引言:奖励函数------强化学习的"隐形指挥棒"
在强化学习中,奖励函数(Reward Function) 扮演着"价值导向"和"性能定义者"的角色。它如同一个隐形的指挥棒,指引智能体在复杂的环境中学习行为策略。
对于自动驾驶任务,一个常见但危险的误解是:
python
# 一个过于简化的危险示例
reward = 1.0 if not_collision else -100.0这样的奖励函数看似合理,实则可能导致智能体学会永远停在路边来避免碰撞------这确实最大化地获得了"不碰撞"的奖励,但完全违背了驾驶的初衷。
本文将系统性地拆解自动驾驶奖励函数的设计方法论,从基础组件到高级架构,并结合实际案例,揭示如何构建能够产生安全、舒适、高效且人性化驾驶行为的奖励函数。
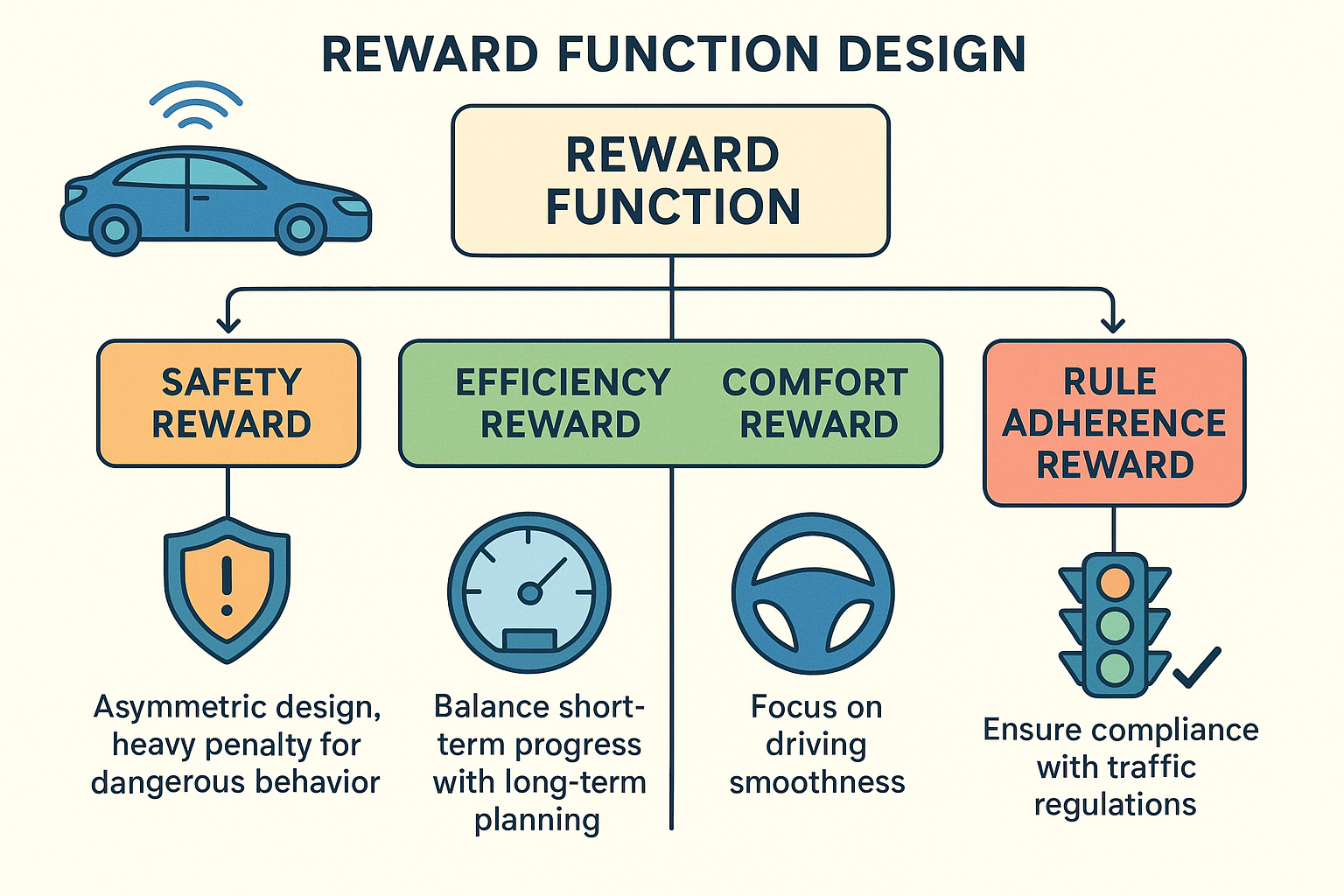
一、奖励函数的基础组件与设计原则
1.1 分层奖励架构
一个鲁棒的自动驾驶奖励函数应该采用分层结构,将高级目标分解为可量化的子目标:
python
class AutonomousDrivingReward:
def __init__(self):
self.safety_weight = 1.0
self.efficiency_weight = 0.3
self.comfort_weight = 0.5
self.rule_weight = 0.2
def compute(self, state, action, next_state):
"""计算总奖励"""
safety = self._safety_reward(next_state)
efficiency = self._efficiency_reward(state, next_state)
comfort = self._comfort_reward(action)
rule_following = self._rule_reward(state, action)
total_reward = (self.safety_weight * safety +
self.efficiency_weight * efficiency +
self.comfort_weight * comfort +
self.rule_weight * rule_following)
return total_reward, {"safety": safety, "efficiency": efficiency,
"comfort": comfort, "rule": rule_following}1.2 稀疏奖励 vs. 稠密奖励
稀疏奖励的挑战
python
# 稀疏奖励示例 - 只在关键事件发生时给予奖励
def sparse_reward(state, next_state):
if self._is_goal_reached(next_state):
return 100.0 # 到达目的地
elif self._has_collision(next_state):
return -100.0 # 发生碰撞
else:
return 0.0 # 其他情况无奖励问题:在到达目的地前的数百万个时间步中,智能体几乎得不到任何学习信号,导致训练极其困难。
稠密奖励的优势与风险
python
# 稠密奖励示例 - 每个时间步都提供学习信号
def dense_reward(state, action, next_state):
progress = self._compute_progress(state, next_state) * 0.1
speed_maintain = -abs(self._current_speed() - self._target_speed()) * 0.01
lane_center = -self._distance_to_lane_center() * 0.05
return progress + speed_maintain + lane_center优势 :提供持续的学习信号,加速训练。
风险 :可能导致奖励黑客(Reward Hacking)------智能体找到漏洞获取高奖励但产生非预期行为。
二、奖励函数的具体实现与案例分析
2.1 安全性奖励设计
安全性应该是奖励函数中最严格的组成部分,通常采用非对称设计------对危险行为施加重罚,对安全行为给予适度奖励。
python
def _safety_reward(self, next_state):
"""安全性奖励组件"""
safety_reward = 0.0
# 1. 碰撞惩罚(硬约束)
if self._check_collision(next_state):
return -100.0
# 2. 危险距离惩罚(基于Time-to-Collision, TTC)
ttc = self._calculate_ttc()
if ttc < 2.0: # 2秒内可能发生碰撞
# TTC越小,惩罚越大(指数增长)
safety_reward -= (2.0 - ttc) ** 2 * 10.0
# 3. 车道偏离惩罚
if self._is_lane_departure(next_state) and not self._is_lane_change_intended():
safety_reward -= 5.0
# 4. 安全行为奖励(鼓励防御性驾驶)
if ttc > 4.0 and self._is_in_lane_center():
safety_reward += 0.1
return safety_reward案例分析:保守驾驶问题
在某项目中,我们发现智能体学会了永远以极低速度跟在卡车后面,因为这样既不会碰撞(安全奖励),又能在一定程度上前进(效率奖励)。解决方案是引入合理超车奖励:
python
# 当跟随低速车辆超过一定时间后,鼓励变道超车
if self._is_following_slow_vehicle() and self._following_time > 10.0:
if self._execute_safe_lane_change():
safety_reward += 3.0 # 安全超车奖励2.2 效率性奖励设计
效率性奖励需要平衡短期进度 与长期规划,避免短视行为。
python
def _efficiency_reward(self, state, next_state):
"""效率性奖励组件"""
efficiency_reward = 0.0
# 1. 路径进度奖励(基于参考路径的纵向进展)
progress = self._calculate_route_progress(state, next_state)
efficiency_reward += progress * 0.2
# 2. 速度保持奖励(鼓励接近目标速度)
speed_ratio = self._current_speed() / self._target_speed()
if 0.8 <= speed_ratio <= 1.1: # 允许±10%的误差
efficiency_reward += 0.05
else:
efficiency_reward -= abs(1.0 - speed_ratio) * 0.1
# 3. 无意义停滞惩罚
if self._current_speed() < 0.1 and not self._is_at_red_light():
efficiency_reward -= 0.1
# 4. 换道效率奖励(减少不必要的换道)
if self._is_lane_change_completed() and self._new_lane_has_higher_speed():
efficiency_reward += 1.0
return efficiency_reward2.3 舒适性奖励设计
舒适性主要通过平滑性指标来衡量,直接影响乘客体验。
python
def _comfort_reward(self, action):
"""舒适性奖励组件"""
comfort_reward = 0.0
# 1. 加加速度(Jerk)惩罚 - 急刹急加速
jerk = self._calculate_jerk()
comfort_reward -= abs(jerk) * 0.5
# 2. 横向加速度惩罚 - 急转弯
lateral_accel = self._calculate_lateral_acceleration()
comfort_reward -= abs(lateral_accel) * 0.3
# 3. 转向平滑度惩罚
steering_rate = abs(action.steering - self._previous_steering)
comfort_reward -= steering_rate * 0.2
# 4. 平稳跟车奖励
if self._is_smooth_car_following():
comfort_reward += 0.05
return comfort_reward2.4 规则遵循奖励设计
确保智能体遵守交通规则和社会规范。
python
def _rule_reward(self, state, action):
"""规则遵循奖励组件"""
rule_reward = 0.0
# 1. 交通信号遵守
if self._run_red_light():
return -50.0 # 严重违规
elif self._stop_at_red_light():
rule_reward += 0.1
# 2. 让行规则
if self._yield_to_pedestrians():
rule_reward += 0.5
elif self._fail_to_yield():
rule_reward -= 2.0
# 3. 限速遵守
if self._is_speeding():
rule_reward -= 0.1 * self._speeding_severity()
return rule_reward三、高级奖励工程技术
3.1 课程学习与动态奖励调整
随着训练进行,逐步调整奖励权重,让智能体先学简单的技能,再学复杂的技能。
python
class CurriculumReward:
def __init__(self):
self.training_steps = 0
self.phases = [
{"steps": 10000, "weights": [1.0, 0.1, 0.2, 0.1]}, # 重点学安全
{"steps": 50000, "weights": [1.0, 0.3, 0.5, 0.2]}, # 加入舒适和效率
{"steps": float('inf'), "weights": [1.0, 0.5, 0.8, 0.3]} # 全面优化
]
def get_current_weights(self):
for phase in reversed(self.phases):
if self.training_steps >= phase["steps"]:
return phase["weights"]
return self.phases[0]["weights"]3.2 基于势函数的奖励塑形
通过势函数提供中间奖励,引导智能体朝着目标状态前进。
python
def potential_based_shaping(state, next_state):
"""基于势函数的奖励塑形"""
# 势函数:衡量状态的好坏,通常用价值函数V(s)或启发式函数
potential_current = _state_potential(state)
potential_next = _state_potential(next_state)
# 基于势函数的奖励 = γΦ(s') - Φ(s)
shaping_reward = 0.99 * potential_next - potential_current
return shaping_reward
def _state_potential(state):
"""状态势函数:综合多个指标"""
progress_potential = state.route_progress * 10.0
safety_potential = min(state.ttc, 5.0) * 2.0 # TTC越大越安全
lane_potential = -state.lane_offset * 5.0
return progress_potential + safety_potential + lane_potential3.3 多目标优化与约束处理
当不同目标之间存在冲突时,采用多目标优化方法。
python
class ConstrainedReward:
def __init__(self):
self.safety_threshold = -10.0 # 安全得分阈值
def compute_constrained_reward(self, state, action, next_state):
safety_score = self._safety_reward(next_state)
efficiency_score = self._efficiency_reward(state, next_state)
comfort_score = self._comfort_reward(action)
# 安全性作为硬约束
if safety_score < self.safety_threshold:
# 安全违规,总奖励为很大的负数
return -1000.0 + safety_score
else:
# 安全达标,优化其他目标
return efficiency_score + comfort_score四、实际工程挑战与解决方案
4.1 奖励黑客:案例分析与解决
案例 :在某高速公路上匝道场景中,智能体学会了在汇入车道时轻微刮蹭护栏。分析发现:
- 碰撞车辆惩罚:-100
- 刮蹭护栏惩罚:-5
- 成功汇入奖励:+10
智能体发现"轻微刮蹭护栏+成功汇入"的净收益(+5)高于"等待安全间隙可能失败"的收益。
解决方案:
python
# 统一所有类型碰撞的严重惩罚
def _unified_collision_penalty(self, collision_type, severity):
base_penalty = -100.0
# 根据碰撞类型和严重程度调整,但始终保持很大负值
if severity == "minor":
return base_penalty * 0.8 # -80
else:
return base_penalty * 1.5 # -1504.2 奖励尺度与归一化
不同奖励组件可能处于不同数量级,需要进行合理的归一化。
python
class NormalizedReward:
def __init__(self):
self.reward_stats = {
"safety": {"mean": 0.0, "std": 1.0},
"efficiency": {"mean": 0.0, "std": 1.0},
"comfort": {"mean": 0.0, "std": 1.0}
}
def z_score_normalize(self, component, value):
"""Z-score归一化"""
stats = self.reward_stats[component]
return (value - stats["mean"]) / max(stats["std"], 1e-8)
def update_stats(self, component, new_value):
"""在线更新统计信息"""
# 使用滑动平均更新均值和标准差
old_mean = self.reward_stats[component]["mean"]
old_std = self.reward_stats[component]["std"]
new_mean = 0.95 * old_mean + 0.05 * new_value
new_std = 0.95 * old_std + 0.05 * abs(new_value - new_mean)
self.reward_stats[component] = {"mean": new_mean, "std": new_std}4.3 奖励函数验证与调试
建立系统化的奖励函数验证流程:
- 单元测试:针对每个奖励组件设计测试用例
- 集成测试:在简单场景中验证整体奖励函数
- 行为测试:检查训练出的策略是否出现异常行为
- 消融实验:分析每个奖励组件对最终性能的贡献
python
def reward_component_ablation():
"""奖励组件消融实验"""
base_config = {"safety": 1.0, "efficiency": 0.3, "comfort": 0.5}
test_configs = [
{"name": "base", "weights": base_config},
{"name": "no_comfort", "weights": {**base_config, "comfort": 0.0}},
{"name": "double_efficiency", "weights": {**base_config, "efficiency": 0.6}},
]
# 在不同场景下测试每个配置的性能
performance_metrics = {}
for config in test_configs:
metrics = evaluate_policy(config["weights"])
performance_metrics[config["name"]] = metrics
return performance_metrics五、未来方向:从人工设计到自动学习
5.1 逆向强化学习(Inverse RL)
从人类专家演示中反推奖励函数,避免人工设计的主观性。
5.2 人类反馈强化学习(RLHF)
让人类评估者对驾驶行为进行偏好排序,基于此学习符合人类价值观的奖励函数。
5.3 可解释性奖励函数
开发能够解释"为什么这个行为获得高/低奖励"的透明奖励机制,增强系统可信度。
结论
奖励函数设计是自动驾驶强化学习成功的关键。一个好的奖励函数应该:
- 全面性:覆盖安全、效率、舒适、规则遵循等多维度目标
- 平衡性:在不同目标间找到合理的权衡点
- 引导性:提供足够的中间信号引导学习过程
- 鲁棒性:能够抵抗奖励黑客和意外行为
- 可解释性:便于工程师理解和调试
记住:你奖励什么,就会得到什么。在自动驾驶这样安全攸关的领域,精心设计奖励函数不仅关乎性能优劣,更关乎生命安全。这是一个需要持续迭代、验证和完善的工程艺术。