使用CNN构建VAE
-
- [0. 前言](#0. 前言)
- [1. 网络架构](#1. 网络架构)
- [2. 模型构建](#2. 模型构建)
- [3. 生成结果](#3. 生成结果)
0. 前言
在原始变分自编码器 (Variational Autoencoder, VAE)中,VAE 网络采用全连接网络实现。本节将使用卷积神经网络 (Convolutional Neural Network, CNN)提升生成数字的质量,同时将参数数量大幅减少至 134165 个。
1. 网络架构
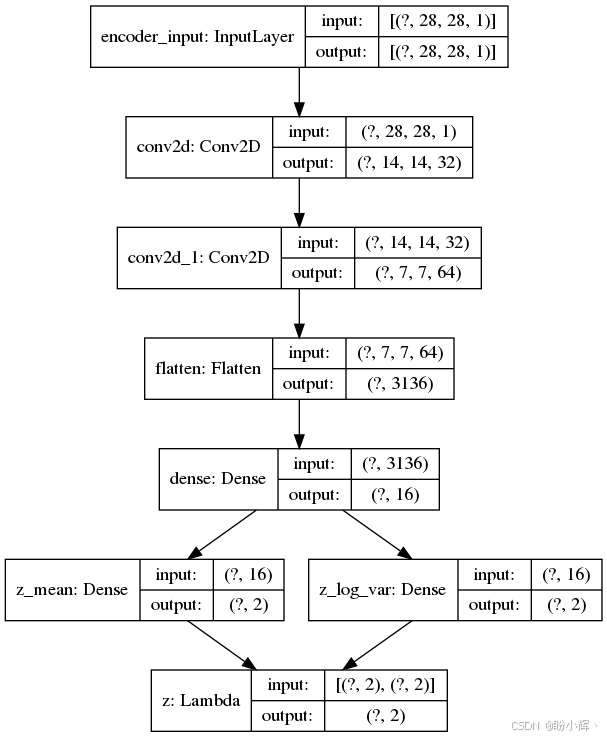
下图展示了 CNN 编码器模型的两个输出------潜向量的均值与方差。其中的 lambda 函数实现了重参数化技巧,将随机潜编码的采样过程移至 VAE 网络外部:
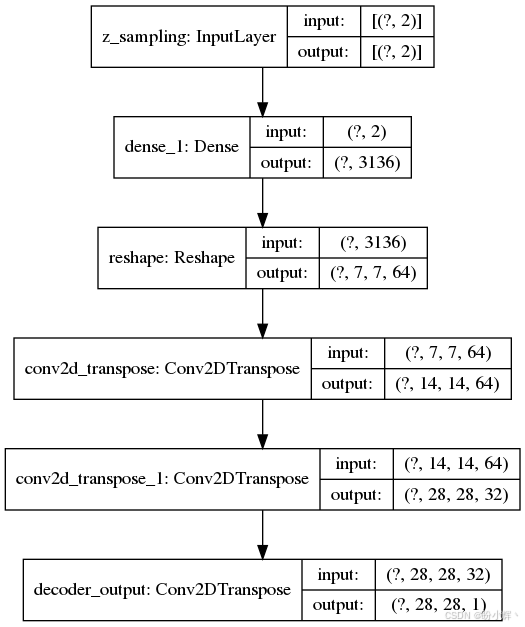
下图展示了 CNN 解码器模型。其二维输入来自 lambda 函数,输出为重构的 MNIST 数字图像:
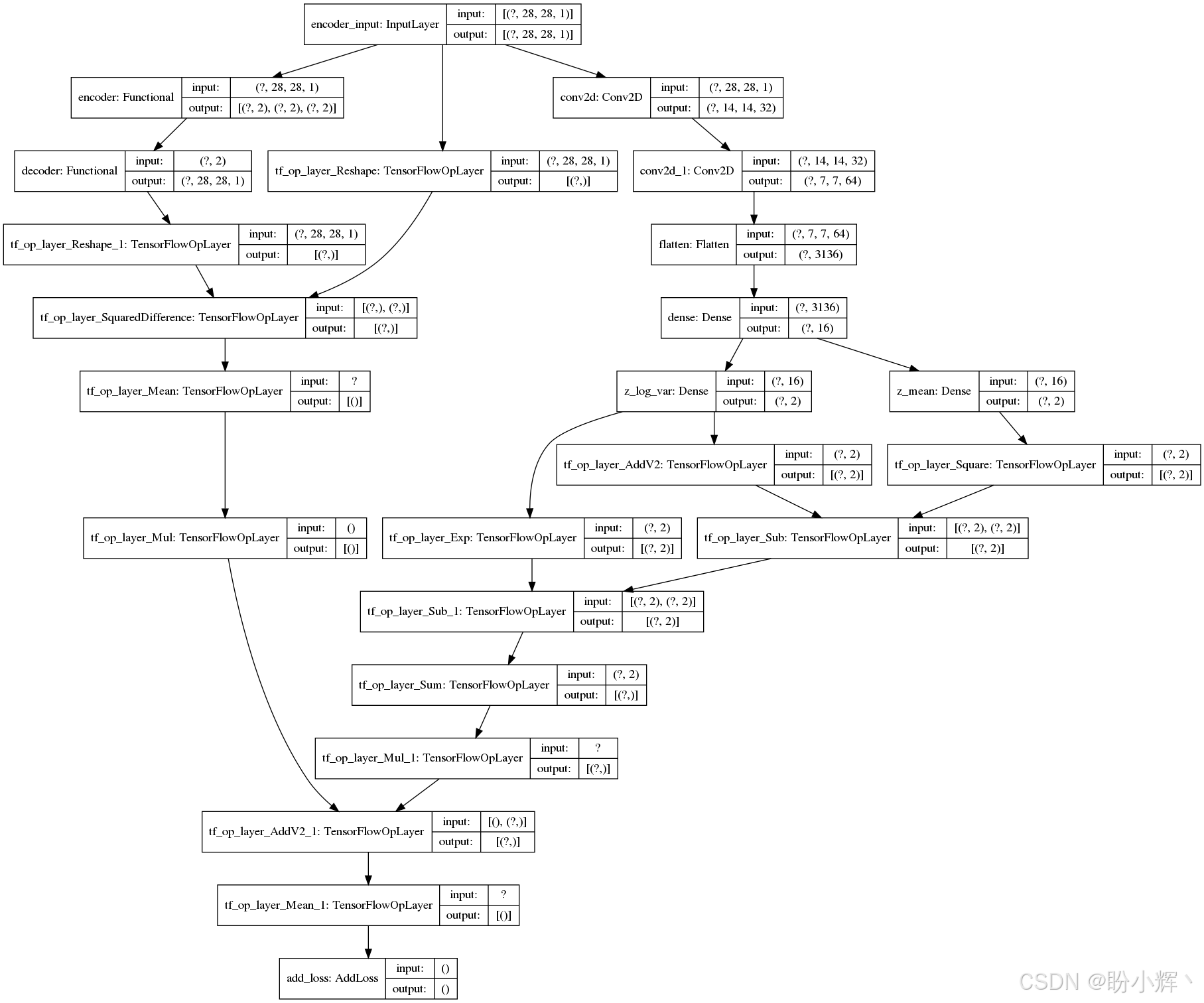
下图展示了完整的 CNN-VAE 模型,由编码器与解码器连接构成:
2. 模型构建
编码器由两层 CNN 和两层全连接层组成,用于生成潜编码。其输出结构与原始变分自编码器 (Variational Autoencoder, VAE)类似。解码器则包含一层全连接层和三层转置卷积层。
python
#reparameterization trick
#z = z_mean + sqrt(var) * eps
def sampling(args):
z_mean,z_log_var = args
batch = keras.backend.shape(z_mean)[0]
dim = keras.backend.shape(z_mean)[1]
epsilon = keras.backend.random_normal(shape=(batch,dim))
return z_mean + keras.backend.exp(0.5 * z_log_var) * epsilon
def plot_results(models,
data,
batch_size=128,
model_name='vae_mnist'):
encoder,decoder = models
x_test,y_test = data
xmin = ymin = -4
xmax = ymax = +4
os.makedirs(model_name,exist_ok=True)
filename = os.path.join(model_name,'vae_mean.png')
#display a 2D plot of the digit classes in the latent space
z,_,_ = encoder.predict(x_test,batch_size=batch_size)
plt.figure(figsize=(12,10))
#axes x and y ranges
axes = plt.gca()
axes.set_xlim([xmin,xmax])
axes.set_ylim([ymin,ymax])
# subsampling to reduce density of points on the plot
z = z[0::2]
y_test = y_test[0::2]
plt.scatter(z[:,0],z[:,1],marker='')
for i,digit in enumerate(y_test):
axes.annotate(digit,(z[i,0],z[i,1]))
plt.xlabel('z[0]')
plt.ylabel('z[1]')
plt.savefig(filename)
plt.show()
filename = os.path.join(model_name,'digits_over_latent.png')
#display a 30*30 2D mainfold of digits
n = 30
digit_size = 28
figure = np.zeros((digit_size * n,digit_size * n))
#linearly spaced coordinates corresponding to the 2D plot of digit classes in the latent space
#线性间隔的坐标,对应于潜在空间中数字类的二维图
grid_x = np.linspace(-4,4,n)
grid_y = np.linspace(-4,4,n)[::-1]
for i,yi in enumerate(grid_x):
for j,xi in enumerate(grid_y):
z_sample = np.array([[xi,yi]])
x_decoded = decoder.predict(z_sample)
digit = x_decoded[0].reshape(digit_size,digit_size)
figure[i * digit_size:(i+1)*digit_size,j*digit_size:(j+1)*digit_size] = digit
plt.figure(figsize=(10, 10))
start_range = digit_size // 2
end_range = (n-1) * digit_size + start_range + 1
pixel_range = np.arange(start_range, end_range, digit_size)
sample_range_x = np.round(grid_x, 1)
sample_range_y = np.round(grid_y, 1)
plt.xticks(pixel_range, sample_range_x)
plt.yticks(pixel_range, sample_range_y)
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.imshow(figure, cmap='Greys_r')
plt.savefig(filename)
plt.show()
# MNIST dataset
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
image_size = x_train.shape[1]
# original_dim = image_size * image_size
x_train = np.reshape(x_train, [-1, image_size,image_size,1])
x_test = np.reshape(x_test, [-1, image_size,image_size,1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
#超参数
input_shape = (image_size,image_size,1)
batch_size = 128
kernel_size = 3
filters = 16
latent_dim = 2
epochs = 50
#VAE model
#encoder
inputs = keras.layers.Input(shape=input_shape,name='encoder_input')
x = inputs
for i in range(2):
filters *= 2
x = keras.layers.Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu',
strides=2,
padding='same')(x)
shape = keras.backend.int_shape(x)
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(16,activation='relu')(x)
z_mean = keras.layers.Dense(latent_dim,name='z_mean')(x)
z_log_var = keras.layers.Dense(latent_dim,name='z_log_var')(x)
z = keras.layers.Lambda(sampling,output_shape=(latent_dim,),name='z')([z_mean,z_log_var])
encoder = keras.Model(inputs,[z_mean,z_log_var,z],name='encoder')
encoder.summary()
keras.utils.plot_model(encoder,to_file='vae_cnn_encoder.png',show_shapes=True)
#decoder
latent_inputs = keras.layers.Input(shape=(latent_dim,),name='z_sampling')
x = keras.layers.Dense(shape[1]*shape[2]*shape[3],activation='relu')(latent_inputs)
x = keras.layers.Reshape((shape[1],shape[2],shape[3]))(x)
for i in range(2):
x = keras.layers.Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
activation='relu',
strides=2,
padding='same')(x)
filters //= 2
outputs = keras.layers.Conv2DTranspose(filters=1,
kernel_size=kernel_size,
activation='sigmoid',
padding='same',
name='decoder_output')(x)
decoder = keras.Model(latent_inputs,outputs,name='decoder')
decoder.summary()
keras.utils.plot_model(decoder,to_file='vae_cnn_decoder.png',show_shapes=True)
outputs = decoder(encoder(inputs)[2])
vae = keras.Model(inputs,outputs,name='vae_cnn')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
help_ = "Load tf model trained weights"
parser.add_argument("-w", "--weights", help=help_)
help_ = "Use binary cross entropy instead of mse (default)"
parser.add_argument("--bce", help=help_, action='store_true')
args = parser.parse_args()
models = (encoder, decoder)
data = (x_test, y_test)
#VAE loss = mse_loss or xent_loss + kl_loss
if args.bce:
reconstruction_loss = keras.losses.binary_crossentropy(keras.backend.flatten(inputs),
keras.backend.flatten(outputs))
else:
reconstruction_loss = keras.losses.mse(keras.backend.flatten(inputs),
keras.backend.flatten(outputs))
reconstruction_loss *= image_size * image_size
kl_loss = 1 + z_log_var - keras.backend.square(z_mean) - keras.backend.exp(z_log_var)
kl_loss = keras.backend.sum(kl_loss,axis=-1)
kl_loss *= -0.5
vae_loss = keras.backend.mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
vae.summary()
keras.utils.plot_model(vae,to_file='vae_cnn.png',show_shapes=True)
save_dir = 'vae_cnn_weights'
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
if args.weights:
filepath = os.path.join(save_dir,args.weights)
vae = vae.load_weights(filepath)
else:
#train
vae.fit(x_train,
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test,None))
filepath = os.path.join(save_dir,'vae_cnn.mnist.tf')
vae.save_weights(filepath)
plot_results(models,data,batch_size=batch_size,model_name='vae_cnn')3. 生成结果
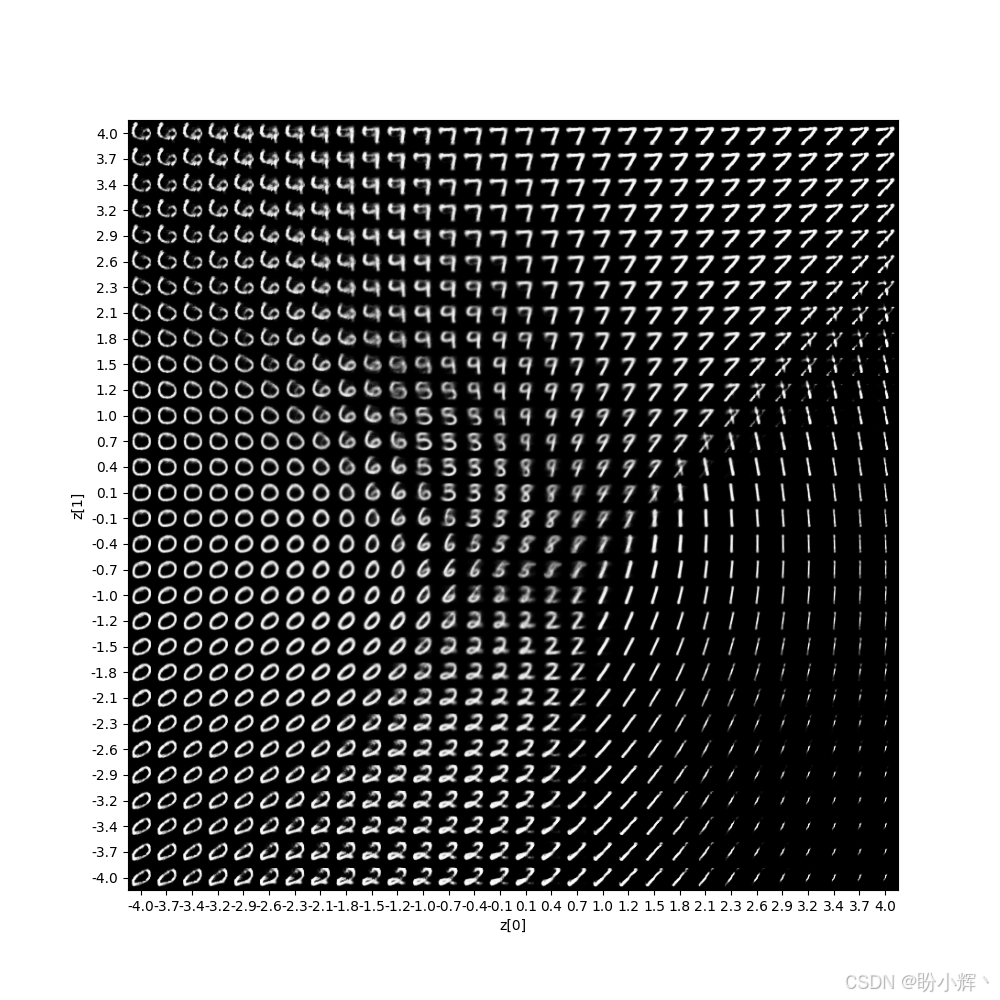
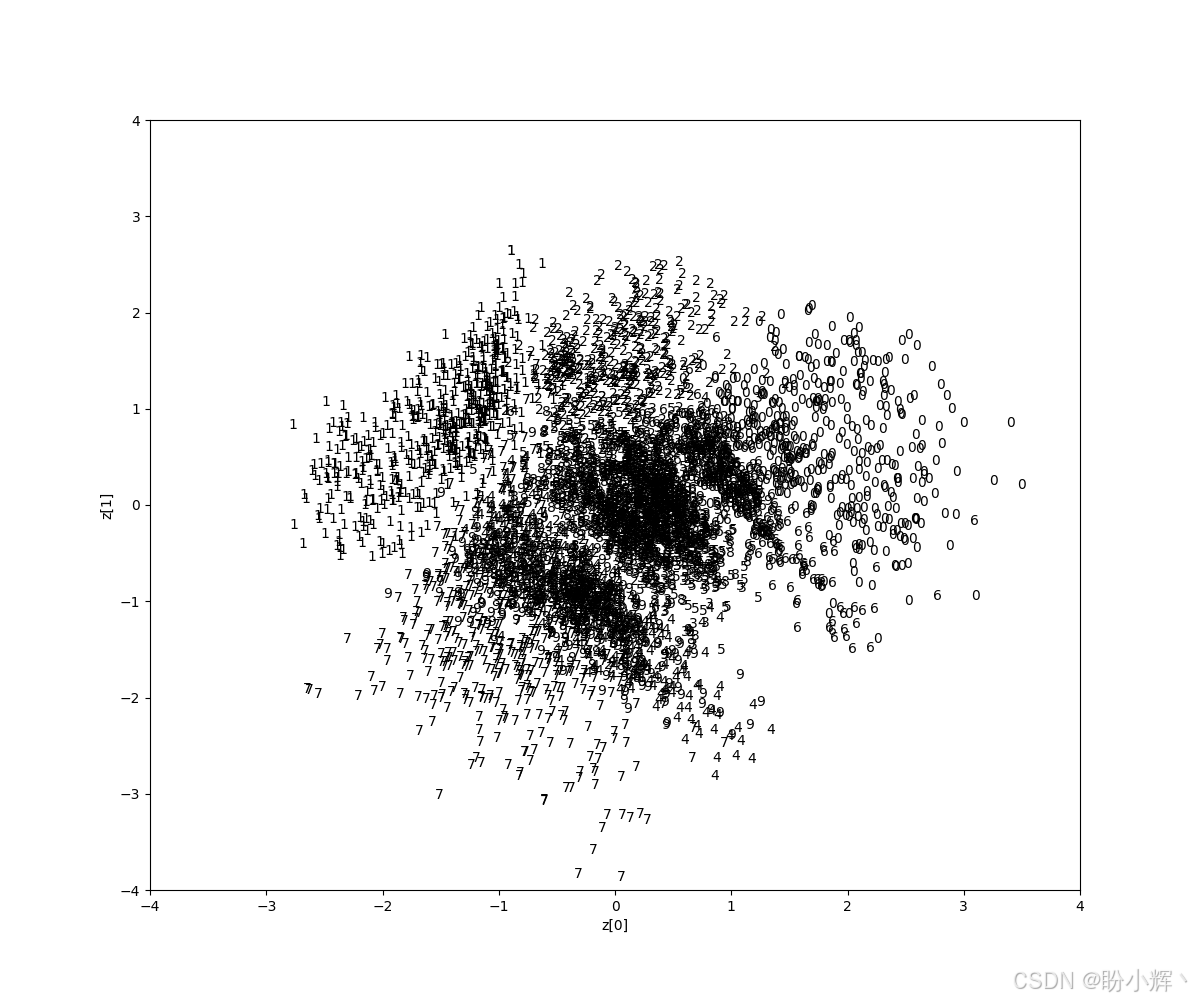
VAE 模型经过 30 个 epoch 训练后,下图展示了在连续潜空间中遍历时数字的分布情况。例如从中心区域向右移动时,数字会从 2 逐渐转变为 0:
下图展示了生成模型的输出结果。从质量上看,与基于 MLP 实现 VAE相比,模糊难辨的数字数量明显减少: