现在 AI 能写代码、能画画,但你有没有想过,让 AI 去拧个瓶盖,为什么就这么难?
因为拧瓶盖这件事,需要三个能力同时在线:
-
眼睛-视觉(Vision): 它得先看懂------哪个是瓶子?哪里是盖子?盖子纹理是什么样?
-
大脑-语言(Language):它得理解人类的指令------"拧开瓶盖"是什么意思?是顺时针还是逆时针?用多大力?
-
身体-动作(Action):它得精确地执行------手指要以多大角度抓住瓶盖?施加多大扭矩?
这三个能力,缺一不可,还得实时协同。
连接这三个能力的技术,就是 ****VLA(Vision-Language-Action)模型,****也是当下具身智能领域最核心的能力。
但现在做 VLA 研究的这群人,面临的是------现在做大模型的这群人 10 年前的工程环境。
什么意思?
VLA 领域现在的状态,类似于 2015-2016 年时候的深度学习------虽然算法创新很快,OpenVLA、RT-2、Pi0 轮番登场,但在工程上,很多团队在重复造轮子。
比如,你在顶会上看到三篇 VLA 论文,一个用 PyTorch + Llama2,一个用 JAX + PaLI,一个用 TensorFlow + 自己魔改的 VLM。想复现并对比,你得配置三套完全不同的环境。
比训练更恶心的是数据问题,想用同一份数据测试三个算法,你得写三个数据加载的脚本。
你还会面临一个问题------评测不公平,算法 A 训了 100 个 epoch,学习率 1e-4,算法 B 训了 200 个 epoch,学习率 2e-5,难以确定哪个更优。
而且,大多数 VLA 模型(OpenVLA、CogACT)在用 2023 的 Llama2,但现在 VLM 已经迭代到 Qwen2.5、Llama3 了。
为什么不用最新的?因为 VLA 代码一般和特定 VLM 深度绑定,换模型意味着大改代码,甚至重构整个训练流程。
这不是某个人、某个团队的问题,而是 VLA 研究的现状------****工程基础设施不成熟,****不得不内卷重复造轮子。
而这些痛苦,在 NLP、CV、深度学习领域里,还算可控。
因为你有 PyTorch、TensorFlow 这样的框架,有 MMDetection、Transformers 这样的工具箱。
Transformers 库允许让你能用 3 行代码加载 BERT、GPT,而不用管它们底层的实现细节。
from transformers import AutoModel model = AutoModel.from_pretrained("bert-base")
而就在最近,死磕真实世界"的老熟人---Dexmal 原力灵机推出了 Dexbotic,一套基于 PyTorch 框架开发的开源视觉-语言-动作模型(VLA)代码库,刚好提供了一种终结这种"内卷式"的重复劳动的方案。
前几天我写过一篇文章,介绍了他们不久前推出的全球首个大规模、多任务的真实机器人基准测试平台------RoboChallenge,在这个平台上,全球的机器人可以远程用真实的机器人,进行公平评测。解决的是具身智能领域"评测标准缺失"的问题。
而这次的 Dexbotic,解决的是"训练标准缺失"的问题。
就像计算机视觉有 MMDetection,NLP 有 Transformers 库,Dexbotic 试图成为具身智能领域的标准化工具箱。
总结来说,Dexbotic 提供了一套同时支持多个主流 VLA 算法的代码库,用户只需配置一次环境,基于所提供的预训练模型,即可在各类仿真环境中复现各类主流 VLA 算法。
不用再从头配环境,不用再猜别人的参数,更不用担心预训练模型过时。
老规矩,先放传送门:
官网:
https://dexbotic.com/
Paper:https://dexbotic.com/Dexbotic_Tech_Report.pdf
GitHub:https://github.com/Dexmal/dexbotic
Hugging Face:https://huggingface.co/collections/Dexmal/dexbotic-68f20493f6808a776bfc9fc4
现在我们一起看看 Dexbotic 到底做了什么?

Dexbotic 做了什么?
简单点说,Dexbotic 做了三件事:统一框架、统一数据、提供更强的预训练模型。
听起来好像没那么难,但这三件事,恰恰是现在 VLA 研究最缺的。
先说统一框架,用一个环境跑通所有主流算法。
主流的 VLA 算法有 Pi0、OpenVLA-OFT、CogACT 等,这些算法原本分散在不同的代码仓库,使用不同的深度学习框架,有些甚至没有开源完整代码。
现在在 Dexbotic 里,想测试 Pi0 和 CogACT 哪个更好,不用配两套环境,改一行代码就行:
class MyExp(BaseExp): model = "CogACT" # 从 π0 切换到 CogACT
Dexbotic 的做法是,把所有 VLA 模型抽象成两部分:视觉-语言模型(VLM)+ 动作专家(Action Expert)。VLM 负责「看懂」和「理解」,Action Expert 负责「执行」。这样一来,不管你用的是扩散模型还是流匹配,底层的 VLM 都可以复用,就这么简单。
再说统一数据格式。
这个问题比统一框架还恶心。因为每个团队采集数据的方式都不一样:有人用图片序列存储,有人用视频,有人还把机器人状态单独存成 CSV。你想混合使用不同来源的数据,得写一堆数据转换脚本,还得祈祷转换过程没出 bug。
Dexbotic 定义了一个叫 Dexdata 的格式:视频统一存成 MP4,每一帧的元数据(机器人状态、文字指令)存成 JSONL。就这么简单粗暴。

这个格式最大的好处是省空间。
以前那种把每一帧都存成 PNG 的方式,一个任务的数据可能要几个 GB,现在用视频压缩,能省下一大半存储。对于那些要在云端训练、数据传输成本很高的团队来说,是一件收益很大的事。
而且,转换一次之后,不管你是要训练 Pi0、CogACT 还是 OpenVLA,都能直接用。不用再为每个算法写一套数据加载代码。
我觉得最值得拿出来说说的,其实是预训练模型。
大多数 VLA 模型都是基于 Llama2 构建的,而 Llama2 是 2023 年的东西。现在是 2025 年,Qwen2.5、Llama3 在视觉-语言理解上已经甩开 Llama2 几条街了。
之前换模型意味着要大改代码,甚至重构整个训练流程,虽然大部分是工程活儿,但折腾一圈,成本太高。
Dexbotic 做的事情就是:基于最新的 Qwen2.5,从头预训练了一个视觉-语言模型,叫 DexboticVLM。
然后,基于这个模型,重新训练了几个主流的 VLA 算法------Pi0、CogACT、OpenVLA-OFT、MemoryVLA。效果也很明显。
拿 SimplerEnv 这个仿真环境来说,它包含 4 个操作任务:把勺子放在毛巾上、把胡萝卜放在盘子上、堆叠方块、把茄子放进篮子。
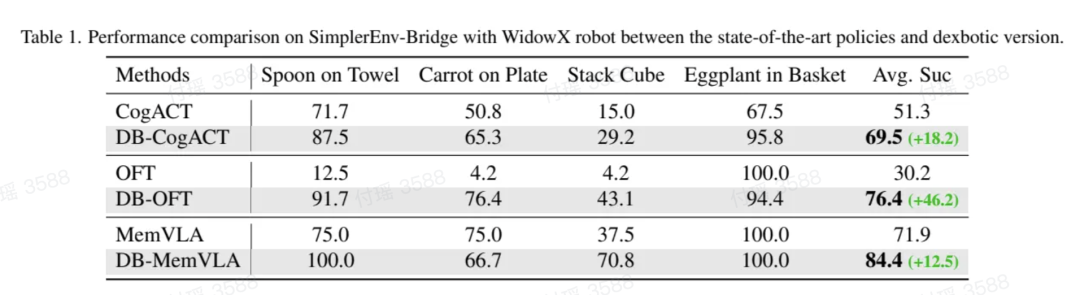
CogACT 官方版本的平均成功率是 51.3%,用了 Dexbotic 的预训练模型之后,直接飙到 69.5%------提升了 18 个百分点。
OFT 更夸张:官方版本只有 30.2%,用了 Dexbotic 之后变成 76.4%------提升了 46 个百分点。
再看 CALVIN 这个长时任务基准。它要求机器人连续完成多个指令,比如"先打开抽屉,再拿出红色方块,然后放到桌上"。这考验的是机器人的长时记忆和任务规划能力。
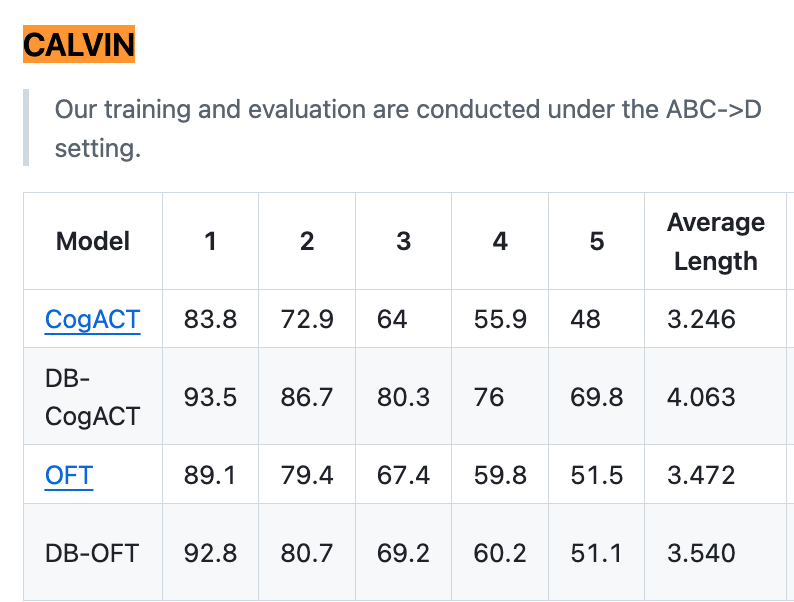
CogACT 官方版本平均能连续完成 3.25 个任务,用了 Dexbotic 之后能完成 4.06 个------提升了 25%。
意味着同样的算法,用了更好的基础模型,性能起飞了。
当然,仿真环境的成功率再高,也不如真机测试来得实在。
Dexmal 原力灵机团队在真实机器人上做了大量实验,包括 UR5e、Franka、ALOHA、ARX5 等多种平台。
从视频可以看到,有些任务的成功率已经很高了------比如用 UR5e 摆盘子,成功率达到 100%;用 ALOHA 叠碗,成功率 90%;用 ARX5 搜索绿色盒子,成功率 80%。

但也有一些任务还很困难,比如撕纸、倒薯条这种精细操作,成功率只有 20%-40%。
这也不是 Dexbotic 的问题,是这个领域要突破的问题,真实世界里的摩擦、碰撞、形变,都会导致失败。
上面介绍了这么多,可以概括一下,Dexbotic 整体架构分为三层:数据层(Data Layer)、模型层(Model Layer) 和 实验层(Experiment Layer)。
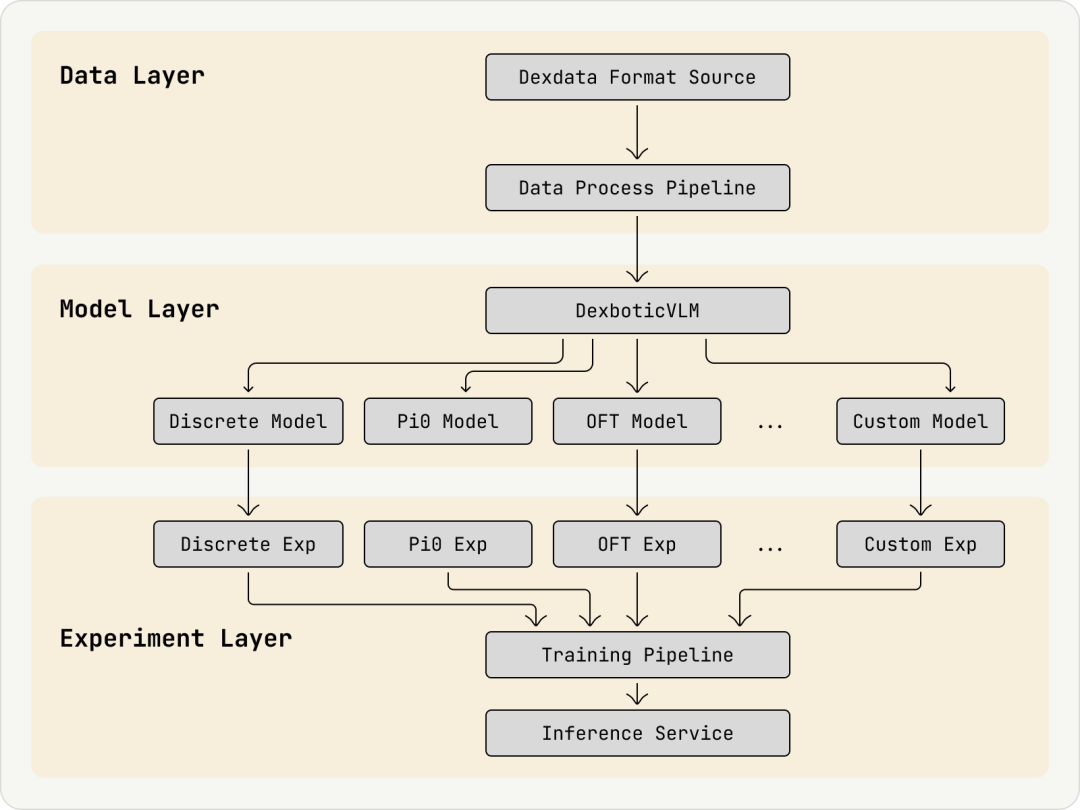
数据格式统一,模型层提供了几乎主流 VLA 算法,作为研究者,你 99% 的时间只在实验层工作。
值得一提的是,Dexbotic 的基础设施也很灵活,从云端到本地都支持。
如果你有预算,它支持阿里云 PAI、火山引擎这些云平台,可以用几百张 GPU 做大规模分布式训练。
如果你是高校学生或者小团队,它也支持本地 GPU 训练------一张 RTX 4090 就能跑起大多数 VLA 模型。不用非得有几百张 A100 才能入场。
除了这些核心能力,Dexbotic 还有一个很实用的设计:实验为中心的开发框架。
传统的深度学习项目,配置参数通常用 YAML 文件。你想改一个参数,得复制整个配置文件,找到对应的那一行,小心翼翼地修改,还得检查有没有漏改的地方。
Dexbotic 的做法是用 Python 类来管理配置。你有一个基础配置类,想改什么参数,就继承这个类,覆盖那一行:
# 基础配置 class BaseExp:
model = "DexboticVLM"
lr = 1e-4
epochs = 100
# 你的实验
class MyExp(BaseExp):
lr = 5e-5 # 只改学习率,其他自动继承
这符合软件工程的"开闭原则"------对扩展开放,对修改封闭。你改一行代码,不会影响其他部分,做对照实验的速度都变快了呢。
Dexbotic 还有一个容易被忽视的价值:它为未来的"全身控制"做了架构准备。
现在的机器人研究,通常分两个方向:
-
****操作(Manipulation):****用机械臂抓取、放置
-
****导航(Navigation):****在环境中移动、避障
这两个方向往往是分开研究的。但未来的机器人,显然不能"只会站着抓东西"或"只会走路不干活"。它需要既能走到厨房,又能打开冰箱拿出可乐。
Dexbotic 在设计时考虑了这一点,把操作类和导航类统一到了一套框架下:
-
支持操作类策略:Pi0、CogACT、OpenVLA-OFT
-
支持导航类策略:MUVLA
****这意味着,未来你可以在同一个框架下,训练"既能走又能干活"的机器人。****虽然现在还做不到,但至少架构上留了空间。
最后,聊聊开源。
Dexbotic 是完全开源的,代码、预训练模型都在 GitHub 和 Hugging Face 上。
而且,为了进一步软硬件协同推进具身智能发展,降低了研究者的使用、改造的门槛,Dexmal 原力灵机还开源了DOS - W1 (Dexbotic Open Source-W1)------一款低成本的双臂机器人硬件平台。所有硬件设计文件都公开,使用消费级电机和传感器,普通实验室就能组装。

以及全球首个大规模、多任务的真实机器人基准测试平台 RoboChallenge:

至此,Dexmal 原力灵机的版图非常清晰了:
-
软件(大脑) :Dexbotic 提供了标准化的"软件开发工具箱";
-
硬件(身体) :DOS-W1 系列提供了开放、低成本的"硬件身体";
-
标准(试炼) :RoboChallenge 则提供了公平衡量"AI 大脑"能力的"标准竞技场"。
这套组合拳,试图从根本上降低具身智能研究的门槛。
那 Dexbotic 能否真正成为具身智能的"标准工具箱"?
可能这还需要时间验证。但是对于那些正在被"配置地狱"和"高昂成本"双重折磨的研究者来说---这个正在形成的完整生态,或许,真的值得一试!
10月23日晚 19:00,Dexmal 原力灵机创始团队成员汪天才将现身直播间,讲解开源一站式 VLA 工具箱 Dexbotic,欢迎大家扫描图中二维码预约观看、线上交流 :
