1.简介
本文介绍python爬虫的使用方法,主要使用到的包有
import requests
from bs4 import BeautifulSoupBeautifulSoup 是用于在爬取的内容中 提取信息
1.1
爬取前肯定要熟悉目标网站的html结构
比如我们现在需要目标网站的图书信息。
目标网站html结构:
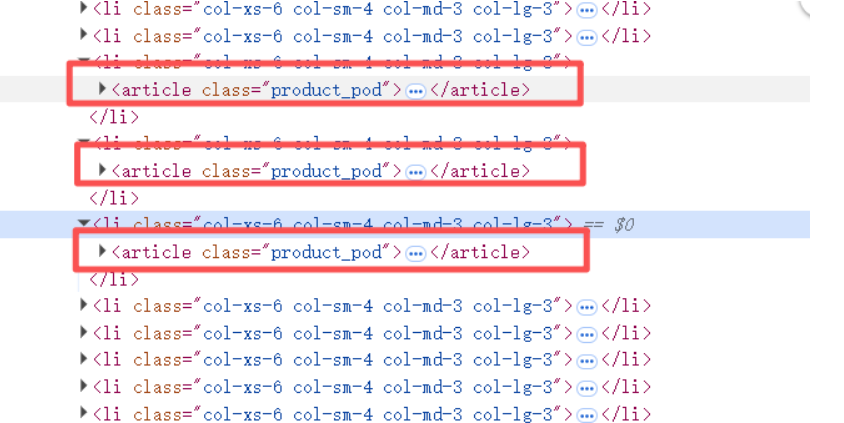
然后我们需要实现自动翻页,翻页按钮是怎么显示的。比如我们这里如果翻到最后一页,下一页的按钮就不显示了。
那么我们可以通过判断 爬取的内容中是否有,这个下一页的标签。判断时候最后一页
例如:
soup = BeautifulSoup(html, 'html.parser')
next_button = soup.select_one('li.next a')
if next_button:
current_page += 1
else:
print("没有更多页面,爬取完成")
break这里下一页的标签是 li.next的 a标签
<li class="next"><a href="page-50.html">next</a></li>好了,所有都准备好后,我们开始编码工作
2.第一种方法
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
from urllib.parse import urljoin, urlparse
class BookScraper:
def __init__(self):
self.session = requests.Session()
self.base_url = "https://books.toscrape.com/"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def get_page(self, url):
"""获取网页内容"""
try:
response = self.session.get(url, headers=self.headers, timeout=10)
response.raise_for_status()
response.encoding = 'utf-8'
return response.text
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
def parse_book_list(self, html):
"""解析图书列表页面"""
soup = BeautifulSoup(html, 'html.parser')
books = []
# 查找所有图书条目
book_elements = soup.select('article.product_pod')
for book in book_elements:
try:
# 提取图书标题
title = book.select_one('h3 a')['title']
# 提取价格
price = book.select_one('p.price_color').get_text().strip()
# 提取评分(通过类名判断)
rating_class = book.select_one('p.star-rating')['class']
rating = rating_class[1] if len(rating_class) > 1 else 'Not rated'
# 提取图书详情链接(需要转换为绝对URL)
relative_link = book.select_one('h3 a')['href']
book_url = urljoin(self.base_url + 'catalogue/', relative_link)
# 提取图片URL
img_relative = book.select_one('img')['src']
img_url = urljoin(self.base_url + 'catalogue/', img_relative)
books.append({
'title': title,
'price': price,
'rating': rating,
'book_url': book_url,
'image_url': img_url
})
except (AttributeError, KeyError, TypeError) as e:
print(f"解析图书信息时出错: {e}")
continue
return books
def scrape_with_auto_pagination(self, max_pages=None):
"""自动翻页爬取,直到没有下一页"""
all_books = []
current_page = 1
while True:
print(f"正在爬取第 {current_page} 页...")
# 添加随机延迟
time.sleep(random.uniform(1, 2))
# 构建当前页URL
if current_page == 1:
url = f"{self.base_url}catalogue/page-1.html"
else:
url = f"{self.base_url}catalogue/page-{current_page}.html"
html = self.get_page(url)
if not html:
print(f"第 {current_page} 页爬取失败,停止爬取")
break
# 解析当前页的图书
books = self.parse_book_list(html)
all_books.extend(books)
print(f"第 {current_page} 页爬取完成,获取到 {len(books)} 本书籍")
# 检查是否有下一页
soup = BeautifulSoup(html, 'html.parser')
next_button = soup.select_one('li.next a')
# 如果设置了最大页数限制,检查是否达到
if max_pages and current_page >= max_pages:
print(f"已达到最大页数限制 {max_pages},停止爬取")
break
if next_button:
current_page += 1
else:
print("没有更多页面,爬取完成")
break
return all_books
def save_to_csv(self, data, filename):
"""将数据保存为CSV文件"""
if not data:
print("没有数据可保存")
return
df = pd.DataFrame(data)
df.to_csv(filename, index=False, encoding='utf-8-sig')
print(f"数据已保存到 {filename},共 {len(data)} 条记录")
# 使用示例
if __name__ == "__main__":
scraper = BookScraper()
# 这种方法会自动翻页直到没有下一页
# 可以设置 max_pages 参数限制爬取的页数
all_books_auto = scraper.scrape_with_auto_pagination(max_pages=5) # 只爬取5页作为示例
scraper.save_to_csv(all_books_auto, 'books_auto.csv')这里以爬5页为例,爬取后保存为csv文件
3.第二种方法
第二种方法的话,会先去获取有多少页。
然后循环去请求每一页
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
from urllib.parse import urljoin, urlparse
class BookScraper:
def __init__(self):
self.session = requests.Session()
self.base_url = "https://books.toscrape.com/"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def get_page(self, url):
"""获取网页内容"""
try:
response = self.session.get(url, headers=self.headers, timeout=10)
response.raise_for_status()
response.encoding = 'utf-8'
return response.text
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
def parse_book_list(self, html):
"""解析图书列表页面"""
soup = BeautifulSoup(html, 'html.parser')
books = []
# 查找所有图书条目
book_elements = soup.select('article.product_pod')
for book in book_elements:
try:
# 提取图书标题
title = book.select_one('h3 a')['title']
# 提取价格
price = book.select_one('p.price_color').get_text().strip()
# 提取评分(通过类名判断)
rating_class = book.select_one('p.star-rating')['class']
rating = rating_class[1] if len(rating_class) > 1 else 'Not rated'
# 提取图书详情链接(需要转换为绝对URL)
relative_link = book.select_one('h3 a')['href']
book_url = urljoin(self.base_url + 'catalogue/', relative_link)
# 提取图片URL
img_relative = book.select_one('img')['src']
img_url = urljoin(self.base_url + 'catalogue/', img_relative)
books.append({
'title': title,
'price': price,
'rating': rating,
'book_url': book_url,
'image_url': img_url
})
except (AttributeError, KeyError, TypeError) as e:
print(f"解析图书信息时出错: {e}")
continue
return books
def get_total_pages(self, html):
"""获取总页数"""
soup = BeautifulSoup(html, 'html.parser')
# 查找分页组件
pagination = soup.select_one('ul.pager li.current')
if pagination:
# 文本格式通常是 "Page 1 of 20"
text = pagination.get_text().strip()
try:
total_pages = int(text.split('of')[-1].strip())
return total_pages
except (IndexError, ValueError):
pass
# 如果没有找到分页信息,检查是否有图书,如果有则至少有1页
books = soup.select('article.product_pod')
return 1 if books else 0
def scrape_all_pages(self, start_page=1):
"""爬取所有页面"""
all_books = []
current_page = start_page
# 先获取第一页,确定总页数
first_page_url = f"{self.base_url}catalogue/page-{start_page}.html"
first_page_html = self.get_page(first_page_url)
if not first_page_html:
print("无法获取第一页内容")
return all_books
total_pages = self.get_total_pages(first_page_html)
print(f"检测到总共 {total_pages} 页")
# 从第一页开始爬取
for page in range(start_page, total_pages + 1):
print(f"正在爬取第 {page}/{total_pages} 页...")
# 添加随机延迟,避免请求过于频繁
time.sleep(random.uniform(1, 2))
if page == 1:
# 第一页已经获取过了
page_html = first_page_html
else:
page_url = f"{self.base_url}catalogue/page-{page}.html"
page_html = self.get_page(page_url)
if page_html:
books = self.parse_book_list(page_html)
all_books.extend(books)
print(f"第 {page} 页爬取完成,获取到 {len(books)} 本书籍")
else:
print(f"第 {page} 页爬取失败")
break
return all_books
def save_to_csv(self, data, filename):
"""将数据保存为CSV文件"""
if not data:
print("没有数据可保存")
return
df = pd.DataFrame(data)
df.to_csv(filename, index=False, encoding='utf-8-sig')
print(f"数据已保存到 {filename},共 {len(data)} 条记录")
# 使用示例
if __name__ == "__main__":
scraper = BookScraper()
all_books = scraper.scrape_all_pages(start_page=1)
scraper.save_to_csv(all_books, 'all_books.csv')