文章结尾部分有CSDN官方提供的学长 联系方式名片
up主B站: 麦麦大数据
关注B站,有好处!
编号: D026
视频
D026 📑文献知识图谱推荐可视化系统
1 系统简介
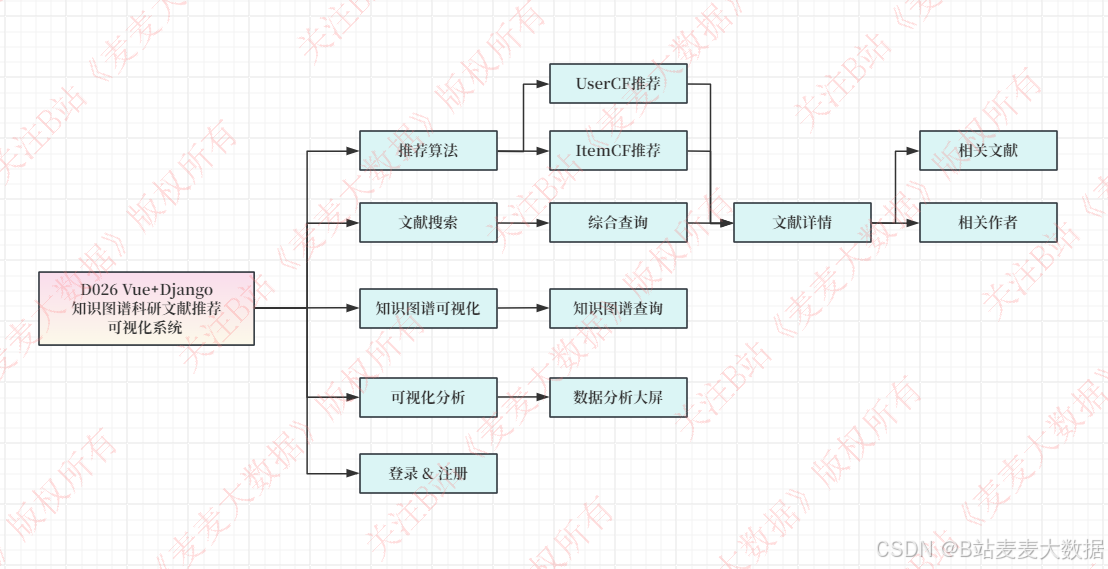
本系统是一个基于Vue3和Django构建的论文知识图谱推荐可视化系统,旨在为用户提供直观的论文知识图谱展示、论文数据分析以及智能化的论文推荐服务。系统的核心功能围绕论文知识图谱的构建与可视化、论文数据的分析与检索、以及用户管理展开。主要包括以下功能模块:知识图谱可视化模块,用于展示科研论文作者之间的关联关系;论文数据可视化模块,提供论文的详细信息和多维度的统计分析;智能检索模块,支持多关键词模糊检索和论文的关联推荐;以及用户管理模块,包含登录、注册以及个人信息管理功能,确保系统的安全性和个性化体验。
2 功能设计
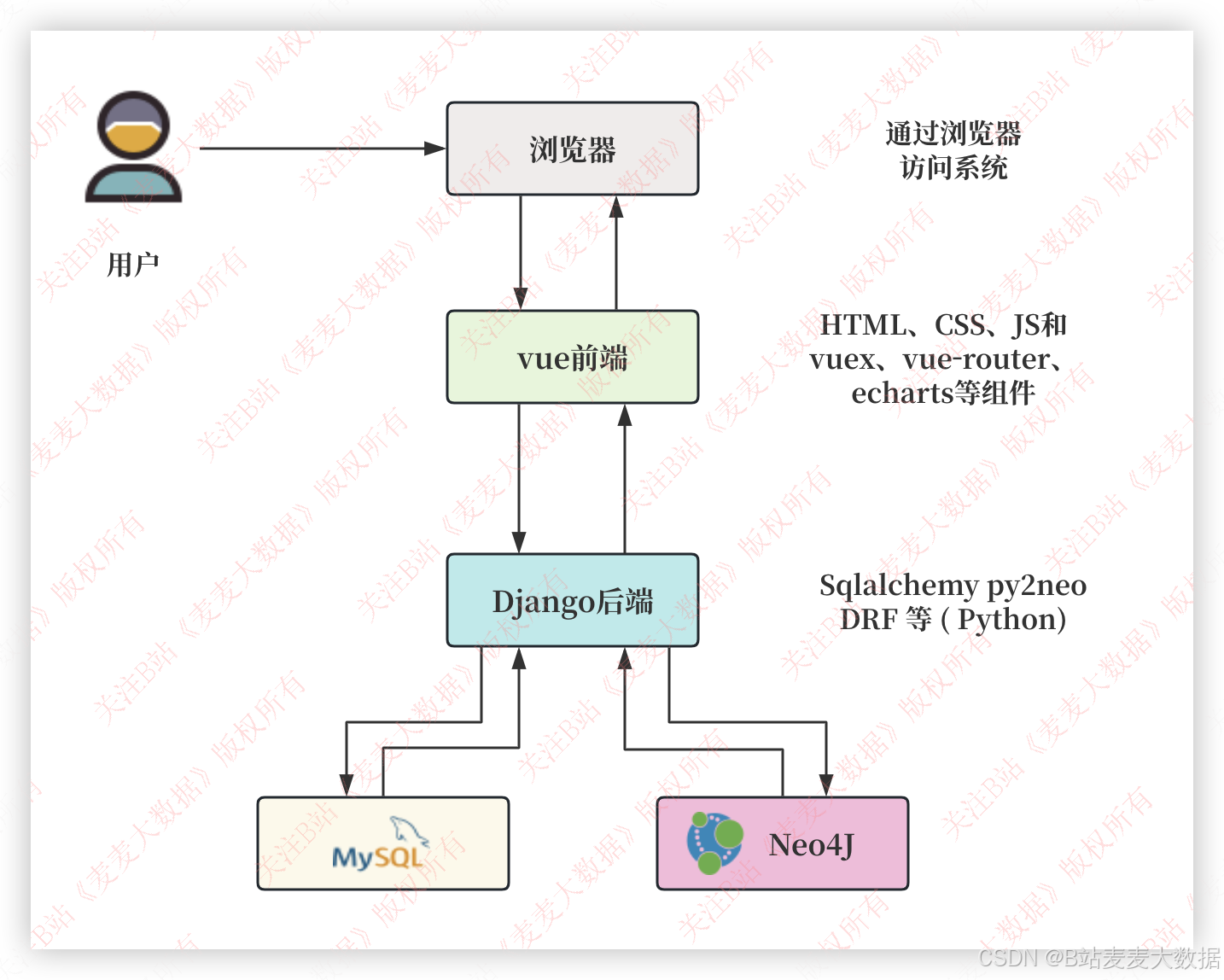
该系统采用典型的B/S(浏览器/服务器)架构模式,前端基于Vue3生态系统构建,包括HTML、CSS、JavaScript以及Vue3中的Pinia(用于状态管理)、Vue Router(用于路由导航)和ECharts(用于数据可视化)等组件。前端通过RESTful API与Django后端进行数据交互,Django后端利用Django Rest Framework框架构建,负责业务逻辑处理,并连接Neo4j图数据库和MySQL关系型数据库进行数据存储和检索。系统还集成了NetworkX库,用于知识图谱的构建与分析。
2.1系统架构图
2.2 功能模块图
3 功能展示
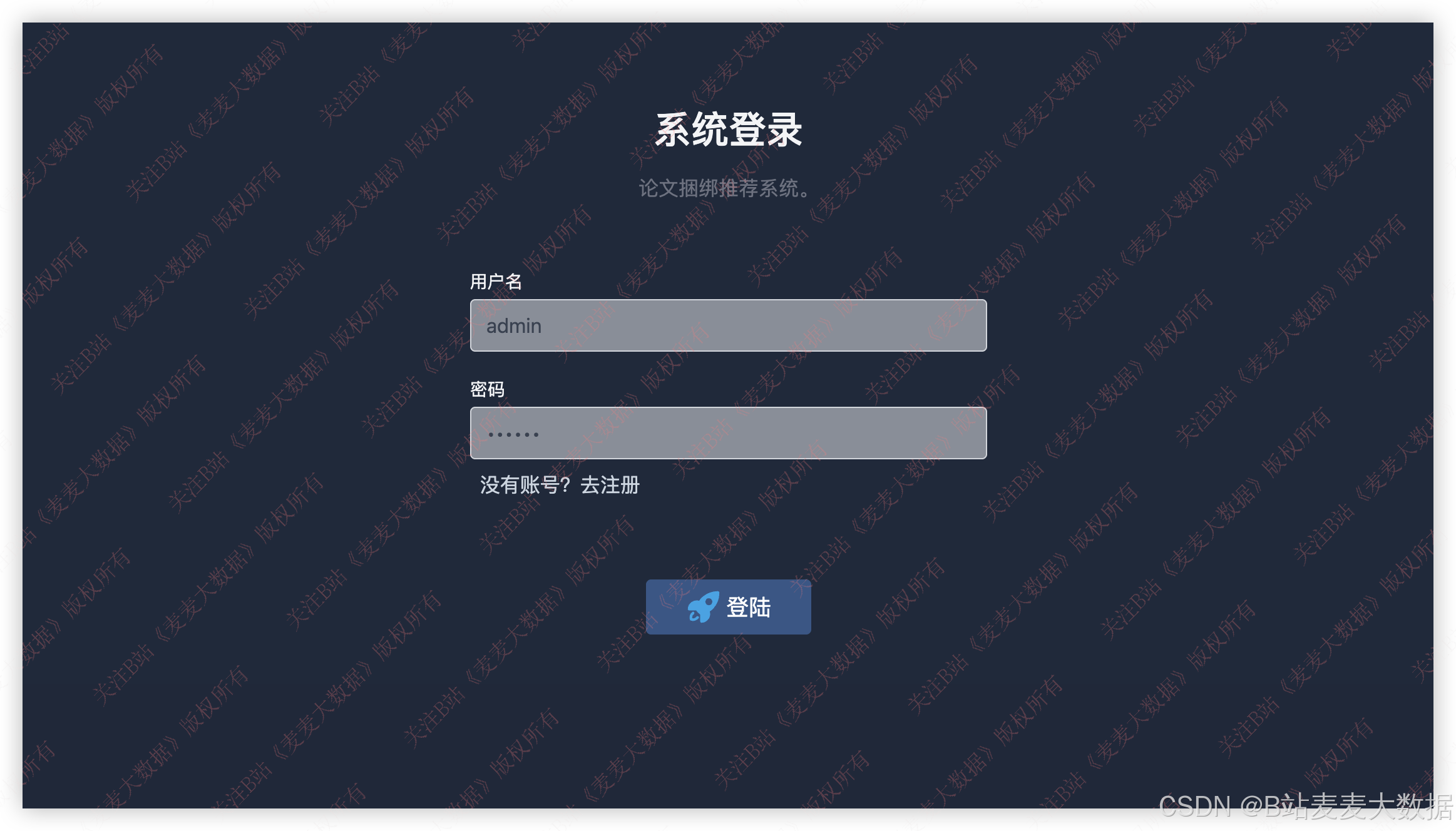
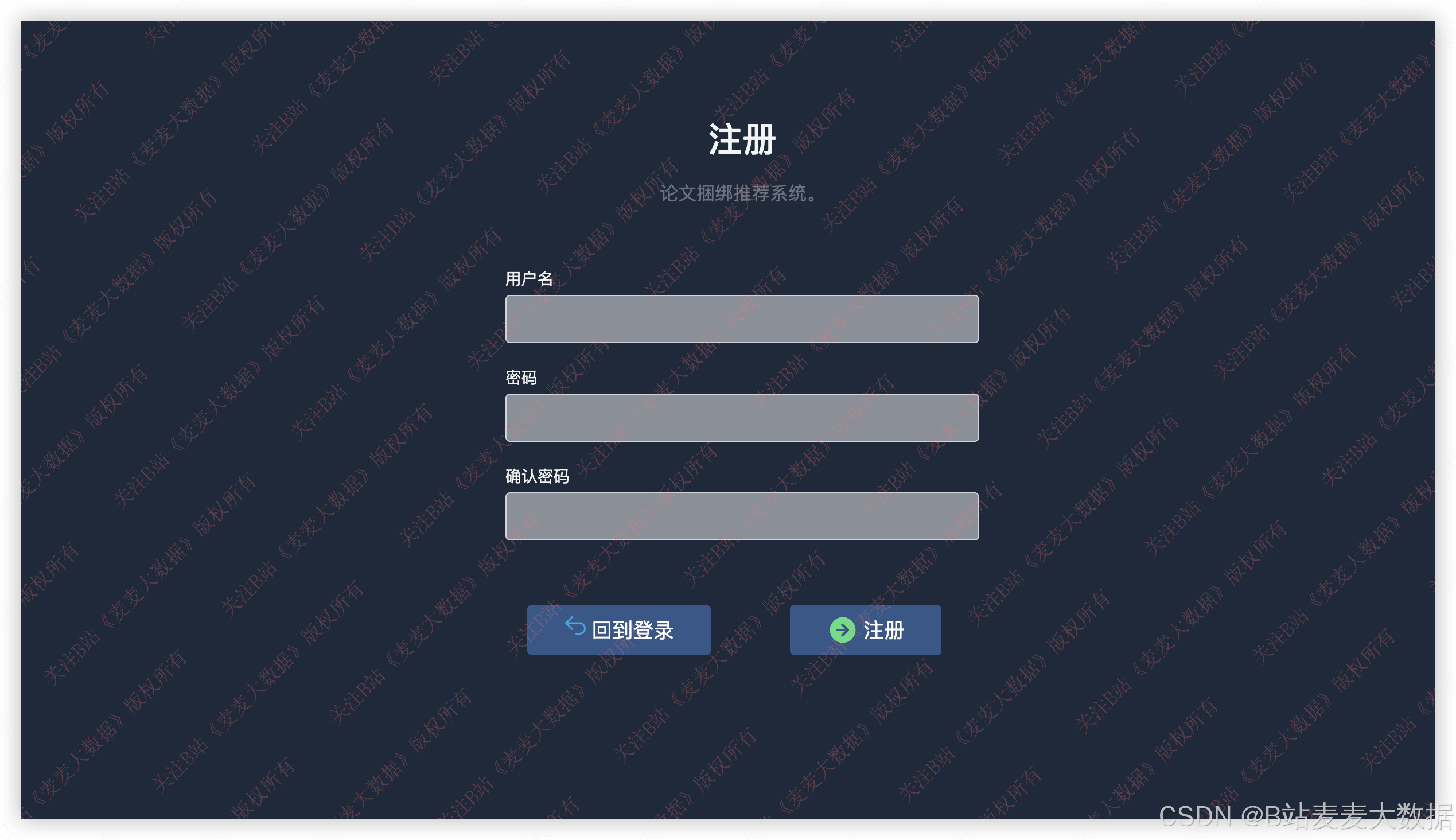
3.1 登录 & 注册
登录界面背景是一个视频,展示和本文系统主题相匹配的内容,登录和注册界面在一个界面下,通过按钮来切换,注册界面输入用户名和密码,会检查这个用户是否存在,登录界面则要检查用户名是否存在以及用户名密码是否正确:
3.2 主页
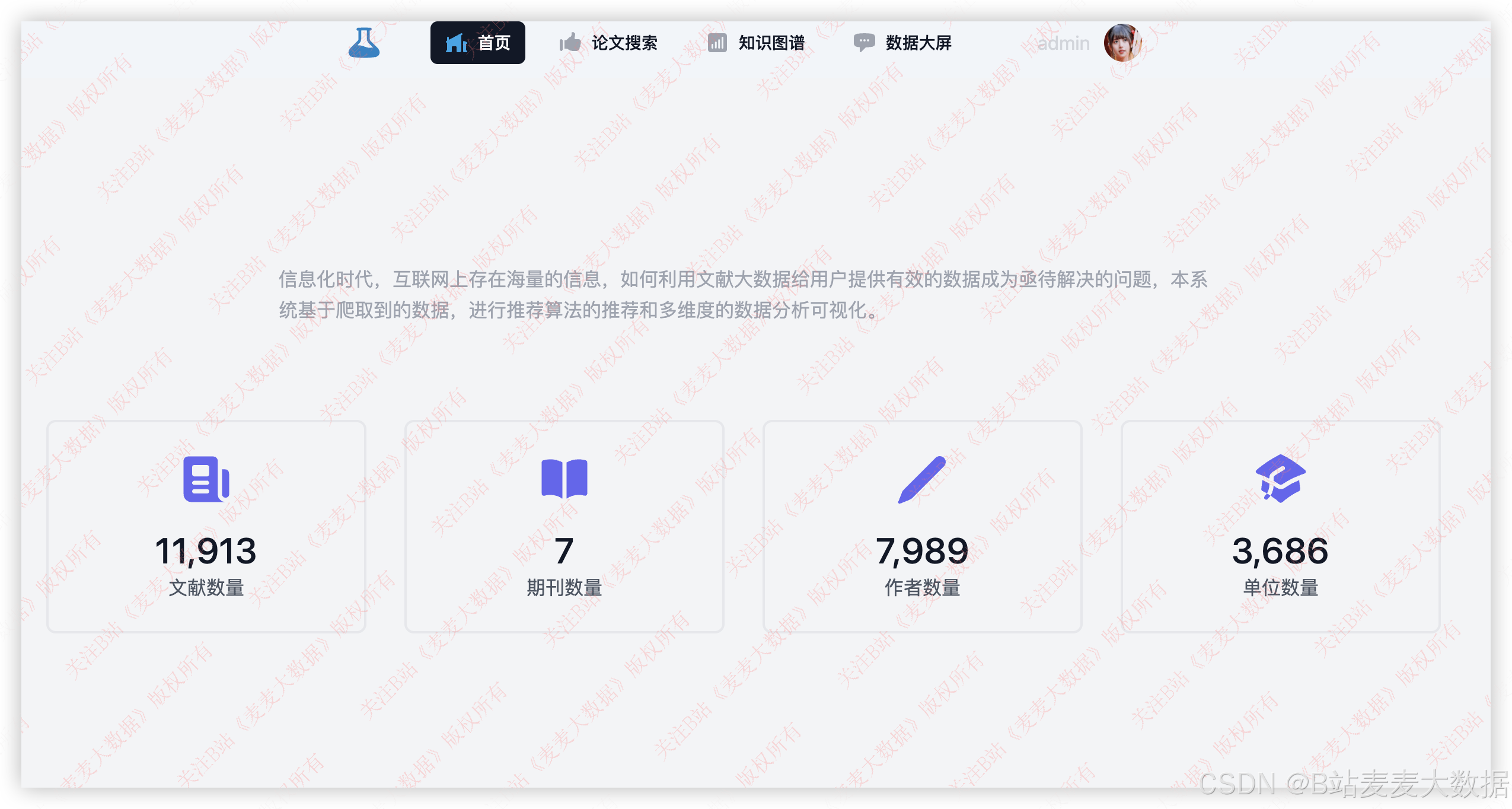
如果通过校验,则可以进入主页,在主页是一个上方菜单,下方操作面板的布局,右上角是登录用户的头像和退出按钮,这个界面通过滚动数字展示系统内文献数量
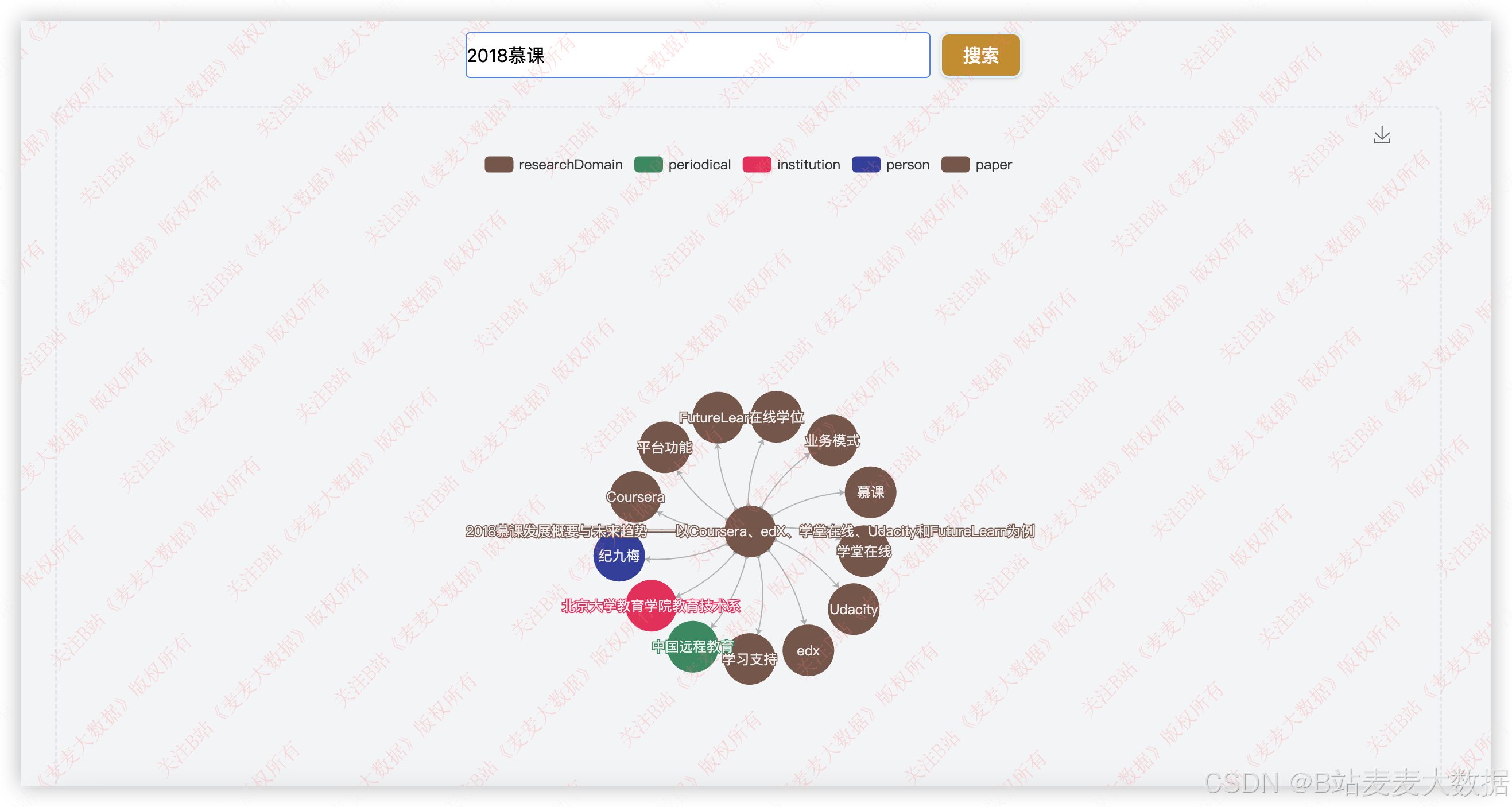
3.3 论文搜索
论文搜索和论文推荐实际上再一个界面里,是仿照X网的风格来开发的一个界面,上方是一个搜索框,右侧是推荐的界面。
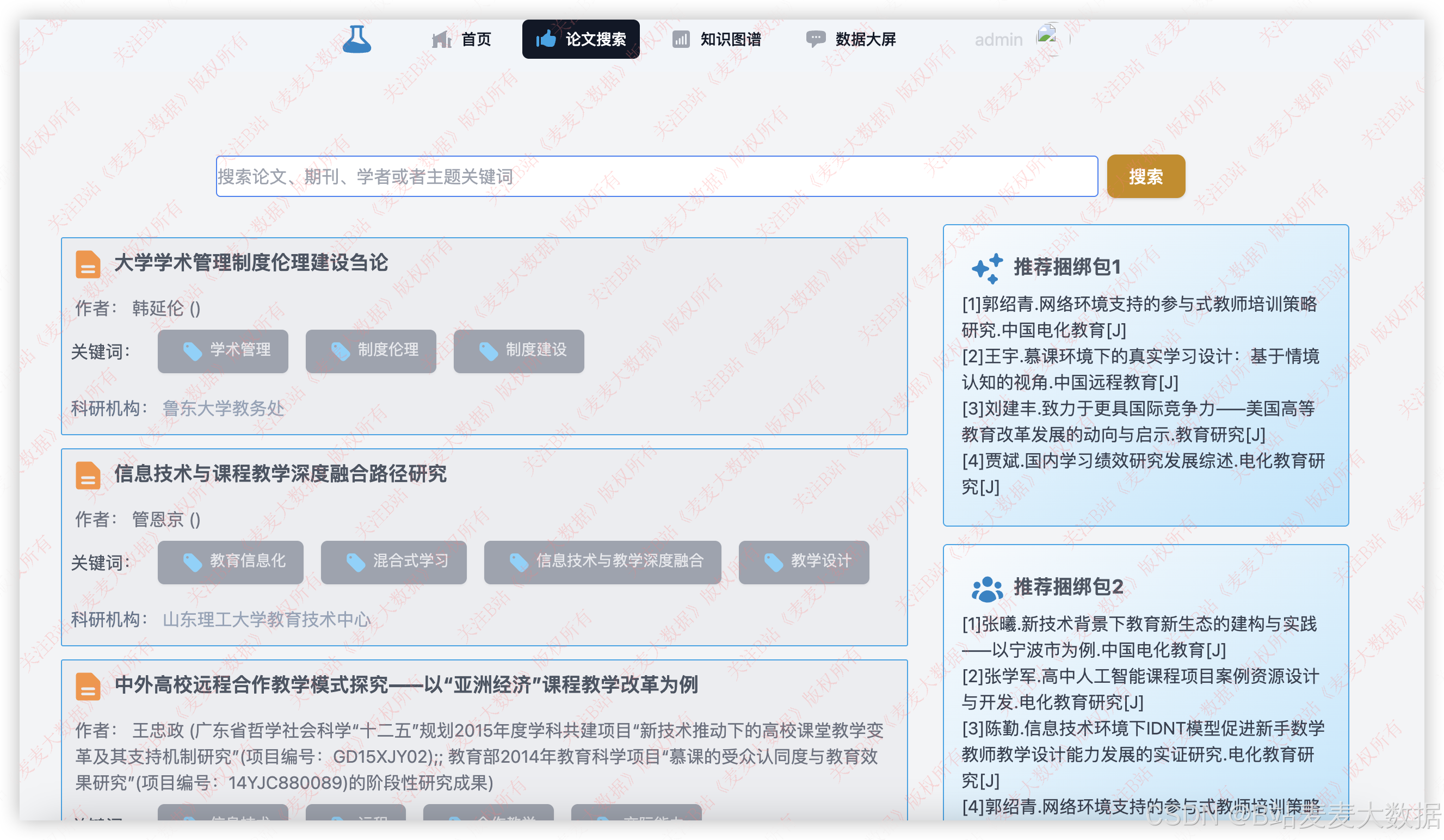
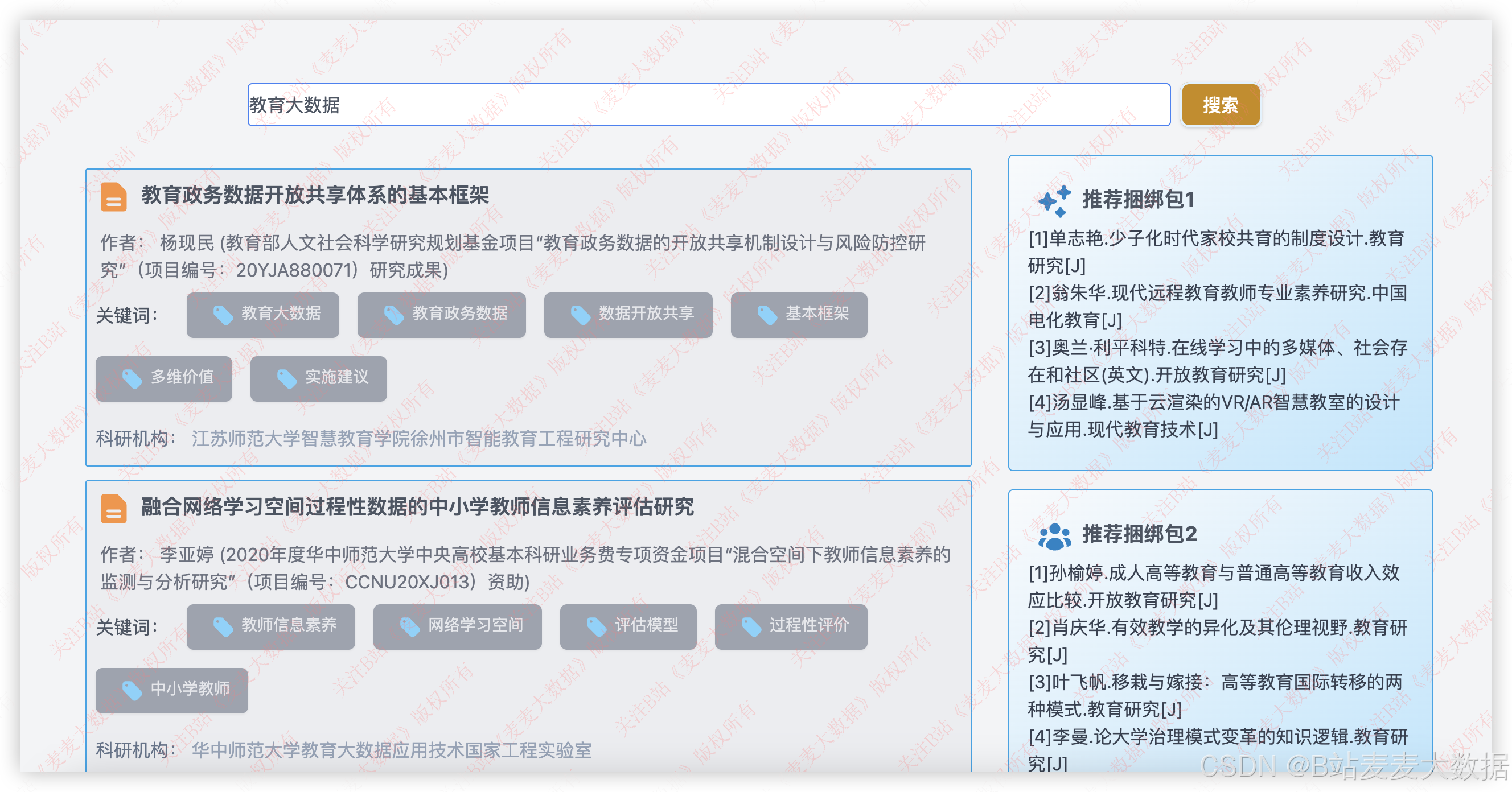
3.4 论文推荐
论文搜索和论文推荐实际上再一个界面里,是仿照X网的风格来开发的一个界面,上方是一个搜索框,右侧是推荐的界面。
使用的推荐算法有UserCF 和 ItemCF论文相似度推荐::
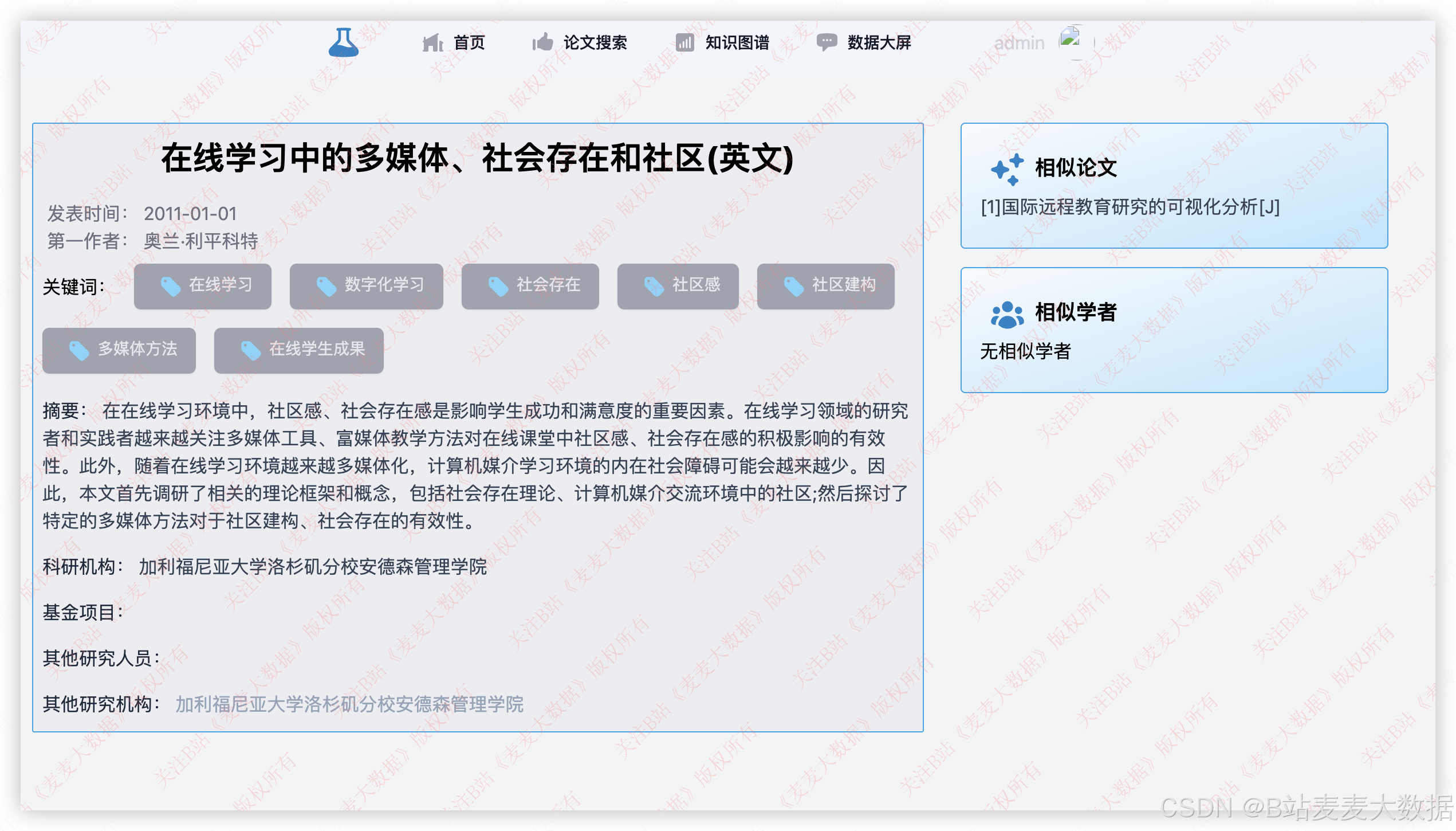
3.5 论文详情
在详情页面可以查看论文文献的详细信息,作者、机构、关键词,右侧还有相似论文和相似作者的推荐,带有链接,可以直接跳转:
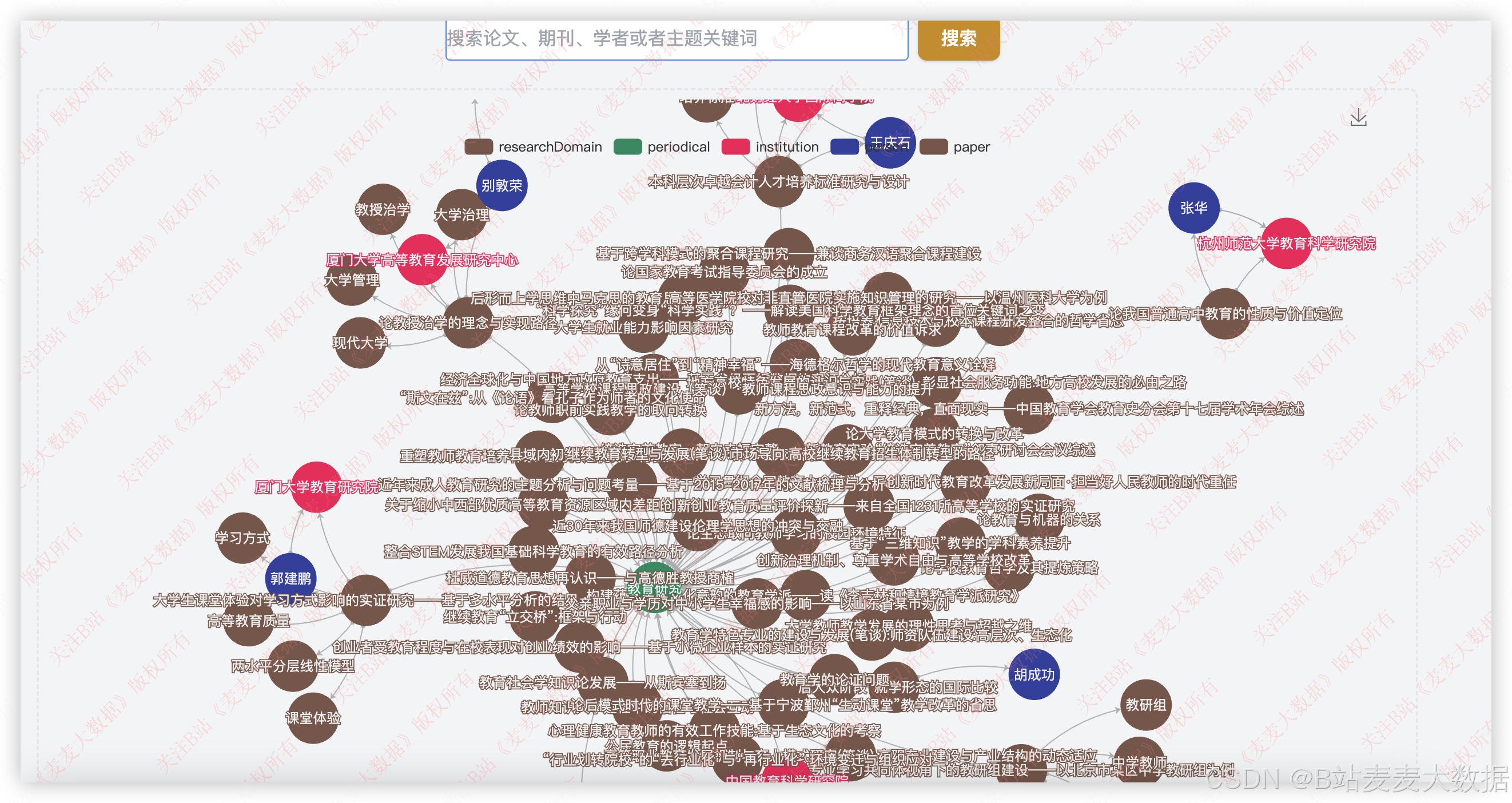
3.6 知识图谱
论文文献和作者、机构特别适合制作知识图谱,本文的图谱存储在neo4j之中,支持搜索功能
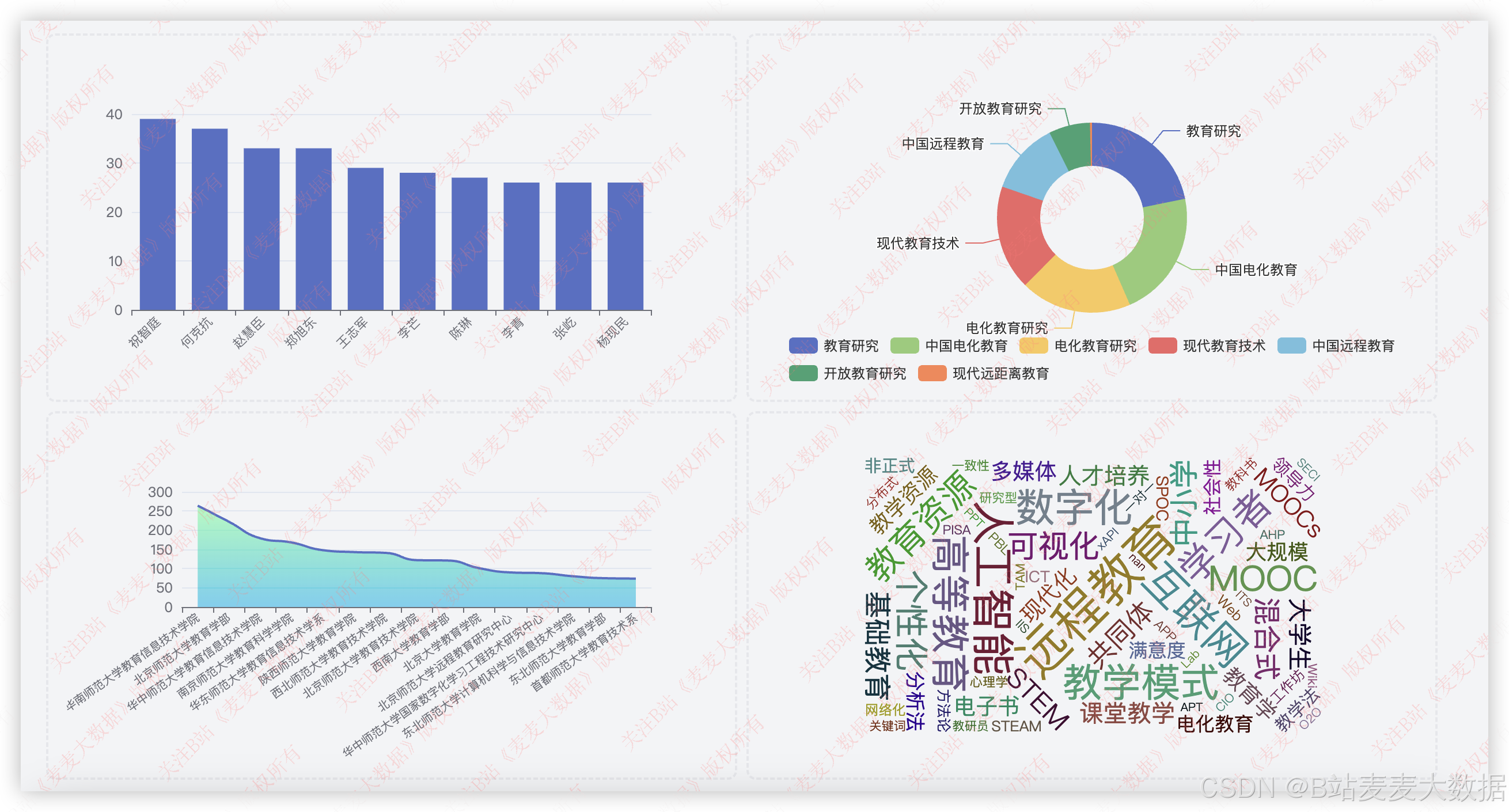
3.7 可视化
基于echarts的可视化分析功能:
4程序代码
4.1 代码说明
代码介绍:本算法基于python实现,用于推荐相似的论文文献。算法首先对输入的论文文献进行文本预处理,包括分词、去停用和词干提取等步骤,然后利用TF-IDF(Term Frequency-Inverse Document Frequency)提取文本特征,计算各文献间的相似度。相似度计算采用余弦相似度,通过构建向量空间模型来量化文献间的相似程度。最终,通过排序Retrieve最相似的文献,并输出前N个推荐结果。
4.2 流程图
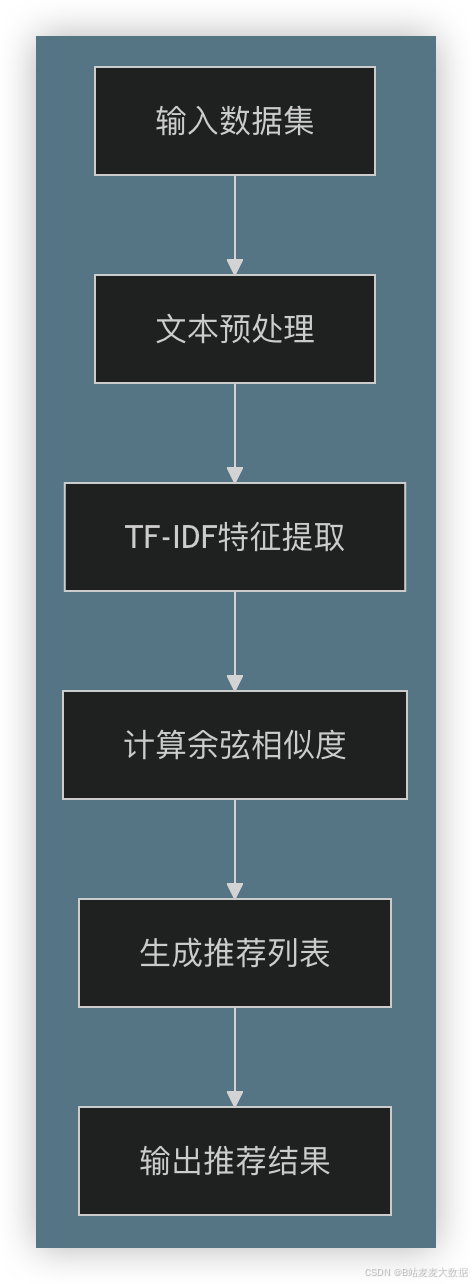
4.3 代码实例
python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
import numpy as np
def similar_papers_recommendation(papers, target_paper, top_k=5):
"""
基于TF-IDF和余弦相似度的论文推荐算法
参数:
- papers: 列表,包含所有文献的文本内容
- target_paper: 字符串,目标文献的文本内容
- top_k: 整数,指定返回的推荐数量
返回:
- recommendations: 列表,包含与target_paper最相似的top_k篇文献的索引
"""
# 将目标文献与其他文献合并成一个列表进行处理
all_papers = papers.copy()
all_papers.appendtarget_paper
# 初始化TF-IDF向量器
vectorizer = TfidfVectorizer(stop_words='english')
tfidf = vectorizer.fit_transform(all_papers)
# 计算余弦相似度
similarity_scores = linear_kernel(tfidf[-1:], tfidf).flatten()
# 获取与目标文献的相似度排序后的索引
similarities = [(i, similarity_scores[i]) for i in range(len(all_papers))]
similarities.sort(key=lambda x: x[1], reverse=True)
# 去除掉目标文献本身
recommendations = [sim[0] for sim in similarities if sim[0] != len(papers)]
# 返回top_k个推荐
return recommendations[:top_k]
if __name__ == "__main__":
# 示例数据
papers = [
"This paper is about machine learning in medicine.",
"A study on deep learning applications.",
"Machine learning for natural language processing tasks.",
"Deep learning approaches for computer vision.",
" wearable devices in healthcare recent studies"
]
target_paper = papers[0]
recommended_indices = similar_papers_recommendation(papers, target_paper, top_k=2)
print("推荐的论文索引:", recommended_indices)