目录
[2.1 插入排序](#2.1 插入排序)
[2.1.1 直接插入排序](#2.1.1 直接插入排序)
[2.1.2 希尔排序](#2.1.2 希尔排序)
[2.2 选择排序](#2.2 选择排序)
[2.2.1 直接选择排序](#2.2.1 直接选择排序)
[2.2.2 堆排序](#2.2.2 堆排序)
[2.3 交换排序](#2.3 交换排序)
[2.3.1 冒泡排序](#2.3.1 冒泡排序)
[2.3.2 快速排序](#2.3.2 快速排序)
[2.4 归并排序](#2.4 归并排序)
[2.5 计数排序(非基于比较的排序)](#2.5 计数排序(非基于比较的排序))
一、引言:排序的重要性
排序是计算机科学中最基础且重要的主题之一,无论是学术研究还是实际开发,都离不开排序算法的应用。
本文将系统介绍常用且重要的排序算法,分析它们的性能特点。
排序的概念
排序的定义
排序是将一串记录按照某个或某些关键字的大小,递增或递减排列起来的操作。
简单来说,就是将一组无序的数据变成有序的过程
稳定性
稳定性是排序算法的重要特性。
假设在待排序序列中存在多个相同关键字的记录,如果排序后这些记录的相对次序保持不变,则称该算法是稳定的;否则称为不稳定。
例如:序列 9, 5a, 2, 7, 5b, 8 经过稳定排序后,5a仍然在5b之前
内部排序和外部排序
- 内部排序:数据元素全部放在内存中进行排序
- 外部排序:数据量太大,无法全部放入内存,需要在内外存之间移动数据
二、常见排序算法原理与实现
因为比较排序算法离不开大小比较,因此小编先把交换方法swap写在前面:
java
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}2.1 插入排序
2.1.1 直接插入排序
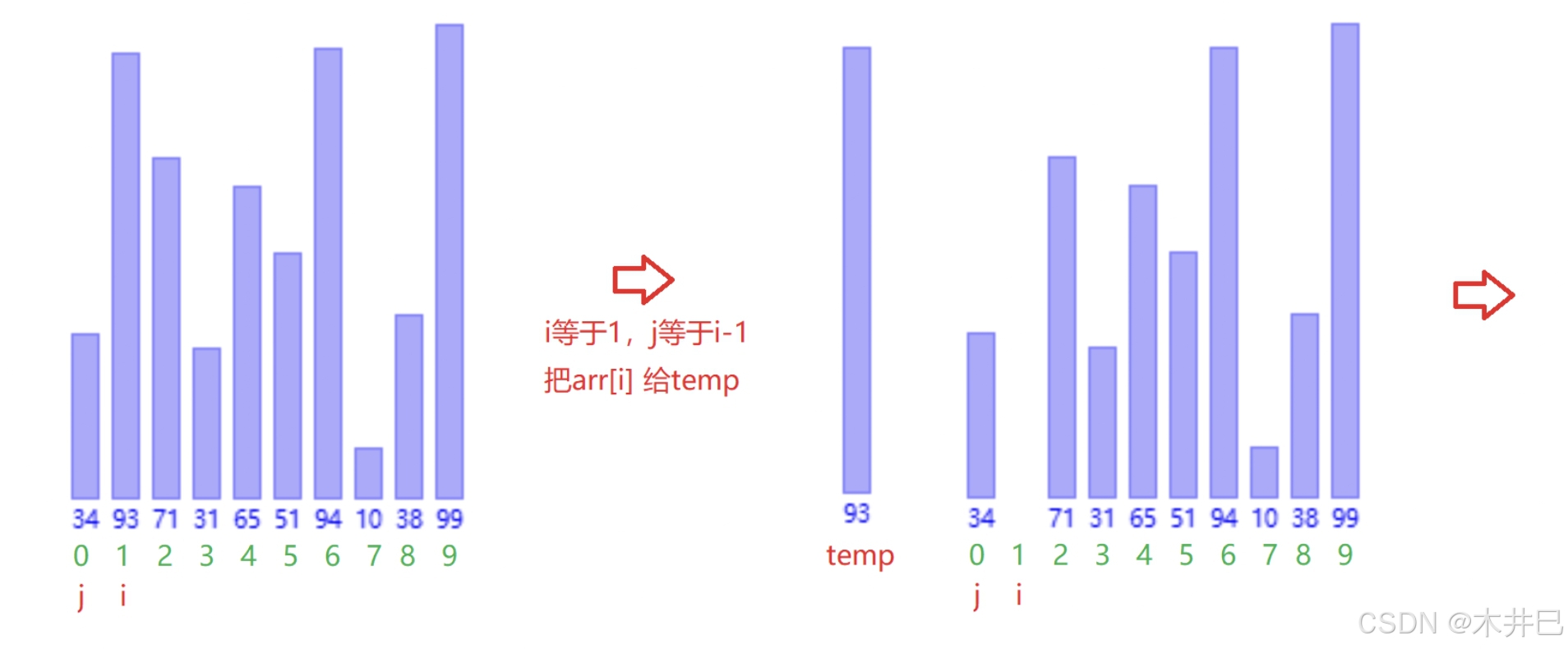
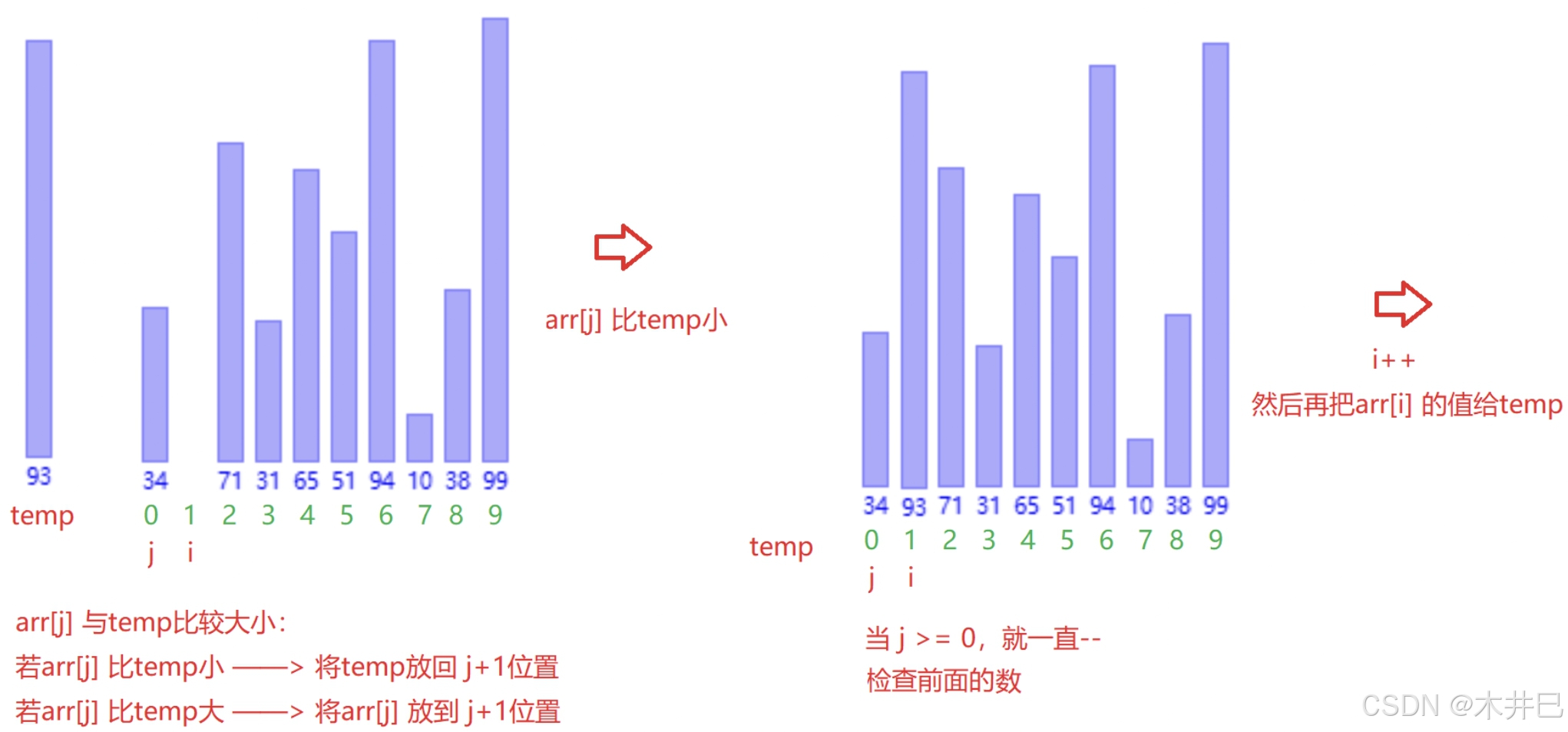
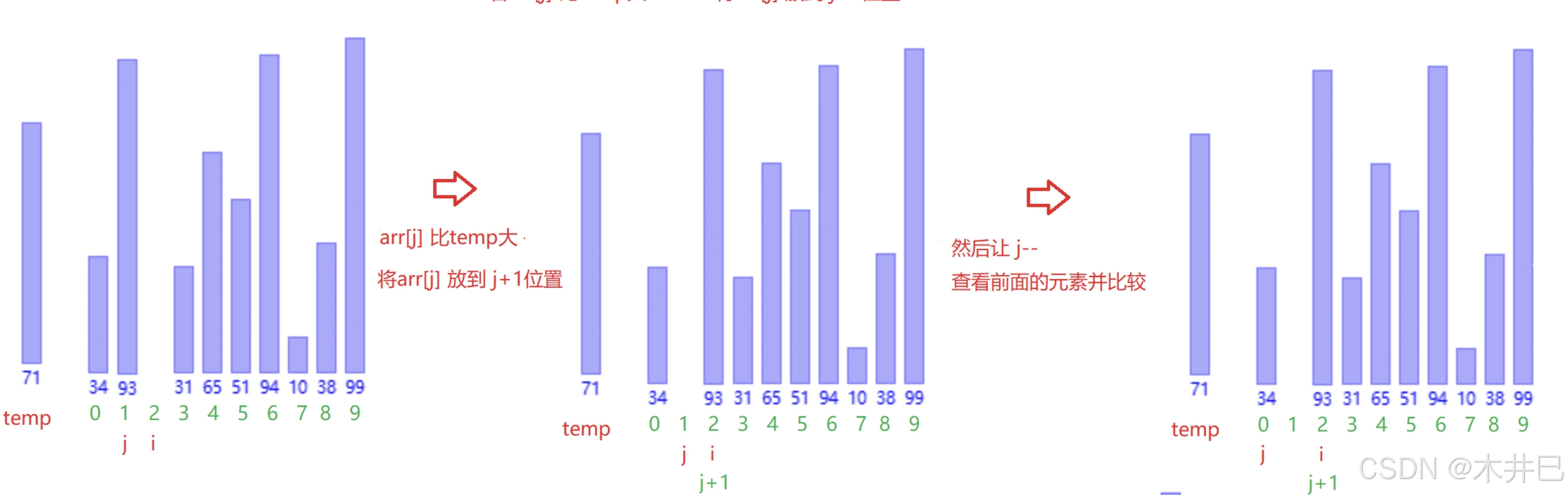
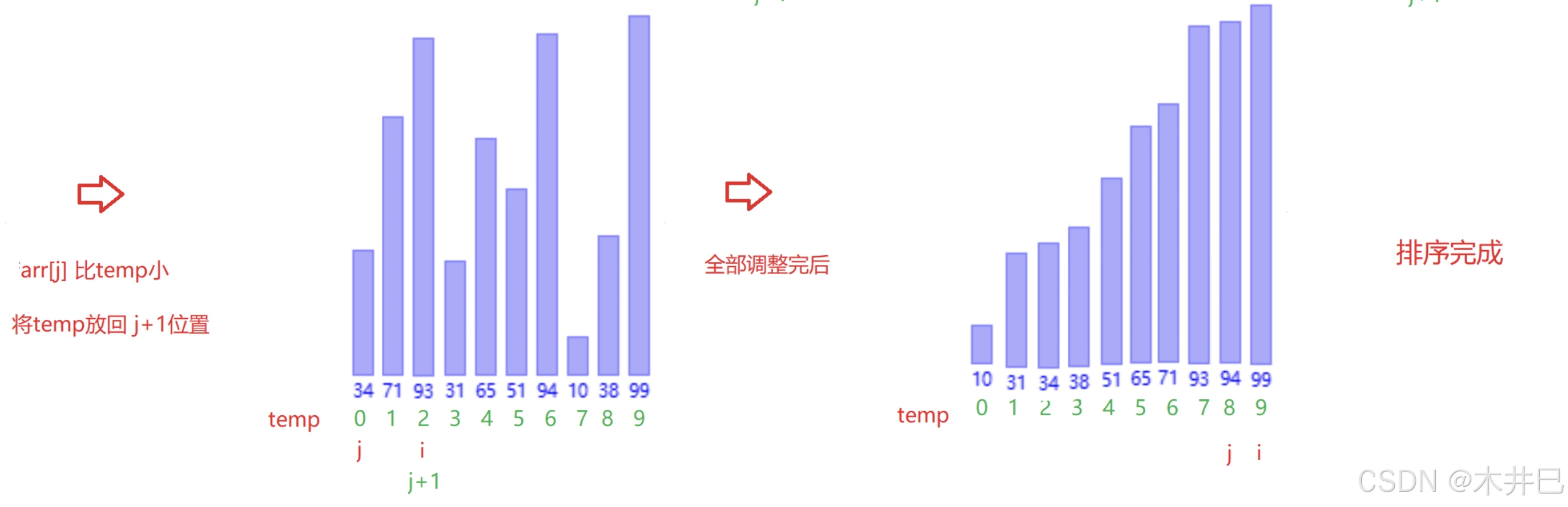
算法实现思路
- 先把第一个元素视作已有序的元素
- 从第二个元素开始,与前面的元素进行大小比较:
- 若比前面的元素小,就交换
- 若比前面的元素大,就停止交换
图示如下:
代码实现
java
// 直接插入排序
public static void insertSort (int[] arr) {
for (int i = 1; i < arr.length; i++) {
int temp = arr[i];
int j = i - 1;
for (; j >= 0; j--) {
if (arr[j] > temp)
arr[j+1] = arr[j];
else {
arr[j+1] = temp;
break;
}
}
arr[j+1] = temp;
}
}性能分析
- 时间复杂度:O(N²) ------ 元素集合越接近有序,效率越高
- 空间复杂度:O(1)
- 稳定性:稳定
2.1.2 希尔排序
算法实现思路
是对直接插入排序的优化
分组插入排序+缩小增量gap。
当gap>=1,属于预排序。
希尔排序采用跳跃式分组(按照gap进行分组),好处是能够把大的数据放到更靠后的位置,随着分的组数越来越少,数据逐渐趋于有序
- 每一次按照数据长度的一半来分组,每一组交替进行插入排序
- 当gap=1时,就全部排序完毕
图示如下:
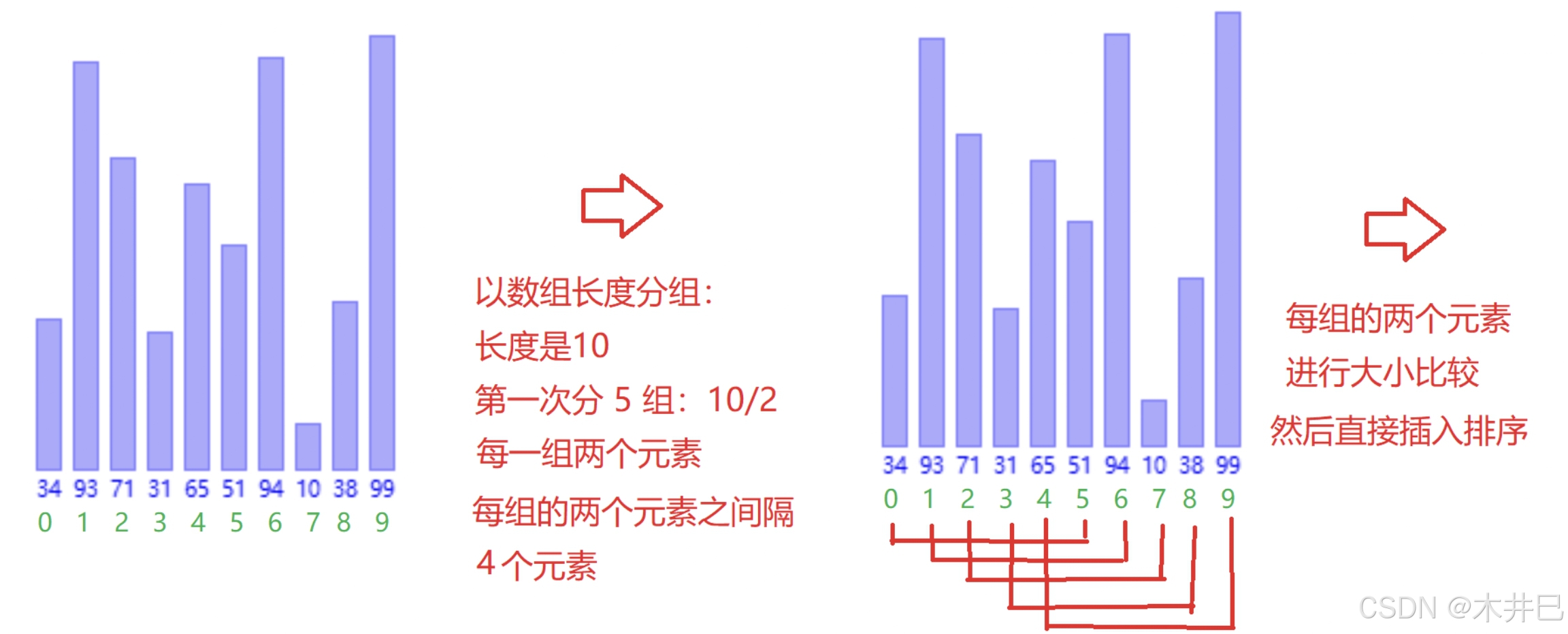
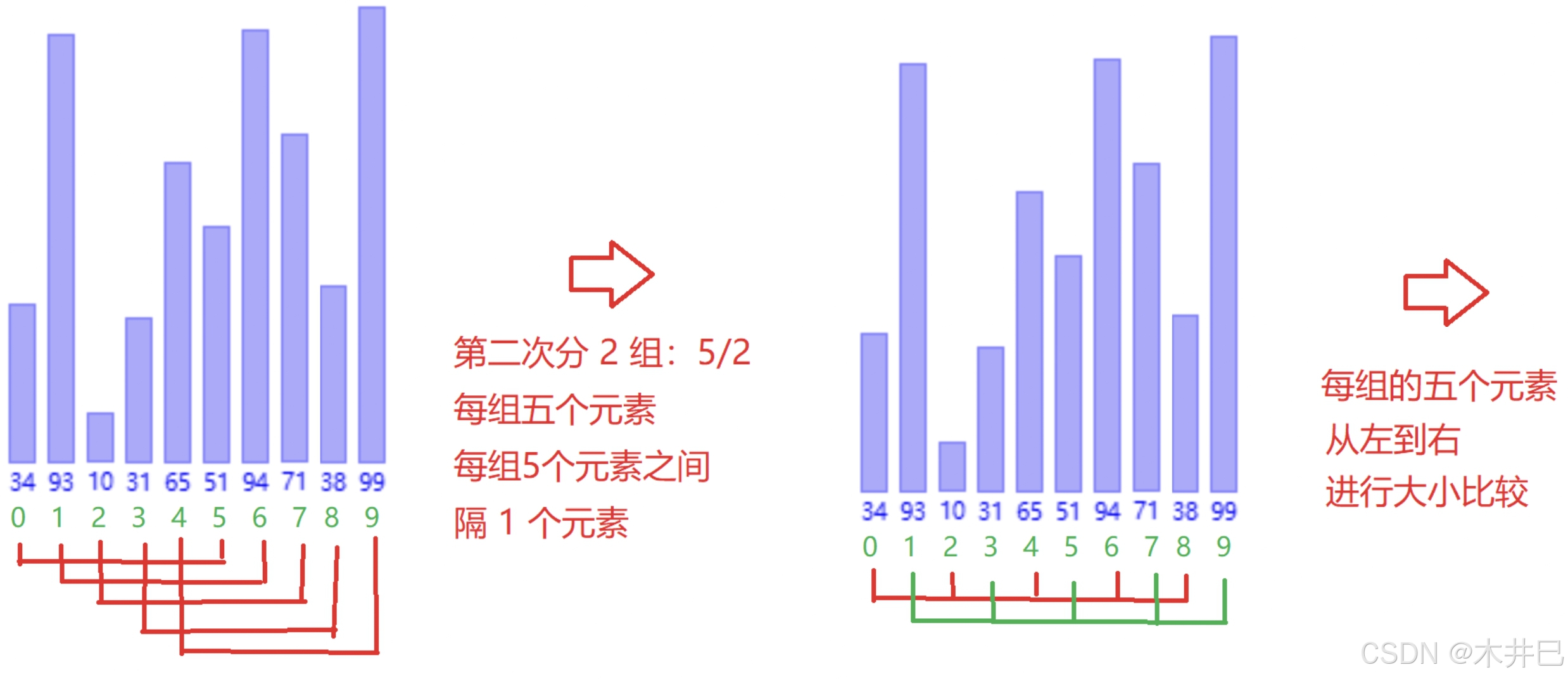
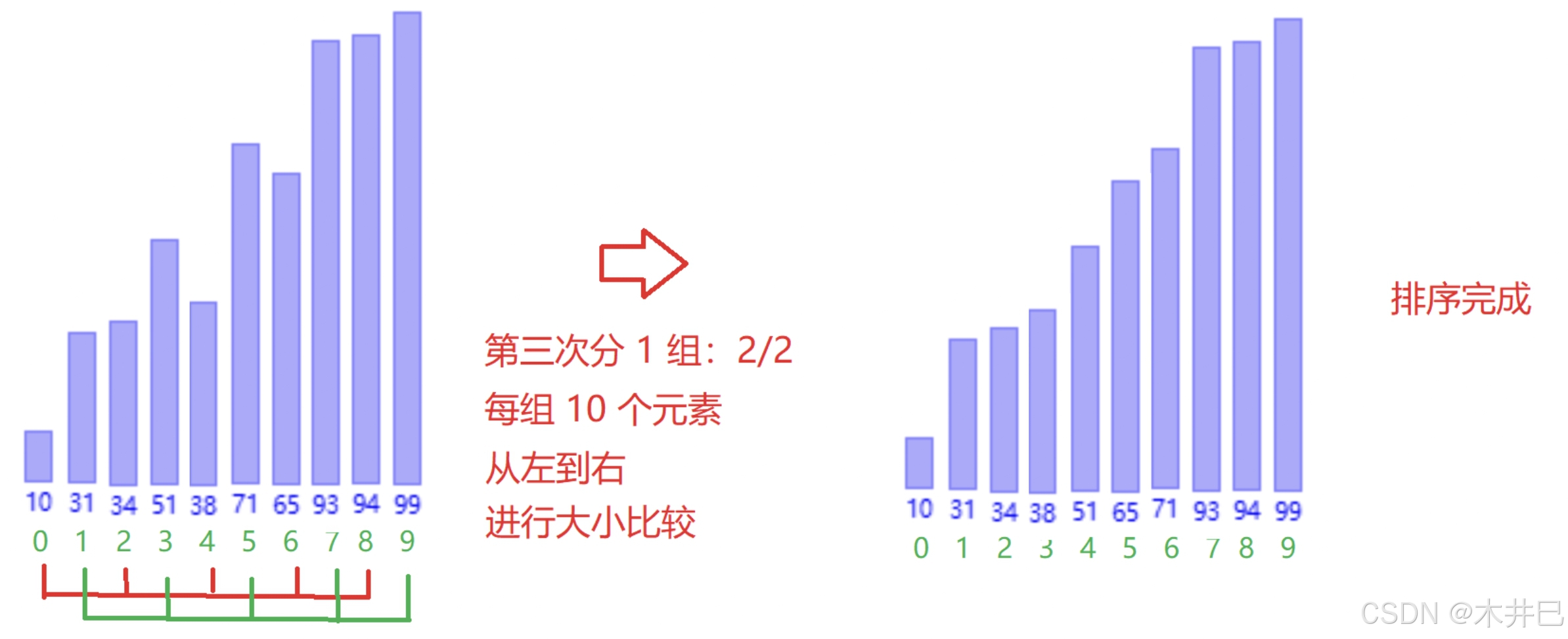
代码实现
java
// 希尔排序
public static void shellSort (int[] arr) {
// 让gap等于数据的长度
int gap = arr.length;
while (gap > 1) {
// 每次按照gap的一半进行分组
gap /= 2;
// 每组进行直接插入排序
shell(arr,gap);
}
}
private static void shell(int[] arr, int gap) {
for (int i = gap; i < arr.length; i++) {
int temp = arr[i];
int j = i - gap;
for (; j >= 0; j -= gap) {
if (arr[j] > temp)
arr[j+gap] = arr[j];
else {
arr[j+gap] = temp;
break;
}
}
arr[j+gap] = temp;
}
}性能分析
- 时间复杂度:约为O(n^1.25)到O(1.6*n^1.25)
- 空间复杂度:O(1)
- 稳定性:不稳定
2.2 选择排序
2.2.1 直接选择排序
算法实现思路
- 遍历数据,第一次默认第一个元素是最小的然后往后面走;当遇到比前面认定最小元素还小的值就记录下标;遍历完数据后再将两个值调换
- 当遍历走完,数据就有序了
图示如下:
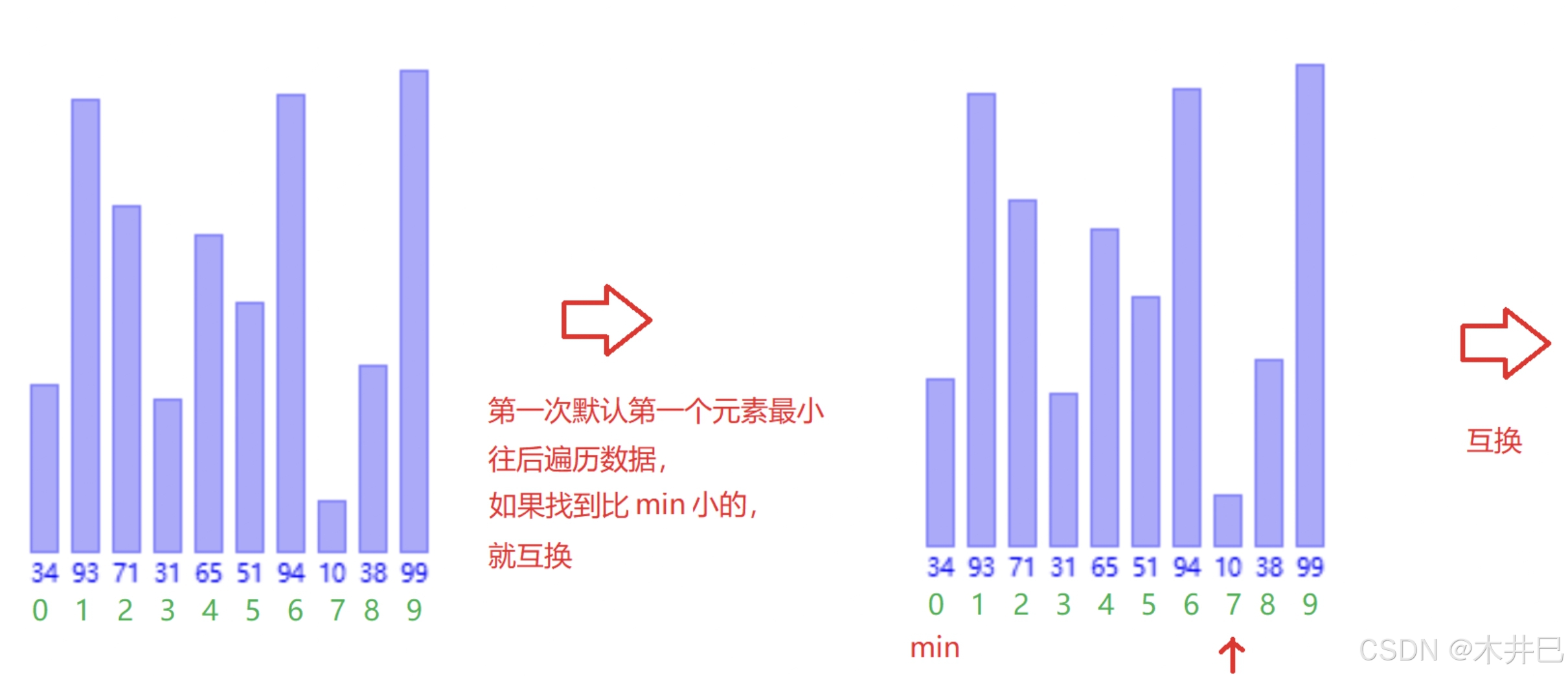
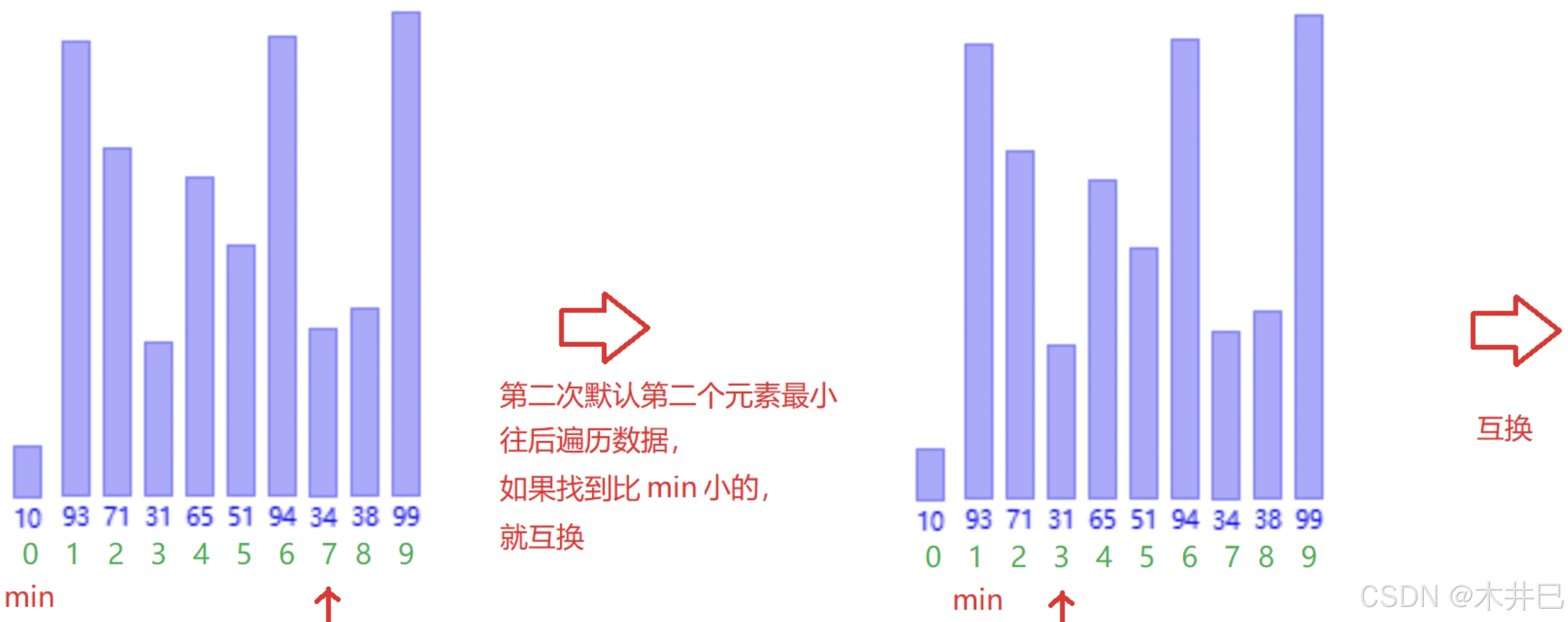
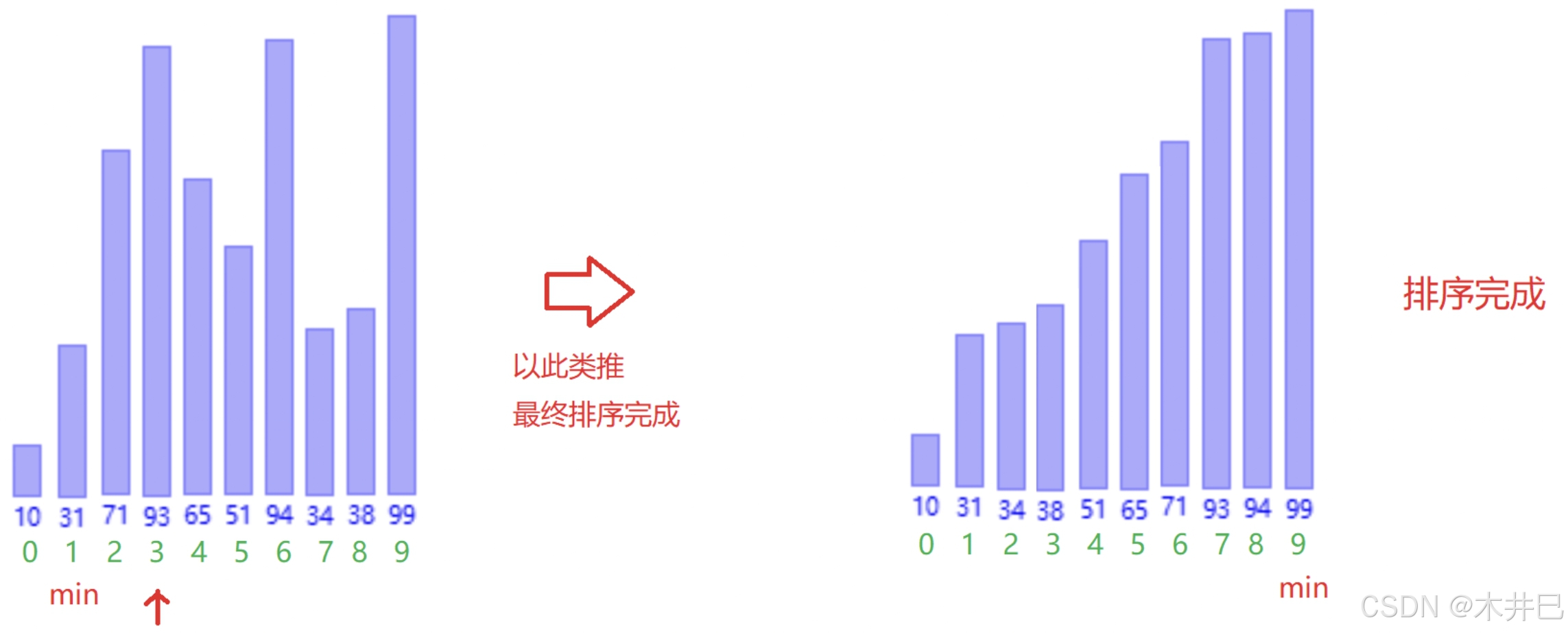
代码实现
java
// 直接选择排序
public static void selectSort2 (int[] arr) {
for (int i = 0; i < arr.length; i++) {
// 默认第i个数据最小
int minIndex = i;
for (int j = i+1; j < arr.length; j++) {
// 进行比较,找到比min还小的数
if (arr[j] < arr[minIndex])
minIndex = j;
}
// 执行到这里时,已经找到/或者没有更小的数
// 进行交换操作
swap(arr,i,minIndex);
}
}性能分析
- 时间复杂度:O(N²) ------ 不管数据本身是否有序,都是O(N²)
- 空间复杂度:O(1)
- 稳定性:不稳定
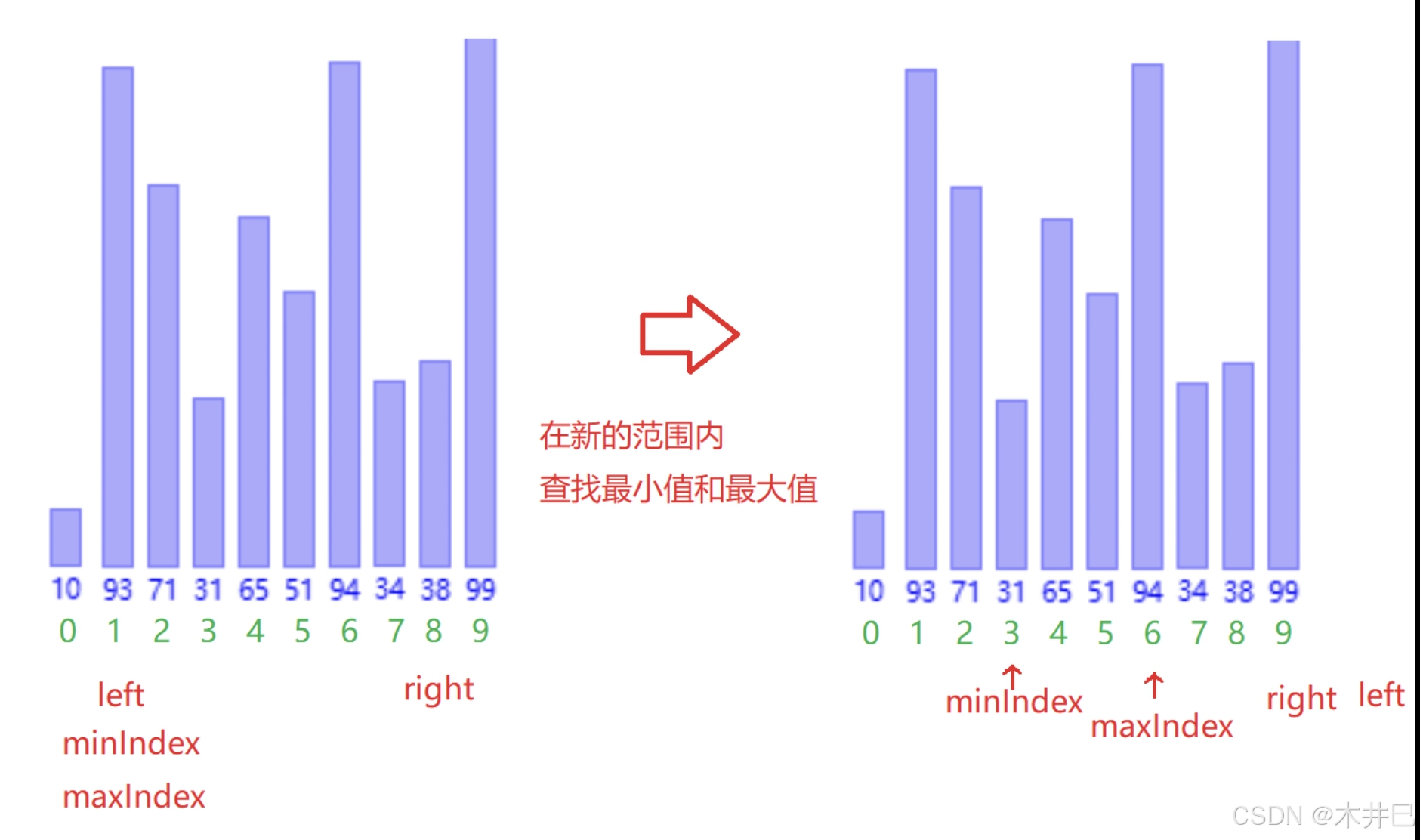
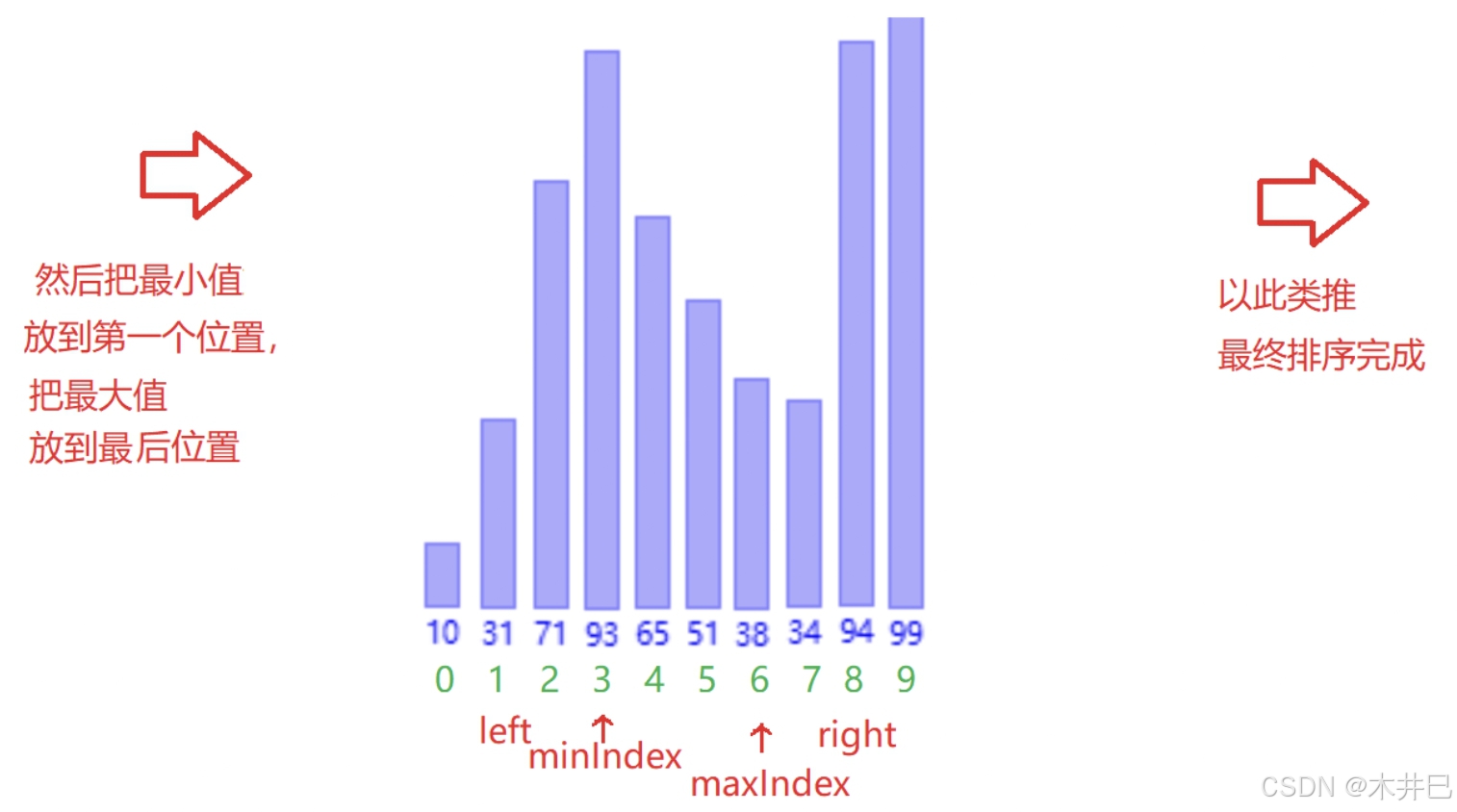
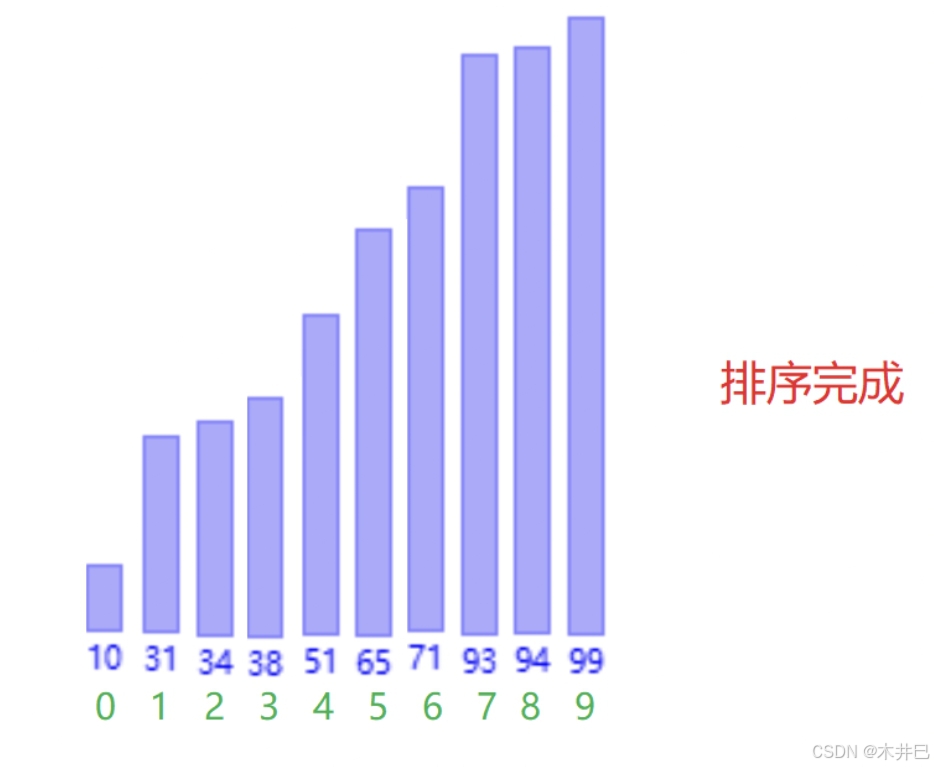
算法优化
- 遍历数据,默认第一个元素(left所在位置的值)是最小值和最大值;往后遍历数据的同时找到数据中的最小值和最
- 大值,并记录到 minlndex 和 maxlndex;然后把最小值放到第一个位置,把最大值放到最
- 后位置
- 注意当数据的第一个数就是最大数时,最大值就变成minlndex了,需要改一下
图示如下:
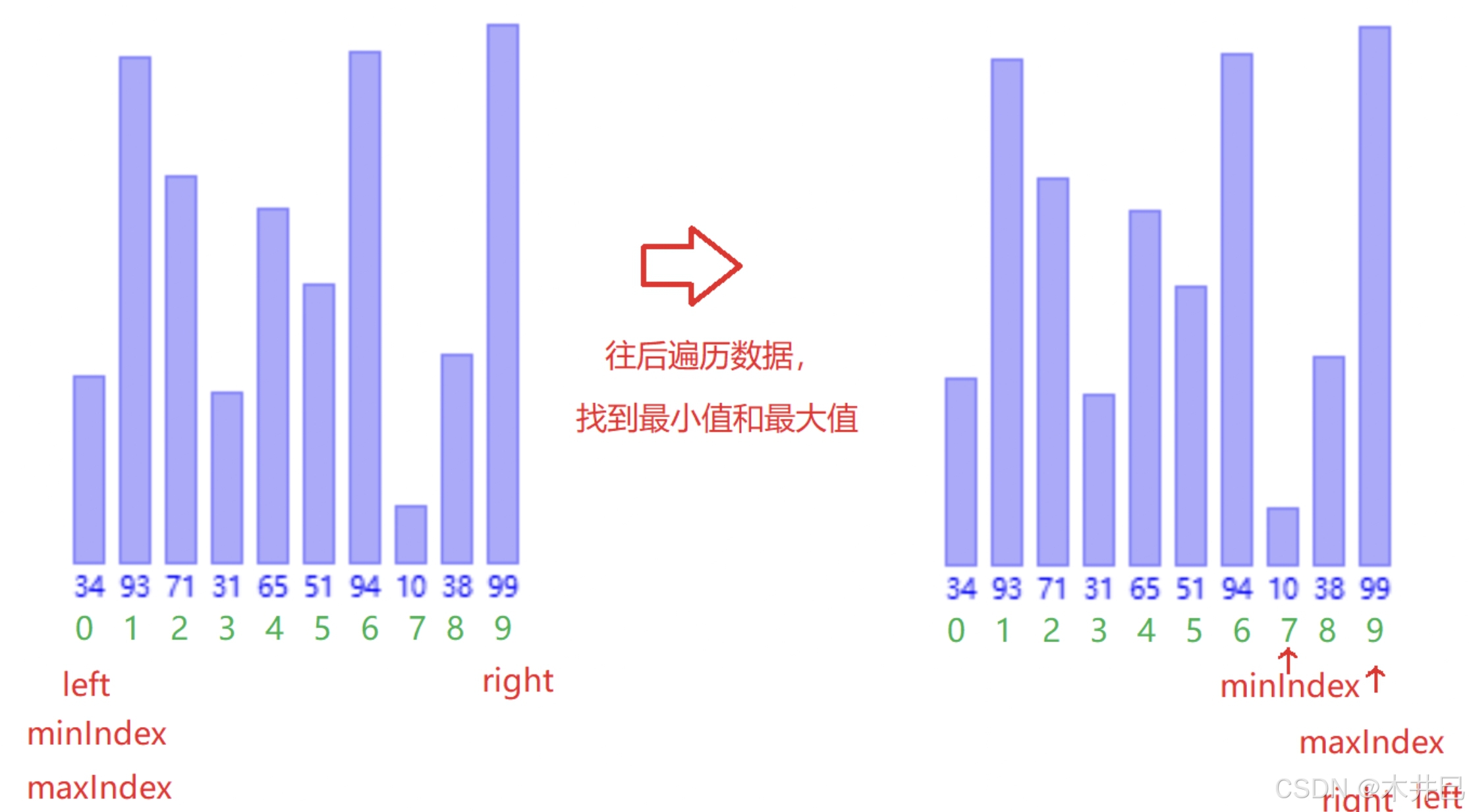
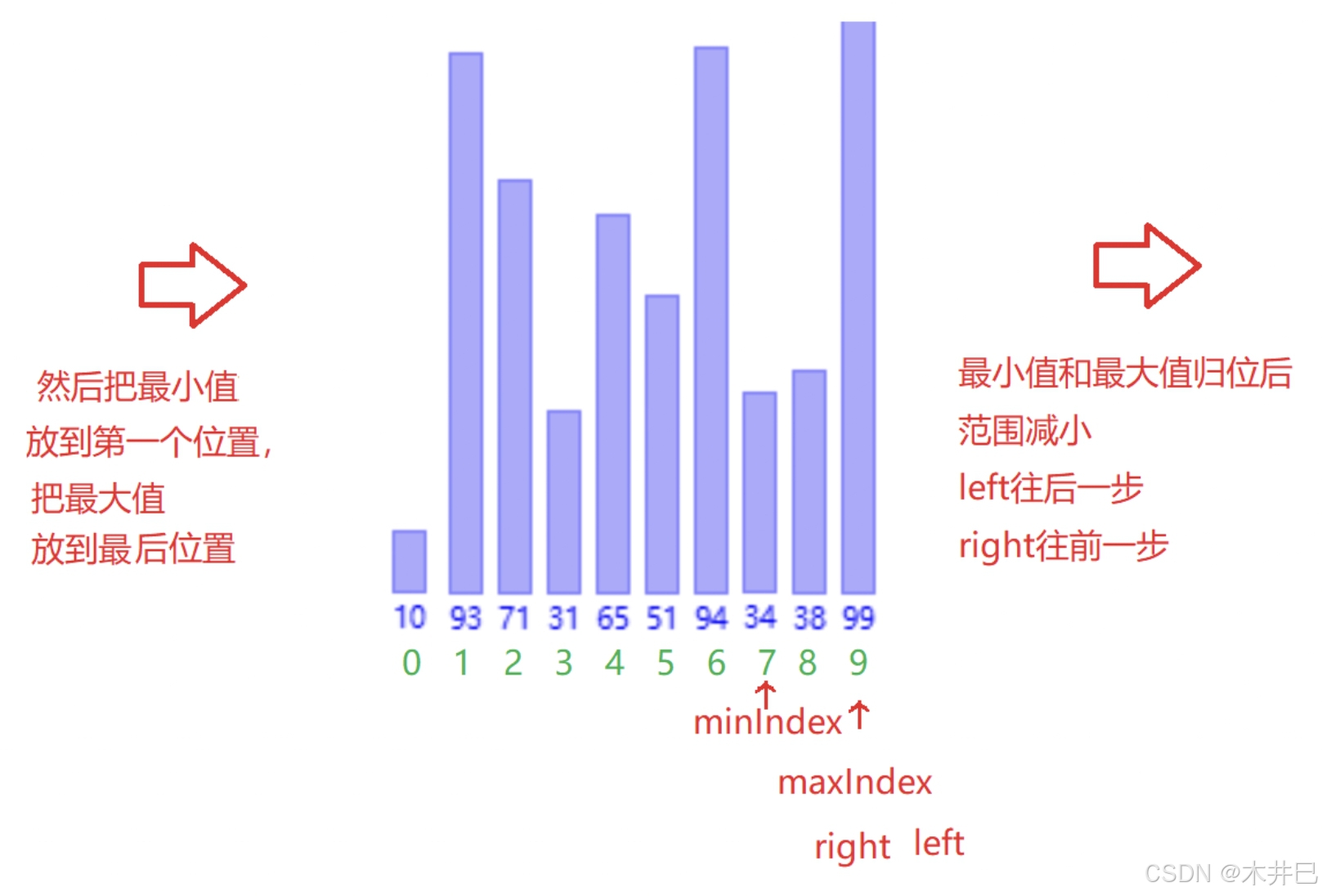
java
// 优化版
public static void selectSort (int[] arr) {
int left = 0;
int right = arr.length - 1;
while (left < right) {
// 默认left所在位置的值是最小值和最大值
int minIndex = left;
int maxIndex = left;
// 找到数据中的最小值和最大值
for (int i = left+1; i <= right; i++) {
if (arr[i] < arr[minIndex])
minIndex = i;
if (arr[i] > arr[maxIndex])
maxIndex = i;
}
// 把最小值放到第一个位置
swap(arr,left,minIndex);
// 当数据的第一个数就是最大值时,由于先换了最小值,所以此时第一个数在minIndex位置
if (maxIndex == left)
maxIndex = minIndex;
// 把最大值放到最后位置
swap(arr,right,maxIndex);
left++;
right--;
}
}2.2.2 堆排序
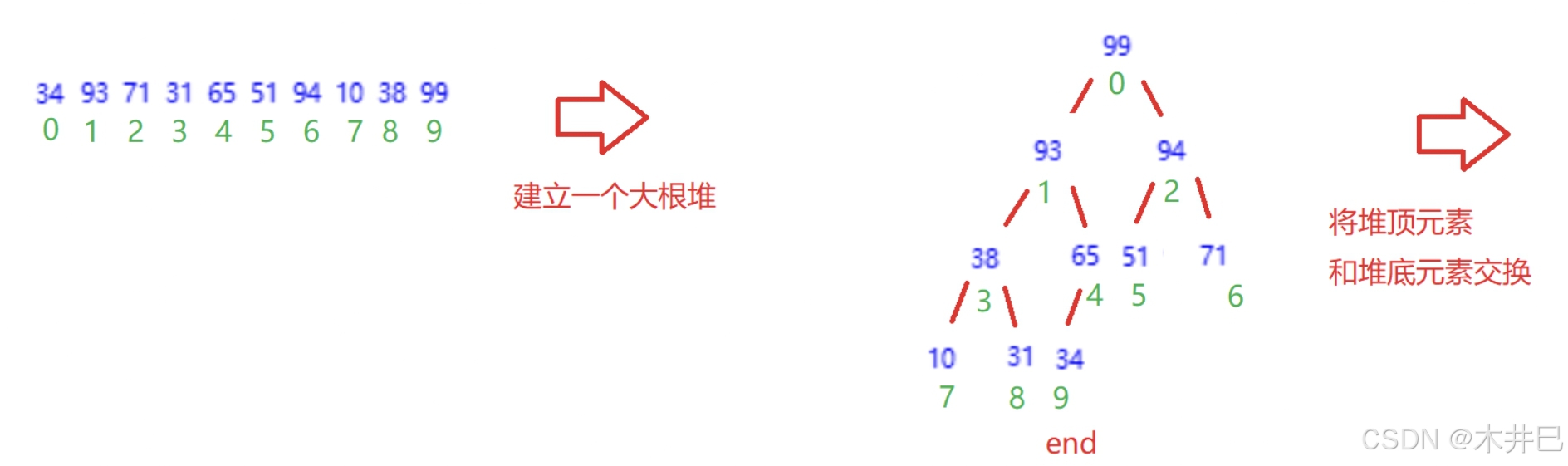
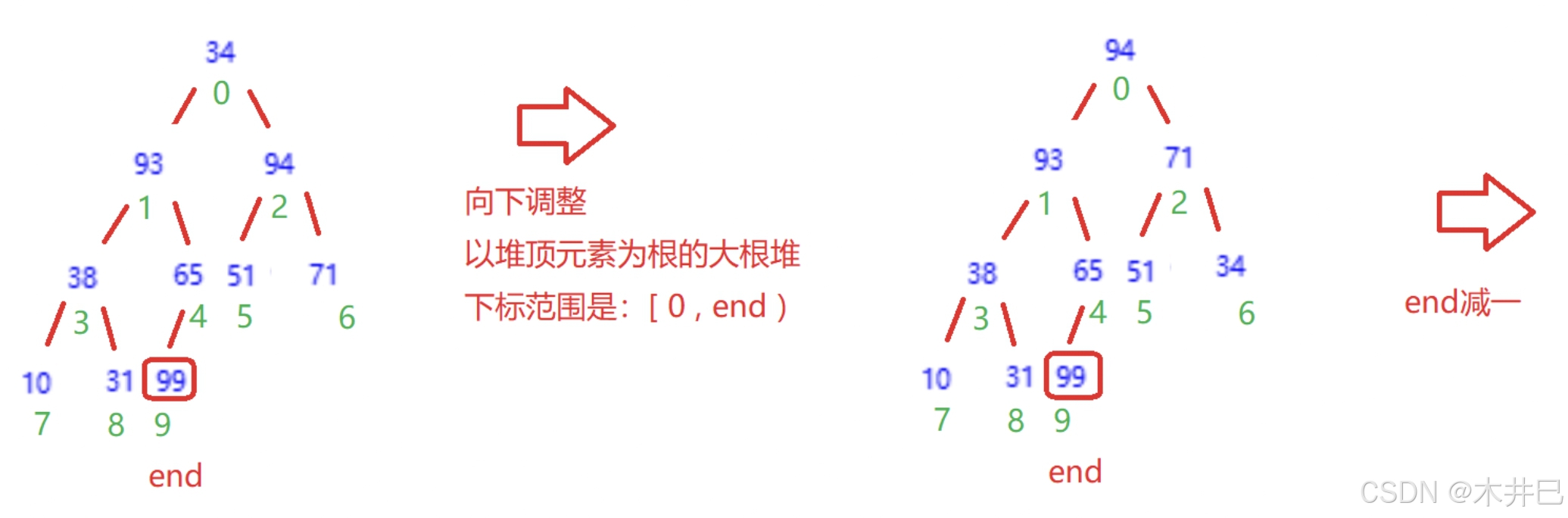
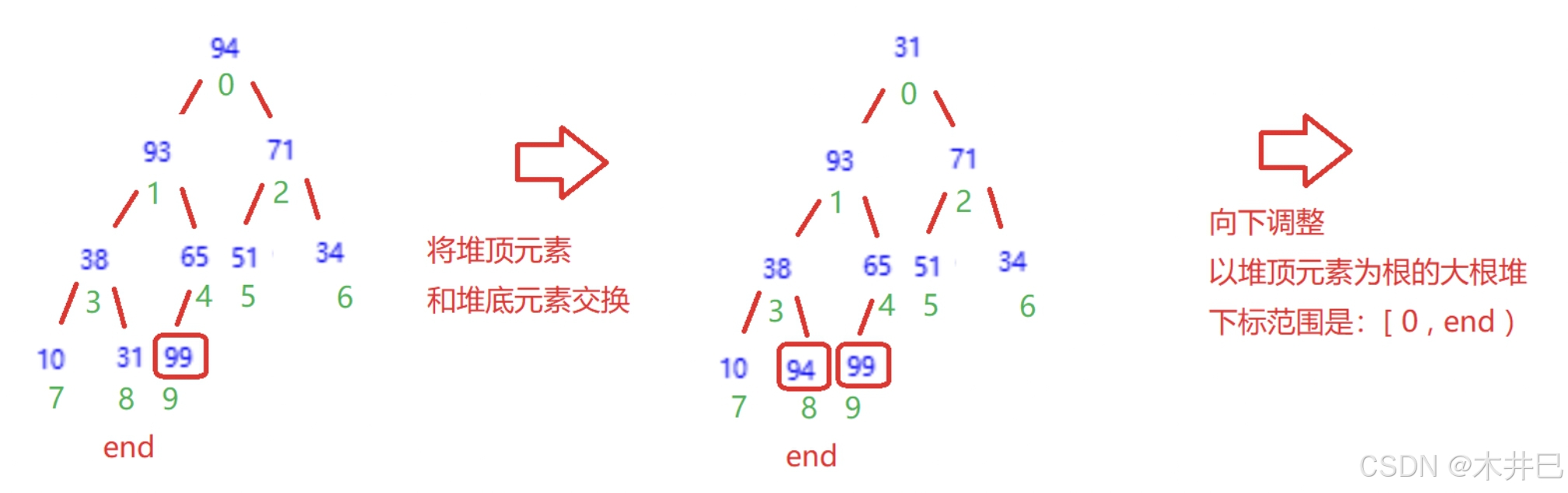
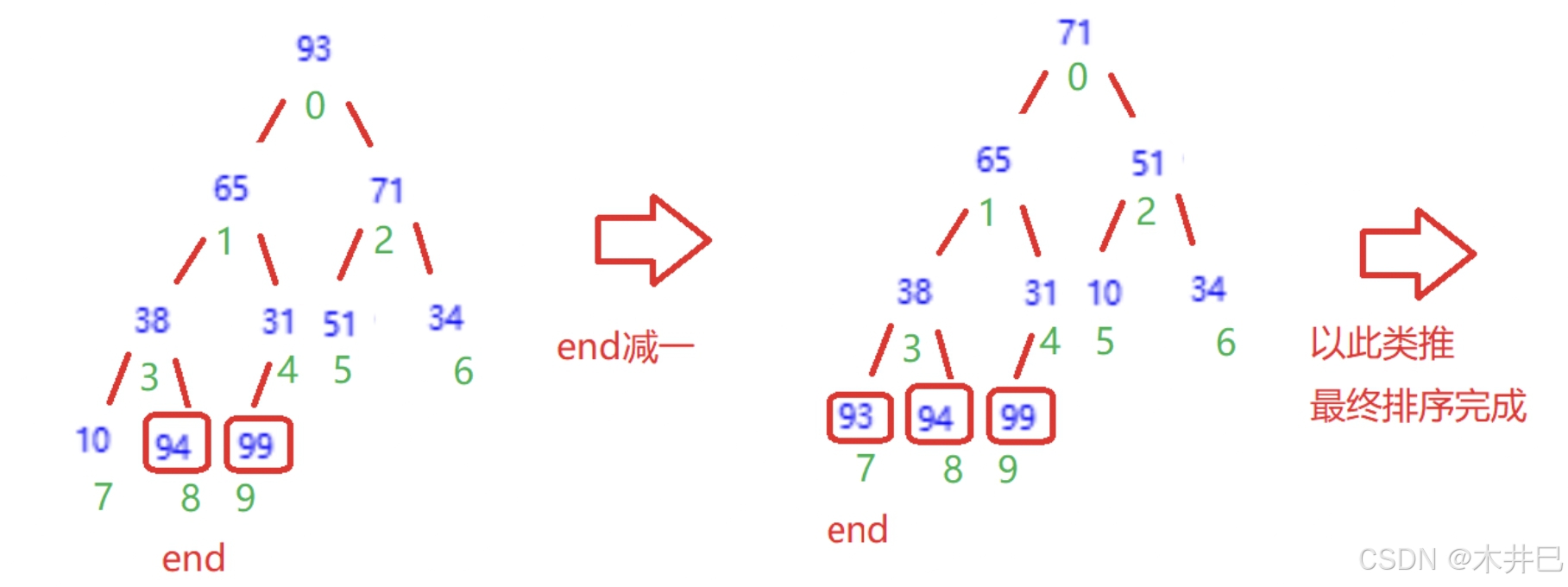
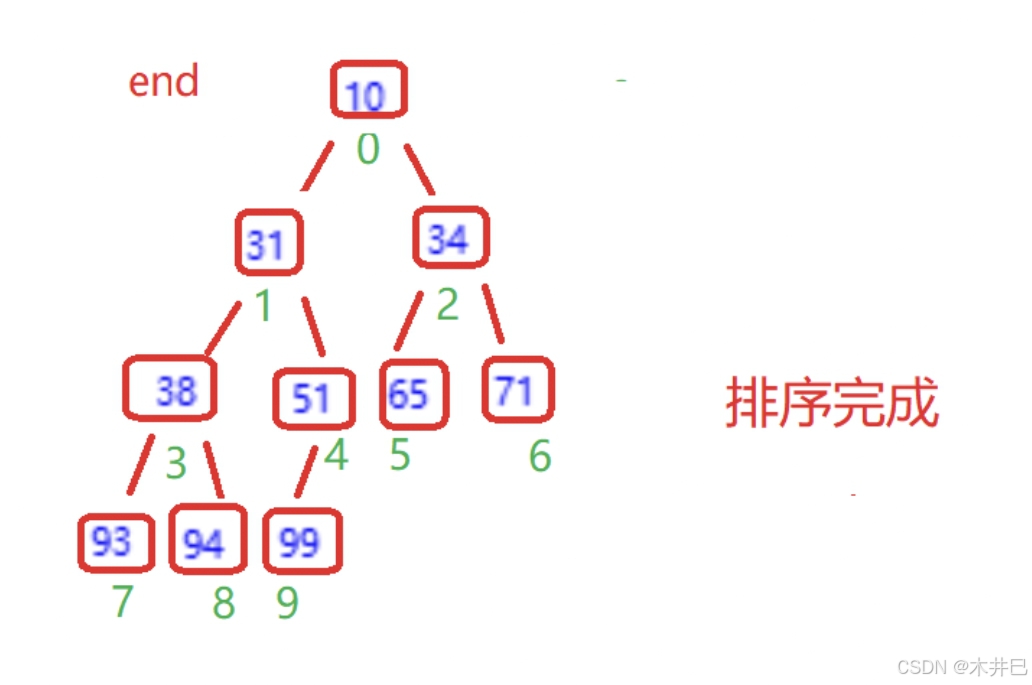
算法实现思路
- 升序(从小到大)------> 建立大根堆
- 降序 (从大到小) ------> 建立小根堆
升序为例:
- 将堆顶元素(即下标为0的元素)和堆底元素end交换
- 向下调整,每一次调整end都要减一,堆从后往前就逐渐由大到小排序了
- 当end大于0时才进行以上操作,否则结束循环
图示如下:
代码实现
java
// 堆排序
public static void heapSort (int[] arr) {
// 创建堆
createHeap(arr);
// 标记的最后元素的位置,每一次调整后都要减一
int end = arr.length - 1;
while (end > 0) {
// 将第一个元素和最后元素交换
swap(arr,0,end);
// 向下调整以第一个元素为堆顶的堆
shiftDown(arr,0,end);
// 标记最后元素位置的end自减1
end--;
}
}
private static void createHeap(int[] arr) {
for (int parent = (arr.length-2)/2; parent >= 0; parent--) {
// 向下调整建堆
shiftDown(arr,parent,arr.length);
}
}
private static void shiftDown(int[] arr, int parent, int length) {
// param: 目标数据 起始范围 结束范围
int child = parent * 2 + 1;
while (child < length) {
// 找到较大的数:确保下标位置合法
if ((child+1)<length && arr[child]<arr[child+1]) {
child++;
}
// 与parent的值比较
if (arr[child] > arr[parent]) {
swap(arr,child,parent);
// 往子树走
parent = child;
child = parent * 2 + 1;
} else {
break;
}
}
}性能分析
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
2.3 交换排序
2.3.1 冒泡排序
算法实现思路
- 第一次从数组的第一个元素开始遍历数据直到最后,两两与相邻的元素比较大小;
- 第二次遍历数据直到倒数第二个元素,因为最后元素已经在第一趟排好位置了
- 循环此操作就可得到升序的数据
图示如下:
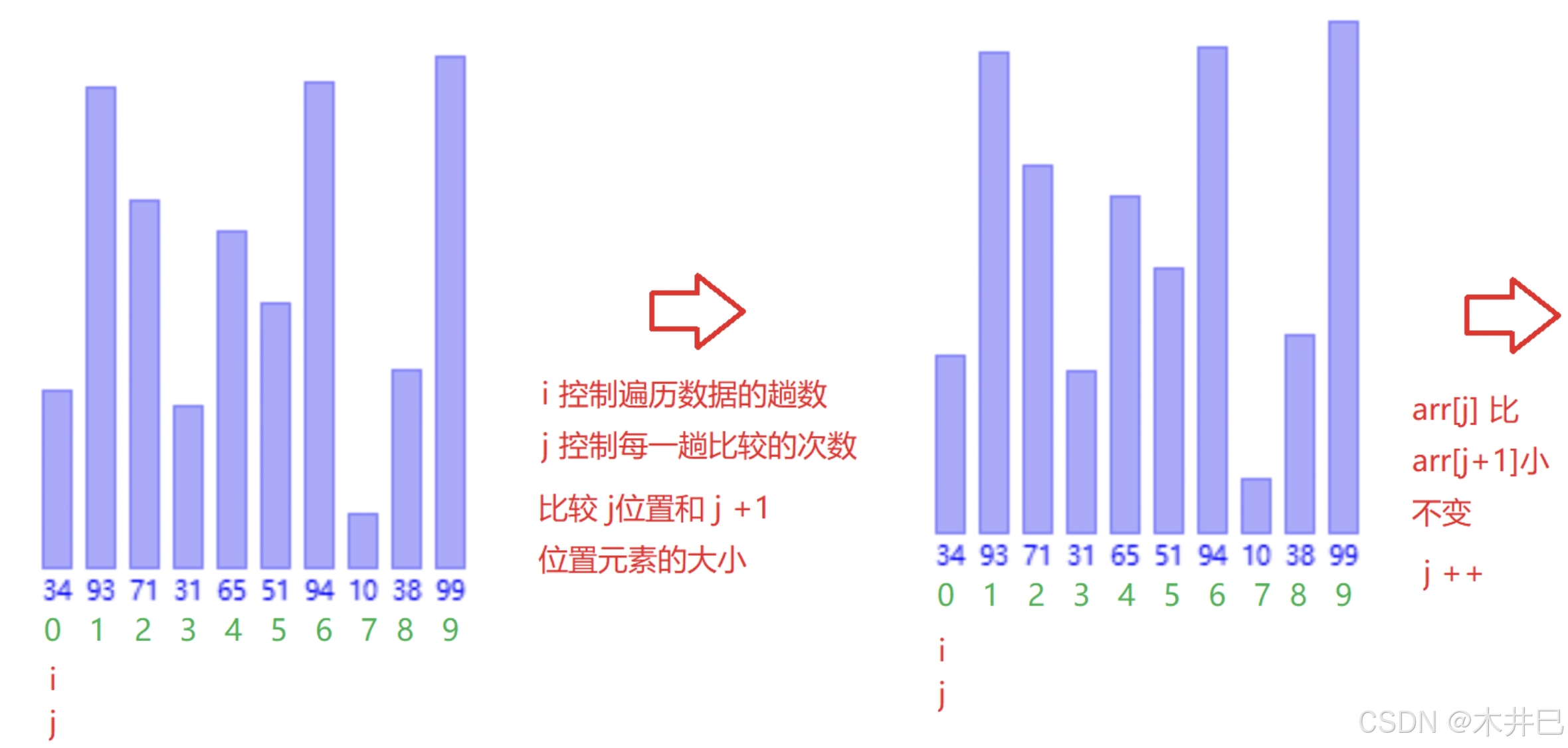
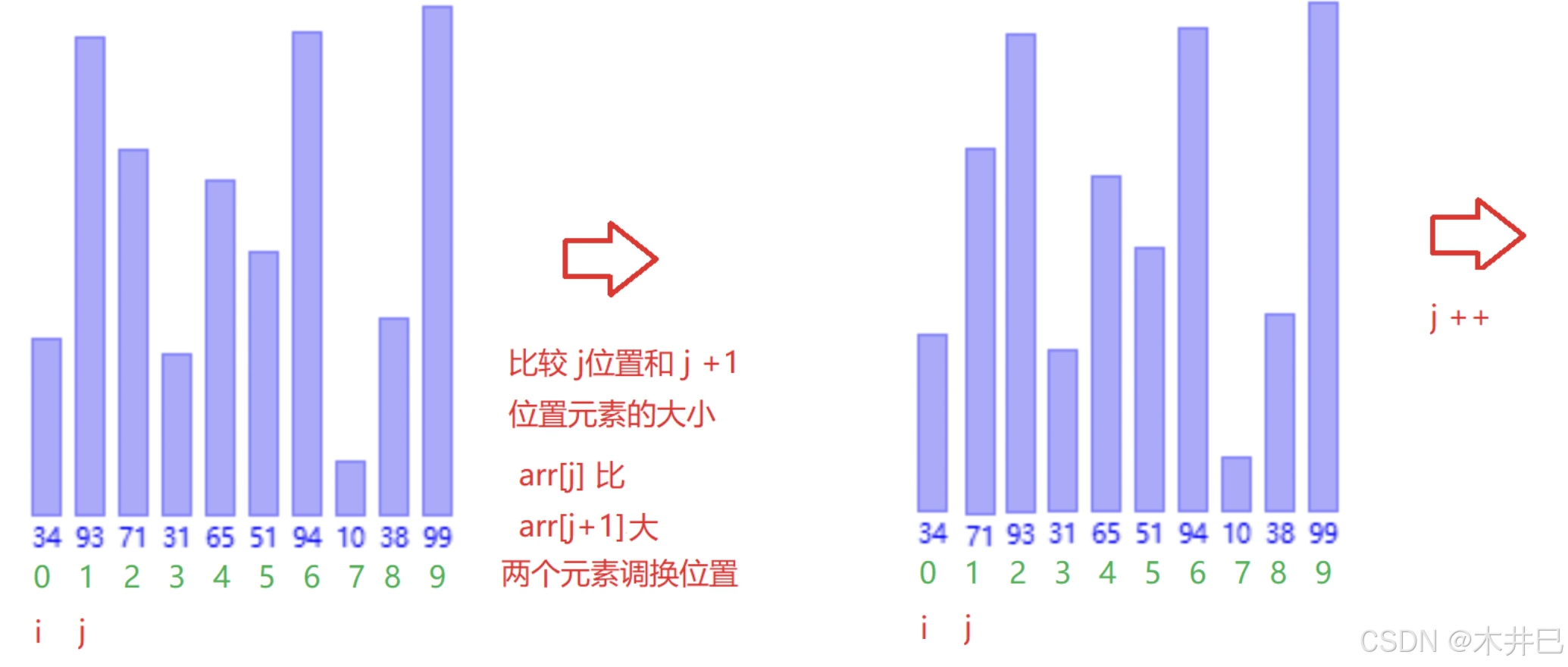
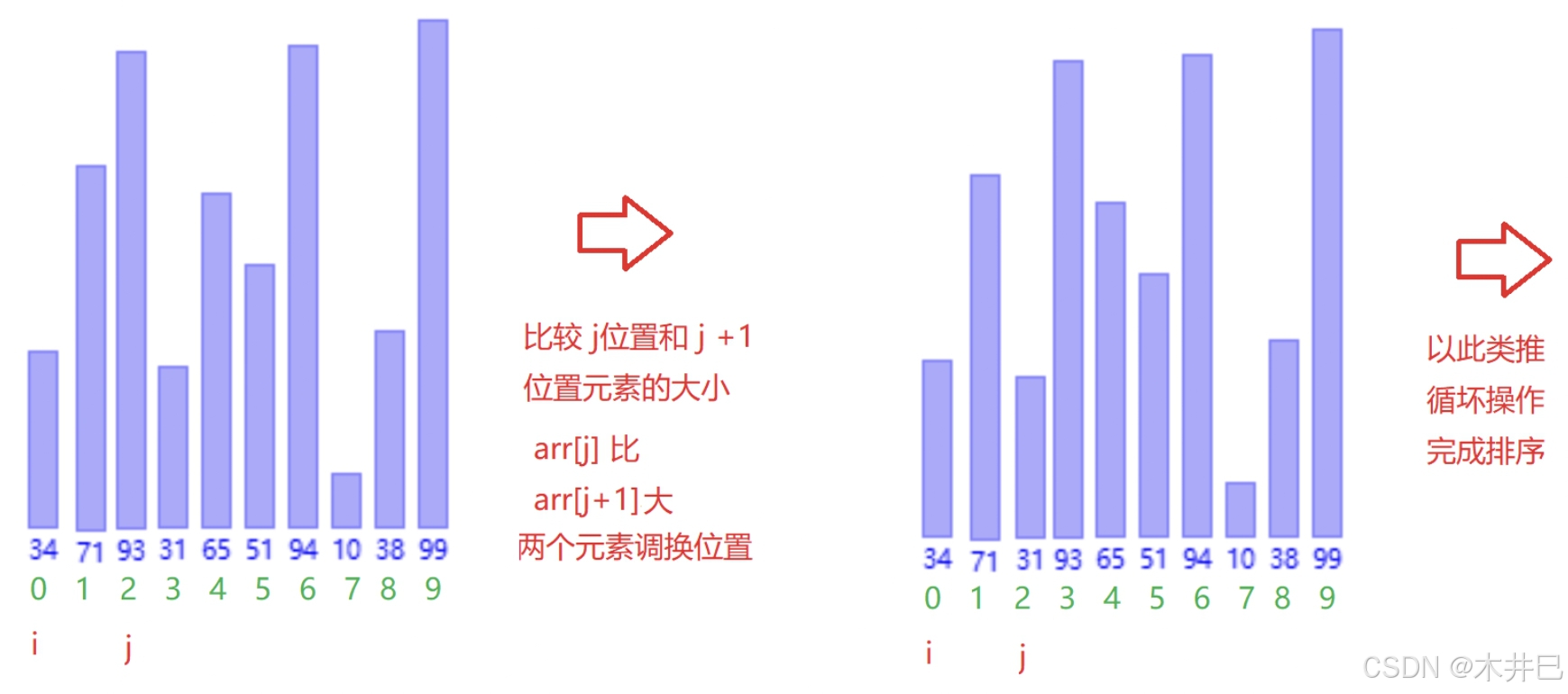
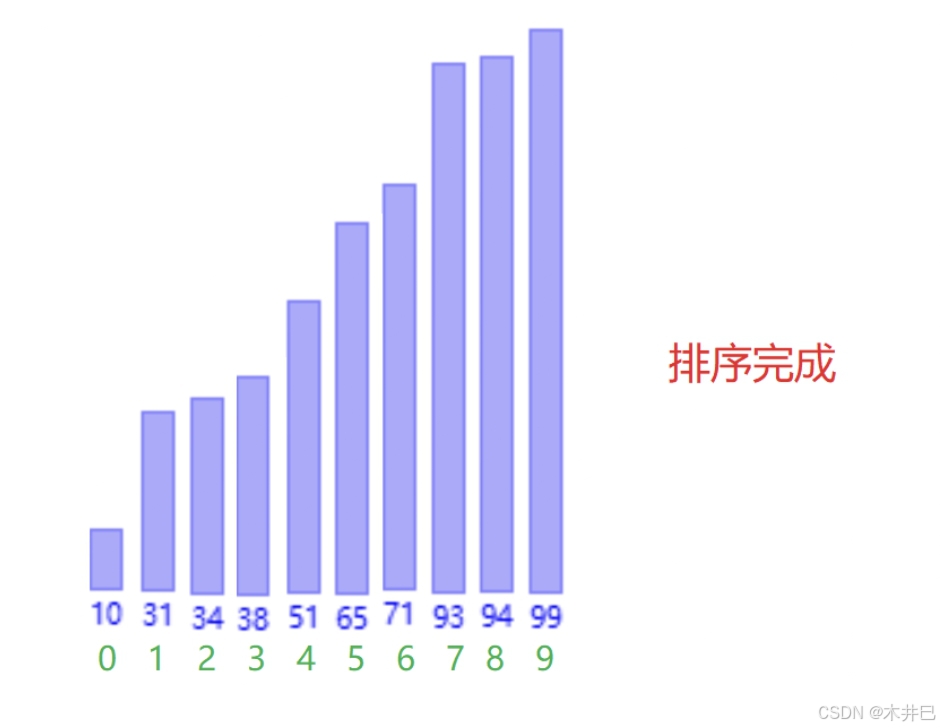
代码实现
java
// 冒泡排序
public static void bubbleSort2 (int[] arr) {
// i控制比较的趟数
for (int i = 0; i < arr.length-1; i++) {
// j控制每一趟比较的次数
for (int j = 0; j < arr.length-1-i; j++) {
if (arr[j] > arr[j+1]) {
swap(arr,j,j+1);
}
}
}
}性能分析
- 时间复杂度:O(N²) ------> 优化以后可能达到O(N)
- 空间复杂度:O(1)
- 稳定性:稳定
算法优化
- 使用一个布尔变量,当数据交换一次就标记
- 若数据本身有序就可以避免多次遍历和比较了
java
// 优化版
public static void bubbleSort (int[] arr) {
// i控制比较的趟数
for (int i = 0; i < arr.length-1; i++) {
// 每一次排序时都默认标记有序,表示数据是有序的
boolean isOrder = true;
// j控制每一趟比较的次数
for (int j = 0; j < arr.length-1-i; j++) {
if (arr[j] > arr[j+1]) {
swap(arr,j,j+1);
// 一旦交换一次,就改变标记,表示数据是无序的
isOrder = false;
}
}
// 若标记始终有序,就直接退出比较
if (isOrder) {
break;
}
}
}2.3.2 快速排序
算法实现思路
- 采用分治策略,选取一个基准值,将序列划分成左右两部分:左边均小于基准值,右边均大于基准值
- 然后递归处理左右子序列
有三种划分方法:
- Hoare法:左右指针向中间扫描
- 挖坑法:将基准值保存,形成坑位
- 前后指针法:使用前后两个指针进行划分
小编在这里逐一配图来给读者解析
Hoare法
- 使用两个引用(left和right) 分别从前后往中间遍历数据;以数据第一个元素为基准,从后查找比该元素小的数,从前查找比该元素大的数然后交换这两个数;当两个引用相遇时把基准与相遇时位置(pivot)的值进行交换,该位置的左边全是比它小的数,右边全是比它大的数
- 接着开始递归遍历以相遇点位置(pivot)为根的二叉树,每一棵子树都重复 找基准值并划分 的操作,直到遍历完全部数据
图示如下:







代码实现
java
// hoare法
public static void quickSortHoare (int[] arr) {
quickHoare(arr,0,arr.length-1);
}
private static void quickHoare(int[] arr, int start, int end) {
// 当范围不合法就退出
if (start >= end)
return;
// 将数据以基准值划分
int pivot = patitionHoare(arr,start,end);
// 递归
quickHoare(arr,start,pivot-1);
quickHoare(arr,pivot+1,end);
}
private static int patitionHoare (int[] arr, int left, int right) {
// 基准值
int base = arr[left];
int baseIndex = left;
// 当两个引用还没相遇时进行操作
while (left < right) {
// 若值没有基准值小
if (left<right && arr[right]>=base) {
right--;
}
// 若值没有基准值大
if (left<right && arr[left]<=base) {
left++;
}
// 交换min和max的值
swap(arr,left,right);
}
// 当两个引用相遇时,将基准值与相遇位置的值交换
swap(arr,baseIndex,left);
return left;
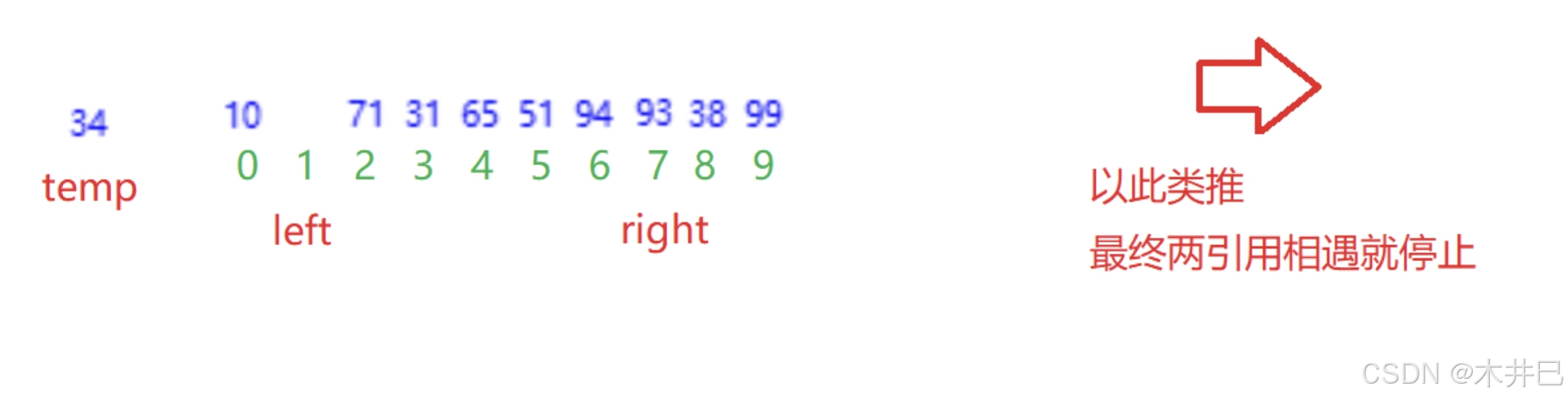
}Δ挖坑法
- 与Hoare法不同的是:先暂时存储基准值于临时变量temp, 当从后遍历的引用 right 找到数后,直接将其与从前遍历的引用 left 所在位置的数交换;
- 当从前遍历的引用 left 找到数后,将其放到从后遍历的引用 right 所在位置;
- 当两个引用相遇,把基准值放到相遇位置(pivot)
图示如下:



代码实现
java
// 挖坑法
private static int patition (int[] arr, int left, int right) {
// 把基准值暂存至temp
int temp = arr[left];
// 当两个引用还没相遇时进行操作
while (left < right) {
// 若值没有基准值小
while (left<right && arr[right]>=temp) {
right--;
}
// 将最小的数放到left位置
arr[left] = arr[right];
// 若值没有基准值大
while (left<right && arr[left]<=temp) {
left++;
}
// 将最大的数放到right位置
arr[right] = arr[left];
}
// 当两个引用相遇时,将基准值放到相遇位置
arr[left] = temp;
return left;
}前后指针法
- 使用两个引用(prev和cur) 从前往后遍历数据。保证 prev 位置的值都是比基准值小的数:当cur位置的值比基准数小并且cur和prev+1不在同一位置,就将两个位置的值进行交换
- 当cur遍历完数据,将prev位置的值与基准值交换
图示如下:





代码实现
java
// 前后指针法
private static int patitionPCPtr (int[] arr, int left, int right) {
// 定义两个引用
int prev = left;
int cur = left + 1;
// 合法范围内进行操作
while (cur <= right) {
// 找到比基准值大的数
if (arr[cur]<arr[left] && arr[++prev]!=arr[cur]) {
swap(arr,prev,cur);
}
cur++;
}
// 将prev的值和基准值交换
swap(arr,prev,left);
return prev;
}性能分析
- 时间复杂度:最好情况O(N*logN) 最坏情况O(N2)
- 空间复杂度:最好情况O(logN) 最坏情况O(N)
- 稳定性:不稳定
算法优化
由于快速排序是递归进行的,当数据量过大时,不断递归可能会导致栈溢出。
因此,需要优化递归------减少递归的次数。
有两种方法可以减少递归的次数:
- 三数取中法:找到left和right值的中位数,然后以中位数作为基准值,目的是减少单分支递归
- 直接插入法 (针对一定范围):对二叉树的后两层(小区间)使用插入排序而不使用递归
三数取中法:
- 分两种大情况:start < end ; start > end
- 每一种大情况又分为三种小情况:mid < start/end < end/start ; start/end< mid < end/start; start/end < end/start < mid
如图:
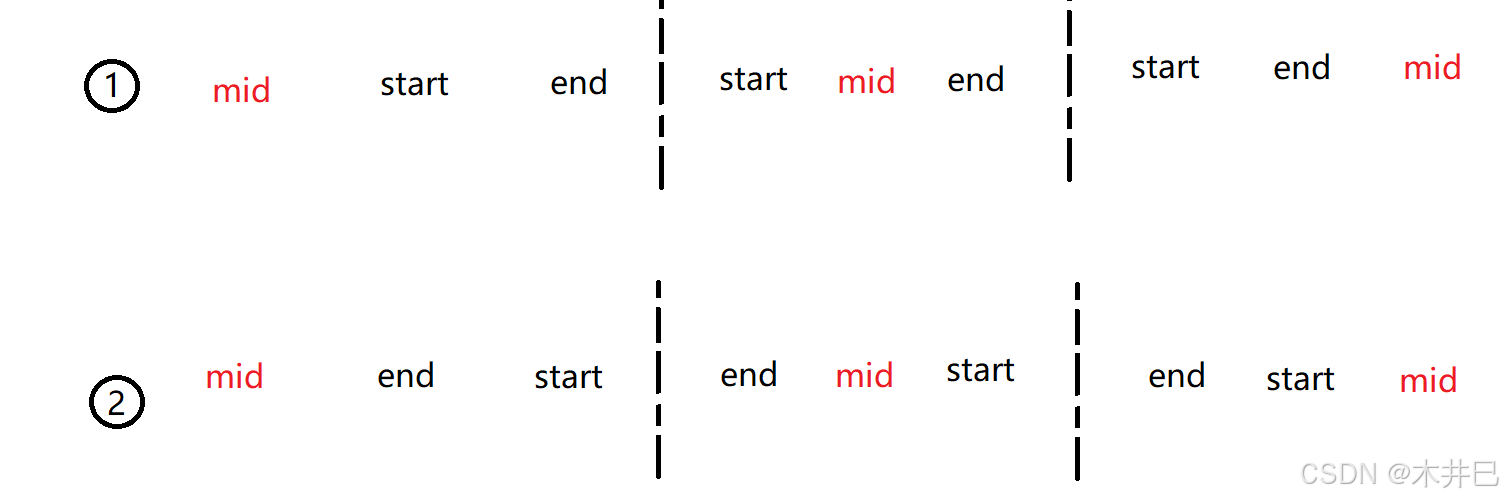
优化后的完整快速排序算法:
java
public static void quickSort (int[] arr) {
quick(arr,0,arr.length-1);
}
private static void quick(int[] arr, int start, int end) {
// 当范围不合法就退出
if (start >= end)
return;
// 递归到小范围的数据时,使用直接插入排序,减少递归的次数
if (end-start+1 <= 7) {
insertSortRange(arr,start,end);
return;
}
// 三数取中找中位数并以中位数位基准值
int midIndex = getMiddleNum(arr,start,end);
swap(arr,start,midIndex);
// 将数据以基准值划分
int pivot = patition(arr,start,end);
// 递归
quick(arr,start,pivot-1);
quick(arr,pivot+1,end);
}
private static int patition (int[] arr, int left, int right) {
// 把基准值暂存至temp
int temp = arr[left];
// 当两个引用还没相遇时进行操作
while (left < right) {
// 若值没有基准值小
while (left<right && arr[right]>=temp) {
right--;
}
// 将最小的数放到left位置
arr[left] = arr[right];
// 若值没有基准值大
while (left<right && arr[left]<=temp) {
left++;
}
// 将最大的数放到right位置
arr[right] = arr[left];
}
// 当两个引用相遇时,将基准值放到相遇位置
arr[left] = temp;
return left;
}
// 三数取中法
private static int getMiddleNum(int[] arr, int start, int end) {
int mid = (start + end) / 2;
if (arr[start] < arr[end]) {
if (arr[mid] < arr[start]) {
return start;
} else if (arr[mid] > arr[end]) {
return end;
} else {
return mid;
}
} else {
if (arr[mid] > arr[start]) {
return start;
} else if (arr[mid] < arr[end]) {
return end;
} else {
return mid;
}
}
}
// 直接插入法(针对一定范围)
private static void insertSortRange (int[] arr, int start, int end) {
for (int i = start+1; i <= end; i++) {
int temp = arr[i];
int j = i - 1;
for (; j >= start; j--) {
if (arr[j] > temp)
arr[j+1] = arr[j];
else {
arr[j+1] = temp;
break;
}
}
arr[j+1] = temp;
}
}非递归实现快速排序
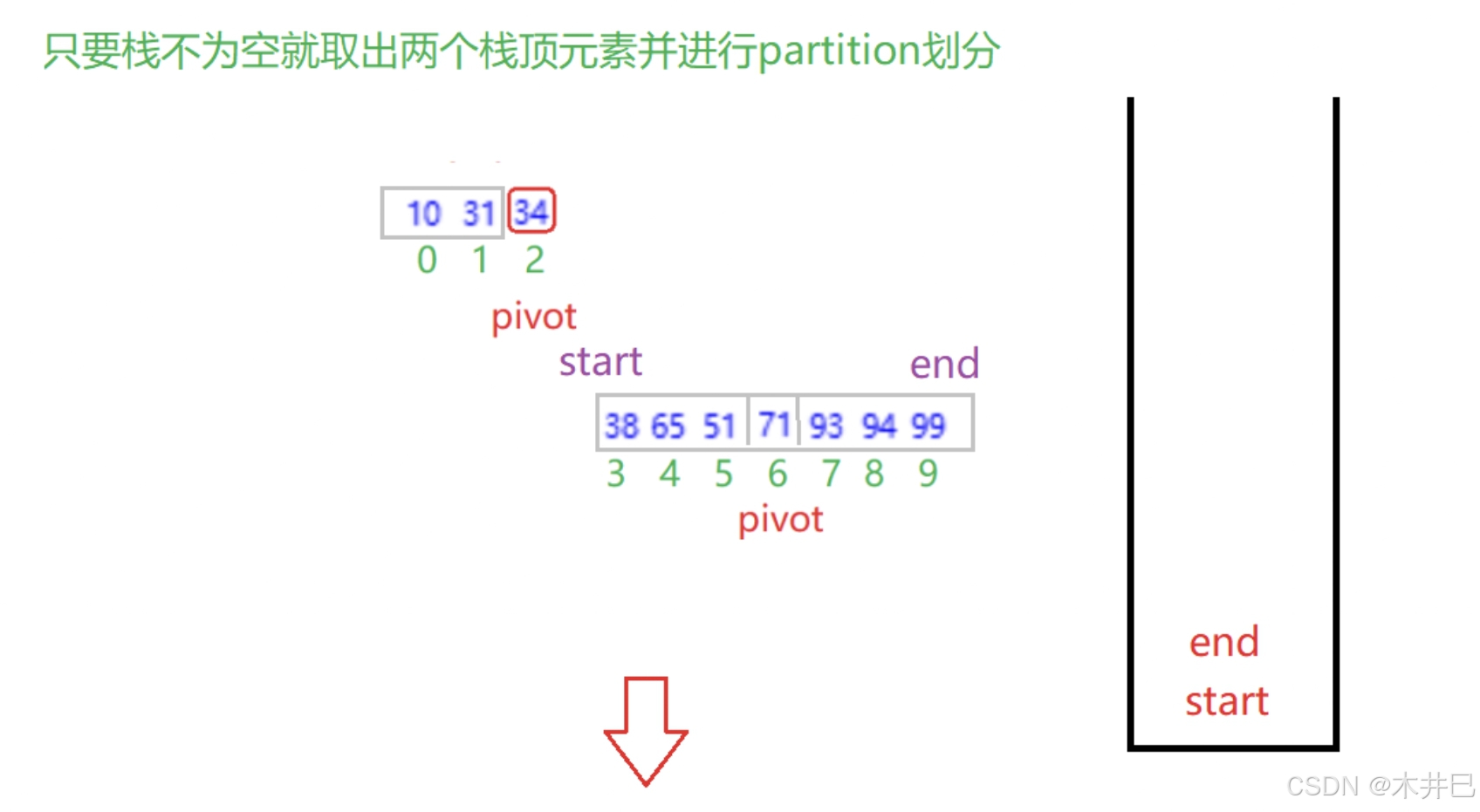
算法实现思路
- 以 基准值 为界划分数组之后,把 pivot 左边部分的 start 和 end 压入栈中(当pivot>start+1),再压右边部分的(当pivot<end-1)
- 只要栈不为空就取出两个栈顶元素并进行partition划分
图示如下:


代码实现
java
// 非递归快速排序
public static void quickSortNonTra (int[] arr) {
quickNonTra(arr,0,arr.length-1);
}
private static void quickNonTra(int[] arr, int start, int end) {
Stack<Integer> stack = new Stack<>();
// 找到基准值
int pivot = patition(arr,start,end);
// 若基准值的左边/右边至少有两个元素,就需要排序,故入栈
if (pivot > start+1) {
stack.push(start);
stack.push(pivot-1);
}
if (pivot < end-1) {
stack.push(pivot+1);
stack.push(end);
}
// 当栈不为空就持续排序
while (!stack.isEmpty()) {
// 弹出的第一个元素是end,第二个元素是start
end = stack.pop();
start = stack.pop();
// 找到基准值
pivot = patition(arr,start,end);
// 若基准值的左边/右边至少有两个元素,就需要排序,故入栈
if (pivot > start+1) {
stack.push(start);
stack.push(pivot-1);
}
if (pivot < end-1) {
stack.push(pivot+1);
stack.push(end);
}
}
}2.4 归并排序
算法实现思路
- 先递归分解
- 再合并:合并两个有序数组
图示如下:



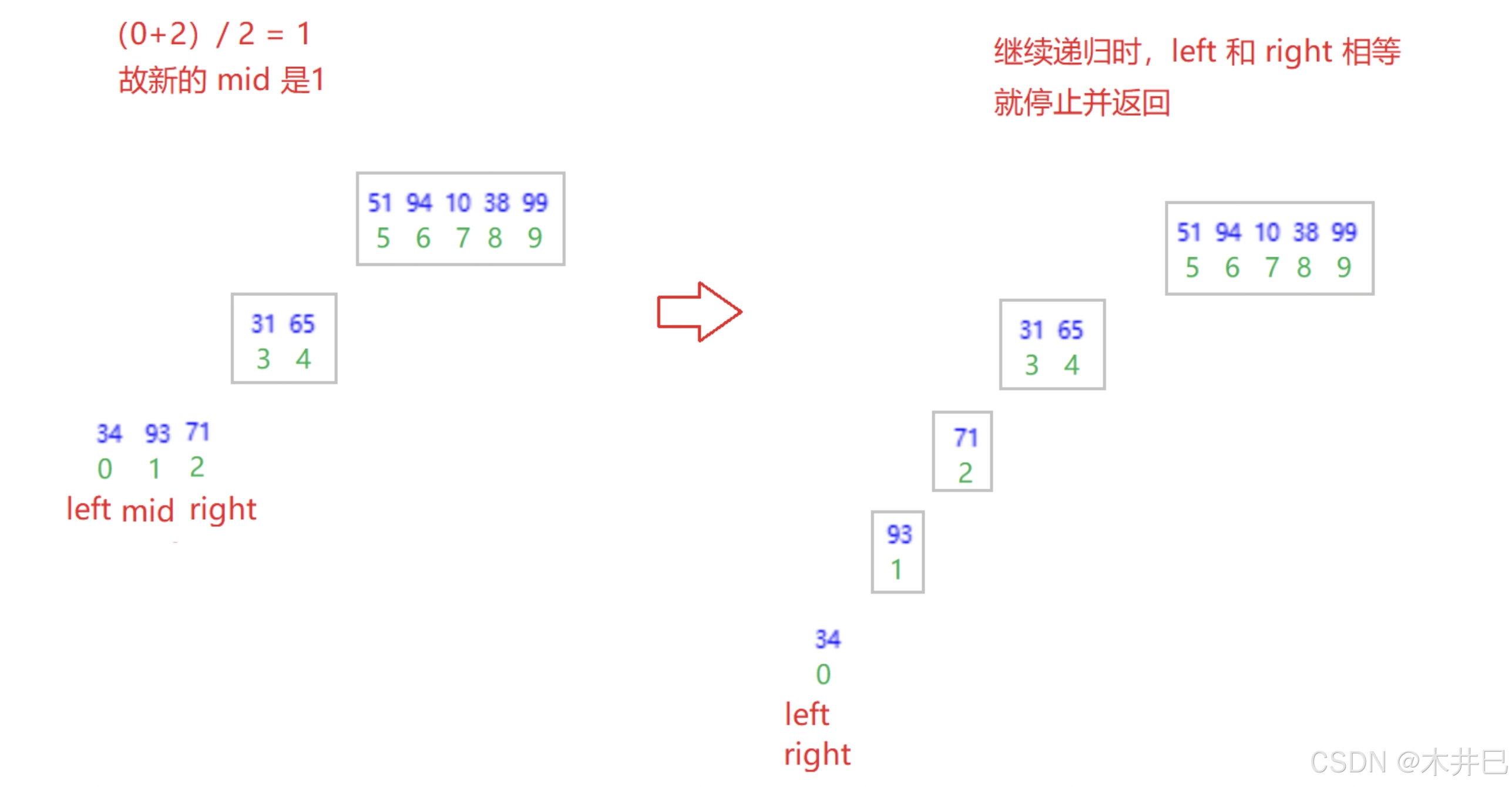
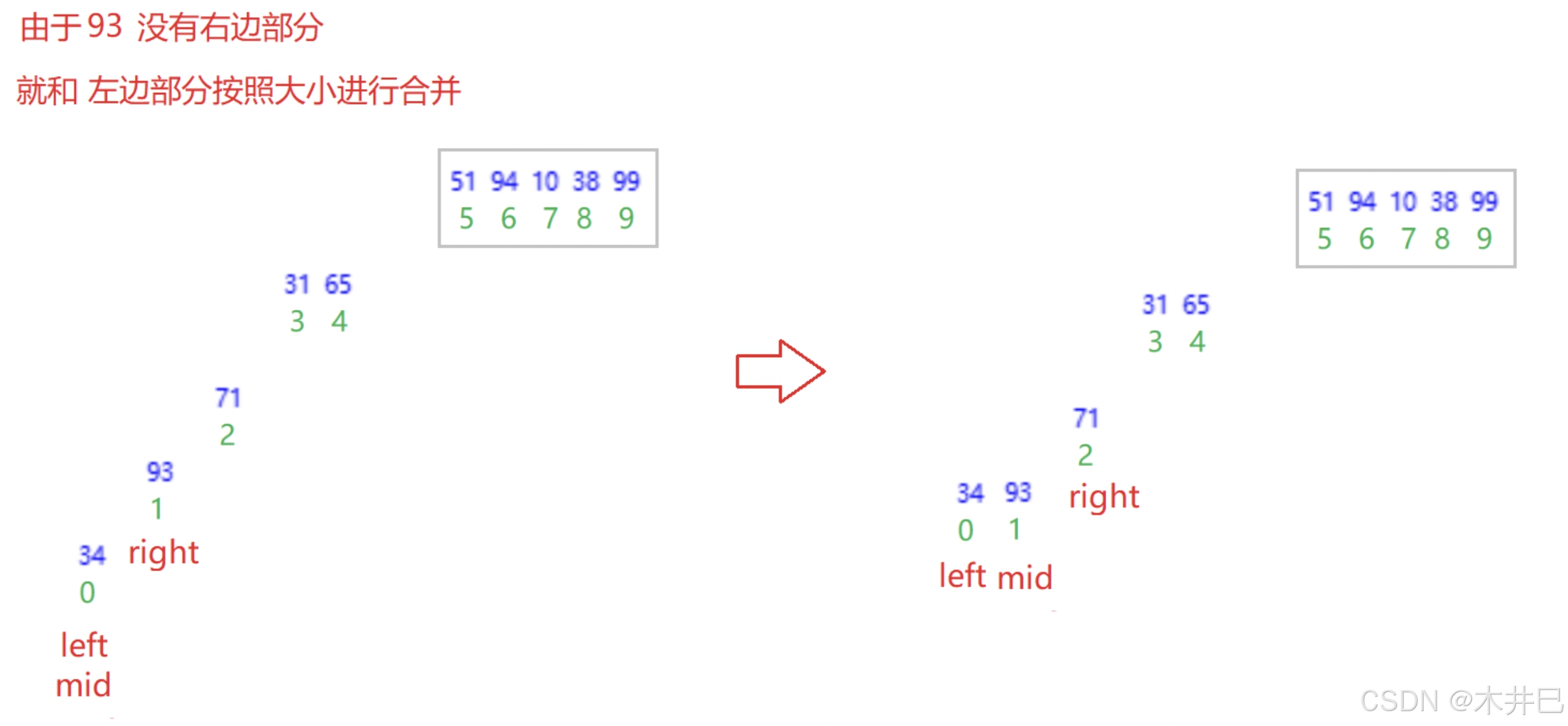
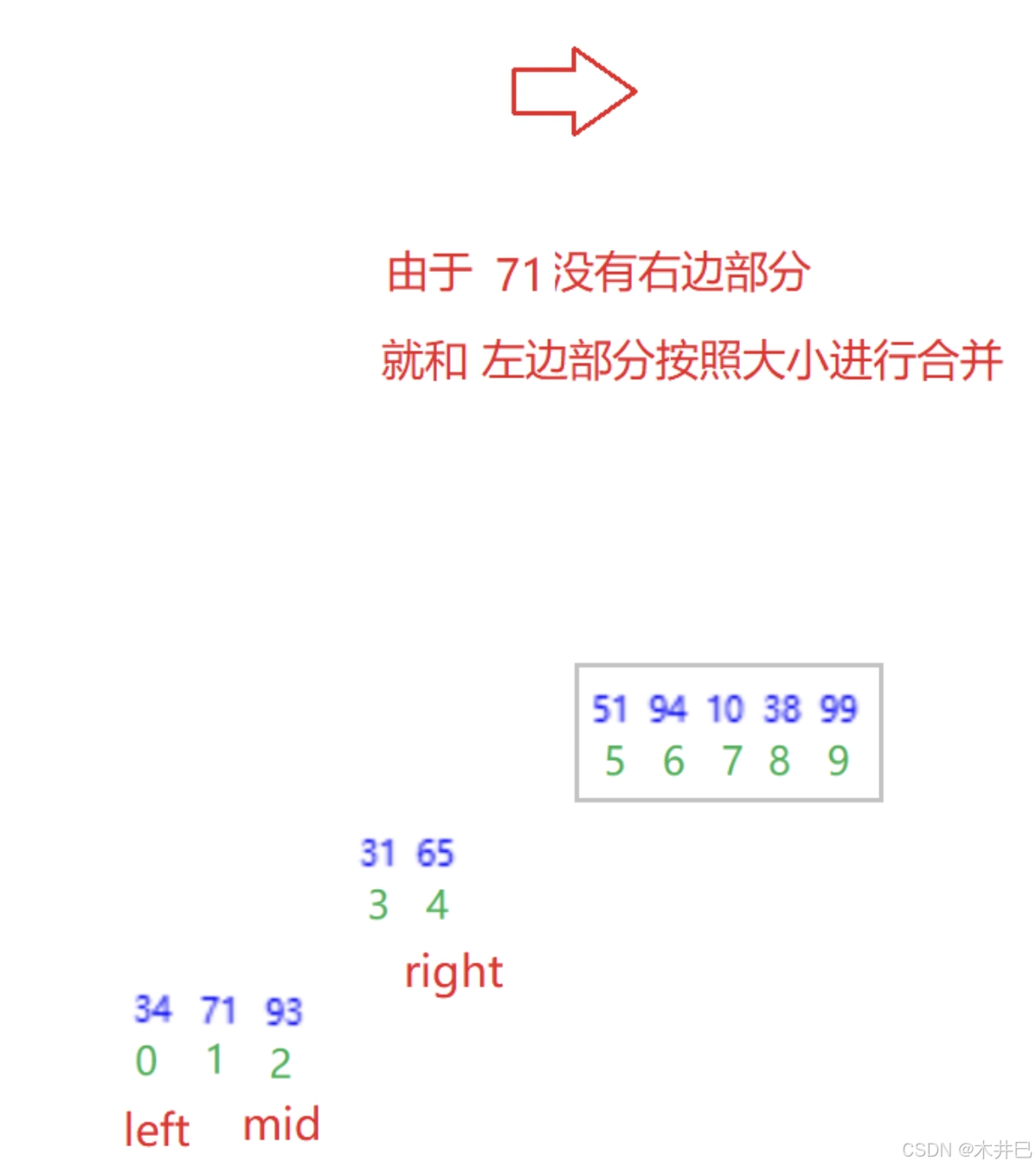

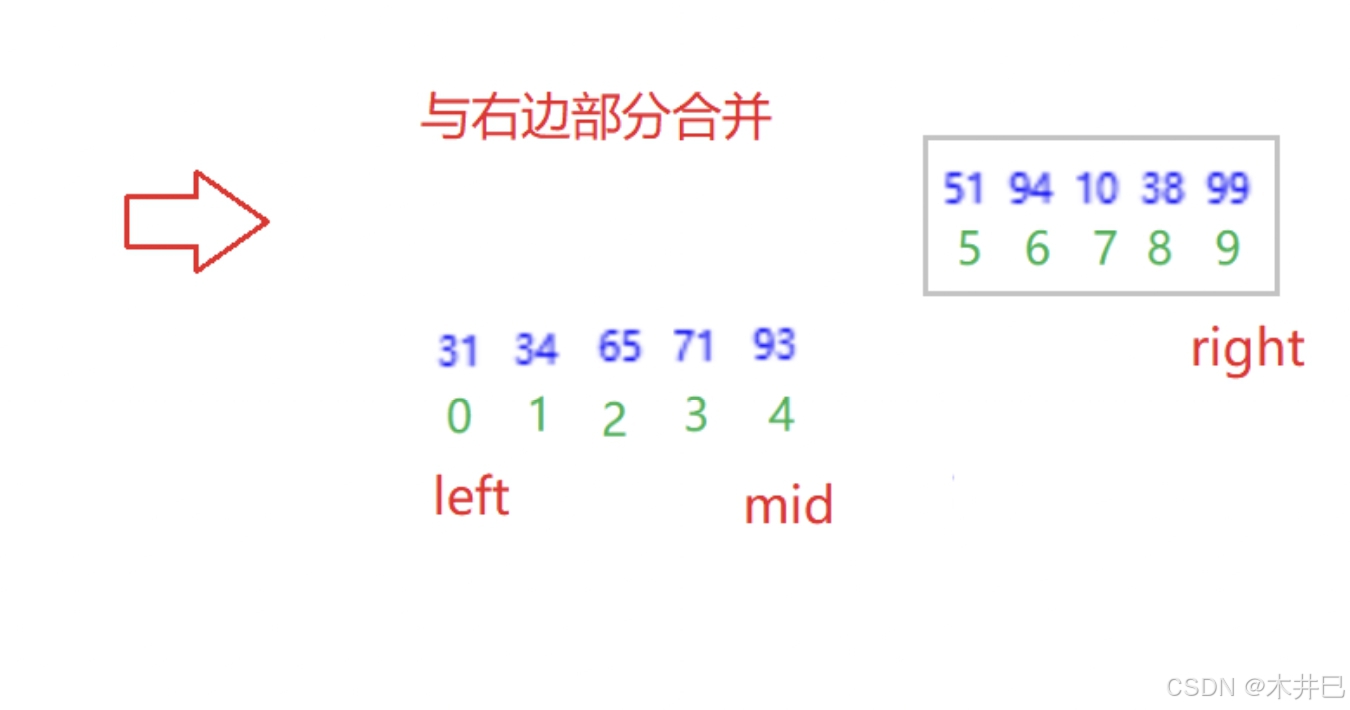

合并的具体操作详见链表面试题中的:合并两个有序链表,思路是一样的。
代码实现
java
// 归并排序
public static void mergeSort (int[] arr) {
splitAndMerge(arr,0,arr.length-1);
}
private static void splitAndMerge(int[] arr, int left, int right) {
// 分解
if (left >= right)
return;
int mid = (left + right) / 2;
splitAndMerge(arr,left,mid);
splitAndMerge(arr,mid+1,right);
// 合并
merge(arr,left,mid,right);
}
private static void merge(int[] arr, int left, int mid, int right) {
int[] ret = new int[arr.length];
int k = 0;
int fs = left;
//int fe = mid;
int ls = mid + 1;
//int le = right;
// 当两个有序数组都不为空
while (fs<=mid && ls<=right) {
if (arr[fs] < arr[ls]) {
ret[k++] = arr[fs++];
} else {
ret[k++] = arr[ls++];
}
}
while (fs <= mid) {
ret[k++] = arr[fs++];
}
while (ls <= right) {
ret[k++] = arr[ls++];
}
// 此时ret数组已经存入全部数据,将ret数组接入arr数组
for (int i = 0; i < k; i++) {
arr[i+left] = ret[i];
}
}性能分析
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
非递归实现归并排序
算法实现思路
- 第一次每一个数都是一组有序的数,然后第二次两个看成有序一组,以此类推依次乘二,当达到数组长度就结束
- 每一次定义三个下标left、mid和right, 通过下标实现合并数组操作
- 注意检查下标是否越界
图示如下:




合并操作传送:合并两个有序链表
代码实现
java
// 非递归归并排序
public static void mergeSortNonTra (int[] arr) {
// 最开始每一个元素看成一组有序的数组
int gap = 1;
// 确保gap不超过数组长度
while (gap < arr.length) {
// 遍历数据,每次走i+2*gap步
for (int i = 0; i < arr.length; i = i+2*gap) {
int left = i;
int mid = left + gap - 1;
// 判断mid是否合法
if (mid >= arr.length) {
mid = arr.length - 1;
}
int right = mid + gap;
// 判断right是否合法
if (right >= arr.length) {
right = arr.length - 1;
}
// 合并数组
merge(arr,left,mid,right);
}
// 每一轮结束后让gap乘2
gap *= 2;
}
}2.5 计数排序(非基于比较的排序)
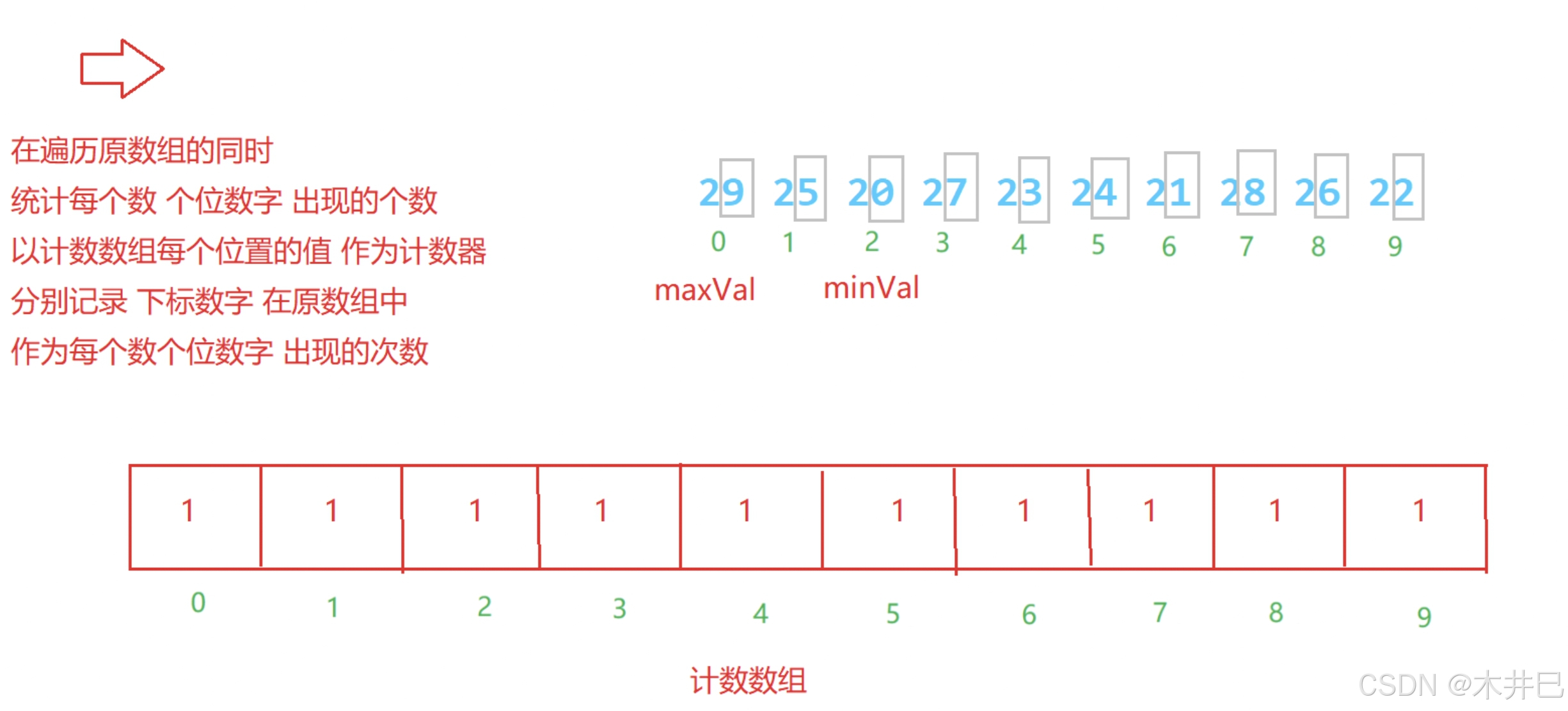
算法实现思路
- 使用一个计数数组存储0~9数字每个数字出现的次数(将每个数字减去最小值的结果作为计数数组的下标)
- 然后按照计数数组按顺序打印每个数字对应的个数
- 注意:1. 场景:数据集中在某个范围内,对于太发散的数据不适用;2. 需要先观察数据的最大和最小值,再计算计数数组的长度len = max - min+ 1
图示如下:



代码实现
java
// 计数排序(非基于比较的排序)
public static void countSort (int[] arr) {
// 1.找数据中的最大值和最小值,然后确定 计数数组 的长度
int minVal = arr[0];
int maxVal = arr[0];
for (int i = 0; i < arr.length; i++) {
if (arr[i] < minVal) {
minVal = arr[i];
}
if (arr[i] > maxVal) {
maxVal = arr[i];
}
}
// 计算 计数数组 的长度
int len = maxVal - minVal + 1;
int[] count = new int[len];
// 2.遍历原数组,通过 计数数组 统计每一个数个位数字出现的个数
for (int i = 0; i < arr.length; i++) {
count[arr[i]-minVal]++;
}
// 3.遍历计数数组,按顺序覆盖原数组
int index = 0;
for (int i = 0; i < count.length; i++) {
while (count[i] != 0) {
arr[index++] = i + minVal;
count[i]--;
}
}
}性能分析
- 时间复杂度:O(N + k),k为数据范围
- 空间复杂度:O(k)
- 稳定性:稳定
至此,八大排序就全部讲解完毕啦,若有不正确的,请尽管指出!
希望读者朋友们能够学到知识~
完