目录
[为什么在 序列模型 中 使用 普通神经网络(如全连接网络)和CNN 效果不好?](#为什么在 序列模型 中 使用 普通神经网络(如全连接网络)和CNN 效果不好?)
[方案A: 马尔科夫假设](#方案A: 马尔科夫假设)
[方案B: 隐变量模型](#方案B: 隐变量模型)
[解决------梯度裁剪 (针对梯度爆炸)](#解决——梯度裁剪 (针对梯度爆炸))
[情感分类 (many-to-one 任务)](#情感分类 (many-to-one 任务))
[门控循环单元 GRU](#门控循环单元 GRU)
[GRU 的门控计算](#GRU 的门控计算)
[GRU 的隐状态更新流程](#GRU 的隐状态更新流程)
[LSTM 的三门机制与状态更新](#LSTM 的三门机制与状态更新)
[第一步:决定遗忘什么 ------ 遗忘门](#第一步:决定遗忘什么 —— 遗忘门)
[第二步:输入门 ------ 决定向长期记忆中写入什么](#第二步:输入门 —— 决定向长期记忆中写入什么)
[第四步:输出门 ------ 决定当前输出(隐状态)是什么](#第四步:输出门 —— 决定当前输出(隐状态)是什么)
[RNN 的核心思想](#RNN 的核心思想)
[LSTM 的核心思想](#LSTM 的核心思想)
[GRU 的核心思想](#GRU 的核心思想)
序列数据
- 序列数据是 按顺序排列 的数据,其中 前后元素之间存在依赖关系。
【PTA题目】
为什么在 序列模型 中 使用 普通神经网络(如全连接网络)和CNN 效果不好?
(1)难以有效建模长期依赖关系
全连接网络:输入维度固定,当序列变长时参数爆炸,且难以学习元素间的远距离依赖。
CNN:依靠局部卷积核,需要堆叠多层才能扩大感受野,导致信息传递路径长、易丢失,效率低下。
(2)对序列顺序不敏感
全连接网络:打乱输入顺序不影响输出,无法感知序列顺序。
CNN:仅能捕捉局部顺序,对全局顺序和位置关系建模能力弱。
(3)处理可变长度序列不灵活
全连接网络:必须固定输入长度,需填充或截断,造成信息损失。
CNN:对长度变化适应性较差,结构设计通常针对规整输入。
(4)参数共享效率低
全连接网络:无跨位置参数共享,计算冗余。
CNN:仅在局部窗口内共享参数,难以像RNN或Transformer那样实现全局高效的参数共享。
相比之下,RNN/LSTM通过循环结构自然传递状态,适合处理序列顺序和动态长度;Transformer通过自注意力和位置编码,能直接捕捉全局依赖。
序列模型
序列模型的两种建模方案
【考点总结】
方案A: 马尔科夫假设
方案B: 隐变量模型
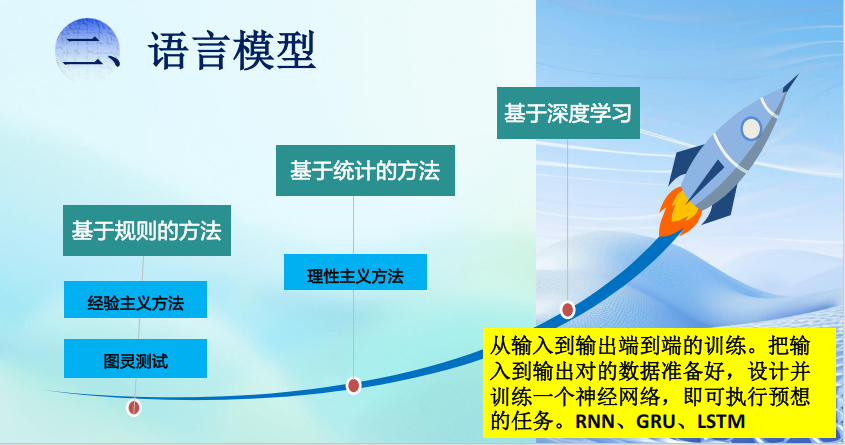
语言模型
建模概率---基于统计的方法
基于计数的统计模型
引入马尔科夫假设简化------N元语法
RNN
- RNN通过一个循环传递的"记忆单元"(隐状态),将历史信息动态地融入当前计算,从而赋予神经网络对序列数据的建模能力。
工作流程
- RNN的输出取决于当前输入 和前一时刻的隐变量(记忆)。
RNN的前向传播 :
RNN的损失函数计算:平均交叉熵损失
- 整个序列(一个句子)作为一个训练实例,总误差就是各个时刻词的误差之和取平均。
RNN的训练------时间反向传播 (BPTT)
- RNN的训练也使用梯度下降 ,但因其时间步之间共享参数且存在循环连接 ,计算梯度的方法比普通神经网络更复杂,称为 时间反向传播。
RNN的核心挑战------梯度消失与梯度爆炸
解决------梯度裁剪 (针对梯度爆炸)
核心思想 :在更新参数之前,检查所有梯度的L2范数 (总大小)。如果超过某个预设的阈值 θ,就将所有梯度按比例缩小,使总范数等于 θ。
【小结】
RNN用什么算法训练?
BPTT(时间反向传播),一种沿时间轴进行反向传播的算法。BPTT和标准反向传播有什么区别?
核心区别在于梯度累积 :BPTT需要对所有时间步上共享参数的梯度进行求和,因为同一个参数在每个时间步都被使用并影响最终的损失。
RNN训练的两大核心挑战是什么?
梯度消失 与梯度爆炸。梯度消失/爆炸的根本数学原因是什么?
根本原因是梯度计算中包含跨越多个时间步的雅可比矩阵连乘。当这些雅可比矩阵的特征值持续小于1时,连乘积指数级趋零(消失);持续大于1时,指数级发散(爆炸)。
如何解决梯度爆炸?
采用梯度裁剪:在参数更新前,如果梯度向量的范数超过预设阈值,就按比例缩小整个梯度向量,防止更新步伐过大。
RNN在NLP中的完整应用流程
情感分类 (many-to-one 任务)
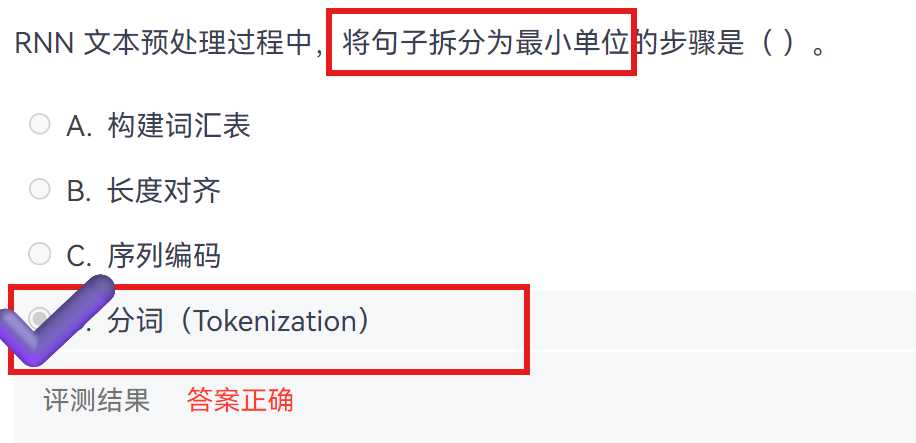
第一步:文本预处理
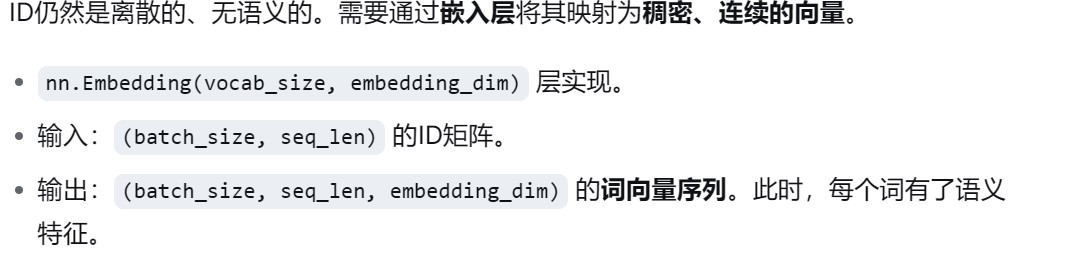
第二步:词向量嵌入
第三步:RNN循环计算
将词向量序列按时间步输入RNN。
RNN根据公式
逐步更新隐状态。
每个时间步都会产生一个输出状态(包含了到当前为止的上下文信息)。
第四步:任务特定输出
对于情感分类(many-to-one) 任务:
通常只取最后一个时间步的隐状态
H_last(因为它理论上概括了整个句子的信息)。将
H_last输入一个全连接层 + Sigmoid激活函数,得到最终的分类概率。RNN语言模型的损失函数
应用于语言模型时,RNN根据当前词预测下一时刻的词。
损失函数:序列级平均交叉熵损失
对一个序列中每个时间步的预测误差(交叉熵) 进行求和并取平均。
评估指标:困惑度( 衡量模型预测的不确定性,值越小越好。)
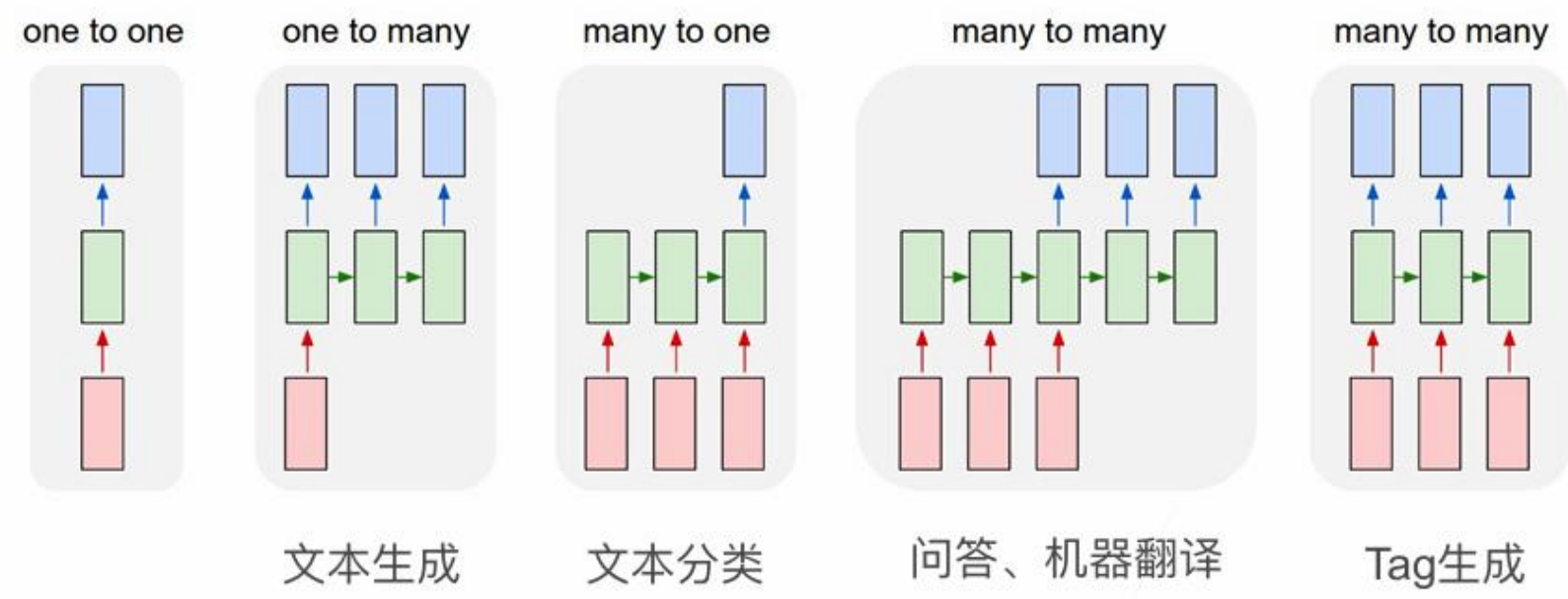
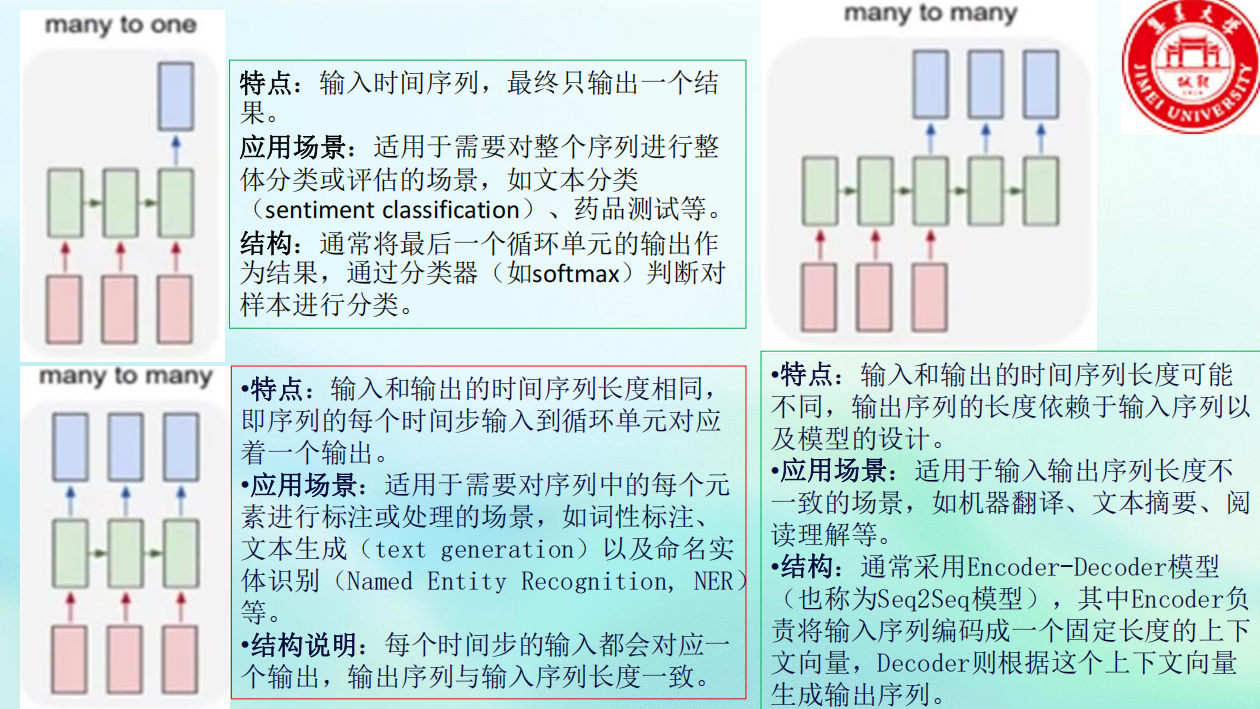
RNN的输入输出类型
One to One:经典神经网络,非RNN典型结构。
One to Many :单输入,序列输出。
应用:图像描述生成(输入一张图片,输出一句话)。
Many to One :序列输入,单输出。
应用 :情感分类 、文本分类。结构 :用最后一个时间步的隐状态作分类。
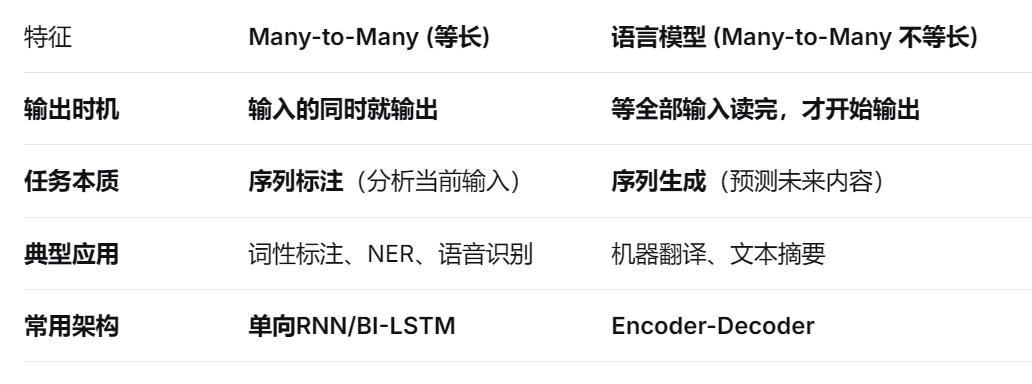
Many to Many (不等长) :序列输入,不等长序列输出。
应用 :机器翻译、文本摘要。
Encoder-Decoder(Seq2Seq) 框架。
核心思想:编码器将输入序列压缩为上下文向量,解码器基于该向量生成输出序列。
Many to Many (等长) :序列输入,等长序列输出。
应用 :词性标注、命名实体识别。结构 :每个时间步都有对应输出。
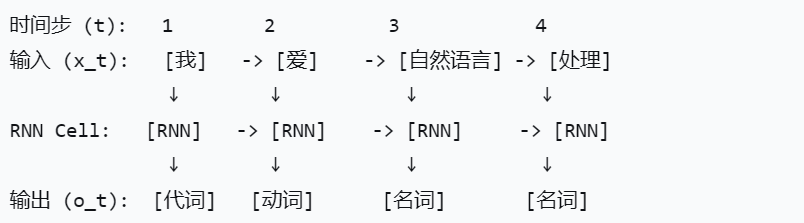
关键点:
当RNN读入第一个词
"我"时,它不是 去预测下一个词"爱",而是直接输出 对当前词"我"的判定:"代词"。然后,它带着这个状态读入第二个词
"爱",输出对"爱"的判定:"动词"。以此类推,读完即标完。输入序列结束,输出序列也同时结束,且长度一致。
门控循环单元 GRU
设计动机
普通RNN存在梯度消失 问题,难以学习长距离依赖。GRU(以及LSTM)的提出,就是为了有选择性地记忆和遗忘信息,从而让信息(梯度)在长序列中更稳定地传递。
核心思想
GRU的核心思想是不是每个输入都同等重要,也不是所有历史记忆都需要完整保留到未来。
它通过引入 "门控"机制 来实现对信息流的精细化控制。
GRU有两个核心门:
重置门 :控制过去的记忆有多少需要与当前输入结合 ,用于计算新的候选信息。
更新门 :控制要从过去记忆中保留多少信息,以及要加入多少新信息 ,从而更新最终状态。
GRU 的门控计算
GRU 的隐状态更新流程
【说明】
【说明】
【思考】
如果将重置门设置为1,更新门设置为0,会发生什么?
在这种极端设置下,GRU的行为退化为一个稍微复杂一点的基础RNN。它虽然使用了全部旧记忆来计算新状态,但最终却完全用新状态覆盖了旧状态,没有实现"记忆的持续保留"。
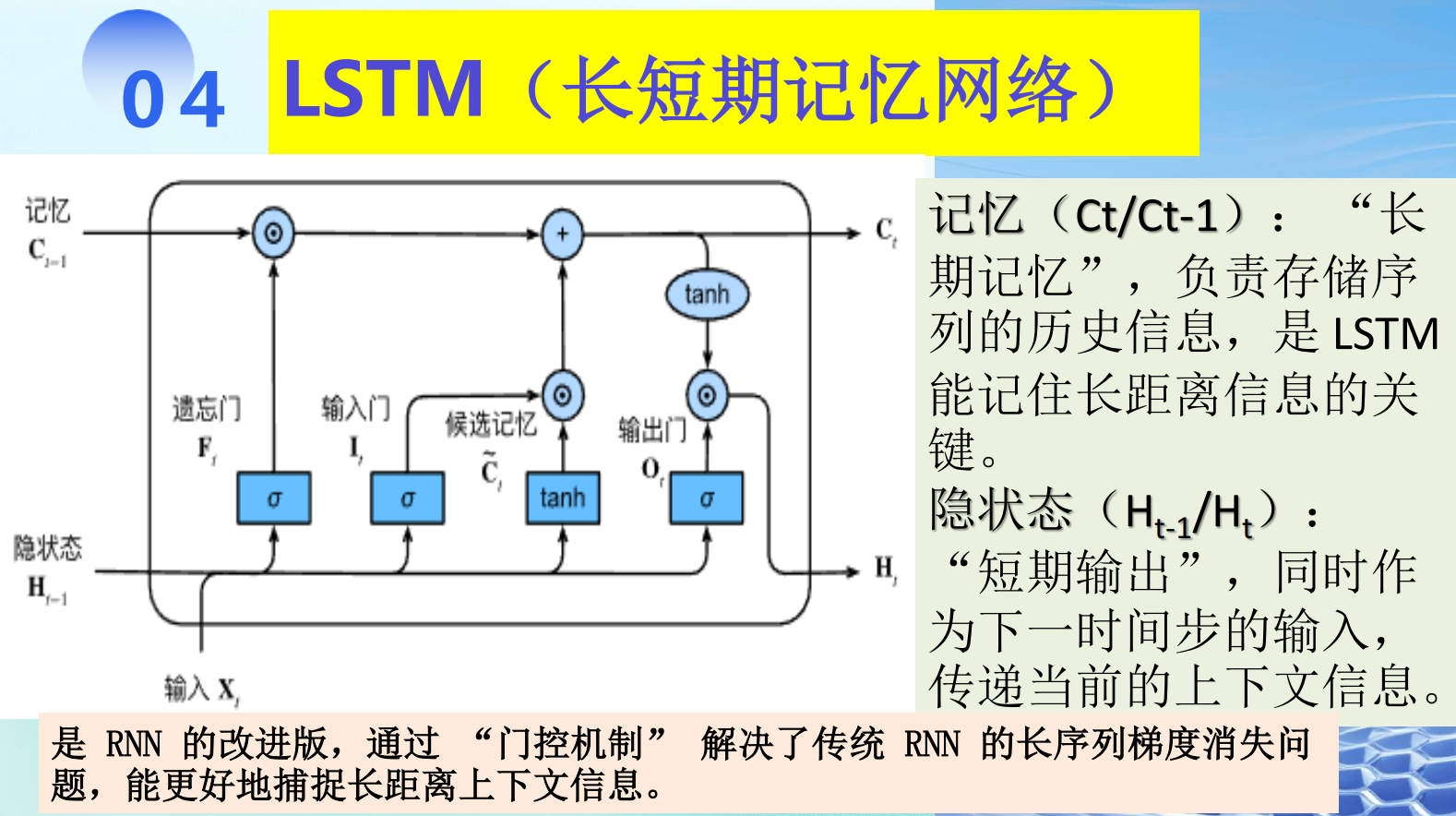
长短期记忆网络(LSTM)
细胞状态 :称为 "长期记忆" ,用 Ct 表示。它像一个传送带 ,只在关键位置进行线性微调 ,因此梯度可以在此路径上更稳定地流动,不易消失。它负责保存从序列开始至今的长期信息。
隐状态 :称为 "短期输出" ,用 Ht 表示。它是细胞状态经过过滤后的产物,作为当前时间步的输出,并传递给下一个时间步作为"短期记忆"输入。它更多地反映了与当前输入相关的信息。
LSTM 的三门机制与状态更新
LSTM在每个时间步
t的输入 和已有信息:
- LSTM通过三个门 和一个候选状态来控制细胞状态的更新。
第一步:决定遗忘什么 ------ 遗忘门
工作过程 :
将拼接后的向量
数值接近1:表示"保留"对应维度上的旧记忆。
数值接近0:表示"遗忘"对应维度上的旧记忆。
第二步:输入门 ------ 决定向长期记忆中写入什么
这步包含两个计算:一个门决定写多少,一个候选值决定写什么。
1. 输入门公式:
2. 候选细胞状态公式:
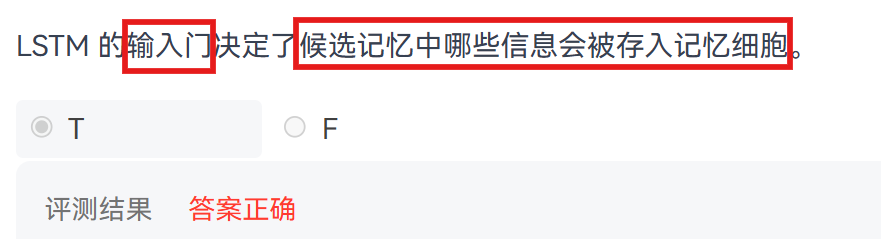
第三步:更新长期记忆(细胞状态)
工作过程(分两部分):
⊙
⊙:选择性记忆 。候选新信息
与输入门 𝐼𝑡逐元素相乘。根据 𝐼𝑡的值,决定候选信息的每一部分有多少被允许写入。
最终 :将 "过滤后的旧记忆" 和 "筛选后的新信息" 相加,得到全新的长期记忆 Ct。
第四步:输出门 ------ 决定当前输出(隐状态)是什么
1. 输出门公式:
2. 当前隐状态公式:
Ht:当前时间步的隐状态(短期输出) 。它有两个作用:一是作为当前时间步的输出 ,二是作为下一个时间步的"短期记忆"输入。
⊙
自然语言处理(NLP)的核心任务
自然语言理解(NLU - Natural Language Understanding)
目标 :让机器理解人类语言所表达的含义。
关键:涉及分析、解析、推理。
典型任务 :情感分析 (理解一句话的情感倾向)、问答系统 (理解问题并找到答案)、信息提取(从文本中提取结构化信息)。
自然语言生成(NLG - Natural Language Generation)
目标 :让机器根据内部的意图、数据或理解,生成通顺、合理的人类语言。
关键:涉及规划、组织、表达。
典型任务 :机器翻译 (将一种语言的理解生成另一种语言)、文本摘要 (将长文本理解后生成简短摘要)、对话生成(根据对话历史和当前理解生成回复)。
两者关系:NLU是NLG的基础。通常,一个复杂的NLP系统(如智能对话机器人)会同时包含NLU模块(理解用户输入)和NLG模块(生成系统回复)。
自然语言理解的五个层次
语音/字符分析:最底层。对于语音,是将声波信号切分为音素、音节;对于文本,是识别字符、编码。
词法分析 :将连续的字符序列切分成有意义的词(分词),并识别出每个词的词性(词性标注)。
句法分析 :分析句子的语法结构,找出词与词之间的修饰、主谓宾等关系(形成句法树)。
语义分析 :理解句子中词、短语以及整个句子的真实含义。例如,知道"苹果"指的是水果还是公司。
语用分析 :最高层。结合上下文、背景知识、说话者意图和世界常识 ,理解语言在具体场景下的真正目的和隐含意义。例如,理解"房间里好冷"可能是在陈述事实,也可能是在暗示"请关上窗户"。
自然语言处理的五大难点(歧义)
难点1:不同语言/个体间的信息失真
核心 :从"想表达的意思 "到"说出来的话 ",再到对方"理解的意思 ",每一步都可能因语言差异、知识差异、背景差异而发生信息扭曲和丢失。
例子:"I'm waiting for you at the bank." 对方需要知道你的常识(是河岸还是银行?)和当前上下文才能正确理解。
难点2:词法歧义
发生在词法分析层。
类型:
分词歧义 :字符串可以有多种切分方式。"橙子皮厂"可以切分为
[橙子皮/厂]或[橙子/皮厂],意思完全不同。词性歧义 :同一个词在不同上下文中词性不同。"他在削 苹果"(动词) vs "这是一把削笔刀"(形容词/名词前缀)。
未登录词/命名实体识别:对新出现的人名、地名、专有名词(如"ChatGPT")的识别困难。
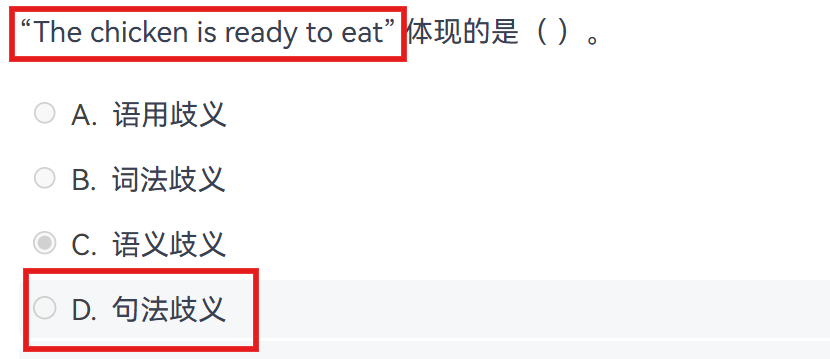
难点3:句法歧义
发生在句法分析层 。同一个句子可以有多种合法的语法结构树。
经典例子:"The chicken is ready to eat."
结构1:鸡是主语 ,也是"吃"的逻辑宾语(鸡被吃)。意思是"鸡已经做好了,可以吃了。"
结构2:鸡是主语 ,也是"吃"的逻辑主语(鸡去吃)。意思是"鸡已经准备好去吃东西了。"
难点4:语义歧义
发生在语义分析层 。即使语法结构清楚,句子仍有多种含义。
经典例子:"At last, a computer understands you like your mother."
含义1:计算机理解你 ,就像你母亲理解你一样。
含义2:计算机理解 你喜欢你的母亲 这件事。
含义3:计算机理解你,就像计算机理解你母亲一样。
难点5:语用歧义
发生在语用分析层 。同一句话在不同的语境、场景、说话者关系 下,表达完全不同的意图和言外之意。
经典例子:"你在干什么?"
朋友闲聊:纯粹的询问。
妈妈对捣蛋的孩子说:生气的质问。
发现对方行为可疑时:怀疑和警觉的盘问。























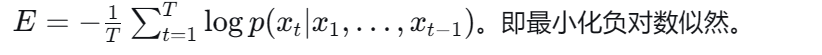




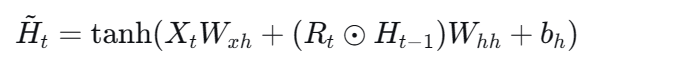


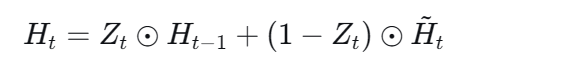



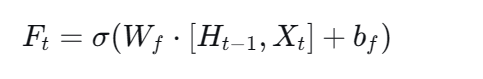

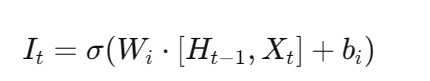

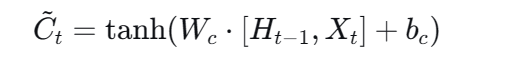


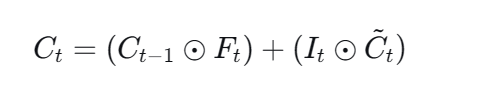

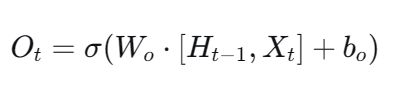



为什么CNN不适合直接处理序列数据(如文本、时间序列)?
- 答案 :CNN的核心是卷积核捕捉局部空间模式 ,并依赖平移不变性。它缺乏内部状态(记忆) 来建模序列中元素之间的长距离动态依赖关系和时间顺序。RNN通过隐状态的循环传递解决了这个问题。
RNN 的核心思想
RNN 的核心思想是 引入"循环"的隐状态 来建模序列的动态依赖。它通过一个在所有时间步共享参数的循环单元,在每一步将 当前输入 和 上一步的隐状态 结合,生成新的隐状态。这个隐状态像一个 持续更新的记忆 ,理论上包含了所有历史信息。这使得 RNN 能够处理任意长度的序列,并捕捉序列中元素之间的 时间依赖关系 ,但其简单的线性组合与非线性激活结构,也导致了长序列训练中 梯度消失/爆炸 的根本缺陷。
LSTM 的核心思想
LSTM 的核心思想是 将"记忆"与"输出"分离,并通过三重门控保护长期信息的流动。它明确区分:
细胞状态 :作为 长期记忆的传送带 ,主要经由 加法操作
隐状态 :作为 短期输出 ,是细胞状态经 输出门过滤 后的结果。
通过 遗忘门、输入门、输出门 的三重控制,LSTM 能 精细地读写、保留和忽略信息,成为处理长序列依赖的经典强效架构。
GRU 的核心思想
GRU 的核心思想是 通过"门控"机制实现记忆的精细化更新 ,以缓解梯度消失。它引入 重置门 和 更新门 两个控制单元:
重置门 决定 多少旧记忆 参与计算新候选信息;
更新门 决定 新旧记忆如何混合 以形成当前状态。
通过将 LSTM 的 细胞状态与隐状态合并 ,GRU 用更简洁的结构(两门、无独立细胞状态)实现了 对信息流的自适应选择与保留,既保留了长期依赖能力,又减少了参数数量。