一、RNN基本概念与数学原理
1.1 RNN的核心思想
循环神经网络(RNN)是一种专门用于处理序列数据的神经网络结构。与传统的前馈神经网络不同,RNN引入了"记忆"的概念,能够利用之前的处理结果来影响当前的输出。
1.2 RNN的数学表示
RNN的核心计算过程可以用以下公式表示:
text
当前时刻隐藏状态:h_t = σ(W_h * h_(t-1) + W_x * x_t + b_h)
当前时刻输出:y_t = σ(W_y * h_t + b_y)其中:
- h_t:当前时刻的隐藏状态(存储历史信息)
- h_(t-1):上一时刻的隐藏状态
- x_t:当前时刻的输入
- y_t:当前时刻的输出
- W_h, W_x, W_y:权重矩阵(需要学习的参数)
- b_h, b_y:偏置项
- σ:激活函数(如tanh、ReLU等)
1.3 计算过程图解
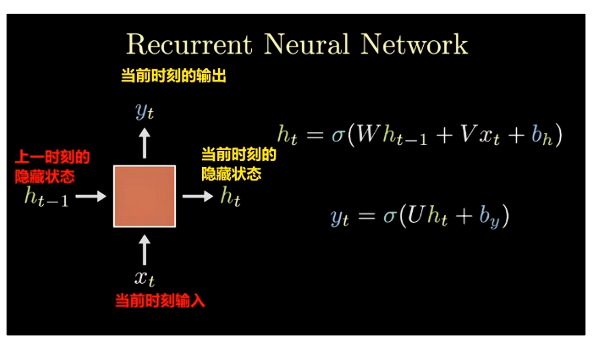
- 隐藏状态更新 :结合上一时刻的隐藏状态
h_(t-1)和当前输入x_t - 加权求和 :通过权重矩阵
W_h和W_x进行线性变换 - 激活函数处理 :使用非线性激活函数
σ增强模型表达能力 - 输出生成 :基于当前隐藏状态
h_t计算输出y_t
二、文本生成任务的数据预处理
2.1 文本预处理流程
python
import jieba
def preprocess_text(corpus):
"""
文本预处理完整流程
"""
# 1. 分词处理
words = []
for sentence in corpus:
seg_list = jieba.cut(sentence)
words.extend(seg_list)
# 2. 构建词表
unique_words = list(set(words)) # 去重
vocab_size = len(unique_words) # 词表大小
# 3. 创建词到索引的映射
word_to_idx = {word: i for i, word in enumerate(unique_words)}
idx_to_word = {i: word for i, word in enumerate(unique_words)}
return words, word_to_idx, idx_to_word, vocab_size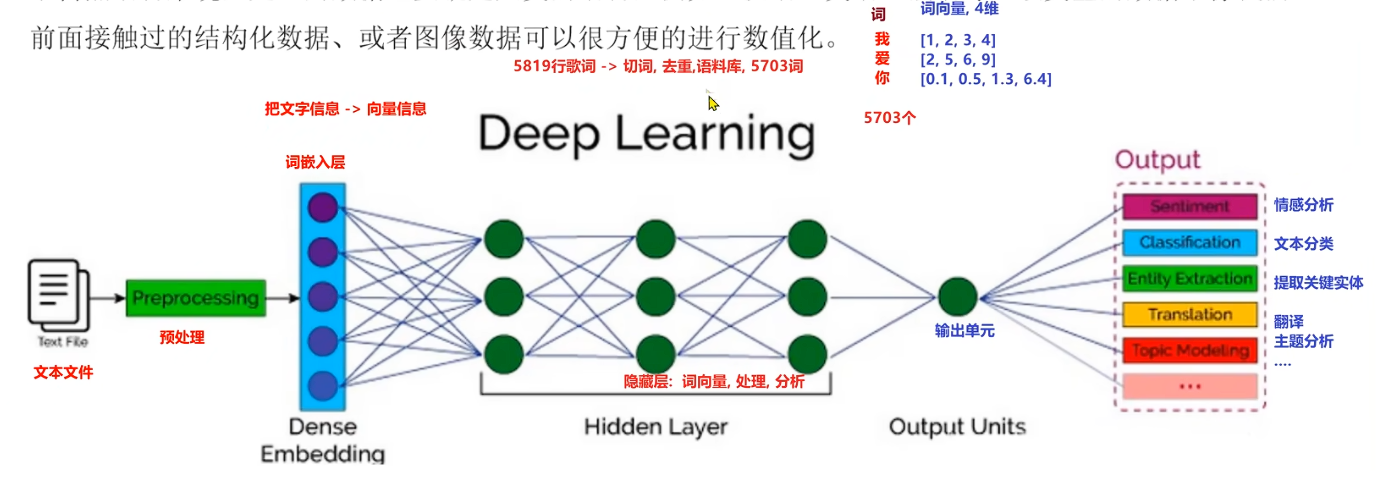
2.2 词嵌入层的作用
在词嵌入层之前,需要对数据进行预处理:
- 分词:将句子切分为词语序列
- 去重:统计所有不重复的词语
- 建立映射:创建词语↔索引的双向映射
- 参数传入:将去重后的词数量(如5703)传入嵌入层
三、PyTorch实现RNN文本生成器
3.1 完整的RNN模型实现
python
python
import torch
import torch.nn as nn
class TextGenerator(nn.Module):
def __init__(self, vocab_size, embedding_dim=128, hidden_dim=256, n_layers=1):
"""
初始化RNN文本生成模型
参数:
vocab_size: 词汇表大小(去重后的词数量,如5703)
embedding_dim: 词向量维度
hidden_dim: 隐藏层维度
n_layers: RNN层数
"""
super(TextGenerator, self).__init__()
# 保存参数
self.vocab_size = vocab_size
self.hidden_dim = hidden_dim
self.n_layers = n_layers
# 1. 词嵌入层:将词索引转换为稠密向量
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# 2. RNN层:处理序列信息
self.rnn = nn.RNN(
input_size=embedding_dim,
hidden_size=hidden_dim,
num_layers=n_layers,
batch_first=False # PyTorch默认格式:(seq_len, batch, features)
)
# 3. 输出层:将隐藏状态转换为词汇表上的概率分布
self.fc = nn.Linear(hidden_dim, vocab_size)
# 4. Dropout层(可选,防止过拟合)
self.dropout = nn.Dropout(0.2)
def forward(self, x, hidden=None):
"""
前向传播过程
参数:
x: 输入序列,形状为 (batch_size, seq_len)
hidden: 初始隐藏状态,默认为None
返回:
output: 预测结果,形状为 (seq_len, batch_size, vocab_size)
hidden: 更新后的隐藏状态
"""
batch_size = x.size(0)
# 如果没有提供隐藏状态,则初始化
if hidden is None:
hidden = self.init_hidden(batch_size)
# 1. 词嵌入:整数索引 -> 词向量
# 输入: (batch_size, seq_len) -> 输出: (batch_size, seq_len, embedding_dim)
embedded = self.embedding(x)
# 2. 转置维度以适应RNN输入格式
# PyTorch RNN期望格式: (seq_len, batch_size, embedding_dim)
embedded = embedded.transpose(0, 1)
# 3. 应用Dropout
embedded = self.dropout(embedded)
# 4. RNN处理
# output: (seq_len, batch_size, hidden_dim) - 每个时间步的隐藏状态
# hidden: (n_layers, batch_size, hidden_dim) - 最后一个时间步的隐藏状态
output, hidden = self.rnn(embedded, hidden)
# 5. 转置回来以便后续处理
output = output.transpose(0, 1)
# 6. 展平维度以通过全连接层
# 形状: (batch_size * seq_len, hidden_dim)
output = output.reshape(-1, self.hidden_dim)
# 7. 全连接层得到词汇表上的概率分布
output = self.fc(output)
# 8. 恢复序列维度
# 形状: (batch_size, seq_len, vocab_size)
output = output.view(batch_size, -1, self.vocab_size)
return output, hidden
def init_hidden(self, batch_size):
"""
初始化隐藏状态
返回:
hidden: 全零的隐藏状态,形状为 (n_layers, batch_size, hidden_dim)
"""
device = next(self.parameters()).device
return torch.zeros(self.n_layers, batch_size, self.hidden_dim, device=device)3.2 维度变化详解
text
输入序列: (batch_size=32, seq_len=20)
↓ 词嵌入层
嵌入表示: (32, 20, 128)
↓ 转置
RNN输入: (20, 32, 128)
↓ RNN层
RNN输出: (20, 32, 256) # hidden_dim=256
↓ 转置
中间结果: (32, 20, 256)
↓ 展平
全连接输入: (640, 256) # 32*20=640
↓ 全连接层
全连接输出: (640, 5703) # vocab_size=5703
↓ 恢复维度
最终输出: (32, 20, 5703)四、训练与优化
4.1 损失函数与优化器
python
# 初始化模型
vocab_size = 5703
model = TextGenerator(vocab_size)
# 定义损失函数 - 交叉熵损失适用于分类任务
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)优化器的作用:
优化器优化的是神经网络的参数更新过程,通过计算损失函数对参数的梯度,智能地调整参数值,使损失函数最小化。
4.2 训练循环
python
def train_epoch(model, dataloader, criterion, optimizer, device):
"""
训练一个epoch
"""
model.train()
total_loss = 0
for batch_idx, (inputs, targets) in enumerate(dataloader):
# 将数据移动到设备
inputs, targets = inputs.to(device), targets.to(device)
# 初始化隐藏状态
hidden = model.init_hidden(inputs.size(0))
# 前向传播
outputs, hidden = model(inputs, hidden)
# 计算损失
# 需要将输出和目标调整为合适的形状
loss = criterion(
outputs.view(-1, model.vocab_size), # (batch*seq_len, vocab_size)
targets.view(-1) # (batch*seq_len)
)
# 反向传播
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
# 梯度裁剪(防止梯度爆炸)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
optimizer.step() # 更新参数
total_loss += loss.item()
if batch_idx % 100 == 0:
print(f'Batch {batch_idx}, Loss: {loss.item():.4f}')
return total_loss / len(dataloader)五、RNN的优缺点与改进
5.1 RNN的优点
- 序列建模能力强:能够处理变长序列数据
- 参数共享:不同时间步共享权重,减少参数量
- 记忆能力:能够利用历史信息
- 灵活性:适用于多种序列任务
5.2 RNN的局限性
- 梯度消失/爆炸:长序列训练困难
- 短期记忆:难以捕捉长期依赖
- 计算效率:无法并行处理序列
5.3 改进方案
python
# 1. 使用LSTM(长短期记忆网络)
class LSTMTextGenerator(nn.Module):
def __init__(self, vocab_size, embedding_dim=128, hidden_dim=256, n_layers=2):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, n_layers,
batch_first=False, dropout=0.3)
self.fc = nn.Linear(hidden_dim, vocab_size)
# 2. 使用GRU(门控循环单元)
class GRUTextGenerator(nn.Module):
def __init__(self, vocab_size, embedding_dim=128, hidden_dim=256, n_layers=2):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.gru = nn.GRU(embedding_dim, hidden_dim, n_layers,
batch_first=False, dropout=0.3)
self.fc = nn.Linear(hidden_dim, vocab_size)六、总结与最佳实践
6.1 关键要点
- 维度匹配:注意PyTorch中RNN的输入输出维度要求
- 隐藏状态管理:正确初始化和传递隐藏状态
- 序列长度:合理选择序列长度平衡效果和效率
- 梯度处理:使用梯度裁剪防止梯度爆炸
6.2 实践建议
- 预处理充分:文本清洗、分词、构建高质量词表
- 超参数调优:学习率、隐藏层大小、序列长度等
- 模型评估:使用困惑度(Perplexity)评估生成质量
- 批次处理:合理设置批次大小提高训练效率
6.3 扩展阅读方向
- 注意力机制:增强对关键信息的关注
- Transformer架构:完全基于注意力的序列模型
- 预训练语言模型:BERT、GPT等大规模预训练模型
- 多模态生成:结合图像、音频等多模态信息
择序列长度平衡效果和效率
- 梯度处理:使用梯度裁剪防止梯度爆炸
6.2 实践建议
- 预处理充分:文本清洗、分词、构建高质量词表
- 超参数调优:学习率、隐藏层大小、序列长度等
- 模型评估:使用困惑度(Perplexity)评估生成质量
- 批次处理:合理设置批次大小提高训练效率
6.3 扩展阅读方向
- 注意力机制:增强对关键信息的关注
- Transformer架构:完全基于注意力的序列模型
- 预训练语言模型:BERT、GPT等大规模预训练模型
- 多模态生成:结合图像、音频等多模态信息
通过本文的讲解,你应该已经掌握了RNN的基本原理、PyTorch实现方法以及文本生成的应用。实际应用中,可以根据具体任务需求调整网络结构、超参数和训练策略,以获得更好的效果。