舍入误差只是影响模型输出的很小的一部分,更常见的大部分变化来自于概率、随机性和上下文的相互作用。
在生成回复的最后阶段,模型不会选择一个"预先确定"的词,而是会计算词汇表的概率分布:
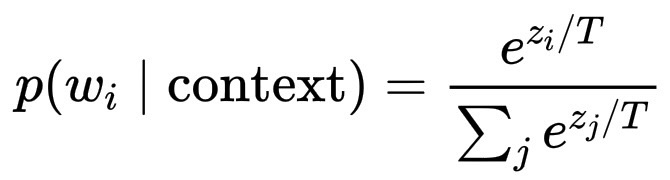
p(w_i \mid \text{context}) = \frac{e^{z_i / T}}{\sum_j e^{z_j / T}}
其中 z_i 是模型的 logits(分数),T 是温度参数。然后模型会从这个分布中抽样,换句话说,模型会掷一个加权骰子。
-
当 T = 1 时:你得到了正常的softmax分布。
-
当 T < 1 时:除以较小的数会使指数更陡峭,模型变得更有信心,几乎是确定性的。
-
当 T > 1 时:除以较大的数会使分布更平坦,随机性更强,后续单词的多样性也更强。
因此,如果两个词的概率接近,比如:p("美丽的") = 0.32,p("可爱的") = 0.30。那么它们都可能被选中,句子的表达方式也会略有不同。即使整体含义保持不变,每次穿过语言空间的路径也可能不同。
然而,每个新词的产生都会改变输入语境!一旦选择了不同的词,所有后续的概率都会随之变化。这是一种混沌敏感性:微小的初始差异会导致后续语境的巨大变化,就像概率空间中的蝴蝶效应一样。
这就是为什么对同一个问题进行两次运行,听起来可能都像是同一个模型在说话,但永远不会完全相同。
采样温度 T 具有受控随机性。如果将温度 T 设为 0,模型会停止采样,并始终选择最有可能的下一个词。这就是确定性模式,每次都会得到相同的措辞。更高的 T 值会增加多样性和创造性,但可预测性会降低。
因此,这种明显的不一致性并非 bug,它实际上是设计的一部分,旨在平衡稳定性和自发性。
一些次要技术原因也影响输出结果,包括:GPU/TPU 硬件上的浮点不确定性可能会导致矩阵运算出现微小的变化;并行性,不同的线程或计算分片以略微不同的顺序完成;训练中的自适应优化可能会导致权重更新出现细微的差异,等等。所有这些微观效应都会累积成模型输出的结果差异。