目标检测算法硬件加速器是系统的核心计算模块,对于实现高效推理和满足实时
处理需求具有关键作用。为实现算法的高效部署,本章采用高层次综合技术,将目标检
测算法映射至硬件平台,并结合定点量化、算子融合、循环展开等优化策略,以提升加
速器的性能和算法效率。在此基础上,设计并实现了包括卷积、池化等关键算子的
YOLOv4-tiny 硬件加速推理模块。
4.1 硬件加速工具介绍
4.1.1 高层次综合技术原理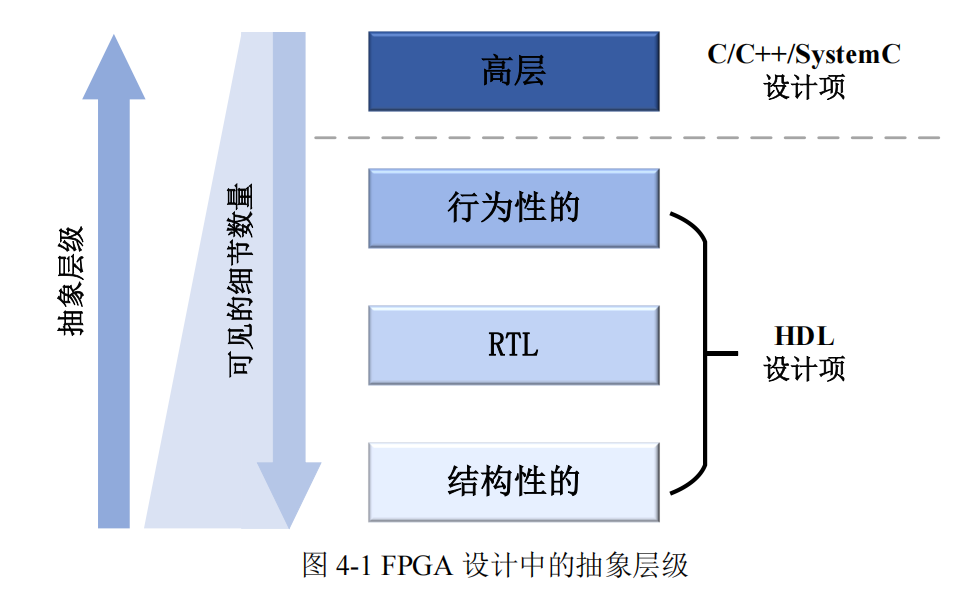
FPGA 设计领域的抽象层次从低到高可分为四级:结构性、RTL、行为性及高层设
计,如图 4-1 所示。最底层的结构性抽象直接操作基础硬件单元,包括逻辑门、LUT 和
触发器等底层元素。实际 FPGA 开发中,设计师多采用 RTL(寄存器传输级)抽象进
行设计。RTL 有效隐藏了底层硬件细节,专注于描述寄存器间的数据传输和逻辑关系。
而行为性抽象则更进一步,侧重算法层面描述,关注电路功能特性而非寄存器操作细
节。这些层级均使用 HDL 作为设计语言,随着抽象层次提高,硬件实现细节逐渐模糊
化。
本章将采用高层设计的方法,直接使用 C/C++等高级语言对硬件加速器进行设计,
再通过 Vivado HLS 工具将代码转换为 HDL 描述69。在实际项目开发中,相较于传统
FPGA 开发,HLS 技术具有显著优势:它可以让设计者专注于算法本身而非硬件细节;
高级语言到硬件的自动转换大幅缩短开发周期;模块化设计支持创建可复用 IP 核,简
化了设计流程并提高了代码可维护性。对嵌入式系统而言,HLS 内置优化功能能自动
调整代码以提升性能;C 级别验证和 C-RTL 协同仿真简化了验证过程;同时降低了设
计成本和风险。
4.1.2 基于 Vivado HLS 的设计流程
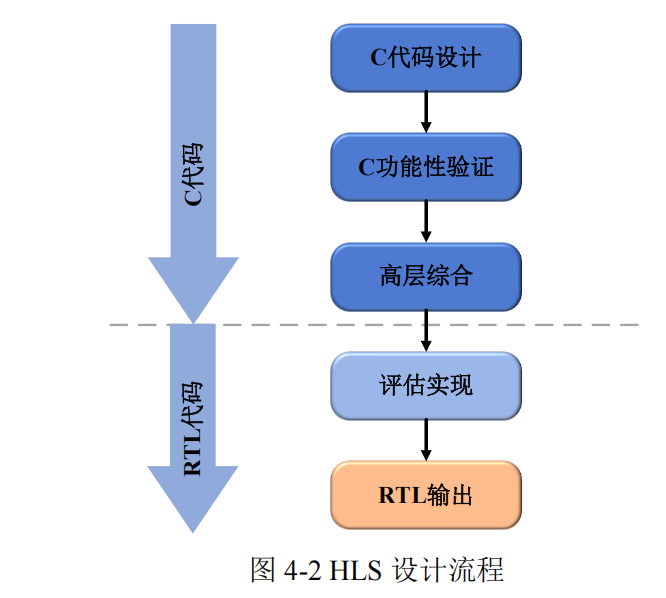
HLS(高层综合)流程如图 4-2 所示,主要输入为 C/C++设计代码。在进行综合前,
首先执行 C 仿真以验证输入代码的功能正确性。随后进入核心环节------高层综合过程,
该过程分析 C 代码并结合用户指令与约束条件,生成 RTL 描述。最后,系统输出 Verilog
或 VHDL 格式的 RTL 设计文件。
除功能验证外,评估 RTL 设计的实现效果和性能指标同样重要,如 FPGA 资源占
用、延迟特性及最高时钟频率等是否符合预期。如果未达要求,设计师需要多次进行调
整指令和约束参数,并重新进行综合优化,寻找"最优"的方案。
4.2 硬件加速器实现架构分析
YOLOv4-tiny 算法是目标检测的关键环节。为了实现高效、实时的检测任务,选
择合适的卷积神经网络加速器架构至关重要。在卷积神经网络加速器的设计过程中,
数据传输和计算的组织方式对性能有着显著影响。常见的两种实现架构为 Stream
Pattern 和 Overlap Pattern70。
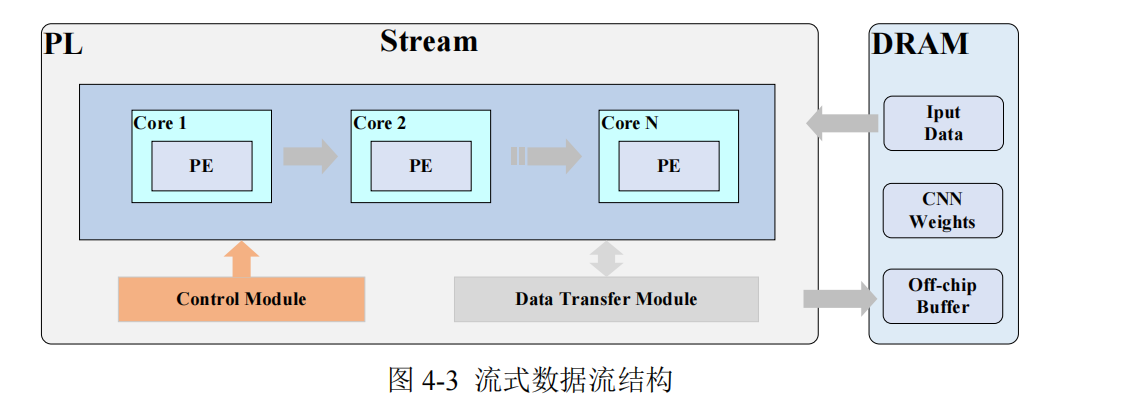
Stream Pattern 即流式数据流,其结构如图 4-3 所示,是一种顺序执行的方式。在
这种模式下,数据从内存中读取后,按照固定的顺序依次传输到计算单元进行处理。计
算单元完成一次计算后,将结果写回内存。这种方案的优势在于其数据传输和计算过
程简洁明了。此外,它能够根据不同层次的计算特点,有针对性地采用多样化的策略来
优化每个硬件内核的实现方式及并行处理方案,从而有效提升整体吞吐量。然而,由于
数据传输和计算是严格顺序进行的,计算单元在等待数据传输完成时可能会出现闲置,
导致资源利用率较低,且不够灵活。
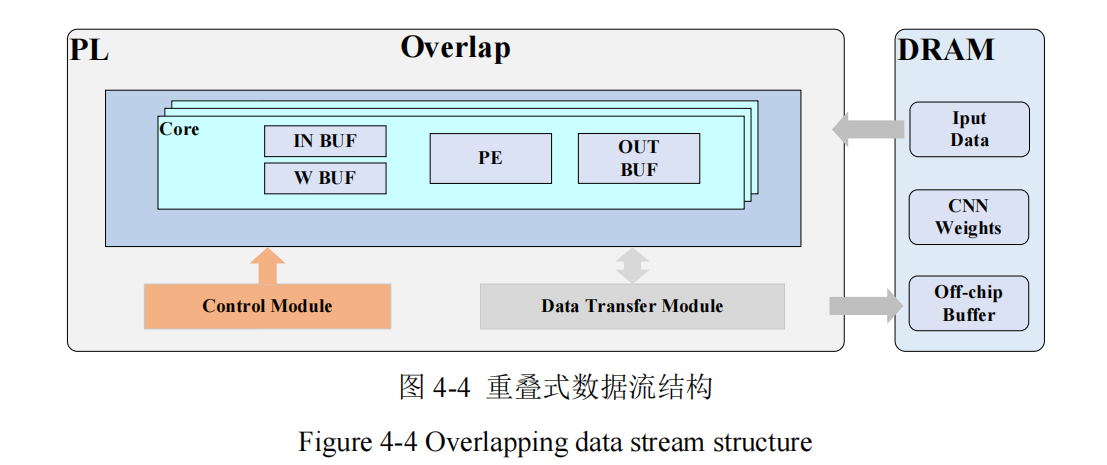
Overlap Pattern 即重叠式数据流,其结构如图 4-4 所示,是一种数据传输和计算重
叠的方式71。在这种模式下,数据的读取、计算和写回操作可以部分重叠进行。当一
部分数据正在计算单元中处理时,下一组数据可以同时从内存中读取,而计算结果也
可以在计算完成后立即写回内存。这种设计的一大优点是灵活性,当输入模型发生变
化,但计算算子保持不变时,无需重新设计硬件,这大大节省了时间和资源。但由于采
用了与通用处理器相近的控制架构,这类系统在运算过程中难以充分发挥能效优势。
当基于这种架构部署计算模型时,需要解决双重挑战:既要精准计算核心组件的物理
规格参数,又需设计高效的任务分配策略。
为充分发挥 Zynq 异构平台的 PS-PL 协同优势和应对快速迭代的算法场景,本设计
采用基于重叠式数据流的可重构架构实现 YOLOv4-tiny 模型,针对卷积、池化等通用
算子设计独立可复用 PE 单元,提升硬件资源利用率,降低计算单元闲置时间。
4.3 硬件加速器性能优化策略
在面向目标检测的硬件加速器设计中,性能优化需在计算效率、资源占用与功耗
约束间实现精准权衡。传统硬件加速方案常因计算并行度不足、数据流阻塞或存储带
宽瓶颈导致性能劣化,难以满足嵌入式实时目标检测系统对高吞吐率、低延时的严苛
要求。本节将从计算精度压缩、计算流程优化、计算并行化、数据流优化和存储架构重
构五个方面优化硬件加速器的性能72。
信迈科技提供ZYNQ/ ARM+FPGA工业主板及算法定制。
基于ZYNQ的目标检测算法硬件加速器优化设计
ARM+FPGA+AI工业主板定制专家2025-10-20 21:16
相关推荐
深度研习笔记39 分钟前
OpenCV工业视觉实战11|多线程解耦+视频流稳流+推理加速,彻底解决卡顿阻塞,实现毫秒级工业实时检测delishcomcn42 分钟前
AI视觉识别+分切算法:电化铝缺陷检测与裁切一体化解锁触底反弹1 小时前
深入理解大模型采样:Temperature、Top-K、Top-P 的原理与实战cd_949217211 小时前
2026 AI Agent 落地指南:除了搭建工具,你还需要配套的搜索基础设施武子康1 小时前
Search Console Platform Properties 扩大 SEO 资产边界:从 Page Ranking 到 Topic Coverage(5 类误读边界 + 3 表数据层设计)大模型码小白1 小时前
【Python零基础教程】继承、多态与魔法函数:面向对象编程三大核心特性详解麻雀飞吧2 小时前
最新量化学习路径,交易认知和技术实现要并行北辰alk2 小时前
我用Seed Evolving做了个“代码遗产抢救者”和“旅行规划师”——一个开发者的双面实战日记腾渊信息科技公司2 小时前
Spring Boot对接MES实战:视觉检测数据自动同步方案