PyTorch实战(9)------从零开始实现Transformer
-
- [0. 前言](#0. 前言)
- [1. Transformer 模型](#1. Transformer 模型)
-
- [1.1 语言模型](#1.1 语言模型)
- [1.2 Transformer 模型架构](#1.2 Transformer 模型架构)
- [2. 构建 Transformer 模型](#2. 构建 Transformer 模型)
- [3. 数据集处理](#3. 数据集处理)
- [4. Transformer 模型训练](#4. Transformer 模型训练)
-
- [4.1 从零开始训练 Transformer 模型](#4.1 从零开始训练 Transformer 模型)
- [4.2 使用预训练 Transformer 模型](#4.2 使用预训练 Transformer 模型)
- 小结
- 系列链接
0. 前言
我们已经详细学习了各类卷积神经网络 (Convolutional Neural Network, CNN)和循环神经网络 (Recurrent Neural Network, RNN)架构,并使用 PyTorch 进行实现。在本节中,我们将探索 Transformer 模型,这种架构在序列任务(包括大语言模型)中已全面超越循环神经网络,更成为多模态模型、生成式人工智能等领域的实际标准架构。本节将详细介绍 Transformer 模型,并使用 PyTorch 实现 Transformer 模型解决序列任务。
1. Transformer 模型
在本节中,我们将探讨 Transformer 模型的基本原理,使用 PyTorch 构建 Transformer 语言模型,并学习如何通过 PyTorch 的预训练模型库调用 BERT、GPT 等预训练模型。PyTorch 官方模型库提供基于通用任务(如语言建模,给定前面的词序列预测下一个词)训练的预训练模型,这些模型可通过微调适配情感分析等具体任务。在构建 Transformer 模型之前,我们先回顾语言建模的基本概念。
1.1 语言模型
语言建模的任务是确定一个词或一串词在给定词序列后出现的概率。例如,给定的词序列是"中文是一门美丽的 __",预测后续出现"语言"或其他词汇的概率?这些概率通过使用各种概率和统计技术建模语言来计算。传统方法通过统计语料库中的词汇共现规律来建立概率规则。通过这种方式,语言模型会在给定不同序列的情况下,建立起不同词汇或词汇序列出现的概率规则。
在 Transformer 出现之前,循环神经网络 (Recurrent Neural Network, RNN)曾是构建语言模型的流行方法。但与其它序列相关的任务一样,Transformer 模型在这一任务中的表现同样超越了循环神经网络。
(1) 首先,导入所需库:
python
import math
import time
import torch
from torch import nn, Tensor
import torch.nn.functional as F
from torch.nn import TransformerEncoder, TransformerEncoderLayer
from torch.utils.data import dataset
from torchtext.datasets import PennTreebank
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator除常规 torch 库外,导入 torch.nn.Transformer 等模块,并通过 torchtext.datasets 直接获取文本数据集。下一节将详细介绍 Transformer 模型架构及其组件实现。
1.2 Transformer 模型架构
在本节中,我们将完整定义 Transformer 模型架构。首先,简要介绍模型架构,然后使用 PyTorch 定义 Transformer 模型。下图展示了 Transformer 模型的架构:

该架构本质上是编码器-解码器结构,通过堆叠多个编码/解码单元可以构建更深层网络,在本节中,采用 2 个编码器单元和 1 个解码器单元。编码器将输入序列转换为词嵌入向量(每个单词对应一个嵌入),解码器则结合这些嵌入向量和已有预测结果进行输出。
接下来,介绍 Transformer 的核心组件:
-
嵌入层 (
Embedding Layer):将每个输入序列中的单词转换为一个数字向量,即嵌入 (embedding)。通常,使用torch.nn.Embedding模块来实现。 -
位置编码器 (
Positional Encoder):Transformer虽无循环结构却能处理序列数据,其奥秘就在于位置编码 (Positional Encoding)。位置编码让模型能够感知数据的顺序,或者说是序列顺序,通过特定数学函数生成具有顺序规律的向量,与词嵌入相加后赋予模型位置感知能力。为了能系统性地体现单词间的周期关系和相对距离,这些向量可以通过正弦和余弦函数生成:pythonclass PosEnc(nn.Module): def __init__(self, d_m, dropout=0.2, size_limit=5000): super(PosEnc, self).__init__() self.dropout = nn.Dropout(dropout) p_enc = torch.zeros(size_limit, 1, d_m) pos = torch.arange(size_limit, dtype=torch.float).unsqueeze(1) divider = torch.exp(torch.arange(0, d_m, 2).float() * (-math.log(10000.0) / d_m)) p_enc[:, 0, 0::2] = torch.sin(pos * divider) p_enc[:, 0, 1::2] = torch.cos(pos * divider) self.register_buffer('p_enc', p_enc) def forward(self, x): return self.dropout(x + self.p_enc[:x.size(0)])交替使用正弦和余弦函数构建顺序模式。位置编码的实现方式多样,但若没有位置编码层,模型将无法理解单词的顺序。
-
多头注意力机制 :在了解多头注意力之前,首先了解自注意力机制。自注意力机制作用于序列自身------即对每个单词施加注意力。序列中的每个单词嵌入都会通过自注意力层,并生成一个与单词嵌入长度相同的输出向量。该过程如下图所示:
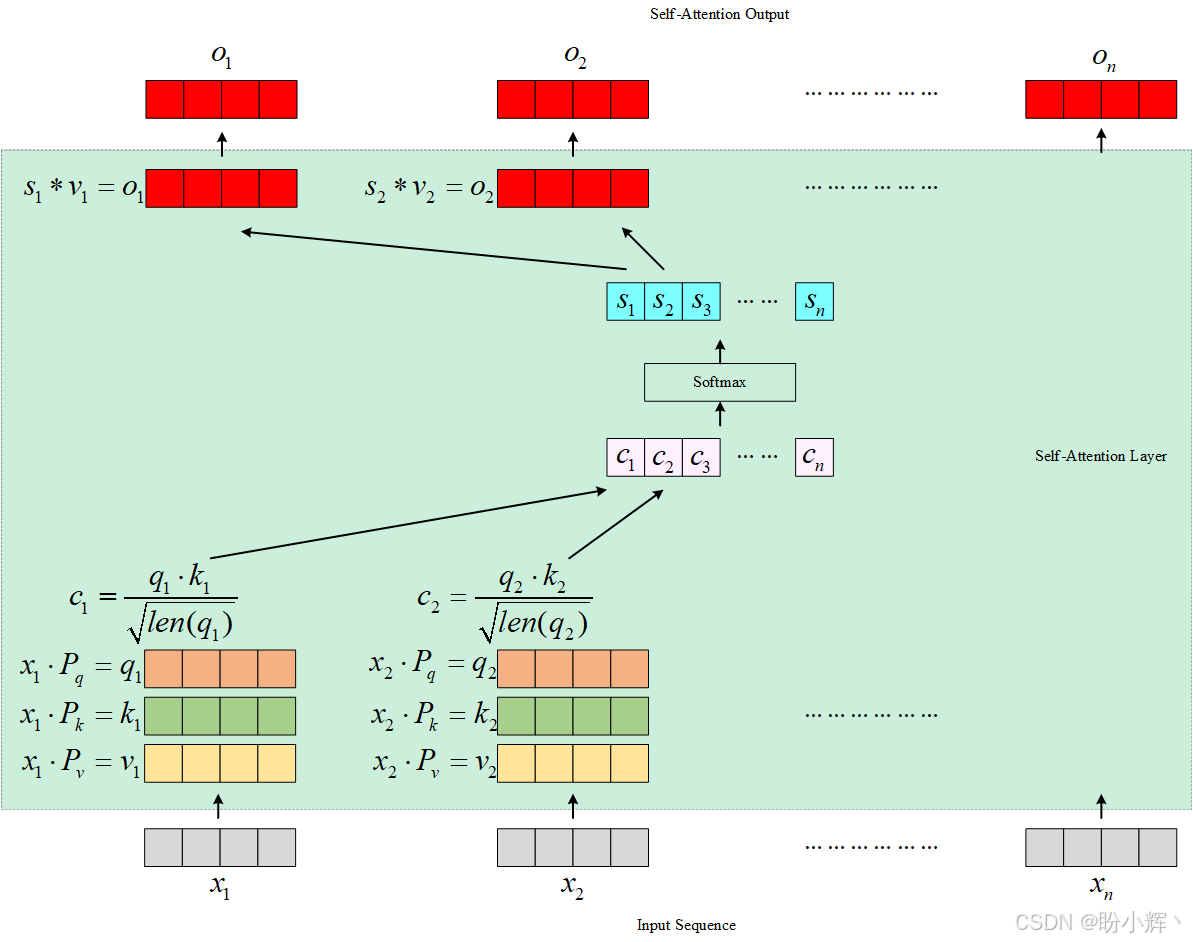
如图所示,每个单词通过三个可训练参数矩阵 ( P q P_q Pq、 P k P_k Pk、 P v P_v Pv) 生成三组向量:查询向量 (
query)、键向量 (key) 和值向量 (value)。查询向量和键向量进行点积后,通过除以键向量长度的平方根进行标准化,然后,所有单词的结果数字同时经过Softmax处理,生成概率,并最终与每个单词对应的值向量相乘。以上为序列中的每个单词生成一个输出向量,且输出向量的长度与输入单词嵌入向量相同。多头注意力层是自注意力层的扩展,其核心原理是通过多组并行的自注意力模块为每个单词生成不同的输出向量,这些独立输出的向量会进行拼接,并与另一个参数矩阵 ( P m P_m Pm) 进行矩阵乘法,生成最终的输出向量,长度与输入词嵌入向量相同。下图展示了多头注意力层,本节中使用两个自注意力头:
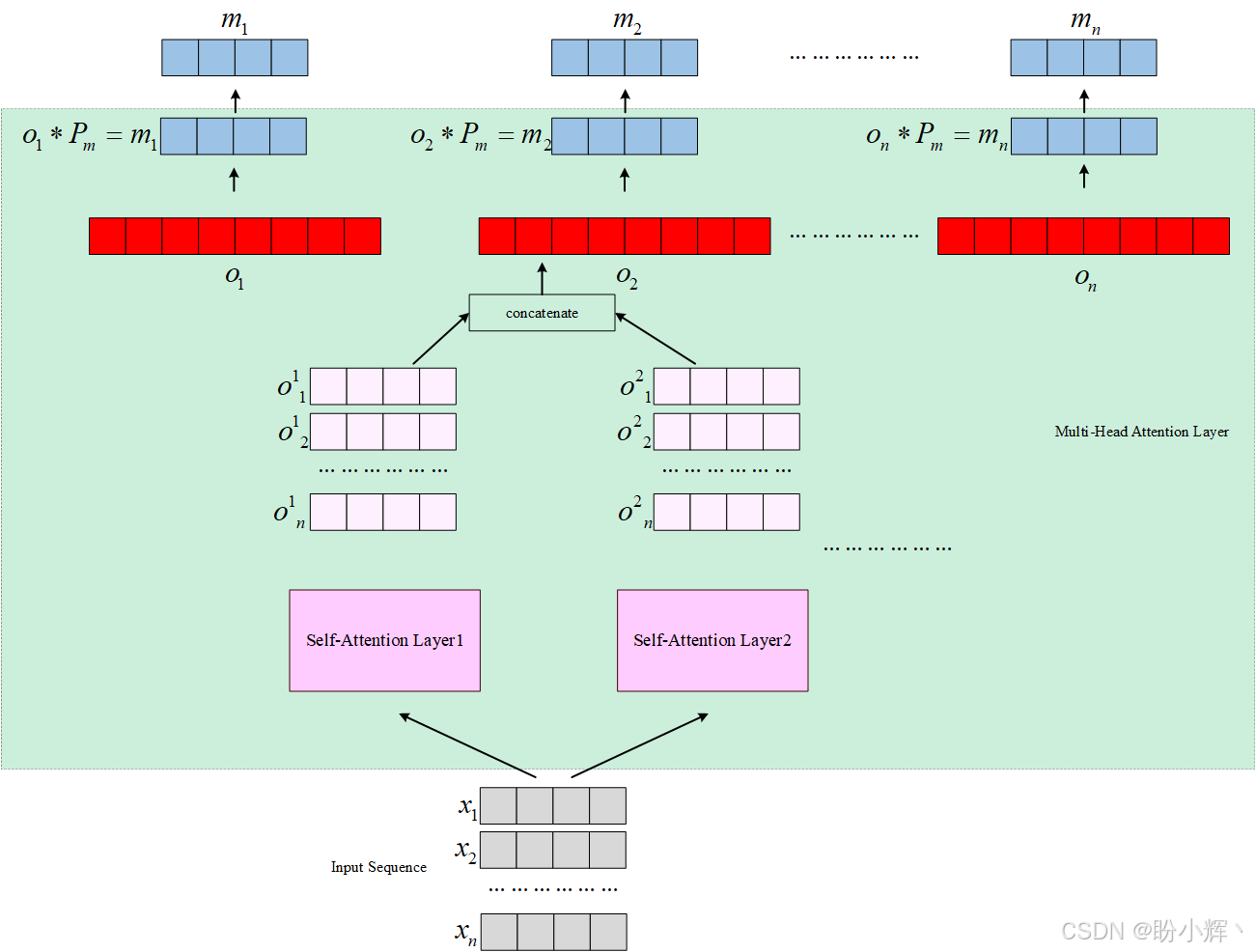
这种设计的优势在于:不同的注意力头能够捕捉序列中不同类型的特征关联,类似于卷积神经网络中不同特征图学习不同模式的特点,因此,多头注意力层的表现优于单头自注意力层。
需要注意的是,解码器中的掩码多头注意力层的工作方式与多头注意力层基本相同,唯一的区别是增加了掩码处理:当处理序列的第 t t t 个时间步时,会遮蔽从 t + 1 t+1 t+1 到序列末尾 n n n的所有单词。
在训练过程中,解码器接收两种类型的输入:从编码器接收查询/键向量(通过编码器输出的矩阵变换生成),输入至普通多头注意力层解码器接收来自前一个时间步的预测作为其掩码多头注意力层的顺序输入。
-
残差和层归一化 :网络通过跨层的残差连接(将多头注意力层的输出与原始词嵌入直接相加)配合层归一化操作,这种设计借鉴了 ResNet 的思想。该结构能有效改善梯度流动,缓解梯度爆炸/消失问题,同时有助于在各层之间高效地学习恒等函数。层归一化操作会对每个词向量的特征维度进行独立标准化,确保所有特征具有统一的均值和方差。需要注意的是,残差和归一化操作是单会在网络每个处理阶段独立应用于序列中的各个词向量。
-
前馈神经网络层:在编码器和解码器单元中,经过归一化的残差输出向量会通过共享参数的前馈神经网络。这种参数共享机制有助于模型学习序列中的全局模式。
-
线性层和 Softmax 层 :上述每一层都输出一个向量序列,每个单词一个向量。对于语言建模任务,线性层将向量序列转换为一个单一的向量,该向量的大小等于词汇表中单词的数量,再经
Softmax层转化为概率分布(概率之和为1),这些概率表示词汇表中的相应单词作为序列中下一个单词出现的概率。
介绍了 Transformer 模型的各个元素后,接下来,使用 PyTorch 创建 Transformer 模型。
2. 构建 Transformer 模型
(1) 根据上一小节中描述的架构,使用 PyTorch 实现 Transformer 模型:
python
def gen_sqr_nxt_mask(size):
msk = torch.triu(torch.ones(size, size) * float('-inf'), diagonal=1)
return msk
class Transformer(nn.Module):
def __init__(self, num_token, num_inputs, num_heads, num_hidden, num_layers, dropout=0.3):
super(Transformer, self).__init__()
self.model_name = 'transformer'
self.position_enc = PosEnc(num_inputs, dropout)
layers_enc = TransformerEncoderLayer(num_inputs, num_heads, num_hidden, dropout)
self.enc_transformer = TransformerEncoder(layers_enc, num_layers, enable_nested_tensor=False)
self.enc = nn.Embedding(num_token, num_inputs)
self.num_inputs = num_inputs
self.dec = nn.Linear(num_inputs, num_token)
self.init_params()
def init_params(self):
initial_rng = 0.12
self.enc.weight.data.uniform_(-initial_rng, initial_rng)
self.dec.bias.data.zero_()
self.dec.weight.data.uniform_(-initial_rng, initial_rng)在类的 __init__ 方法中,借助 PyTorch 内置的 TransformerEncoder 和 TransformerEncoderLayer 模块,我们无需手动实现编码器结构。针对语言建模任务(需为输入序列生成单一预测输出),解码器仅需一个线性变换层将编码器输出的向量序列转换为单个输出向量。位置编码器则采用前文讨论的方案进行初始化。
(2) 在 forward 方法中,输入数据先经过位置编码处理,再依次通过编码器和解码器:
python
def forward(self, source, mask_source):
source = self.enc(source) * math.sqrt(self.num_inputs)
source = self.position_enc(source)
op = self.enc_transformer(source, mask_source)
op = self.dec(op)
return op定义了 Transformer 模型架构后,接下来加载文本语料库来进行训练。
3. 数据集处理
在本节中,我们将讨论文本数据集的加载与处理流程,采用华尔街日报文本构成的 Penn Treebank 数据集。
(1) 使用 torchtext 下载训练数据集,并进行分词处理:
python
tr_iter = PennTreebank(split='train')
tkzer = get_tokenizer('basic_english')
vocabulary = build_vocab_from_iterator(map(tkzer, tr_iter), specials=['<unk>'])
vocabulary.set_default_index(vocabulary['<unk>'])
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")(2) 基于训练集构建词汇表,将原始文本转换为训练、验证和测试数据集对应的张量:
python
def process_data(raw_text):
numericalised_text = [torch.tensor(vocabulary(tkzer(text)), dtype=torch.long) for text in raw_text]
return torch.cat(tuple(filter(lambda t: t.numel() > 0, numericalised_text)))
tr_iter, val_iter, te_iter = PennTreebank()
training_text = process_data(tr_iter)
validation_text = process_data(val_iter)
testing_text = process_data(te_iter)(3) 定义训练和评估的批大小,并声明一个数据生成函数:
python
def gen_batches(text_dataset, batch_size):
num_batches = text_dataset.size(0) // batch_size
text_dataset = text_dataset[:num_batches * batch_size]
text_dataset = text_dataset.view(batch_size, num_batches).t().contiguous()
return text_dataset.to(device)
training_batch_size = 32
evaluation_batch_size = 16
training_data = gen_batches(training_text, training_batch_size)
validation_data = gen_batches(validation_text, evaluation_batch_size)
testing_data = gen_batches(testing_text, evaluation_batch_size)(4) 接下来,定义最大序列长度,编写函数用于生成符合要求的输入序列与对应输出目标:
python
max_seq_len = 64
def return_batch(src, k):
sequence_length = min(max_seq_len, len(src) - 1 - k)
sequence_data = src[k:k+sequence_length]
sequence_label = src[k+1:k+1+sequence_length].reshape(-1)
return sequence_data, sequence_label定义模型并准备好训练数据之后,接下来,开始训练 Transformer 模型。
4. Transformer 模型训练
4.1 从零开始训练 Transformer 模型
在本节中,我们将定义训练模型所需的超参数,定义模型的训练和评估流程,最后执行训练循环。
(1) 定义所有模型的超参数并实例化 Transformer 模型:
python
num_tokens = len(vocabulary) # vocabulary size
embedding_size = 256 # dimension of embedding layer
num_hidden_params = 256 # transformer encoder's hidden (feed forward) layer dimension
num_layers = 2 # num of transformer encoder layers within transformer encoder
num_heads = 2 # num of heads in (multi head) attention models
dropout = 0.25 # value (fraction) of dropout
loss_func = nn.CrossEntropyLoss()
lrate = 4.0 # learning rate
transformer_model = Transformer(num_tokens, embedding_size, num_heads, num_hidden_params, num_layers,
dropout).to(device)
optim_module = torch.optim.SGD(transformer_model.parameters(), lr=lrate)
sched_module = torch.optim.lr_scheduler.StepLR(optim_module, 1.0, gamma=0.88)(2) 在启动训练循环前,需预先定义核心训练逻辑和评估方法:
python
def train_model():
transformer_model.train()
loss_total = 0.
time_start = time.time()
mask_source = gen_sqr_nxt_mask(max_seq_len).to(device)
num_batches = len(training_data) // max_seq_len
for b, i in enumerate(range(0, training_data.size(0) - 1, max_seq_len)):
train_data_batch, train_label_batch = return_batch(training_data, i)
sequence_length = train_data_batch.size(0)
if sequence_length != max_seq_len: # only on last batch
mask_source = mask_source[:sequence_length, :sequence_length]
op = transformer_model(train_data_batch, mask_source)
loss_curr = loss_func(op.view(-1, num_tokens), train_label_batch)
optim_module.zero_grad()
loss_curr.backward()
torch.nn.utils.clip_grad_norm_(transformer_model.parameters(), 0.6)
optim_module.step()
loss_total += loss_curr.item()
interval = 100
if b % interval == 0 and b > 0:
loss_interval = loss_total / interval
time_delta = time.time() - time_start
print(f"epoch {ep}, {b}/{len(training_data)//max_seq_len} batches, training loss {loss_interval:.2f}, training perplexity {math.exp(loss_interval):.2f}")
loss_total = 0
time_start = time.time()
def eval_model(eval_model_obj, eval_data_source):
eval_model_obj.eval()
loss_total = 0.
mask_source = gen_sqr_nxt_mask(max_seq_len).to(device)
with torch.no_grad():
for j in range(0, eval_data_source.size(0) - 1, max_seq_len):
eval_data, eval_label = return_batch(eval_data_source, j)
sequence_length = eval_data.size(0)
if sequence_length != max_seq_len:
mask_source = mask_source[:sequence_length, :sequence_length]
op = eval_model_obj(eval_data, mask_source)
op_flat = op.view(-1, num_tokens)
loss_total += sequence_length * loss_func(op_flat, eval_label).item()
return loss_total / (len(eval_data_source) - 1)(3) 运行模型的训练循环:
python
min_validation_loss = float("inf")
eps = 5
best_model_so_far = None
for ep in range(1, eps + 1):
ep_time_start = time.time()
train_model()
validation_loss = eval_model(transformer_model, validation_data)
print()
print(f"epoch {ep:}, validation loss {validation_loss:.2f}, validation perplexity {math.exp(validation_loss):.2f}")
print()
if validation_loss < min_validation_loss:
min_validation_loss = validation_loss
best_model_so_far = transformer_model
sched_module.step()输出结果如下所示:
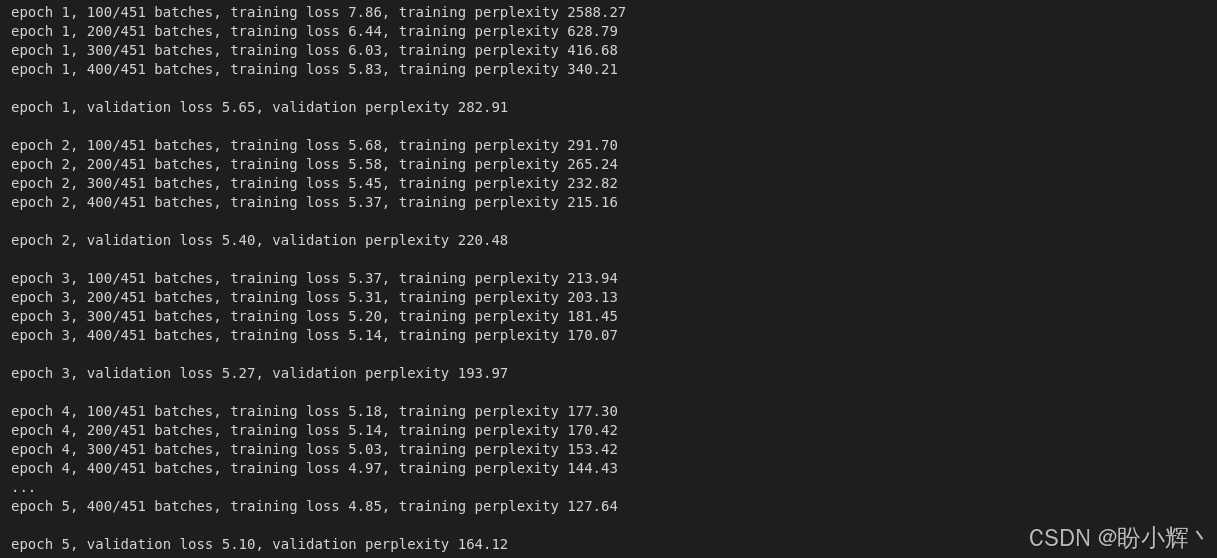
除交叉熵损失外,输出中还包含困惑度 (perplexity) 指标------该指标是自然语言处理领域衡量概率分布预测能力的核心标准,数值越低表示模型预测越准确。从数学角度看,困惑度即交叉熵损失的指数形式,直观反映了模型预测时的"困惑程度"。
(4) 完成训练后,在测试集上评估模型表现:
python
testing_loss = eval_model(best_model_so_far, testing_data)
print(f"testing loss {testing_loss:.2f}, testing perplexity {math.exp(testing_loss):.2f}")输出结果如下所示:
shell
testing loss 5.00, testing perplexity 147.934.2 使用预训练 Transformer 模型
自 2017 年原始 Transformer 问世以来,衍生模型层出不穷,主要包括:
2018年:BERT、GPT2019年:GPT-2、CTRL、Transformer-XL、DistilBERT、RoBERTa2020年:GPT-3、T52021年:LaMDA2022年:PaLM、GPT-3.5(ChatGPT)2023年:LLaMA、GPT-4、LLaMA-2、Grok、Gemini2024年:Sora、Gemini-1.5、LLaMA-3
虽然我们在本节中不会详细介绍这些模型,但通过 Hugging Face 的transformers 库,我们可快速调用预训练模型。transformers 库为各种任务提供了预训练的 Transformer 模型,如语言建模、文本分类、翻译、问答等。除预训练模型外,该库还提供了专用分词器。例如,调用预训练 BERT 模型进行语言建模:
python
import torch
from transformers import BertForMaskedLM, BertTokenizer
bert_model = BertForMaskedLM.from_pretrained('bert-base-uncased')
token_gen = BertTokenizer.from_pretrained('bert-base-uncased')
ip_sequence = token_gen("I love PyTorch !", return_tensors="pt")["input_ids"]
op = bert_model(ip_sequence, labels=ip_sequence)
total_loss, raw_preds = op[:2]在本节中,我们通过从零构建和调用预训练模型两种方式探索了 transformers 技术。Transformer 在自然语言处理领域的意义,堪比计算机视觉领域的 ImageNet 时刻,是当前持续活跃的研究方向。
小结
在本节中,我们探讨了以注意力机制为核心的 Transformer 模型(在多项序列任务中超越所有循环模型),并使用 PyTorch 构建了一个 Transformer 模型,用于语言建模任务。详细探讨了 Transformer 架构以及使用 PyTorch 进行实现的方法,并使用 Penn Treebank 数据集和 torchtext 加载和处理数据集。然后,训练 Transformer 模型 ,并在测试集上对其进行了评估。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成