1.背景
运维对pod的总内存以及pod的使用内存进行监控,当pod的使用内存达到80%之后会触发相应的告警,实际上会触发偶尔91%的占用告警
2.排查过程
2.1 查看grafana pod的内存占用情况

发现其服务使用的内存是稳步上升的并在14点左右达到峰值
2.2 查询JVM以及相关线程信息
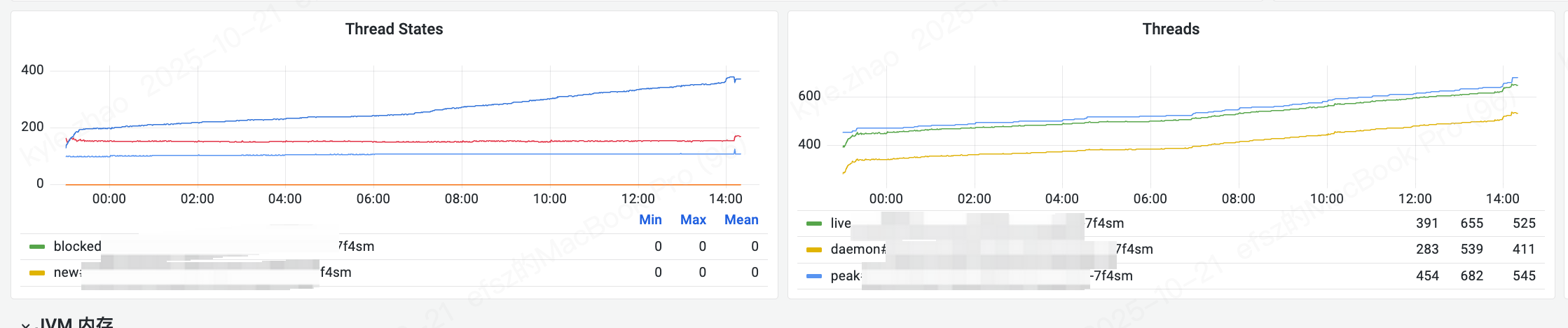
查看线程数是一直往上涨的
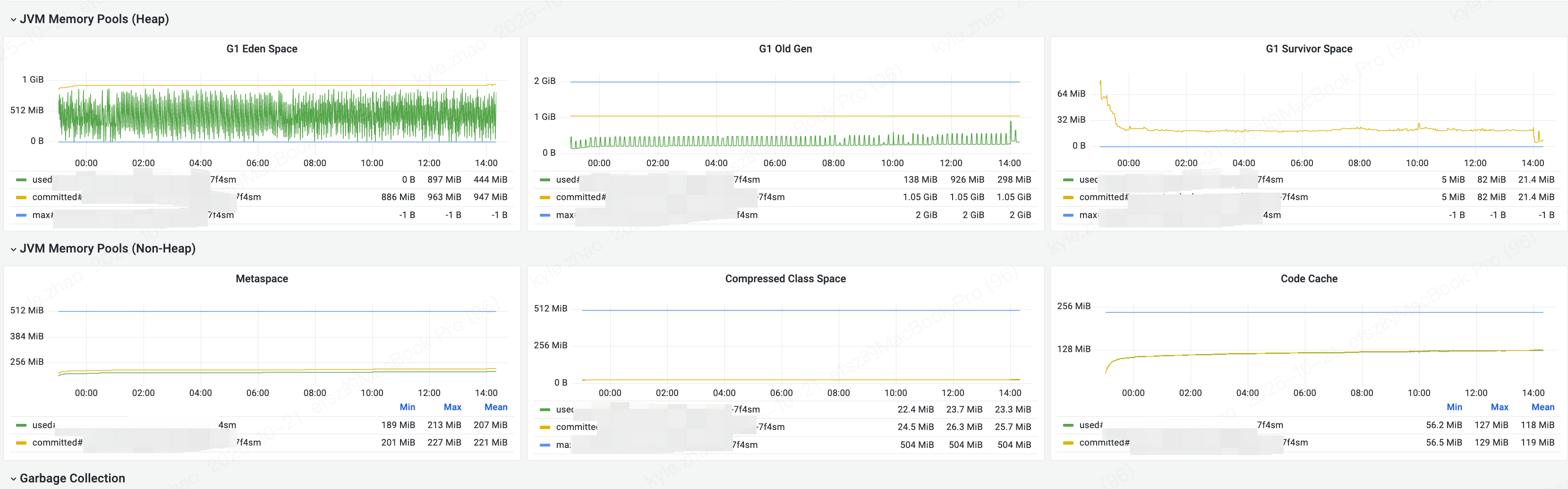
堆内存以及非堆(元数据、类信息、机器码的占用都是较为稳定的)
2.3 查看启动参数
bash
java -Duser.language=en -Duser.country=US -Duser.timezone=Asia/Shanghai -Djava.security.egd=file:///dev/urandom -Dsun.net.client.defaultConnectTimeout=5000 -Dsun.net.client.defaultReadTimeout=60000 -Dspring.jmx.enabled=false -Dspring.backgroundpreinitializer.ignore=true -Djava.util.concurrent.ForkJoinPool.common.parallelism=10 -cp /app:/app/lib/* -Xmx2G -Xms2G -XX:+UseG1GC -XX:+UnlockExperimentalVMOptions -XX:G1MaxNewSizePercent=45 -XX:InitiatingHeapOccupancyPercent=30 -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError=/quitJava.sh -XX:HeapDumpPath=/var/logs/dump/usercenter.hprof -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/var/logs/dump/gc-usercenter.log -javaagent:/arms/ArmsAgent/arms-bootstrap-1.7.0-SNAPSHOT.jar -Darms.licenseKey=cs4c3rve40@5cd8543bd7364f7 -DserviceLibs.report=false -Darms.appName=usercenter -Drocketmq.client.logLevel=error -jar /app.jar实际上堆内存固定在了2G、元数据空间最大为512M
2.4 查看k8s pod yaml
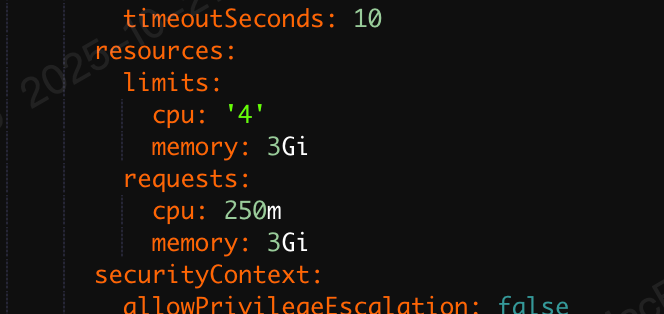
发现pod的内存固定为3G
2.5 查看JVM内存信息以及进程占用内存信息
bash
jcmd <pid> GC.heap_info
awk '/VmRSS/ {printf "PID %d RSS: %.2f MB\n", PID, $2/1024}' PID=<pid> /proc/<pid>/status
看到实际进程占用内存为2838m
JVM各部分占用内存 堆2G、元空间230M、压缩类26M
3、结论
3.1、原因分析
pod只有3G内存,但实际上pod内存使用为主应用占用的内存+其他进程占用的内存
主应用占用的内存 = 2G(堆内存) + 元数据(227M) + 压缩类空间(26M) + Code Cache
编译机器码(130M) + 线程数534个(1个1M) = 2.9G左右

与实际2838M结果差不多
告警的主要原因是pod的request内存只设置了3G,部署久了之后,随着元数据和线程数增长,就导致JVM堆占用了2G + 元数据 + 线程每个1M + 堆外达到了2800M就触发了对应的占用过高的告警,然后随着元数据和线程的释放,会反复触发对应的告警
3.2、解决方案
需要运维将pod的内存调整为4G
4、相关资料
JVM内存组成
| 内存区域 | 说明 |
|---|---|
| Heap | G1GC 堆内存 |
| Metaspace + Class | 元空间+类信息 |
| Thread Stack | 每线程栈约 1 MB × 线程数 |
| DirectByteBuffer / Unsafe 内存 | Netty、ByteBuffer、I/O 缓冲等 |
| CodeCache | JIT 编译后的机器码 |
| Agent(ARMS) | Java Agent 开销 |
| 其他堆外 | JVM 内部缓存、锁信息等 |