目录
1.epoll的底层原理
(1)网络原理引导(上层向下层注册服务)
当服务端和客户端建立连接之后,服务端通信专用的fd对应的struct sock里面就有发送队列和接收队列。我们将该连接放入select和poll中之后,Linux内核就会遍历我们关心的fd和事件,其中就会看我们关心的通信fd里面的sock,看里面的接收队列、发送队列上是否有数据。
但操作系统遍历所有我们关心的fd和事件效率低下,于是我们需要借助一个底层回调机制。
网络部分,当接收队列sk_buff中有数据之后,该套接字会自动调用某个函数指针对应的方法Callback(),这个默认方法是空的(即函数指针指向NULL)。 所以在默认的情况下,数据就绪时,当套接字发现该Callback()方法为空时,就不进行调用,如果该方法不为空就调用。与此同时,套接字在上层有一个接口SetCallback(func_t f),上层可以通过调用这个接口传入一个函数指针,这个指针会被赋值在Callback()方法上,于是后续每当数据就绪时,套接字就会自动去调用这个Callback(),而这个Callback()是上层通过接口传过去的,这就叫上层向下层注册服务!
我们传过去的Callback()方法就是回调函数,即下层执行我们传过去的上层的函数,这个上层函数是我们自定义的,也就是说只要sk_buff收到了数据,它就会自动调用我们的接口,我们想让它干什么,它就干什么!
因此,只要下层提供回调接口,允许我们传函数指针,那么上层就可以向底层注册我们想要的机制。 比如说我们可以注册这个机制为:OS给目标进程发送SIGIO,同时进程捕获该信号,当系统找到PCB修改位图结构的pending标志位之后,进程切换到内核态执行相应的捕获函数handler(),这个handler()就可以打印一条数据,cout << "有数据就绪了!",这就是信号驱动式IO的核心依赖,也是epoll模型底层的重要组成部分。
(2)红黑树和就绪队列
当我们创建一个epoll模型时,OS会在内核创建一颗红黑树,这颗红黑树一开始是没有节点的,但可以新增节点,这个节点可理解为pair<fd, struct epoll_event>。 因此,我们用户ctl设置的所有关心的fd和事件都会以fd为key被保存在一颗红黑树中。
除此之外还有个就绪队列ready_queue,这个队列里面的每个节点保存着已就绪的fd和事件。因此一旦有事件就绪,就绪队列就会被链入新节点。
红黑树描述了内核要为用户关心哪些fd上的哪些事件(用户到内核),而就绪队列是内核告诉用户哪些fd上的哪些事件就绪了(内核到用户)。ctl接口的本质是在修改红黑树(用户到内核),wait是在从就绪队列拿出数据(内核到用户)。
但是,OS怎么知道文件有事件就绪呢?红黑树的节点管我就绪队列什么事?红黑树跟就绪队列怎么联系在一起?
(3)基于回调机制的节点迁移
当用户调用ctl函数时,底层会在红黑树中添加对应的结点(用户到内核)。但除此之外,系统底层还会在我们关心的fd对应的struct file中调用一个SetCallback(func_t f)的接口,设置回调函数。默认情况下这个回调函数是NULL,不会执行,但调用ctl之后,上层注册了这个方法。因此,每当这个fd有事件就绪时,该fd就会主动去调用这个Callback(),而这个方法就是:把该节点从红黑树迁移到就绪队列!
所以,如果有数据就绪了,调用Callback(),判断是读事件就绪还是写事件就绪 ,再把对应fd和对应事件作为就绪节点插入就绪队列。 由于这个函数是回调的,我们只需要负责向红黑树中插入节点,注册回调方法,之后就由回调机制在底层自动完成从红黑树到就绪队列的迁移。
我们把节点的迁移这个回调机制、红黑树、就绪队列这一整套解决方案叫做epoll模型!我们调用create创建epoll模型,本质上就是创建红黑树和就绪队列,维护回调机制。其中最核心的就是利用了回调机制实现类似信号驱动IO的节点迁移。
回调函数就是指被当成参数传递的函数,在这里就是指手动传递的Callback()。相当于留了个电话,后续一方可以拿着这个电话和对方进行联系。
(4)从文件角度看epoll模型
我们需要以struct file的private_data为起点,理解epoll模型的创建过程。
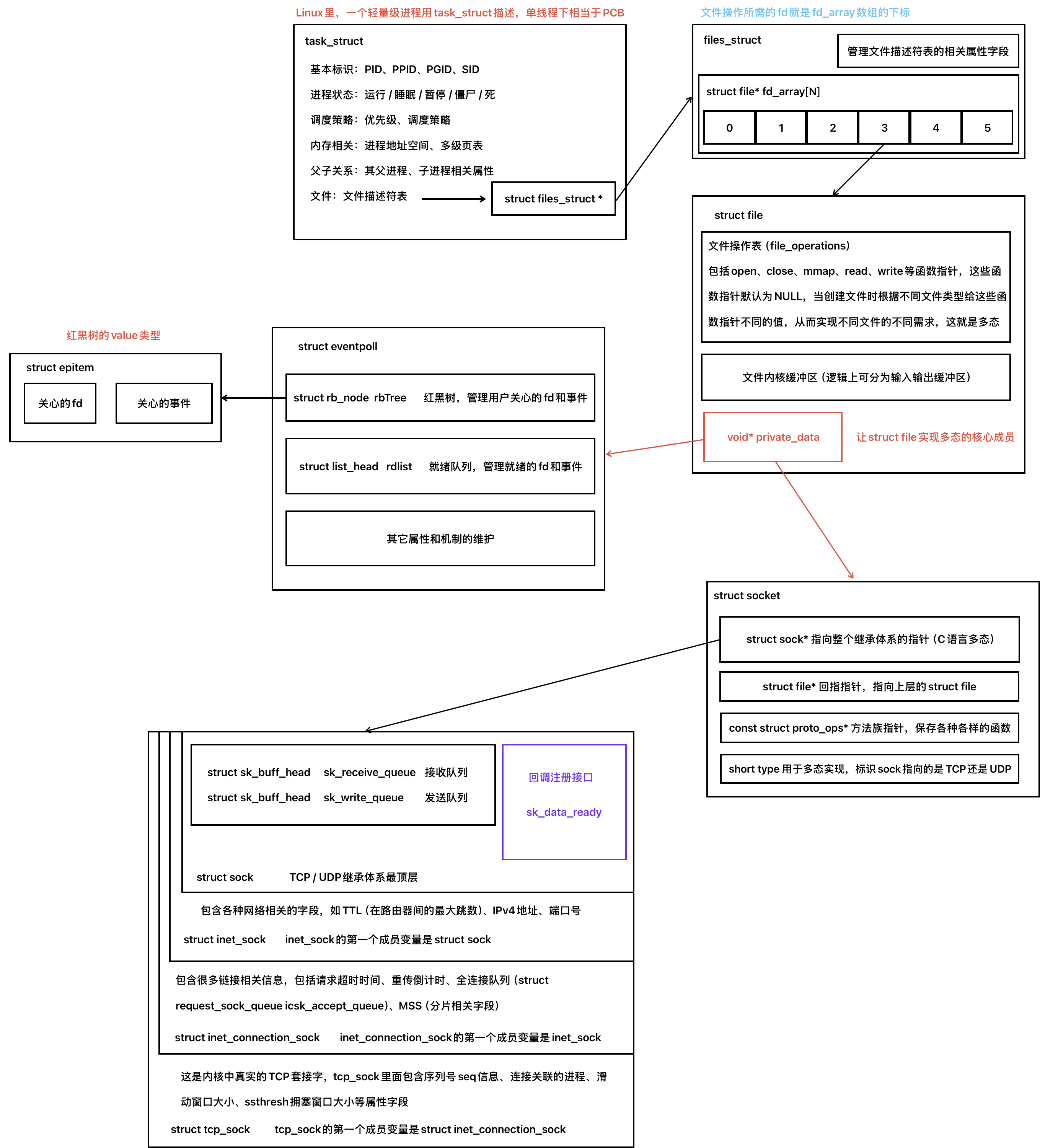
如何理解epoll模型?
如上图,当创建一个epoll模型时其实是创建了一个struct file和struct eventpoll,该file的private_data和我们的struct eventpoll进行关联,因此创建epoll模型返回的其实是一个fd,Linux网络内核和struct file也是这样关联的!Linux下一切皆文件,这也是C风格多态的体现!
在理解epoll模型的构成之后,我们也能理解,ctl和wait都需要fd是因为需要通过fd找到struct file,进而找到struct eventpoll,之后再向红黑树插入 / 修改节点或是从就绪队列取出节点。 所谓wait只会去检测就绪队列里面有没有节点,而不会去主动轮询红黑树里面的fd和事件。
但系统具体是怎么做到把红黑树节点迁移到就绪队列呢?
在图中我们可知红黑树的节点类型是epitem,在内核中,一个节点不是只能属于一个数据结构,利用内核链表的原理,我们添加链接信息就相当于在其它队列激活了该节点。 因此,红黑树的节点也可以是就绪队列的节点,我们可以直接设置指针以激活就绪队列中的节点,使其链接到另一个链表中。
注意,一个节点就绪后不会从红黑树移除,所谓迁移指的就是激活在就绪队列中的节点。能修改红黑树的只有用户的ctl函数。
(5)epoll模型效率分析
epoll为什么高效?
每一个socket里面的sock都可以注册接口,所以用户仅需注册方法 (当sk_buff有数据时,激活在就绪队列上的节点) 即可,OS就能在数据就绪时自己执行回调函数驱动完成节点迁移到就绪队列,OS不再需要遍历了,仅需检测有没有事件就绪,时间复杂度为O(1)。 当有事件就绪的话,就绪队列不为空,这时wait会把就绪的事件和fd作为输出型参数拷贝给用户,这个时间复杂度是O(N),不过这个开销是避免不了的。
为什么用红黑树?
红黑树相当于select里面的辅助数组(包含所有关心的fd和事件,用户到内核),调用ctl就是管理这个辅助数组。而红黑树近似平衡,搜索复杂度相比数组更均衡,很适合。
接口层面的高效如何体现?
如果有事件就绪了,epoll_wait通过输出型参数返回一个数组,这个数组里面节点都是合法的且就绪的,我们直接遍历数组的0 ~ ret - 1即可。红黑树里面没就绪fd和事件都不在就绪队列里面,也就不会出现在输出型参数的数组里。
(6)DEL注意事项
当关闭通信fd时,我们要先调用ctl函数,再close文件,顺序不能调换。因为我们必须要保证节点的fd在移出红黑树前随时都是合法的,调用ctl前系统会去判断我们想要移除的fd是否合法,如果我们先close文件,那这个fd就一定不合法,就会出现泄漏问题。
2.epoll的工作模式
(1)水平触发(LT)
select、poll、epoll默认的工作模式是水平触发(LT)。LT模式下,只要有数据没被取完,隔段时间就一直通知,直到数据被取完,不管这个数据是旧的还是新来的。
因此,一旦收到数据(事件就绪),节点就会一直激活在就绪队列中,只有读完全部数据后该节点才会被链出队列,在此之前该节点一直在就绪队列中处于激活状态,上层一调用wait就会通过就绪队列被通知一次。
(2)边缘触发(ET)
还有个工作模式边缘触发(ET)。当新收到数据时就通知对方一次,并且仅当有新数据到来时才会再通知一次。
因此,一旦数据就绪,OS就会在就绪队列激活节点,上层一旦调用wait发现到了该就绪节点,该节点立马从就绪队列移除,后面再wait就不会找到刚才的这个节点了,除非又有新的数据就绪,否则后面永远不再通知。
设置ET通过EPOLLET按位或在关心事件上即可,通过位图传过去。
(3)LT和ET的效率分析
ET相对更高效,因为首先ET不做重复通知,在相同的时间能通知的事件数量更多,相比而言LT会做很多重复的通知。
其次,ET模式的规则是一旦通知,数据必须取完,后面就不再通知,用户再也无法通过wait读取到该次数据。这是强硬的规定,所以这也是ET模式倒逼上层一次性读取完数据。这种倒逼上层快速读取数据也会进一步增加数据传输效率。 以TCP为例,当就绪时,由于上层必须将数据从接收缓冲区取完,这样的话缓冲区空闲位置就及时增大,ACK给对方通知的将会是一个更大的滑动窗口,对方就可能发送更多数据。这样网络吞吐量就会变大,提高IO效率。
那代价是什么?
ET模式一旦要读取,就必须取完,那问题是我们怎么保证取完了?循环读取!这个时候我们就可以结合非阻塞IO来处理了,直到读取到返回值为-1,根据errno判断为数据为就绪才停止。当然我们也可以根据直到实际读到的数据 < 小于期望数据判断 ,就像有人找你借钱,你借了一次下次他还要找你,直到你再也掏不出他想要的钱的数量才会停止。在阻塞IO下,我们也可以一直读直到阻塞。
但单进程不敢阻塞,所以ET下都会以非阻塞IO + 错误码那套方法处理。LT模式一般不要求设置非阻塞IO,通知了读一下,通知了读一下,这也是所谓的ET模式约束带来的处理方式不同。
LT + 非阻塞 + 循环读 = ET?那要ET干什么?效率有区别吗?
其实LT + 非阻塞 + 循环读和ET的效率没有本质区别,但是ET是强制要求,而前者是一种自己驱动的,考验开发者的水平和素养的。所以LT是基本使用的,没有强硬的规定,相对而言比较均衡。而ET专门为高吞吐量IO设计的,ET相对而言代码更复杂。两者使用的选择取决于各自运用的场景。
当遇到多连接,且多连接中只有一部分比较活跃时,比较适合使用多路转接(epoll、poll、select都是多路转接,推荐epoll),这种IO模型能够把所有文件描述符聚合在一起,尽可能减少进程线程消耗。这就引入了基于epoll的反应堆模式。
3.反应堆模式
反应堆模式属于并发编程与I/O多路复用领域的架构模式,并不是传统的设计模式,这点我们要清楚。下面我从代码角度上来逐层搭建基于ET模式的反应堆,我们要理解每个模块的作用和耦合方式,而非代码非关键部分的细节。
(1)Epoller的封装
我用单例模式封装epoll模型及其基本操作。相当于后续用户的所有fd和事件的关心操作都是调用该epoller的接口实现的,添加到单例中唯一的epoll模型中。这可以说是反应堆中最底层、最核心的模块。
cpp
#pragma once
#include <iostream>
#include <sys/epoll.h>
#include "myLog.hpp"
#include "myCommon.hpp"
// epoll模块,对epoll的封装,提供接口给reactor使用,后续事件的等待、增删都是对该模块函数的调用
namespace myEpollerModule
{
using namespace myLogModule;
using namespace myCommonModule;
// 强枚举类型
enum class myCtrl
{
ADD = EPOLL_CTL_ADD,
DEL = EPOLL_CTL_DEL,
MOD = EPOLL_CTL_MOD
};
// reactor想要wait事件、ctrl事件时,都是面对epoller进行操作的,而不是一个裸的epoll
class myEpoller
{
// 单例,不允许被拷贝,赋值
myEpoller(const myEpoller &) = delete;
myEpoller &operator=(const myEpoller &) = delete;
myEpoller()
{
_epfd = epoll_create(1); // 参数随便填,已经没用了
if (_epfd < 0)
{
LOG(LogLevel::FATAL) << "epoll模型创建失败";
exit(static_cast<int>(myError::EPOLL_CREATE_ERROR));
}
LOG(LogLevel::INFO) << "epoll模型创建成功";
}
~myEpoller()
{
if (_epfd >= 0)
close(_epfd);
}
public:
static myEpoller *GetInstance()
{
if (_epoller == nullptr)
_epoller = new myEpoller(); // 默认执行构造函数,当第一次调用获取单例之后,整个epoll模型就已经就绪了
return _epoller;
}
// 调用wait接口,epoller从就绪队列取出就绪事件并写入revs中,并且返回就绪事件的个数,返回值不会超过num
int Wait(struct epoll_event *revs, int num, int timeout)
{
// nfds不会超过num
int nfds = epoll_wait(_epfd, revs, num, timeout); // revs是输出型参数,调用方调用wait后可以直接拿到就绪的事件和fd,结合返回值全部取出
if (nfds < 0)
LOG(LogLevel::ERROR) << "epoll模型等待就绪事件失败";
return nfds;
}
bool Ctrl(int fd, uint32_t events, myCtrl op)
{
// 创建一个epoll_event结构体,并将自己关心的fd和事件写进去
struct epoll_event ev;
ev.events = events;
ev.data.fd = fd;
// 调用epoll_ctl接口,将自己关心的fd和事件写入到epoll模型的红黑树中并向fd注册服务,使得后续数据准备就绪后会自动添加到就绪队列中
int n = epoll_ctl(_epfd, static_cast<int>(op), fd, &ev); // op有不同类型,对应不同操作,add、del、mod
if (n < 0)
{
// 操作失败,针对不同操作类型返回错误信息
switch (op)
{
case myCtrl::ADD:
LOG(LogLevel::INFO) << "epoll模型添加fd完成";
break;
case myCtrl::DEL:
LOG(LogLevel::INFO) << "epoll模型删除fd完成";
break;
case myCtrl::MOD:
LOG(LogLevel::INFO) << "epoll模型修改fd完成";
break;
}
return false;
}
return true;
}
private:
int _epfd = -1; // epoll的文件描述符
// 采用懒汉模式,创建reactor对象的时候再创建这个Epoller对象
static myEpoller *_epoller; // 这里就用指针即可,没必要用智能指针,因为单例已经通过接口限制实现了
};
myEpoller *myEpoller::_epoller = nullptr;
}(2)Reactor和Connection

其中 using connection_t = std::shared_ptr<myConnection>;
反应堆模块包含我们刚才封装的epoller单例,可见的是reactor模块直接和epoller模块进行交互。并且reactor模块也包含connection_t,可见reactor模块也直接和用户连接交互,是一个中间层。
既然反应堆直接和epoller交互,那么reactor也承担向epoll模型添加connection_t事件,设置ET模式的责任,代码如下:
cpp
// 拷贝构造connection_t,connection_t是智能指针
void AddConnection(connection_t conn) // 在reactor看来所有的fd、事件都是connection,向epoll模型写的都是根据connection来的
{
std::unordered_map<int, connection_t>::iterator it = _connections.find(conn->GetSockfd()); // 每个connection代表一个连接,里面就有要关心的fd和事件,所以我们需要根据这个fd到哈希表中去找
if (it == _connections.end()) // 说明这个事件还没有出现过,说明是新连接,需要添加到epoll模型中
{
// 先将connection添加到哈希表中
_connections.insert(std::make_pair(conn->GetSockfd(), conn));
// 再将connection添加到epoll模型中
_epoller->Ctrl(conn->GetSockfd(), conn->GetEvents(), myCtrl::ADD);
// 每个进入reactor的connection都要设置回指指针,这样能够在connection中通过回指指针添加新的connection到epoll中
conn->SetReactor(this); // 设置回指指针,设置的信息会同步在哈希表中,因为conn是一个智能指针,指向的是同一块资源
LOG(LogLevel::INFO) << "新连接添加到反应堆中,epoller模块已接管,连接信息为" << conn->PrintAddr() << ",分配的fd为" << conn->GetSockfd();
}
else
LOG(LogLevel::WARNING) << "连接信息" << conn->PrintAddr() << "已存在反应堆中,无需重复添加";
}我们暂时先对reactor理解到这里,我们先处理connection的理解。reactor面向的都是一个一个的connection。

通过这个可知,每个connection都回指向反应堆,这就意味着通过回指指针,每个connection有权力修改自己或者其它connection在epoll模型中的所关心的事件,因为通过回指指针我们可以调用reactor模块里面的函数,而这些函数可以跟epoller交互。
connection是一个基类,其子类可以是Listener类或者IOService类,分别代表不同种类的connection实现,这套继承体系我们要理解。
Listener模块中一个重要的接口如下(建立连接):
cpp
// 有新连接了
void Recver() override
{
// ET模式下,反复读取,因为就绪事件只会通知一次
while (true)
{
myInetAddr peer_addr;
int peer_errno = 0;
int sockfd = _listensock->Accept(&peer_addr, &peer_errno); // 调用accept函数,获取新连接的fd和客户端的IP和端口号
if (sockfd > 0) // 获取的和客户端沟通的服务fd,这个fd应该创建connection对象并被插入到反应堆中
{
LOG(LogLevel::INFO) << " accept到一个新连接并分配fd:" << sockfd;
std::shared_ptr<myIOService> conn = std::make_shared<myIOService>(sockfd); // 创建一个新的connection对象,这个对象就是和客户端沟通的服务对象
conn->RegisterCallback(HandlerRequest); // 注册服务
conn->SetAddr(peer_addr); // 设置客户端的IP和端口号
// 插入到Epoll模型中,利用回指指针
GetReactor()->AddConnection(conn); // 把这个connection对象插入到反应堆中
}
else // 读取失败,做异常处理
{
if (peer_errno == EAGAIN || peer_errno == EWOULDBLOCK)
{
LOG(LogLevel::INFO) << "已经accept所有的连接";
std::cout << "当前缓冲区:" << _inbuffer;
break;
}
else if (peer_errno == EINTR)
{
LOG(LogLevel::INFO) << "连接被信号中断,重新连接";
continue;
}
else
{
LOG(LogLevel::WARNING) << "accepte错误,退出连接";
break;
}
}
}
}
我们可以验证,在connection继承体系下,我们利用基类的回指指针就可以将创建的连接的connection插入到epoll模型中。
这时,我们再回到reactor中,理解其Loop函数
cpp
void LoopOnce(int timeout)
{
// 调用epoll模型的wait接口,等待就绪事件
int nfds = _epoller->Wait(_revs, event_num, timeout);
Dispatcher(nfds); // 这个时候就绪的事件已经写到_revs里面了,根据返回值nfds就能对里面的事件进行完全的梳理
}
void Dispatcher(int nfds)
{
for (int i = 0; i < nfds; i++)
{
// 取出就绪的fd
int sockfd = _revs[i].data.fd;
// 取出就绪的事件,主要是用于异常处理转换
uint32_t events = _revs[i].events;
// 根据就绪事件的类型进行处理
if ((events & EPOLLERR) | (events & EPOLLHUP))
events = (EPOLLIN | EPOLLOUT); // 首先将异常事件转为读写事件,读写错误后再进行进一步处理
// 异常处理后有可能文件就被关了,所以要先判断sockfd是否合法。可以预见的是异常处理都会在Recver()里面被处理
if ((events & EPOLLIN) && isConnectionInReactor(sockfd))
_connections[sockfd]->Recver(); // 该connection触发了读事件,这个connection里面会有相关的处理方式,调用即可。对反应堆来说,一切连接都叫connection
if ((events & EPOLLOUT) && isConnectionInReactor(sockfd))
_connections[sockfd]->Sender();
}
}
void PrintConnections()
{
std::cout << std::endl
<< "当前反应堆中连接信息如下:" << std::endl;
for (auto &conn : _connections)
std::cout << "fd:" << conn.first << ",连接信息为" << conn.second->PrintAddr() << std::endl;
std::cout << std::endl;
}
// 启动反应堆后就进入这个函数
void Loop()
{
int timeout = 1000 * 10; // 10s 称为一次超时
while (_isrunning)
{
// 事件管理
LoopOnce(timeout);
// 管理信息打印
PrintConnections();
// 超时管理等其它模块均可在这里拓展
}
}这和之前poll和select的代码及其相似,通过派发器,reactor会将就绪的事件派发给不同的connection,而这些connection就是Listener或者IOService模块,不同模块会重写自己的Sender(),Recver(),Excepter()函数,实现多态。

这时我们也就能理解IOservice里面函数的作用了
cpp
void Sender() override
{
while(true) // 一直写直到失败
{
int n = send(GetSockfd(), _outbuffer.c_str(), _outbuffer.size(), 0);
if(n > 0)
EraseOutBuffer(n);
if(n == 0)
break;
else
{
if(errno == EAGAIN || errno == EWOULDBLOCK) // 缓冲区写满了
break;
else if(errno == EINTR)// 被信号打断,重新写
continue;
else
{
Excepter(); // 读写错误转为异常处理
return;
}
}
}
// 走到这里的代码不是异常错误,也不是信号错误,而是缓冲区写满了或者发送完毕了
if(!isOutBufferEmpty()) // 说明是对方缓冲区写满了
GetReactor()->ModConnection(GetSockfd(), true, true); // 再次添加对读写事件的关心
else // 说明发送完毕了,outbuffer里面已经没有需要再发送的数据了,所以不再需要关心写事件了
GetReactor()->ModConnection(GetSockfd(), true, false); // 不再关心写事件
}
void Recver() override
{
LOG(LogLevel::INFO) << "fd:" << GetSockfd() << ",触发读事件";
while(true) // 一直读直到失败
{
char buffer[size] = { 0 };
int n = recv(GetSockfd(), buffer, size - 1, 0); // 非阻塞
if(n > 0)
{
buffer[n] = 0; // 补全字符串的\0
AppendInBuffer(buffer);
}
else if(n == 0)
{
Excepter();
break;
}
else
{
if(errno == EAGAIN || errno == EWOULDBLOCK)
break; // 缓冲区读完了
else if(errno == EINTR)
continue; // 被信号打断,重新读
else
{
Excepter(); // 读写错误转为异常处理
return;
}
}
}
// 走到这里的代码不是异常错误,也不是信号错误,而是缓冲区读完了或者对方关闭了连接
std::cout << "接收到的消息为:" << std::endl << _inbuffer;
std::string result;
if(_fun)
result = _fun(_inbuffer); // 调用上层注册的方法,得到处理后的结果
LOG(LogLevel::INFO) << "处理后的结果为:" << result;
// 添加到应答中
AppendOutBuffer(result);
if(_inbuffer == "QUIT")
{
_inbuffer.clear(); // 去掉前4个字符
LOG(LogLevel::INFO) << "客户端请求退出";
}
// 触发写事件,自动处理缓冲区的发送任务
if(!isOutBufferEmpty())
GetReactor()->ModConnection(GetSockfd(), true, true); // 把应答的结果写回给客户端,添加写事件之后自动触发写过去
}
void Excepter() override
{
LOG(LogLevel::INFO) << "触发异常处理,sockfd为" << GetSockfd();
// 触发异常处理,将该连接从反应堆中移除
GetReactor()->DelConnection(GetSockfd()); // 移除之后connection自动调用析构函数,自动close文件
}在这里,我们能看到服务端的connection,只要数据发送完毕,之后就设置该fd取消对写事件的关心。读完毕并处理数据完之后,需要发回客户端,写的时候再打开对写事件的关心,写事件处理完之后继续关闭写事件关心,打开读事件关心。一切IO的触发都是交给通过回指指针,交由reactor所管理的epoll模型来派发的,并不是说收到数据处理之后直接调用Sender()写回结果,而是设置到epoller中,由epoller统一调用。
(3)IOService注册服务
这个IOService要处理怎样的任务呢?由上层决定,我们仅需提供设置接口,在收到数据后调用该接口处理即可。


这不就是epoll的底层原理中上层向下层注册服务的方法吗?设计思想是一致的。
于是,IOService就是一个负责接收数据、处理数据的模块,而处理数据的方法和该模块解耦,我们上层可以传入各种各样的处理方法,得到相应的结果。
(4)反应堆模式设计结构
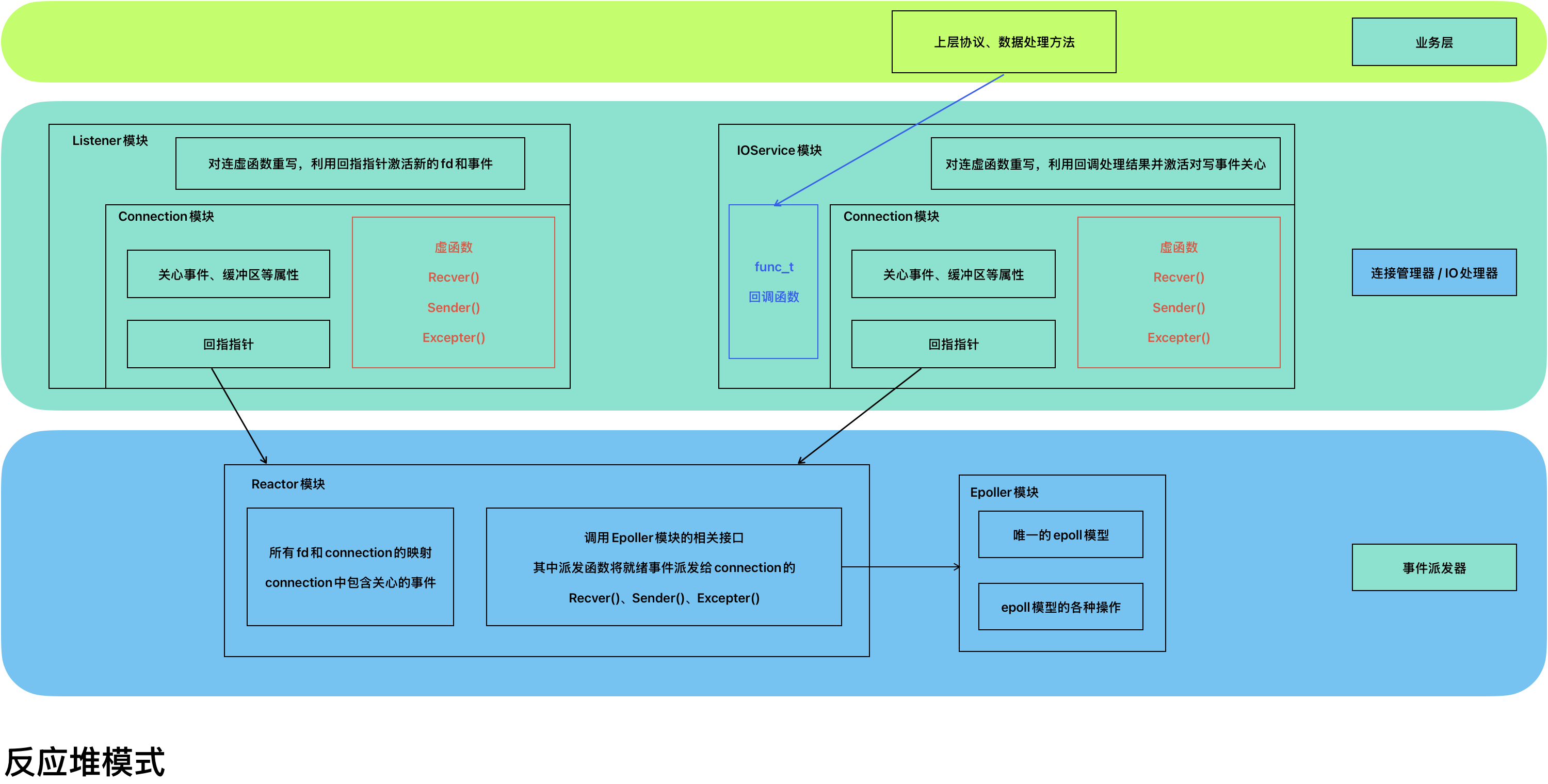
(5)对不同模块之间耦合方式的理解
反应堆模式毫无疑问采用了模块化设计,但它如何让不同的模块之间耦合起来非常值得我们学习。
①上层向下层注册服务
这在epoll模型的底层实现,信号驱动式IO的底层实现上已经见过。
在反应堆模式中,IOService对应的connection负责和客户端通信,Recver()主要负责三件事:接收数据、处理数据、激活写事件。 其中处理数据就是调用一个默认为空的fun(),并且IOService对外提供一个设置fun的接口,上层可以通过这个接口传入任何函数,而下层都会去实现,这个就是上层向下层注册服务。 通过这种方式,我们实现了处理数据操作和处理方法之间的接耦,将IOService变得更加通用了。
②回指指针影响下层
Listener模块调用Recver()获取到连接之后怎么办?创建IOService,但怎么将这个IOService写透到下层的服务中呢,即让Reactor模块的epoller关心该connection的事件?
回指指针!connection里面有着指向reactor的回指指针,当Listener得到连接并创建IOService之后,它直接用基类的回指指针指向下层,进入下层,并调用下层reactor里面的成员函数,将新连接写透到epoll模型中。
其实在反应堆模式中,最底层是Epoller,reactor只能算第二层,那reactor怎么将关心的fd和事件写入到epoll模型中呢?调用epoller对外提供的成员函数。但问题是怎么调用的呢?
本质上也是个回指指针!
③对上下层模块耦合的理解
前面两个例子中,似乎都是上层影响下层。其实在我们的模块化设计中,上下层关系一定存在,那么在上下层进行耦合的过程中,下层影响上层是最轻松的,而上层影响下层是困难的。 因为上层天然受到下层类的影响,上层可以通过调用接口修改下层类的一些属性,而下层的属性改变会直接影响上层。从另一个角度上说,上层也影响了下层,但目的是不一样的,影响到了下层是手段,目的是影响上层,这个我们要区分开。 但上层想要影响下层很困难,回指指针和上层向下层注册服务就是其中的解决方案,第一次接触时我们其实难以接受。
用一个形象的例子就能理解了,房子是由地基和上层建筑构成的。房子塌了,地基还在,对于地基而言,它能独立存在,它不依赖上层建筑,就算没有上层建筑,地基一样好好的。而上层建筑却依赖地基,地基随便一动,上层建筑就会受到影响。