本文讲解了将原始的手绘图表(比如白板照片、流程图、线框图)转换成结构化的、机器可读的 JSON。这事儿听起来简单,实践起来却复杂得惊人。本文将通过我的技术实践历程,介绍实际遇到的困难以及真正有效的解决方案。
挑战:为什么图表识别比你想象的更难
当你看一张流程图时,你的大脑能瞬间理解其中的关系:方框代表概念,箭头表示流向,文本标签提供含义。但对机器来说,这完全是另一回事。
核心难点在于:
- 箭头模糊性: 那是虚线、点线,还是没画好的实线?这三种情况需要不同处理。
- 元素重叠: 当箭头交叉时,你怎么知道哪个端点属于哪条箭头?
- 文本干扰: 如果有人直接把标签写在箭头上怎么办?
- 绘制风格不一致: 一个人画圆滑的弯,另一个人画带角的折。同样的箭头,像素模式却完全不同。
这些都不是极端案例------在现实世界的图表中比比皆是。
系统架构:三个核心部分
解决方案围绕三个相互关联的子系统构建:
- 目标检测(系统的"眼睛")
使用 RF-DETR作为主干网络,训练模型识别 17 个不同类别:形状(矩形、圆形、菱形、五边形)、各种样式的箭头(实线、虚线、点线、双线)以及箭头头部。
- 训练挑战: 模型最初无法识别旋转的形状------倾斜 30 度的形状会被错误分类。这不是根本性缺陷,而是数据集的问题。
- 解决方法: 在分析失败案例后,我通过细粒度旋转(10°--30° 增量)来增强训练数据。事后回想这似乎显而易见,但这需要实际运行模型、观察失败并理解其原因。在重新平衡数据集后,对这些形状的检测准确率显著提升。
- 最终结果: 所有类别的 mAP 达到 0.8265,其中箭头(0.90 AP)和箭头头部(实线箭头可达 0.95+ AP)的表现尤其出色。
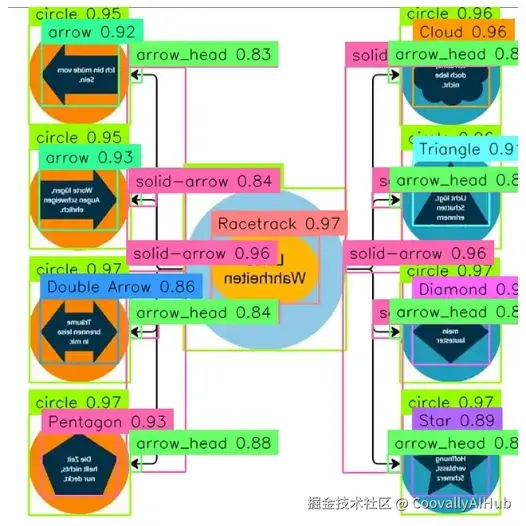
- 文本识别(系统的"翻译官")
我集成了 PaddleOCR 来提取形状内部和连接线旁边的文本。但 OCR 不仅仅是读取文字------它还要理解文本出现的位置。
工作流程:
- RF-DETR 提供感兴趣区域(裁剪出的图像部分)
- 应用锐化内核(小心混合以避免过度增强)
- 运行 OCR 并捕获边界框、识别文本和置信度分数
- 标记任何与箭头路径重叠的文本
这种重叠检测对下一个组件至关重要。
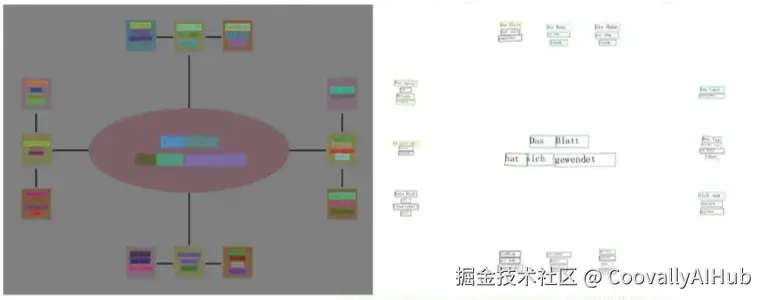
- 空间关系映射(系统的"问题解决者")
这里是真正复杂的地方。我需要回答:哪个箭头连接哪个形状?方向如何?
算法:鲁棒的箭头端点检测
核心创新在于:最远点轮廓分析。与其直接预测端点(当箭头是虚线、曲线或被遮挡时会失败),不如将箭头视为连续形状,并找到其轮廓上距离最远的两个点。
处理流程:
第一步:自适应二值化掩码 - 将裁剪出的箭头转换为二值图像(仅黑白)。这能将箭头与周围噪声分离开。

第二步:连接缺口 - 对于虚线和点线箭头,使用形态学闭运算和膨胀操作来连接视觉上的缺口。结果是:即使原图是断开的,也能得到一条连续的线。


第三步:提取轮廓 - 在二值图像中找到所有轮廓。通常有一个主轮廓代表箭身体,但通过过滤启发式方法(轮廓面积、周长与面积比)可以确保选中正确的那个。

第四步:寻找最远点 - 沿着轮廓采样点,并计算所有点对之间的距离。具有最大间距的两个点?那就是你的端点。 这种方法非常鲁棒------无论箭头是弯曲的、笔直的还是奇怪扭曲的,它都有效。
第五步:确定方向 - 使用检测到的箭头头部来判断哪个点是起点,哪个是终点。没有箭头头部?则回退到曲率分析或一个训练来预测箭头方向的小型 ML 模型。
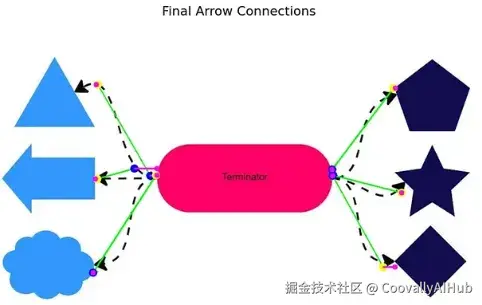
为何有效:传统的端点检测在处理不完整或重叠的绘图时会失败。但最远点方法对噪声、弯曲甚至遮挡都具有不变性。只要箭头大部分可见,它就能找到端点。
实际问题(以及解决方案)
- 问题 1:虚线和点线箭头
图表使用虚线来表示条件流或不同的关系。挑战在于:你的二值掩码显示的是不连续的线段,而不是连续的线。
解决方案:
- 首先,尝试形态学闭运算(一种标准图像处理技术)来连接规则的间隙。
- 对于不规则的间距,实现虚线插值:找到最近的虚线端点并重建缺失的线段。
结果:系统将所有箭头类型都视为连续路径。
测试这个方案需要收集绘制不佳的虚线箭头样本,并迭代改进连接缺口的逻辑。这不光鲜,但必不可少。



- 问题 2:重叠箭头
有时图表很拥挤。两条箭头交叉,你需要弄清楚哪些端点对属于同一条箭头。
解决方案:
- 为每条箭头生成候选端点配对。
- 对每个候选配对,计算一个"平直度分数":欧几里得距离 ÷ 沿着箭头骨架的实际路径长度。
- 平直度分数告诉你路径有多直接------正确的配对几乎是直的,而错误的配对比比弯折。
- 使用基于骨架化路径的广度优先搜索来探索选项并选出最佳者。
这种启发式方法出奇地有效。在拥挤的布局中,正确的配对几乎总是拥有最高的平直度分数。
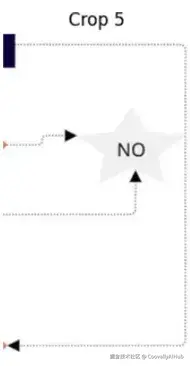
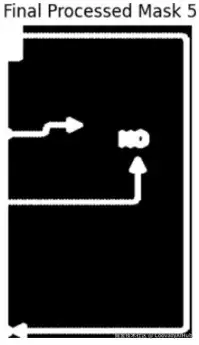
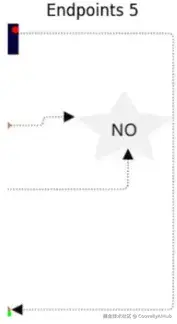
- 问题 3:文本干扰
有人把标签放在箭头上方,破坏了视觉连续性。二值掩码现在显示箭头被分割成两个片段。
解决方案:
- 使用 OCR 结果来识别文本遮挡箭头的确切区域。
- 找到文本间隙前后的箭头像素。
- 插值一条平滑路径来连接这些点。
- 箭头被恢复,且不会错误地将文本解释为形状的一部分。
这需要 OCR 和空间映射组件之间的紧密配合,但它显著提高了鲁棒性。
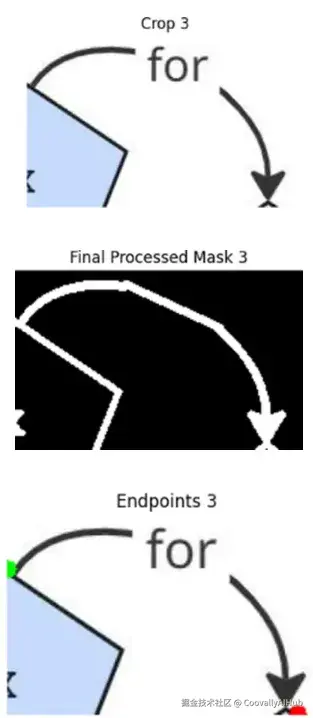
- 问题 4:箭头头部检测的脆弱性
箭头头部很小,而且绘制常常不一致。最初,检测器在这方面很挣扎,尤其是在放大或低分辨率图像上。
解决方案:
- 将箭头头部作为主要的方向信号(如果可用)。
- 实现备用启发式方法:局部曲率分析和方向预测模型。
- 训练一个小型 ResNet 来处理特定形状的数据,以从分割后的掩码预测方向角。
这种分层方法意味着即使箭头头部检测失败,系统也能保持功能。
- 颜色作为上下文信息
使用 K-Means 聚类和基于 HSV 色彩空间的流程添加了颜色分类。这不仅仅是为了美观------颜色信息有助于在重叠场景中分离视觉上纠缠的箭头, essentially 提供了另一个用于消除歧义的维度。
从检测到结构:最终输出
在完成所有检测和关系映射之后,系统输出一个结构化的 JSON 文件,将整个图表编码为一个图:
- 节点:每个形状、箭头和文本元素,包含位置、大小、几何形状、颜色和标签。
- 边:节点之间的有向连接,捕获语义关系。
- 画布:全局尺寸和元数据。
这个 JSON 成为下游应用(可视化、查询、流程挖掘等,任何用例需求)的基础。
结果与经验教训
- 检测性能:
整体 mAP 为 0.8265(满分 0.95 的尺度下)。
在 294 个检测到的箭头上,箭头连接准确率的精确度和召回率达到 96.71%。
- 关键洞见:
- 数据集质量胜过模型复杂度:投入时间进行深思熟虑的数据增强(尤其是细粒度旋转)比调整检测器架构能带来更好的结果。
- 几何启发式方法是你的朋友:当机器学习变得模糊时,回归几何原理。最远点算法和平直度分数之所以有效,是因为它们基于几何学,而不是统计学。
- 尽早用真实数据测试:许多问题只有在用实际手绘图表测试后才会暴露。合成训练数据有价值但不完整。
- 通过冗余实现鲁棒性:多重备用策略(箭头头部检测 → 曲率分析 → ML 模型)意味着即使单个组件失败,系统也能保持有效。
- 集成是难点:让 OCR、检测、分割和空间映射很好地协同工作,需要仔细的 API 设计和大量测试。模型相对简单;工程实现很复杂。
如果重来一次,会怎么做:
- 一开始就使用更多样化的训练数据------奇怪的角度、糟糕的光线、重叠的元素。
- 更早投入可视化调试工具,以了解模型"看到"了什么。
- 对箭头头部检测使用集成方法,而不是依赖单一检测器。
- 考虑在空间关联步骤使用图神经网络(尽管传统的 KD-Tree 匹配已经足够好用)。
总结
构建生产就绪的计算机视觉系统意味着既要解决理论问题(如何检测物体?),也要解决实际问题(如何处理混乱的现实世界数据?)。最远点轮廓算法和缺口连接策略并非突破性创新------它们是源于理解手绘图的约束并尊重"完美数据不存在"这一现实而产生的解决方案。
如果你正在从事涉及结构化图表、文档分析或流程挖掘的视觉问题研究,我希望这里概述的方法------几何启发式、分层备用方案和精心集成------能对你有所助益。
你构建过从混乱图像中提取结构的视觉系统吗?我很想在评论区听到你的方法。哪些问题最让你感到意外?