本篇文章From Data Drift to Compliance: Building Robust Machine Learning (ML) Lineage in ML Applications为构建机器学习(ML)应用的完整数据和模型追踪提供了详细指南。文章的技术亮点在于使用DVC和Prefect实现了全面的ML谱系管理,确保数据的可追溯性和合规性。适用场景包括需要遵循法规和保证模型公平性的行业,如金融和医疗。实际案例中,通过AWS Lambda架构,成功集成了ETL管道、数据漂移检测、模型调优及风险评估等步骤,为机器学习项目提供了结构化的管理方案。

文章目录
- [1 前言](#1 前言)
-
- [1.1 引言](#1.1 引言)
- [1.2 什么是机器学习血缘关系](#1.2 什么是机器学习血缘关系)
- [1.3 我们将构建什么](#1.3 我们将构建什么)
- [1.4 工作流实践](#1.4 工作流实践)
- [2 步骤 1. 初始化 DVC 项目](#2 步骤 1. 初始化 DVC 项目)
- [3 步骤 2. ML 血缘关系](#3 步骤 2. ML 血缘关系)
-
-
- [3.1 阶段 1. ETL 管道](#3.1 阶段 1. ETL 管道)
- [3.2 阶段 2. 数据漂移检查](#3.2 阶段 2. 数据漂移检查)
- [3.3 阶段 3. 预处理](#3.3 阶段 3. 预处理)
- [3.4 阶段 4. 调优模型](#3.4 阶段 4. 调优模型)
- [3.5 阶段 5. 执行推理](#3.5 阶段 5. 执行推理)
- [3.6 阶段 6. 评估模型风险和公平性](#3.6 阶段 6. 评估模型风险和公平性)
-
- [4 本地测试](#4 本地测试)
- [5 步骤 3. 部署 DVC 项目](#5 步骤 3. 部署 DVC 项目)
- [6 步骤 4. 使用 Prefect 配置计划运行](#6 步骤 4. 使用 Prefect 配置计划运行)
-
- [6.1 配置 Docker 镜像注册表](#6.1 配置 Docker 镜像注册表)
- [6.2 配置 Prefect 任务和流程](#6.2 配置 Prefect 任务和流程)
- [6.3 本地测试](#6.3 本地测试)
- [7 步骤 5. 部署应用程序](#7 步骤 5. 部署应用程序)
-
- [7.1 本地测试](#7.1 本地测试)
- [8 结论](#8 结论)
1 前言
1.1 引言
在任何强大的机器学习(ML)系统中,ML 血缘关系都至关重要,它用于跟踪数据和模型版本,确保可复现性、可审计性和合规性。
尽管存在许多服务,但创建一个全面且易于管理的血缘关系通常会很复杂。
在本文中,我将详细介绍如何为部署在无服务器 AWS Lambda 架构上的 ML 应用程序集成全面的 ML 血缘解决方案,涵盖端到端管道阶段:
- ETL 管道,
- 数据漂移检测,
- 预处理,
- 模型调优,以及
- 风险和公平性评估。
1.2 什么是机器学习血缘关系
机器学习(ML)血缘关系是一个用于跟踪和理解机器学习模型完整生命周期的框架。
它包含不同级别的信息,例如:
- 代码:用于模型训练的脚本、库和配置。
- 数据:原始数据、转换和特征。
- 实验:训练运行、超参数调优结果。
- 模型:训练好的模型及其版本。
- 预测:部署模型的输出。
ML 血缘关系对于多种原因至关重要:
- 可复现性:重现相同的模型和预测以进行验证。
- 根本原因分析:当模型在生产中失败时,追溯到数据、代码或配置更改。
- 合规性:一些受监管行业要求提供模型训练证明,以确保公平性、透明度并遵守 GDPR 和欧盟人工智能法案等法律。
1.3 我们将构建什么
在这个项目中,我将使用 DVC(一个用于 ML 应用程序的开源版本控制系统)为 AWS Lambda 架构上的定价系统 集成完整的 ML 血缘关系。
下图展示了整个系统:
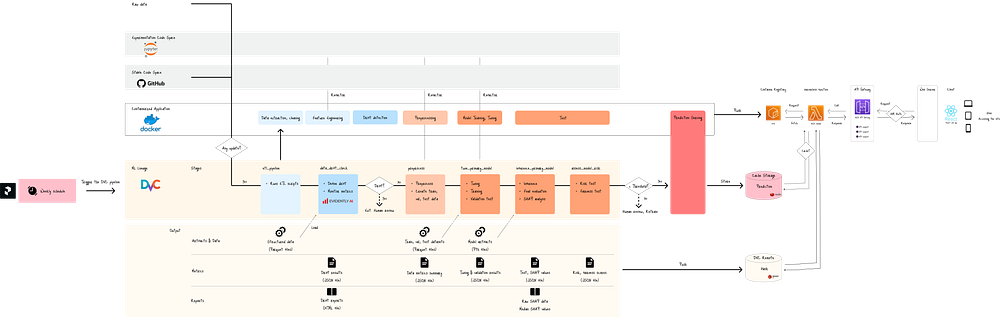
图 A. 无服务器 Lambda 上 ML 应用程序的全面 ML 血缘关系
在该系统中,GitHub 处理代码血缘关系,而 DVC 捕获以下内容的血缘关系:
- 数据(蓝色框):ETL 和预处理,
- 实验(浅橙色):超参数调优和验证,
- 模型(深橙色):最终模型工件,以及
- 预测(深橙色):预测和公平性测试结果。
DVC 在不同的阶段跟踪这些血缘关系,从数据提取到公平性测试(图 A 中的黄色行)。
对于每个阶段,DVC 使用 MD5 哈希 跟踪工件、指标和报告,并将此元数据推送到其在 AWS S3 上的 DVC 远程存储。
然后,只有通过数据漂移和公平性测试的模型工件才能通过 API 网关在生产中提供其预测(图 A 中的红色框)。
最后,整个血缘过程由开源工作流调度器 Prefect 每周触发。
Prefect 提示 DVC 检查数据和脚本的任何更新,如果检测到更改,则执行完整的血缘过程。
1.4 工作流实践
构建过程涉及五个主要步骤:
- 初始化 DVC 项目,
- 使用 DVC 脚本
dvc.yaml和相应的 Python 脚本定义血缘阶段, - 部署 DVC 项目,
- 使用 Prefect 配置计划运行,以及
- 部署应用程序。
让我们来看看。
2 步骤 1. 初始化 DVC 项目
第一步是初始化 DVC 项目:
bash
$dvc init此命令会自动在项目根目录创建 .dvc 目录:
.
.dvc/
│
└── cache/
└── tmp/
└── .gitignore
└── config
└── config.local DVC 通过将大型文件的原始数据与仓库分离,维护一个快速、轻量级的 Git 仓库。
该过程包括:
- 将原始数据缓存到本地
.dvc/cache目录中, - 创建一个小的
.dvc元数据文件,其中包含 MD5 哈希和指向原始数据文件路径的链接, - 只将小的元数据文件推送到 Git,以及
- 将原始数据推送到 DVC 远程存储。
3 步骤 2. ML 血缘关系
接下来,我将配置 ML 血缘关系,包括以下阶段:
etl_pipeline:提取、清理、填充原始数据并执行特征工程。data_drift_check:运行数据漂移测试。如果测试失败,系统将退出。preprocess:创建训练、验证和测试数据集。tune_primary_model:调优超参数并训练模型。inference_primary_model:在测试数据集上执行推理。assess_model_risk:运行风险和公平性测试。
每个阶段都需要在 dvc.yaml 上定义 DVC 命令及其相应的 Python 脚本。
让我们来看看。
3.1 阶段 1. ETL 管道
第一个阶段是提取、清理、填充原始数据并执行特征工程。
DVC 配置
我将在项目根目录创建 dvc.yaml 文件,并添加 etl_pipeline 阶段:
dvc.yaml
yaml
stages:
etl_pipeline:
cmd: python src/data_handling/etl_pipeline.py
deps:
- src/data_handling/etl_pipeline.py
- src/data_handling/
- src/_utils/
outs:
- data/original_df.parquet
- data/processed_df.parquetdvc.yaml 文件通过定义阶段及其部分(如:)来定义 DVC 项目的配置:
cmd:要为该阶段执行的 shell 命令,deps:运行cmd所需的依赖项,params:在params.yaml文件中定义的cmd的默认参数,metrics:要跟踪的指标文件,reports:要跟踪的报告文件,plots:用于可视化的 DVC 绘图文件,以及outs:由cmd生成的输出文件,DVC 将跟踪这些文件。
此配置有助于 DVC:
- 通过明确列出每个阶段的依赖项、输出和命令来确保可复现性,
- 通过建立工作流的有向无环图(DAG)来管理血缘关系,将每个阶段链接到下一个阶段。
Python 脚本
接下来,我将添加 Python 脚本,确保数据使用 dvc.yaml 文件 outs 部分中指定的文件路径存储:
src/data_handling/etl_pipeline.py
python
import os
import argparse
import src.data_handling.scripts as scripts
from src._utils import main_logger
def etl_pipeline(stockcode: str = '', impute_stockcode: bool = False):
df = scripts.extract_original_dataframe()
ORIGINAL_DF_PATH = os.path.join('data', 'original_df.parquet')
df.to_parquet(ORIGINAL_DF_PATH, index=False)
df = scripts.structure_missing_values(df=df)
df = scripts.handle_feature_engineering(df=df)
PROCESSED_DF_PATH = os.path.join('data', 'processed_df.parquet')
df.to_parquet(PROCESSED_DF_PATH, index=False)
return df
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="run etl pipeline")
parser.add_argument('--stockcode', type=str, default='', help="specific stockcode to process. empty runs full pipeline.")
parser.add_argument('--impute', action='store_true', help="flag to create imputation values")
args = parser.parse_args()
etl_pipeline(stockcode=args.stockcode, impute_stockcode=args.impute)输出
原始数据和结构化数据在 Pandas 的 DataFrame 中存储在 DVC 缓存中:
data/original_df.parquetdata/processed_df.parquet
3.2 阶段 2. 数据漂移检查
在进入预处理之前,我将运行数据漂移测试。
数据漂移是指模型训练数据中统计特性(如均值、方差或分布)的任何变化。
其主要类别包括:
- 协变量漂移(特征漂移):输入特征分布的变化。
- 先验概率漂移(标签漂移):目标变量分布的变化。
- 概念漂移:输入数据和目标变量之间关系的变化。
这些数据漂移会随着时间的推移损害模型的泛化能力。
DVC 配置
我将在 etl_pipeline 阶段之后添加 data_drift_check 阶段:
dvc.yaml
yaml
stages:
etl_pipeline:
data_drift_check:
cmd: >
python src/data_handling/report_data_drift.py
data/processed/processed_df.csv
data/processed_df_${params.stockcode}.parquet
reports/data_drift_report_${params.stockcode}.html
metrics/data_drift_${params.stockcode}.json
${params.stockcode}
params:
- params.stockcode
deps:
- src/data_handling/report_data_drift.py
- src/
plots:
- reports/data_drift_report_${params.stockcode}.html
metrics:
- metrics/data_drift_${params.stockcode}.json:
type: json然后,为传递给 DVC 命令的参数添加默认值:
params.yaml
yaml
params:
stockcode: <STOCKCODE OF CHOICE>Python 脚本
在 从 EventlyAI 工作区生成 API 令牌 后,我将添加一个 Python 脚本来检测数据漂移并将结果存储在 metrics 变量中:
src/data_handling/report_data_drift.py
python
import os
import sys
import json
import pandas as pd
import datetime
from dotenv import load_dotenv
from evidently import Dataset, DataDefinition, Report
from evidently.presets import DataDriftPreset
from evidently.ui.workspace import CloudWorkspace
import src.data_handling.scripts as scripts
from src._utils import main_logger
if __name__ == '__main__':
load_dotenv(override=True)
ws = CloudWorkspace(token=os.getenv('EVENTLY_API_TOKEN'), url='https://app.evidently.cloud')
project = ws.get_project('EVENTLY AI PROJECT ID')
REFERENCE_DATA_PATH = sys.argv[1]
CURRENT_DATA_PATH = sys.argv[2]
REPORT_OUTPUT_PATH = sys.argv[3]
METRICS_OUTPUT_PATH = sys.argv[4]
STOCKCODE = sys.argv[5]
os.makedirs(os.path.dirname(REPORT_OUTPUT_PATH), exist_ok=True)
os.makedirs(os.path.dirname(METRICS_OUTPUT_PATH), exist_ok=True)
reference_data_full = pd.read_csv(REFERENCE_DATA_PATH)
reference_data_stockcode = reference_data_full[reference_data_full['stockcode'] == STOCKCODE]
current_data_stockcode = pd.read_parquet(CURRENT_DATA_PATH)
nums, cats = scripts.categorize_num_cat_cols(df=reference_data_stockcode)
for col in nums: current_data_stockcode[col] = pd.to_numeric(current_data_stockcode[col], errors='coerce')
schema = DataDefinition(numerical_columns=nums, categorical_columns=cats)
eval_data_1 = Dataset.from_pandas(reference_data_stockcode, data_definition=schema)
eval_data_2 = Dataset.from_pandas(current_data_stockcode, data_definition=schema)
report = Report(metrics=[DataDriftPreset()])
data_eval = report.run(reference_data=eval_data_1, current_data=eval_data_2)
data_eval.save_html(REPORT_OUTPUT_PATH)
report_dict = json.loads(data_eval.json())
num_drifts = report_dict['metrics'][0]['value']['count']
shared_drifts = report_dict['metrics'][0]['value']['share']
metrics = dict(
drift_detected=bool(num_drifts > 0.0), num_drifts=num_drifts, shared_drifts=shared_drifts,
num_cols=nums,
cat_cols=cats,
stockcode=STOCKCODE,
timestamp=datetime.datetime.now().isoformat(),
)
with open(METRICS_OUTPUT_PATH, 'w') as f:
json.dump(metrics, f, indent=4)
main_logger.info(f'... drift metrics saved to {METRICS_OUTPUT_PATH}... ')
if num_drifts > 0.0: sys.exit('❌ FATAL: data drift detected. stopping pipeline')如果检测到数据漂移,脚本将立即使用最终的 sys.exit 命令退出。
输出
脚本生成两个 DVC 将跟踪的文件:
reports/data_drift_report.html:HTML 格式的数据漂移报告。metrics/data_drift.json:JSON 格式的数据漂移指标,包括漂移结果以及特征列和时间戳:
metrics/data_drift.json
json
{
"drift_detected": false,
"num_drifts": 0.0,
"shared_drifts": 0.0,
"num_cols": [
"invoiceno",
"invoicedate",
"unitprice",
"product_avg_quantity_last_month",
"product_max_price_all_time",
"unitprice_vs_max",
"unitprice_to_avg",
"unitprice_squared",
"unitprice_log"
],
"cat_cols": [
"stockcode",
"customerid",
"country",
"year",
"year_month",
"day_of_week",
"is_registered"
],
"timestamp": "2025-10-07T00:24:29.899495"
}漂移测试结果也可以在 Evently 工作区仪表板上进行进一步分析:
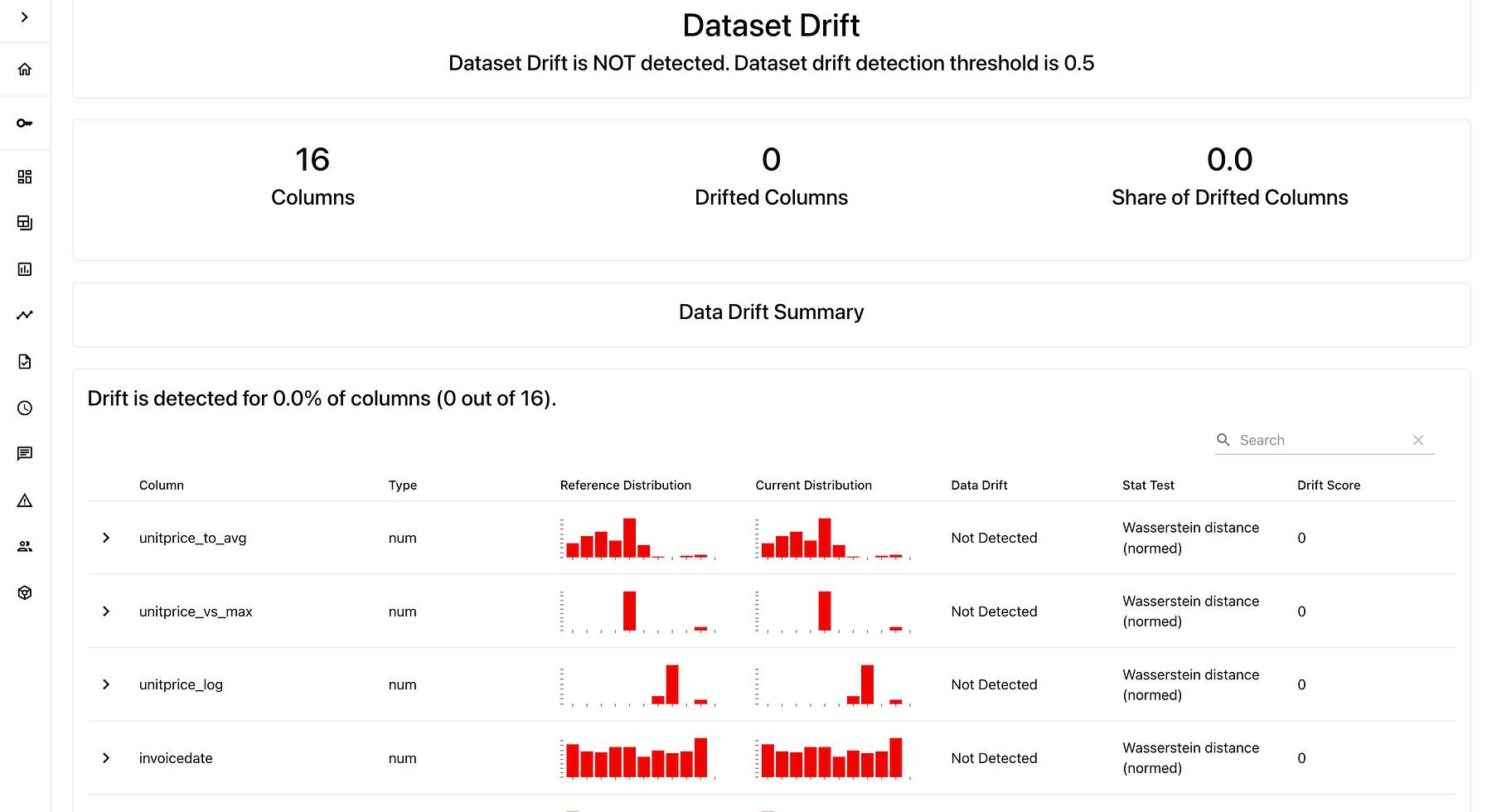
图. Evently 工作区仪表板截图
3.3 阶段 3. 预处理
如果未检测到数据漂移,血缘关系将进入预处理阶段。
DVC 配置
我将在 data_drift_check 阶段之后添加 preprocess 阶段:
dvc.yaml
yaml
stages:
etl_pipeline:
data_drift_check:
preprocess:
cmd: >
python src/data_handling/preprocess.py --target_col ${params.target_col} --should_scale ${params.should_scale} --verbose ${params.verbose}
deps:
- src/data_handling/preprocess.py
- src/data_handling/
- src/_utils
params:
- params.target_col
- params.should_scale
- params.verbose
outs:
- data/x_train_df.parquet
- data/x_val_df.parquet
- data/x_test_df.parquet
- data/y_train_df.parquet
- data/y_val_df.parquet
- data/y_test_df.parquet
- data/x_train_processed.parquet
- data/x_val_processed.parquet
- data/x_test_processed.parquet
- preprocessors/column_transformer.pkl
- preprocessors/feature_names.json并添加 cmd 中使用的参数的默认值:
params.yaml
yaml
params:
target_col: "quantity"
should_scale: True
verbose: FalsePython 脚本
接下来,我将添加其相应的 Python 脚本:
python
import os
import argparse
import json
import joblib
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import src.data_handling.scripts as scripts
from src._utils import main_logger
def preprocess(stockcode: str = '', target_col: str = 'quantity', should_scale: bool = True, verbose: bool = False):
DATA_DRIFT_METRICS_PATH = os.path.join('metrics', f'data_drift_{stockcode}.json')
if os.path.exists(DATA_DRIFT_METRICS_PATH):
with open(DATA_DRIFT_METRICS_PATH, 'r') as f:
metrics = json.load(f)
else: metrics = dict()
PROCESSED_DF_PATH = os.path.join('data', 'processed_df.parquet')
df = pd.read_parquet(PROCESSED_DF_PATH)
num_cols, cat_cols = scripts.categorize_num_cat_cols(df=df, target_col=target_col)
if verbose: main_logger.info(f'num_cols: {num_cols} \ncat_cols: {cat_cols}')
if cat_cols:
for col in cat_cols: df[col] = df[col].astype('string')
PREPROCESSOR_PATH = os.path.join('preprocessors', 'column_transformer.pkl')
try:
preprocessor = joblib.load(PREPROCESSOR_PATH)
except:
preprocessor = scripts.create_preprocessor(num_cols=num_cols if should_scale else [], cat_cols=cat_cols)
y = df[target_col]
X = df.copy().drop(target_col, axis='columns')
test_size, random_state = 50000, 42
X_tv, X_test, y_tv, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state, shuffle=False)
X_train, X_val, y_train, y_val = train_test_split(X_tv, y_tv, test_size=test_size, random_state=random_state, shuffle=False)
X_train.to_parquet('data/x_train_df.parquet', index=False)
X_val.to_parquet('data/x_val_df.parquet', index=False)
X_test.to_parquet('data/x_test_df.parquet', index=False)
y_train.to_frame(name=target_col).to_parquet('data/y_train_df.parquet', index=False)
y_val.to_frame(name=target_col).to_parquet('data/y_val_df.parquet', index=False)
y_test.to_frame(name=target_col).to_parquet('data/y_test_df.parquet', index=False)
X_train = preprocessor.fit_transform(X_train)
X_val = preprocessor.transform(X_val)
X_test = preprocessor.transform(X_test)
pd.DataFrame(X_train).to_parquet(f'data/x_train_processed.parquet', index=False)
pd.DataFrame(X_val).to_parquet(f'data/x_val_processed.parquet', index=False)
pd.DataFrame(X_test).to_parquet(f'data/x_test_processed.parquet', index=False)
with open('preprocessors/feature_names.json', 'w') as f:
feature_names = preprocessor.get_feature_names_out()
json.dump(feature_names.tolist(), f)
return X_train, X_val, X_test, y_train, y_val, y_test, preprocessor
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='run data preprocessing')
parser.add_argument('--stockcode', type=str, default='', help='specific stockcode')
parser.add_argument('--target_col', type=str, default='quantity', help='the target column name')
parser.add_argument('--should_scale', type=bool, default=True, help='flag to scale numerical features')
parser.add_argument('--verbose', type=bool, default=False, help='flag for verbose logging')
args = parser.parse_args()
X_train, X_val, X_test, y_train, y_val, y_test, preprocessor = preprocess(
target_col=args.target_col,
should_scale=args.should_scale,
verbose=args.verbose,
stockcode=args.stockcode,
)输出
此阶段生成模型训练和推理所需的必要数据集:
输入特征:
data/x_train_df.parquetdata/x_val_df.parquetdata/x_test_df.parquet
预处理后的输入特征:
data/x_train_processed_df.parquetdata/x_val_processed_df.parquetdata/x_test_processed_df.parquet
目标变量:
data/y_train_df.parquetdata/y_val_df.parquetdata/y_test_df.parquet
预处理器和人类可读的特征名称也存储在缓存中,用于后续的推理和 SHAP 特征影响分析:
preprocessors/column_transformer.pkpreprocessors/feature_names.json
此外,DVC 更新数据摘要指标以实现可追溯性:
metrics/data.json
json
{
"drift_detected": false,
"num_drifts": 0.0,
"shared_drifts": 0.0,
"num_cols": [
"invoiceno",
"invoicedate",
"unitprice",
"product_avg_quantity_last_month",
"product_max_price_all_time",
"unitprice_vs_max",
"unitprice_to_avg",
"unitprice_squared",
"unitprice_log"
],
"cat_cols": [
"stockcode",
"customerid",
"country",
"year",
"year_month",
"day_of_week",
"is_registered"
],
"timestamp": "2025-10-07T00:24:29.899495",
"preprocess_status": "completed",
"x_train_processed_path": "data/x_train_processed_85123A.parquet",
"preprocessor_path": "preprocessors/column_transformer.pkl"
}这就是数据血缘关系的全部内容。
接下来,我将进入模型/实验血缘关系。
3.4 阶段 4. 调优模型
创建数据集后,我将使用在 preprocess 阶段创建的训练和验证数据集,调优和训练主模型,即 PyTorch 上的多层前馈网络。
DVC 配置
首先,我将在 preprocess 阶段之后添加 tuning_primary_model 阶段:
dvc.yaml
yaml
stages:
etl_pipeline:
data_drift_check:
preprocess:
tune_primary_model:
cmd: >
python src/model/torch_model/main.py
data/x_train_processed_${params.stockcode}.parquet
data/x_val_processed_${params.stockcode}.parquet
data/y_train_df_${params.stockcode}.parquet
data/y_val_df_${params.stockcode}.parquet
${tuning.should_local_save}
${tuning.grid}
${tuning.n_trials}
${tuning.num_epochs}
${params.stockcode}
deps:
- src/model/torch_model/main.py
- src/data_handling/
- src/model/
- src/_utils/
params:
- params.stockcode
- tuning.n_trials
- tuning.grid
- tuning.should_local_save
outs:
- models/production/dfn_best_${params.stockcode}.pth
metrics:
- metrics/dfn_val_${params.stockcode}.json: 然后,为参数添加默认值:
params.yaml
yaml
params:
target_col: "quantity"
should_scale: True
verbose: False
tuning:
n_trials: 100
num_epochs: 3000
should_local_save: False
grid: FalsePython 脚本
接下来,我将添加 Python 脚本,以使用贝叶斯优化 调优模型,然后在 preprocess 阶段创建的完整 X_train 和 y_train 数据集上训练最佳模型。
src/model/torch_model/main.py
python
import os
import sys
import json
import datetime
import pandas as pd
import torch
import torch.nn as nn
import src.model.torch_model.scripts as scripts
def tune_and_train( X_train, X_val, y_train, y_val,
stockcode: str = '',
should_local_save: bool = True,
grid: bool = False,
n_trials: int = 50,
num_epochs: int = 3000 ) -> tuple[nn.Module, dict]:
best_dfn, best_optimizer, best_batch_size, best_checkpoint = scripts.bayesian_optimization(
X_train, X_val, y_train, y_val, n_trials=n_trials, num_epochs=num_epochs
)
DFN_FILE_PATH = os.path.join('models', 'production', f'dfn_best_{stockcode}.pth' if stockcode else 'dfn_best.pth')
os.makedirs(os.path.dirname(DFN_FILE_PATH), exist_ok=True)
torch.save(best_checkpoint, DFN_FILE_PATH)
return best_dfn, best_checkpoint
def track_metrics_by_stockcode(X_val, y_val, best_model, checkpoint: dict, stockcode: str):
MODEL_VAL_METRICS_PATH = os.path.join('metrics', f'dfn_val_{stockcode}.json')
os.makedirs(os.path.dirname(MODEL_VAL_METRICS_PATH), exist_ok=True)
_, mse, exp_mae, rmsle = scripts.perform_inference(model=best_model, X=X_val, y=y_val)
model_version = f"dfn_{stockcode}_{os.getpid()}"
metrics = dict(
stockcode=stockcode,
mse_val=mse,
mae_val=exp_mae,
rmsle_val=rmsle,
model_version=model_version,
hparams=checkpoint['hparams'],
optimizer=checkpoint['optimizer_name'],
batch_size=checkpoint['batch_size'],
lr=checkpoint['lr'],
timestamp=datetime.datetime.now().isoformat()
)
with open(MODEL_VAL_METRICS_PATH, 'w') as f:
json.dump(metrics, f, indent=4)
main_logger.info(f'... validation metrics saved to {MODEL_VAL_METRICS_PATH} ...')
if __name__ == '__main__':
X_TRAIN_PATH = sys.argv[1]
X_VAL_PATH = sys.argv[2]
Y_TRAIN_PATH = sys.argv[3]
Y_VAL_PATH = sys.argv[4]
SHOULD_LOCAL_SAVE = sys.argv[5] == 'True'
GRID = sys.argv[6] == 'True'
N_TRIALS = int(sys.argv[7])
NUM_EPOCHS = int(sys.argv[8])
STOCKCODE = str(sys.argv[9])
X_train, X_val = pd.read_parquet(X_TRAIN_PATH), pd.read_parquet(X_VAL_PATH)
y_train, y_val = pd.read_parquet(Y_TRAIN_PATH
```python
X_train, X_val = pd.read_parquet(X_TRAIN_PATH), pd.read_parquet(X_VAL_PATH)
y_train, y_val = pd.read_parquet(Y_TRAIN_PATH), pd.read_parquet(Y_VAL_PATH)
best_model, checkpoint = tune_and_train(
X_train, X_val, y_train, y_val,
stockcode=STOCKCODE, should_local_save=SHOULD_LOCAL_SAVE, grid=GRID, n_trials=N_TRIALS, num_epochs=NUM_EPOCHS
)
track_metrics_by_stockcode(X_val, y_val, best_model=best_model, checkpoint=checkpoint, stockcode=STOCKCODE)输出
此阶段生成两个文件:
models/production/dfn_best.pth:包含模型工件和检查点,例如最佳超参数集。metrics/dfn_val.json:包含调优结果、模型版本、时间戳以及 MSE、MAE 和 RMSLE 的验证结果:
metrics/dfn_val.json
json
{
"stockcode": "85123A",
"mse_val": 0.6137686967849731,
"mae_val": 9.092489242553711,
"rmsle_val": 0.6953299045562744,
"model_version": "dfn_85123A_35604",
"hparams": {
"num_layers": 4,
"batch_norm": false,
"dropout_rate_layer_0": 0.13765888061300502,
"n_units_layer_0": 184,
"dropout_rate_layer_1": 0.5509872409359128,
"n_units_layer_1": 122,
"dropout_rate_layer_2": 0.2408753527744403,
"n_units_layer_2": 35,
"dropout_rate_layer_3": 0.03451842588822594,
"n_units_layer_3": 224,
"learning_rate": 0.026240673135104406,
"optimizer": "adamax",
"batch_size": 64
},
"optimizer": "adamax",
"batch_size": 64,
"lr": 0.026240673135104406,
"timestamp": "2025-10-07T00:31:08.700294"
}3.5 阶段 5. 执行推理
模型调优阶段完成后,我将配置测试推理以进行最终评估。
最终评估使用 MSE、MAE 和 RMSLE 指标,以及用于特征影响和可解释性分析的 SHAP。
SHAP (SHapley Additive exPlanations) 是一个框架,通过使用博弈论中的 Shapley 值概念来量化每个特征对模型预测的贡献。
SHAP 值用于未来的 EDA 和特征工程。
DVC 配置
首先,我将 inference_primary_model 阶段添加到 DVC 配置中。
此阶段具有 plots 部分,DVC 将在此处跟踪和版本化生成的 SHAP 值可视化文件。
dvc.yaml
yaml
stages:
etl_pipeline:
data_drift_check:
preprocess:
tune_primary_model:
inference_primary_model:
cmd: >
python src/model/torch_model/inference.py
data/x_test_processed_${params.stockcode}.parquet
data/y_test_df_${params.stockcode}.parquet
models/production/dfn_best_${params.stockcode}.pth
${params.stockcode}
${tracking.sensitive_feature_col}
${tracking.privileged_group}
deps:
- src/model/torch_model/inference.py
- models/production/
- src/
params:
- params.stockcode
- tracking.sensitive_feature_col
- tracking.privileged_group
metrics:
- metrics/dfn_inf_${params.stockcode}.json:
type: json
plots:
- reports/dfn_shap_summary_${params.stockcode}.json:
template: simple
x: shap_value
y: feature_name
title: SHAP Beeswarm Plot
- reports/dfn_shap_mean_abs_${params.stockcode}.json:
template: bar
x: mean_abs_shap
y: feature_name
title: Mean Absolute SHAP Importance
outs:
- data/dfn_inference_results_${params.stockcode}.parquet
- reports/dfn_raw_shap_values_${params.stockcode}.parquet Python 脚本
接下来,我将添加相应的 Python 脚本:
src/model/torch_model/inference.py
python
import os
import sys
import json
import datetime
import numpy as np
import pandas as pd
import torch
import shap
import src.model.torch_model.scripts as scripts
from src._utils import main_logger
if __name__ == '__main__':
X_TEST_PATH = sys.argv[1]
Y_TEST_PATH = sys.argv[2]
X_test, y_test = pd.read_parquet(X_TEST_PATH), pd.read_parquet(Y_TEST_PATH)
X_test_with_col_names = X_test.copy()
FEATURE_NAMES_PATH = os.path.join('preprocessors', 'feature_names.json')
try:
with open(FEATURE_NAMES_PATH, 'r') as f: feature_names = json.load(f)
except FileNotFoundError: feature_names = X_test.columns.tolist()
if len(X_test_with_col_names.columns) == len(feature_names): X_test_with_col_names.columns = feature_names
MODEL_PATH = sys.argv[3]
checkpoint = torch.load(MODEL_PATH)
model = scripts.load_model(checkpoint=checkpoint)
y_pred, mse, exp_mae, rmsle = scripts.perform_inference(model=model, X=X_test, y=y_test, batch_size=checkpoint['batch_size'])
STOCKCODE = sys.argv[4]
SENSITIVE_FEATURE = sys.argv[5]
PRIVILEGED_GROUP = sys.argv[6]
inference_df = pd.DataFrame(y_pred.cpu().numpy().flatten(), columns=['y_pred'])
inference_df['y_true'] = y_test
inference_df[SENSITIVE_FEATURE] = X_test_with_col_names[f'cat__{SENSITIVE_FEATURE}_{str(PRIVILEGED_GROUP)}'].astype(bool)
inference_df.to_parquet(path=os.path.join('data', f'dfn_inference_results_{STOCKCODE}.parquet'))
MODEL_INF_METRICS_PATH = os.path.join('metrics', f'dfn_inf_{STOCKCODE}.json')
os.makedirs(os.path.dirname(MODEL_INF_METRICS_PATH), exist_ok=True)
model_version = f"dfn_{STOCKCODE}_{os.getpid()}"
inf_metrics = dict(
stockcode=STOCKCODE,
mse_inf=mse,
mae_inf=exp_mae,
rmsle_inf=rmsle,
model_version=model_version,
hparams=checkpoint['hparams'],
optimizer=checkpoint['optimizer_name'],
batch_size=checkpoint['batch_size'],
lr=checkpoint['lr'],
timestamp=datetime.datetime.now().isoformat()
)
with open(MODEL_INF_METRICS_PATH, 'w') as f:
json.dump(inf_metrics, f, indent=4)
main_logger.info(f'... inference metrics saved to {MODEL_INF_METRICS_PATH} ...')
model.eval()
X_test_tensor = torch.from_numpy(X_test.values.astype(np.float32)).to(device_type)
background = X_test_tensor[np.random.choice(X_test_tensor.shape[0], 100, replace=False)].to(device_type)
explainer = shap.DeepExplainer(model, background)
shap_values = explainer.shap_values(X_test_tensor)
if isinstance(shap_values, list): shap_values = shap_values[0]
if isinstance(shap_values, torch.Tensor): shap_values = shap_values.cpu().numpy()
shap_values = shap_values.squeeze(axis=-1)
shap_df = pd.DataFrame(shap_values, columns=feature_names)
RAW_SHAP_OUT_PATH = os.path.join('reports', f'dfn_raw_shap_values_{STOCKCODE}.parquet')
os.makedirs(os.path.dirname(RAW_SHAP_OUT_PATH), exist_ok=True)
shap_df.to_parquet(RAW_SHAP_OUT_PATH, index=False)
main_logger.info(f'... shap values saved to {RAW_SHAP_OUT_PATH} ...')
mean_abs_shap = shap_df.abs().mean().sort_values(ascending=False)
shap_mean_abs_df = pd.DataFrame({'feature_name': feature_names, 'mean_abs_shap': mean_abs_shap.values })
MEAN_ABS_SHAP_PATH = os.path.join('reports', f'dfn_shap_mean_abs_{STOCKCODE}.json')
shap_mean_abs_df.to_json(MEAN_ABS_SHAP_PATH, orient='records', indent=4)输出
此阶段生成五个输出文件:
data/dfn_inference_result_${params_stockcode}.parquet:存储预测结果、标记的目标以及包含敏感特征(如性别、年龄、收入等)的任何列。我将在最后一个阶段使用此文件进行公平性测试。metrics/dfn_inf.json:存储评估指标和调优结果:
metrics/dfn_inf.json
json
{
"stockcode": "85123A",
"mse_inf": 0.6841545701026917,
"mae_inf": 11.5866117477417,
"rmsle_inf": 0.7423332333564758,
"model_version": "dfn_85123A_35834",
"hparams": {
"num_layers": 4,
"batch_norm": false,
"dropout_rate_layer_0": 0.13765888061300502,
"n_units_layer_0": 184,
"dropout_rate_layer_1": 0.5509872409359128,
"n_units_layer_1": 122,
"dropout_rate_layer_2": 0.2408753527744403,
"n_units_layer_2": 35,
"dropout_rate_layer_3": 0.03451842588822594,
"n_units_layer_3": 224,
"learning_rate": 0.026240673135104406,
"optimizer": "adamax",
"batch_size": 64
},
"optimizer": "adamax",
"batch_size": 64,
"lr": 0.026240673135104406,
"timestamp": "2025-10-07T00:31:12.946405"
}reports/dfn_shap_mean_abs.json:存储平均 SHAP 值:
json
[
{
"feature_name":"num__invoicedate",
"mean_abs_shap":0.219255722
},
{
"feature_name":"num__unitprice",
"mean_abs_shap":0.1069829418
},
{
"feature_name":"num__product_avg_quantity_last_month",
"mean_abs_shap":0.1021453096
},
{
"feature_name":"num__product_max_price_all_time",
"mean_abs_shap":0.0855356899
},
...
]reports/dfn_shap_summary.json:包含绘制蜂群/条形图所需的数据点。reports/dfn_raw_shap_values.parquet:存储原始 SHAP 值。
3.6 阶段 6. 评估模型风险和公平性
最后一个阶段是评估最终推理结果的风险和公平性。
公平性测试
ML 中的公平性测试是系统地评估模型预测的过程,以确保它们不会对由敏感属性(如种族和性别)定义的特定群体产生不公平的偏见。
在此项目中,我将使用注册状态 is_registered 列作为敏感特征,并确保**平均结果差异(MOD)**在指定的阈值 0.1 0.1 0.1 内。
MOD 计算为特权(已注册)和非特权(未注册)群体的平均预测值之间的绝对差异。
DVC 配置
首先,我将在 inference_primary_model 阶段之后添加 assess_model_risk 阶段:
dvc.yaml
yaml
stages:
etl_pipeline:
data_drift_check:
preprocess:
tune_primary_model:
inference_primary_model:
assess_model_risk:
cmd: >
python src/model/torch_model/assess_risk_and_fairness.py
data/dfn_inference_results_${params.stockcode}.parquet
metrics/dfn_risk_fairness_${params.stockcode}.json
${tracking.sensitive_feature_col}
${params.stockcode}
${tracking.privileged_group}
${tracking.mod_threshold}
deps:
- src/model/torch_model/assess_risk_and_fairness.py
- src/_utils/
- data/dfn_inference_results_${params.stockcode}.parquet
params:
- params.stockcode
- tracking.sensitive_feature_col
- tracking.privileged_group
- tracking.mod_threshold
metrics:
- metrics/dfn_risk_fairness_${params.stockcode}.json:
type: json然后,为参数添加默认值:
param.yaml
yaml
params:
target_col: "quantity"
should_scale: True
verbose: False
tuning:
n_trials: 100
num_epochs: 3000
should_local_save: False
grid: False
tracking:
sensitive_feature_col: "is_registered"
privileged_group: 1
mod_threshold: 0.1Python 脚本
相应的 Python 脚本包含 calculate_fairness_metrics 函数,该函数执行风险和公平性评估:
src/model/torch_model/assess_risk_and_fairness.py
python
import os
import json
import datetime
import argparse
import pandas as pd
from sklearn.metrics import mean_absolute_error, mean_squared_error, root_mean_squared_log_error
from src._utils import main_logger
def calculate_fairness_metrics( df: pd.DataFrame,
sensitive_feature_col: str,
label_col: str = 'y_true',
prediction_col: str = 'y_pred',
privileged_group: int = 1,
mod_threshold: float = 0.1, ) -> dict:
metrics = dict()
unprivileged_group = 0 if privileged_group == 1 else 1
for group, name in zip([unprivileged_group, privileged_group], ['unprivileged', 'privileged']):
subset = df[df[sensitive_feature_col] == group]
if len(subset) == 0: continue
y_true = subset[label_col].values
y_pred = subset[prediction_col].values
metrics[f'mse_{name}'] = float(mean_squared_error(y_true, y_pred))
metrics[f'mae_{name}'] = float(mean_absolute_error(y_true, y_pred))
metrics[f'rmsle_{name}'] = float(root_mean_squared_log_error(y_true, y_pred))
metrics[f'mean_prediction_{name}'] = float(y_pred.mean())
mae_diff = metrics.get('mae_unprivileged', 0) - metrics.get('mae_privileged', 0)
metrics['mae_diff'] = float(mae_diff)
mod = metrics.get('mean_prediction_unprivileged', 0) - metrics.get('mean_prediction_privileged', 0)
metrics['mean_outcome_difference'] = float(mod)
metrics['is_mod_acceptable'] = 1 if abs(mod) <= mod_threshold else 0
return metrics
def main():
parser = argparse.ArgumentParser(description='assess bias and fairness metrics on model inference results.')
parser.add_argument('inference_file_path', type=str, help='parquet file path to the inference results w/ y_true, y_pred, and sensitive feature cols.')
parser.add_argument('metrics_output_path', type=str, help='json file path to save the metrics output.')
parser.add_argument('sensitive_feature_col', type=str, help='column name of sensitive features')
parser.add_argument('stockcode', type=str)
parser.add_argument('privileged_group', type=int, default=1)
parser.add_argument('mod_threshold', type=float, default=.1)
args = parser.parse_args()
try:
df_inference = pd.read_parquet(args.inference_file_path)
LABEL_COL = 'y_true'
PREDICTION_COL = 'y_pred'
SENSITIVE_COL = args.sensitive_feature_col
metrics = calculate_fairness_metrics(
df=df_inference,
sensitive_feature_col=SENSITIVE_COL,
label_col=LABEL_COL,
prediction_col=PREDICTION_COL,
privileged_group=args.privileged_group,
mod_threshold=args.mod_threshold,
)
metrics['model_version'] = f'dfn_{args.stockcode}_{os.getpid()}'
metrics['sensitive_feature'] = args.sensitive_feature_col
metrics['privileged_group'] = args.privileged_group
metrics['mod_threshold'] = args.mod_threshold
metrics['stockcode'] = args.stockcode
metrics['timestamp'] = datetime.datetime.now().isoformat()
with open(args.metrics_output_path, 'w') as f:
json_metrics = { k: (v if pd.notna(v) else None) for k, v in metrics.items() }
json.dump(json_metrics, f, indent=4)
except Exception as e:
main_logger.error(f'... an error occurred during risk and fairness assessment: {e} ...')
exit(1)
if __name__ == '__main__':
main()输出
最终阶段生成一个指标文件,其中包含测试结果和模型版本:
metrics/dfn_risk_fairness.json
json
{
"mse_unprivileged": 3.5370739412593575,
"mae_unprivileged": 1.48263614013523,
"rmsle_unprivileged": 0.6080000224747837,
"mean_prediction_unprivileged": 1.8507767915725708,
"mae_diff": 1.48263614013523,
"mean_outcome_difference": 1.8507767915725708,
"is_mod_acceptable": 1,
"model_version": "dfn_85123A_35971",
"sensitive_feature": "is_registered",
"privileged_group": 1,
"mod_threshold": 0.1,
"timestamp": "2025-10-07T00:31:15.998590"
}这就是血缘配置的全部内容。
现在,我将在本地进行测试。
4 本地测试
我将运行整个血缘关系:
bash
$dvc repro -f-f 强制 DVC 重新运行所有阶段,无论是否有任何更新。
此命令将自动在项目根目录创建 dvc.lock 文件:
yaml
schema: '2.0'
stages:
etl_pipeline_full:
cmd: python src/data_handling/etl_pipeline.py
deps:
- path: src/_utils/
hash: md5
md5: ae41392532188d290395495f6827ed00.dir
size: 15870
nfiles: 10
- path: src/data_handling/
hash: md5
md5: a8a61a4b270581a7c387d51e416f4e86.dir
size: 95715
...此 dvc.lock 文件必须发布到 Git,以确保 DVC 将加载最新文件:
bash
$git add dvc.lock .dvc dvc.yaml params.yaml
$git commit -m'updated dvc config'
$git push5 步骤 3. 部署 DVC 项目
接下来,我将部署 DVC 项目,以确保 AWS Lambda 函数可以在生产中访问缓存文件。
此步骤首先配置 DVC 远程存储。
DVC 提供 各种存储类型,如 AWS S3 和 Google Cloud。我将为本项目选择 AWS S3,但选择取决于项目生态系统、熟悉程度和资源限制。
首先,我将在选定的 AWS 区域中创建一个新的 S3 存储桶:
bash
$aws s3 mb s3://<PROJECT NAME>/<BUCKET NAME> --region <AWS REGION>(确保 IAM 角色具有以下权限: _s3:ListBucket_、 _s3:GetObject_、 _s3:PutObject__ 和__s3:DeleteObject__)
然后,将 S3 存储桶的 URI 添加到 DVC 远程存储:
bash
$dvc remote add -d <DVC REMOTE NAME> ss3://<PROJECT NAME>/<BUCKET NAME>然后,我将缓存文件推送到 DVC 远程存储:
bash
$dvc push现在,所有缓存文件都存储在 S3 存储桶中:
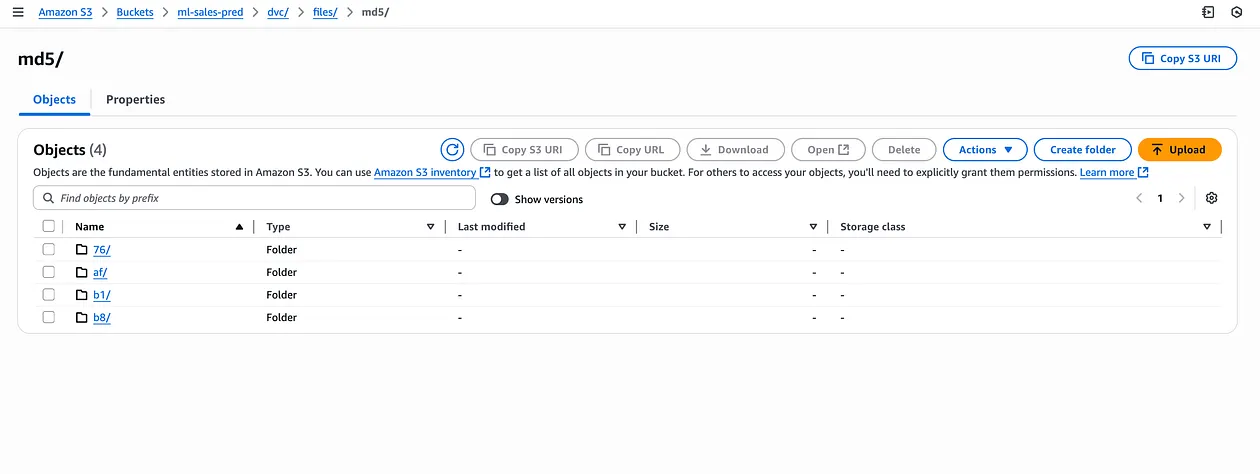
图. AWS S3 存储桶中的 DVC 远程存储截图
如图 A 所示,此部署步骤对于 AWS Lambda 函数在生产中访问 DVC 缓存是必需的。
6 步骤 4. 使用 Prefect 配置计划运行
下一步是使用 Prefect 配置整个血缘关系的计划运行。
Prefect 是一个开源工作流编排工具,用于构建、调度和监控管道。
它使用工作池的概念,有效地将编排逻辑与执行基础设施解耦。
然后,工作池通过运行 Docker 容器镜像作为标准化基础配置,以保证所有流程的一致执行环境。
6.1 配置 Docker 镜像注册表
第一步是为 Prefect 工作池配置 Docker 镜像注册表:
- 对于本地部署:Docker Hub 中的容器注册表。
- 对于生产部署:AWS ECR。
对于本地部署,我将首先验证 Docker 客户端:
bash
$docker login并授予用户无需 sudo 即可运行 Docker 命令的权限:
bash
$sudo dscl . -append /Groups/docker GroupMembership $USER对于生产部署,我将创建一个新的 ECR:
bash
$aws ecr create-repository --repository-name <REGISTORY NAME> --region <AWS REGION>(确保 IAM 角色可以访问此新的 ECR URI。)
6.2 配置 Prefect 任务和流程
接下来,我将配置项目中的 Prefect task 和 flow:
- Prefect
task执行dvc repro和dvc push命令 - Prefect
flow每周执行 Prefecttask。
src/prefect_flows.py
python
import os
import sys
import subprocess
from datetime import timedelta, datetime
from dotenv import load_dotenv
from prefect import flow, task
from prefect.schedules import Schedule
from prefect_aws import AwsCredentials
from src._utils import main_logger
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
@task(retries=3, retry_delay_seconds=30)
def run_dvc_pipeline():
result = subprocess.run(["dvc", "repro"], capture_output=True, text=True, check=True)
subprocess.run(["dvc", "push"], check=True)
@flow(name="Weekly Data Pipeline")
def weekly_data_flow():
run_dvc_pipeline()
if __name__ == '__main__':
load_dotenv(override=True)
ENV = os.getenv('ENV', 'production')
DOCKER_HUB_REPO = os.getenv('DOCKER_HUB_REPO')
ECR_FOR_PREFECT_PATH = os.getenv('S3_BUCKET_FOR_PREFECT_PATH')
image_repo = f'{DOCKER_HUB_REPO}:ml-sales-pred-data-latest' if ENV == 'local' else f'{ECR_FOR_PREFECT_PATH}:latest'
weekly_schedule = Schedule(
interval=timedelta(weeks=1),
anchor_date=datetime(2025, 9, 29, 9, 0, 0),
active=True,
)
AwsCredentials(
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),
region_name=os.getenv('AWS_REGION_NAME'),
).save('aws', overwrite=True)
weekly_data_flow.deploy(
name='weekly-data-flow',
schedule=weekly_schedule,
work_pool_name="wp-ml-sales-pred",
image=image_repo,
concurrency_limit=3,
push=True
)6.3 本地测试
接下来,我将使用 Prefect 服务器在本地测试工作流:
bash
$uv run prefect server start
bash
$export PREFECT_API_URL="http://127.0.0.1:4200/api"运行 prefect_flows.py 脚本:
bash
$uv run src/prefect_flows.py成功执行后,Prefect 仪表板将显示工作流已计划运行:
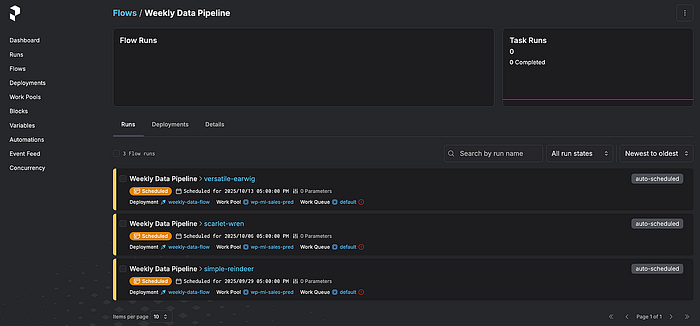
图. Prefect 仪表板截图
7 步骤 5. 部署应用程序
最后一步是通过配置 Dockerfile 和 Flask 应用程序脚本来部署整个应用程序作为容器化 Lambda。
此最终部署步骤中的具体过程取决于基础设施。
但共同点是 DVC 消除了将大型 Parquet 或 CSV 文件直接存储在特征存储或模型存储中的需求,因为它将它们缓存为轻量级哈希文件。
因此,首先,我将通过使用 dvc.api 框架简化 Flask 应用程序脚本的加载逻辑:
app.py
python
import dvc.api
DVC_REMOTE_NAME=<REMOTE NAME IN .dvc/config file>
def configure_dvc_for_lambda():
os.environ.update({
'DVC_CACHE_DIR': '/tmp/dvc-cache',
'DVC_DATA_DIR': '/tmp/dvc-data',
'DVC_CONFIG_DIR': '/tmp/dvc-config',
'DVC_GLOBAL_CONFIG_DIR': '/tmp/d
```python
import dvc.api
DVC_REMOTE_NAME=<REMOTE NAME IN .dvc/config file>
def configure_dvc_for_lambda():
os.environ.update({
'DVC_CACHE_DIR': '/tmp/dvc-cache',
'DVC_DATA_DIR': '/tmp/dvc-data',
'DVC_CONFIG_DIR': '/tmp/dvc-config',
'DVC_GLOBAL_CONFIG_DIR': '/tmp/dvc-global-config',
'DVC_SITE_CACHE_DIR': '/tmp/dvc-site-cache'
})
for dir_path in ['/tmp/dvc-cache', '/tmp/dvc-data', '/tmp/dvc-config']:
os.makedirs(dir_path, exist_ok=True)
def load_x_test():
global X_test
if not os.environ.get('PYTEST_RUN', False):
main_logger.info("... loading x_test ...")
configure_dvc_for_lambda()
try:
with dvc.api.open(X_TEST_PATH, remote=DVC_REMOTE_NAME, mode='rb') as fd:
X_test = pd.read_parquet(fd)
main_logger.info('✅ successfully loaded x_test via dvc api')
except Exception as e:
main_logger.error(f'❌ general loading error: {e}', exc_info=True)
def load_preprocessor():
global preprocessor
if not os.environ.get('PYTEST_RUN', False):
main_logger.info("... loading preprocessor ...")
configure_dvc_for_lambda()
try:
with dvc.api.open(PREPROCESSOR_PATH, remote=DVC_REMOTE_NAME, mode='rb') as fd:
preprocessor = joblib.load(fd)
main_logger.info('✅ successfully loaded preprocessor via dvc api')
except Exception as e:
main_logger.error(f'❌ general loading error: {e}', exc_info=True)然后,更新 Dockerfile 以使 Docker 能够正确引用 DVC 组件:
Dockerfile.lambda.production
dockerfile
FROM public.ecr.aws/lambda/python:3.12
ENV JOBLIB_MULTIPROCESSING=0
ENV DVC_HOME="/tmp/.dvc"
ENV DVC_CACHE_DIR="/tmp/.dvc/cache"
ENV DVC_REMOTE_NAME="storage"
ENV DVC_GLOBAL_SITE_CACHE_DIR="/tmp/dvc_global"
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN python -m pip install --upgrade pip
RUN pip install --no-cache-dir -r requirements.txt
RUN pip install --no-cache-dir dvc dvc-s3
RUN dvc init --no-scm
RUN dvc config core.no_scm true
COPY . ${LAMBDA_TASK_ROOT}
CMD [ "app.handler" ]最后,确保大型文件从 Docker 容器镜像中被忽略:
.dockerignore
.dvc/cache
.dvcignore
data/
preprocessors/
models/
reports/
metrics/7.1 本地测试
最后,我将构建并测试 Docker 镜像:
bash
$docker build -t my-app -f Dockerfile.lambda.local .
$docker run -p 5002:5002 -e ENV=local my-app app.py成功配置后,waitress 服务器将运行 Flask 应用程序。
确认更改后,我将代码推送到 Git:
bash
$git add .
$git commit -m'updated dockerfiles and flask app scripts'
$git pushpush 命令通过 GitHub Actions 触发 CI/CD 管道,该管道生成 Docker 容器镜像并将其推送到 AWS ECR。
在管道流程成功并验证后,我们可以使用 GitHub Actions 手动运行部署工作流。
要设置此 CI/CD 管道,请查看 集成基础设施 CI/CD 管道。
这就是 ML 血缘关系集成的全部内容。
所有代码都可以在 我的 GitHub 仓库中找到。
模拟应用程序也可以在 我的作品集网站上找到。
8 结论
构建强大的 ML 应用程序需要全面的 ML 血缘关系,以确保可靠性和可追溯性。
在本文中,我们演示了如何通过集成 DVC 和 Prefect 等开源服务来构建 ML 血缘关系。
在实践中,初始规划很重要。
具体来说,定义如何以及在哪个阶段跟踪指标直接导致更清晰、更易于维护的代码结构和未来的可扩展性。
展望未来,我们可以考虑在血缘关系中添加更多阶段,并集成用于数据漂移检测或公平性测试的高级逻辑。
这将进一步确保生产环境中模型的持续性能和数据完整性。