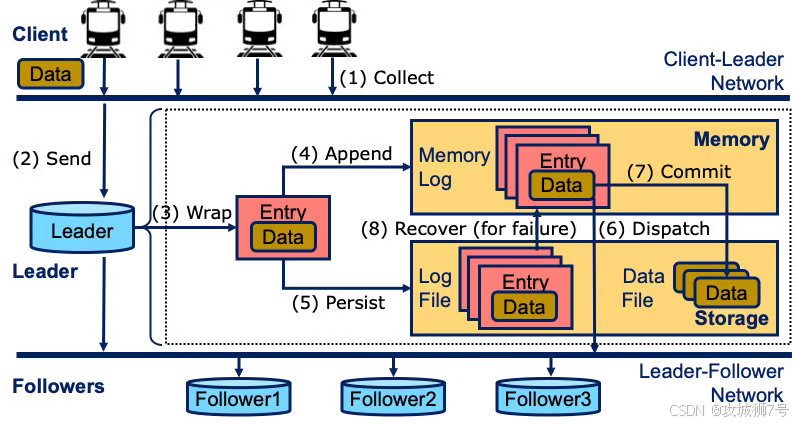
2.2 "杀手级应用":无缝的端、边、云一体化协同
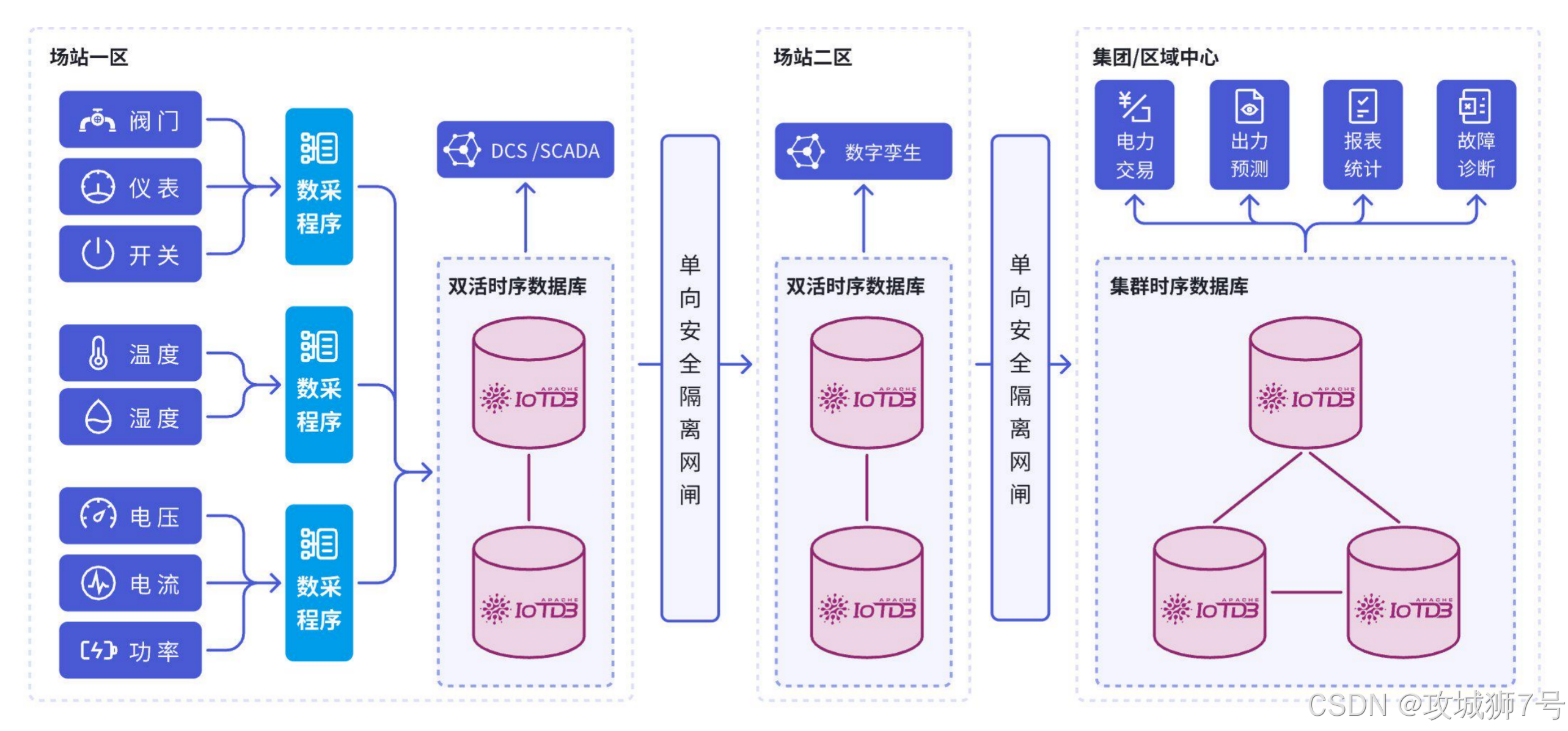
这是IoTDB在物联网领域的绝对主场,也是其区别于其他TSDB的"杀手级应用"。它原生提供轻量级的边缘端版本(IoTDB-Edge),可以在几十MB内存的边缘网关、工控机甚至PLC上运行,实现数据的本地缓存、预聚合和简单分析。更重要的是,通过内置的同步工具,可以将边缘端压缩好的 `TsFile` 文件,高效、断点续传地同步到云端中心节点。这套为弱网络、高延迟工业环境设计的体系,能极大降低宝贵的网络带宽成本和云端写入压力。
2.3 "建模直觉":天然同构的树状模型
IoTDB采用的树状数据模型 (`root.group.device.sensor`) 与工业设备的物理层级结构天然同构。你可以像管理电脑文件目录一样管理数百万的设备测点,例如 `root.发电集团.华北分公司.风电场A.风机01.温度`。这种模型让数据组织非常直观,基于路径的查询(如 `select * from root.发电集团.华北分公司.**`)也极为便利和高效。
三、维度三:AI 与分析
在AI时代,时序数据库不再仅仅是一个被动存储数据的"仓库",它必须进化为连接数据与智能的"智能中枢"。
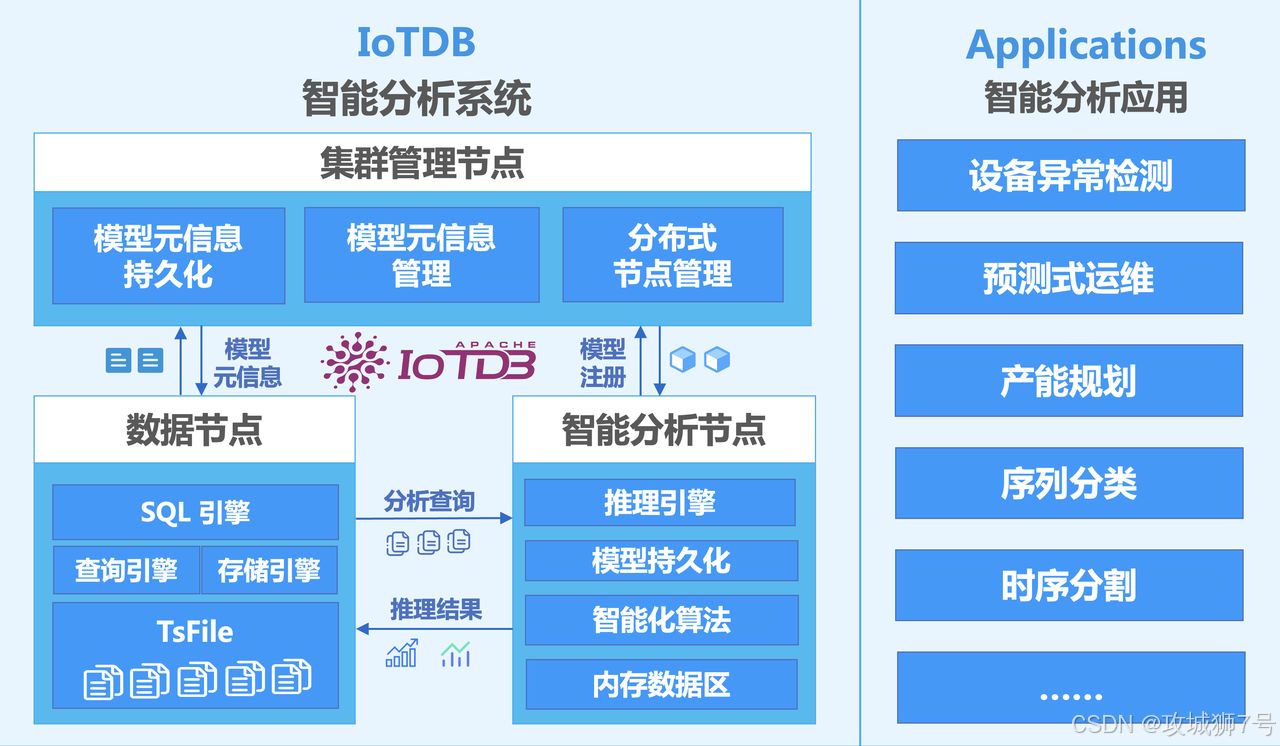
3.1 "数据库原生":让异常检测和可视化不再"慢半拍"
传统的时序数据分析,往往需要将数据从数据库导出到外部计算平台(如Python环境),流程繁琐且延迟高,无法满足实时决策的需求。IoTDB正在引领一场"库内分析"的革命。
**(1)原生异常检测:**研发人员提出的 `LSMOD` 方法,让IoTDB具备了数据库原生的时序数据异常检测能力。它能直接在数据库内核中,高效地处理包括延迟到达数据在内的复杂情况,让异常发现更及时、更准确。
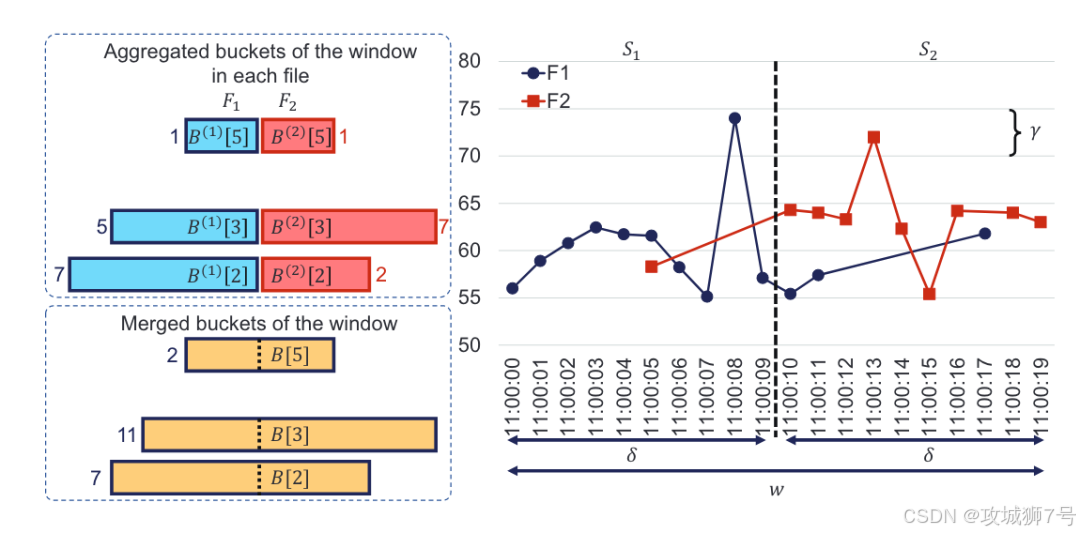
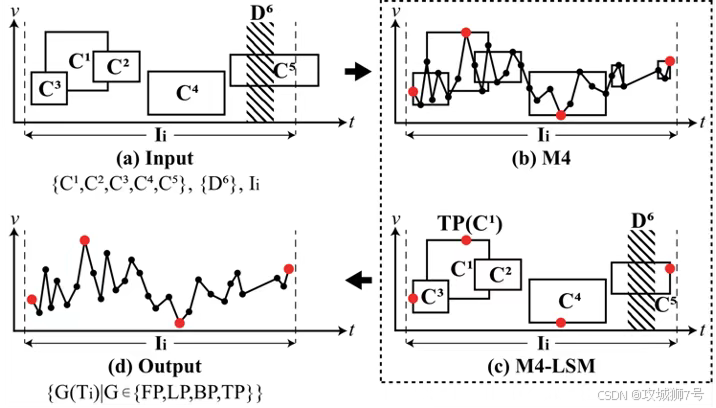
**(2)为可视化而生:**海量时序数据的可视化,往往会因为查询和渲染大量数据点而变得卡顿。IoTDB提出的 `M4-LSM` 技术,则通过结合M4无损采样算法和LSM-Tree的元数据,实现了在不损失可视化精度的情况下,查询性能和前端渲染流畅度的大幅提升。
3.2 "终极形态":当SQL可以直接调用AI模型
这是IoTDB最具前瞻性的功能之一。通过内置的AINode,你可以将训练好的时序预测、分类等AI模型部署进数据库,然后,数据科学家或应用开发者就可以直接用简单的SQL来调用内置模型进行推理!比如如下语法:
sql
call inference(<model_id>,inputSql,(<parameterName>=<parameterValue>)*)
window_function:
head(window_size)
tail(window_size)
count(window_size,sliding_step)内置模型推理无需注册,只需通过 `call` 关键字调用 `inference` 函数,即可直接使用推理功能,对应的参数说明如下:
-
`model_id`:所需调用的模型名称
-
`parameterName`:推理时需传入的参数名称
-
`parameterValue`:对应参数的具体取值
另外我们还能微调内置模型,比如选择测点 root.db.etth.ot 中前 80% 的数据作为微调数据集,基于 sundial 创建模型 sundialv2。
sql
IoTDB> CREATE MODEL sundialv2 FROM MODEL sundial ON DATASET (PATH root.db.etth.OT([1467302400000, 1517468400001)))
Msg: The statement is executed successfully.
IoTDB> show models
+---------------------+--------------------+----------+--------+
| ModelId| ModelType| Category| State|
+---------------------+--------------------+----------+--------+
| arima| Arima| BUILT-IN| ACTIVE|
| holtwinters| HoltWinters| BUILT-IN| ACTIVE|
|exponential_smoothing|ExponentialSmoothing| BUILT-IN| ACTIVE|
| naive_forecaster| NaiveForecaster| BUILT-IN| ACTIVE|
| stl_forecaster| StlForecaster| BUILT-IN| ACTIVE|
| gaussian_hmm| GaussianHmm| BUILT-IN| ACTIVE|
| gmm_hmm| GmmHmm| BUILT-IN| ACTIVE|
| stray| Stray| BUILT-IN| ACTIVE|
| sundial| Timer-Sundial| BUILT-IN| ACTIVE|
| timer_xl| Timer-XL| BUILT-IN| ACTIVE|
| sundialv2| Timer-Sundial|FINE-TUNED|TRAINING|
+---------------------+--------------------+----------+--------+微调任务后台异步启动,可在 AINode 进程看到 log;微调完成后,查询并使用新的AI模型
sql
IoTDB> show models
+---------------------+--------------------+----------+------+
| ModelId| ModelType| Category| State|
+---------------------+--------------------+----------+------+
| arima| Arima| BUILT-IN|ACTIVE|
| holtwinters| HoltWinters| BUILT-IN|ACTIVE|
|exponential_smoothing|ExponentialSmoothing| BUILT-IN|ACTIVE|
| naive_forecaster| NaiveForecaster| BUILT-IN|ACTIVE|
| stl_forecaster| StlForecaster| BUILT-IN|ACTIVE|
| gaussian_hmm| GaussianHmm| BUILT-IN|ACTIVE|
| gmm_hmm| GmmHmm| BUILT-IN|ACTIVE|
| stray| Stray| BUILT-IN|ACTIVE|
| sundial| Timer-Sundial| BUILT-IN|ACTIVE|
| timer_xl| Timer-XL| BUILT-IN|ACTIVE|
| sundialv2| Timer-Sundial|FINE-TUNED|ACTIVE|
+---------------------+--------------------+----------+------+其他更多用法可以查询官网文档。
这种"库内AI"的设计,彻底打通了数据存储和AI应用的"最后一公里",极大地简化了AI应用的开发、部署和维护链路,让AI从一个外部工具,真正变成了数据库的原生赋能。
四、维度四:生态与总体拥有成本(TCO)
一个数据库的生命力,不仅在于其性能,更在于其生态的开放性和长期的综合成本。
4.1 无缝融入大数据生态
作为Apache基金会顶级项目,IoTDB拥有强大的生态整合能力。它与Spark、Flink、Hadoop、Grafana等大数据和可视化生态无缝集成,提供了官方原生Connector,方便你构建从"边缘采集-数据存储-批流计算-上层应用"的一体化数据平台。
4.2 算一笔"经济账":TCO为何成为关键胜负手?
总体拥有成本(TCO)是比性能跑分更现实的考量。IoTDB的优势体现在多个方面:
**(1)存储成本:**凭借极致的压缩比,长期存储成本可降低5-10倍。
**(2)带宽成本:**端云协同架构能大幅减少边缘到云端的数据传输量,尤其在按流量计费的蜂窝网络场景,效益显著。
**(3)开发运维成本:**类SQL的查询语言学习成本低;统一的端、边、云架构降低了运维复杂性;库内AI能力则减少了对外部AI平台和复杂应用开发的依赖。
结论:2025年,如何为你的场景选择那把"钥匙"?
时序数据库的选型没有"银弹",但理解其背后的设计哲学至关重要。
如果你的战场在工业互联网、车联网、智慧能源、高端制造 等领域,面临着海量设备、长期存储、边云协同和高昂成本 的终极挑战。那么,IoTDB在架构、成本、生态和AI集成上的体系化优势,是专门为这些场景而设计的,Apache IoTDB无疑是你的选择。
> 👉 下载 Apache IoTDB 开源版体验:`https://iotdb.apache.org/zh/Download/\`
> 👉 获取企业级支持与更强功能:`https://timecho.com`
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!