- 开发语言:Python
- 框架:django
- Python版本:python3.8
- 数据库:mysql 5.7
- 数据库工具:Navicat12
- 开发软件:PyCharm
网站首页

用户注册
用户登录

招聘信息界面

个人中心
管理员登录

管理员功能界面
用户管理
招聘信息
薪资预测
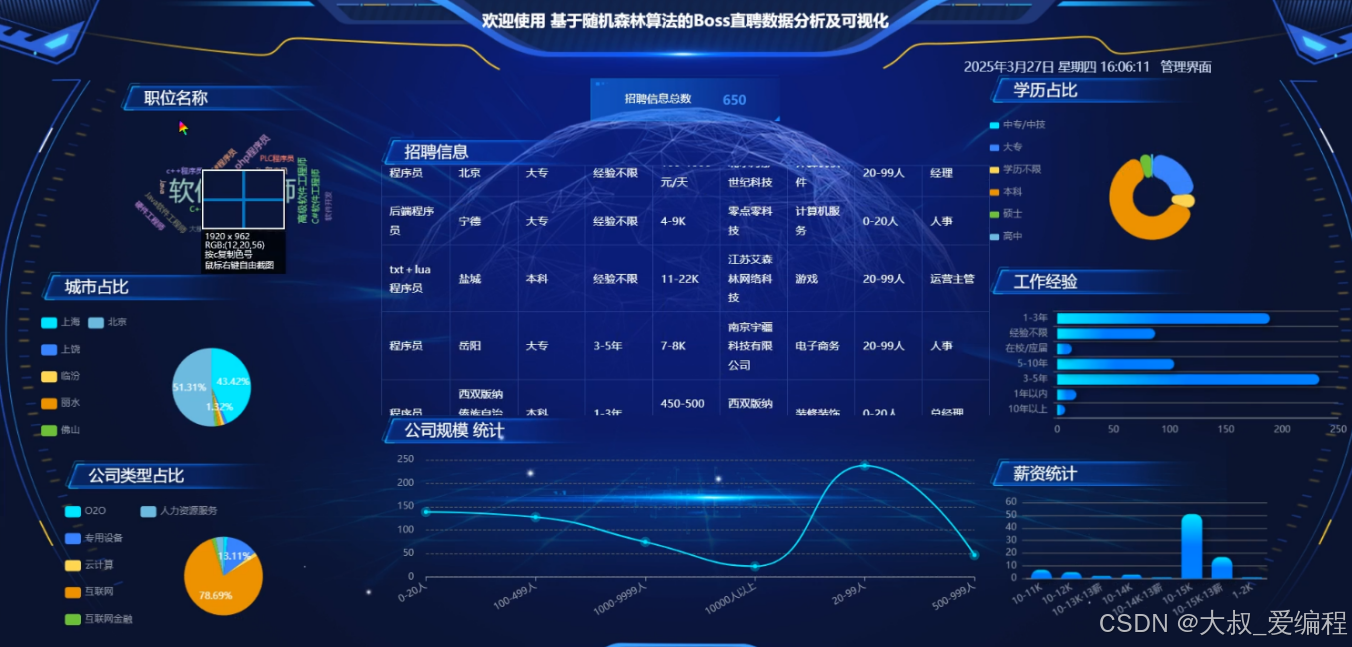
看板展示
摘要
本项目综合运用 Django、Python、Scrapy 以及机器学习等前沿技术来实现核心功能。借助Scrapy的高效爬虫特性,从Boss直聘平台采集丰富的招聘信息和用户数据,再利用Python进行数据的精细清洗、预处理以及深度分析。通过机器学习算法构建出精准的薪资预测模型,为薪资判断提供可靠依据。基于Django搭建的管理系统,管理员可以对用户进行全方位管理,包括注册、权限分配等操作,对招聘信息能够进行审核、分类更新,同时对薪资预测模型持续优化,保障其准确性和时效性。
研究背景
在当今快速发展的数字化时代,就业市场发生了翻天覆地的变化。随着互联网技术的普及,在线招聘平台成为企业寻找人才和求职者寻找工作的重要渠道。Boss直聘作为一款具有创新性和广泛影响力的在线招聘平台,凭借其独特的直聊模式,打破了传统招聘流程的繁琐,极大地提高了招聘效率,吸引了大量的企业和求职者入驻1。随着平台的不断发展,积累了海量的招聘数据,涵盖了职位信息、企业信息、求职者信息以及薪资待遇等多个方面。这些数据蕴含着丰富的信息,能够反映出就业市场的供需关系、行业发展趋势以及薪资水平变化等重要内容。然而,如何从这些海量的数据中提取有价值的信息,为企业、求职者和政府部门提供决策支持,成为了一个亟待解决的问题。
关键技术
Python是解释型的脚本语言,在运行过程中,把程序转换为字节码和机器语言,说明性语言的程序在运行之前不必进行编译,而是一个专用的解释器,当被执行时,它都会被翻译,与之对应的还有编译性语言。
同时,这也是一种用于电脑编程的跨平台语言,这是一门将编译、交互和面向对象相结合的脚本语言(script language)。
Django用Python编写,属于开源Web应用程序框架。采用(模型M、视图V和模板t)的框架模式。该框架以比利时吉普赛爵士吉他手詹戈·莱因哈特命名。该架构的主要组件如下:
1.用于创建模型的对象关系映射。
2.最终目标是为用户设计一个完美的管理界面。
3.是目前最流行的URL设计解决方案。
4.模板语言对设计师来说是最友好的。
5.缓存系统。
Vue是一款流行的开源JavaScript框架,用于构建用户界面和单页面应用程序。Vue的核心库只关注视图层,易于上手并且可以与其他库或现有项目轻松整合。
Hadoop是一个由Apache基金会维护的开源框架,它允许分布式处理大数据集在计算集群中的大规模数据。它的核心设计哲学是将应用程序带到数据所在的位置,而不是将大量数据传输到应用程序所在的服务器。Hadoop主要由两个组件组成:Hadoop Distributed File System(HDFS)和MapReduce。HDFS提供了高度可靠、高吞吐量的数据存储解决方案,而MapReduce则是一个编程模型,用于处理这些大量数据。Hadoop的优势在于其可扩展性、经济性和灵活性,使其成为大数据分析的首选工具。
MYSQL数据库运行速度快,安全性能也很高,而且对使用的平台没有任何的限制,所以被广泛应运到系统的开发中。MySQL是一个开源和多线程的关系管理数据库系统,MySQL是开放源代码的数据库,具有跨平台性。
B/S(浏览器/服务器)结构是目前主流的网络化的结构模式,它能够把系统核心功能集中在服务器上面,可以帮助系统开发人员简化操作,便于维护和使用。
随机森林算法是机器学习领域中一种强大的集成学习方法。它以决策树为基础,通过构建多棵决策树组成 "森林",综合它们的预测结果来进行最终决策。在构建随机森林时,首先从原始训练数据集中有放回地随机抽样,生成多个与原数据集规模相同的子数据集,每棵决策树基于不同的子数据集进行训练,这增加了模型的多样性。其次,在每棵决策树的节点分裂过程中,不是考虑所有特征,而是随机选择一部分特征来寻找最优分裂点,进一步降低了树与树之间的相关性。随机森林算法具有诸多优点。它对数据的适应性强,能处理多种类型的数据,包括数值型和类别型数据。同时,它具有出色的抗过拟合能力,因为多棵决策树的投票机制能有效平衡个别树的偏差。
系统分析
对系统的可行性分析以及对所有功能需求进行详细的分析,来查看该系统是否具有开发的可能。
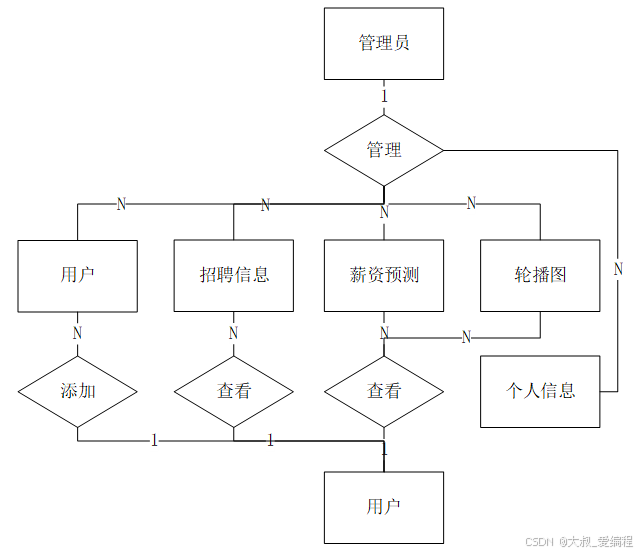
系统设计
功能模块设计和数据库设计这两部分内容都有专门的表格和图片表示。
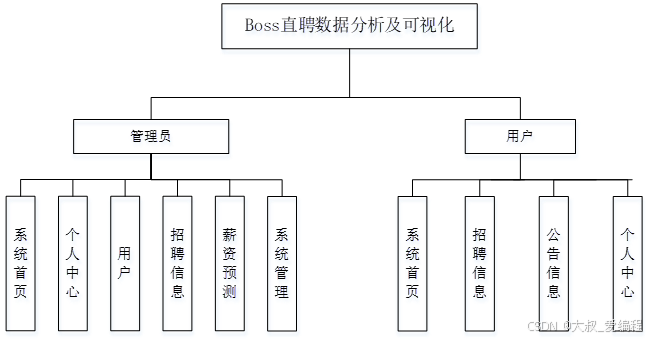
系统实现
管理员登录系统后,可以访问并管理系统首页、个人中心、用户、招聘信息、薪资预测、系统管理等各项管理功能,并对这些内容执行具体的操作和管理任务。网站首页的基本设计遵循列固定、中间栏、标题和脚注的布局原则。针对每个子模块,我们分别创建独立的HTML和CSS网页文件,并在这些文件中实现各自的功能。用户进入该模块后,可以修改自己权限内的个人资料,包括学号、密码等。此外,他们还能进行多项操作,如更改密码、我的收藏等。
代码实现
python
#获取预测可视化图表接口
def zhipincxyforecast_forecastimgs(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, 'message': 'success'}
# 指定目录
directory = os.path.join(parent_directory, "templates", "upload", "zhipincxyforecast")
# 获取目录下的所有文件和文件夹名称
all_items = os.listdir(directory)
# 过滤出文件(排除文件夹)
files = [f'upload/zhipincxyforecast/{item}' for item in all_items if os.path.isfile(os.path.join(directory, item))]
msg["data"] = files
fontlist=[]
for font in fm.fontManager.ttflist:
fontlist.append(font.name)
msg["message"]=fontlist
return JsonResponse(msg, encoder=CustomJsonEncoder)
def zhipincxyforecast_forecast(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
#1.获取数据集
req_dict = request.session.get("req_dict")
connection = pymysql.connect(**mysql_config)
query = "SELECT cityname,jobdegree,jobexperience, salarydesc,jobname FROM zhipincxy"
#2.处理缺失值
data = pd.read_sql(query, connection).dropna()
id = req_dict.pop('id',None)
grouped = data.groupby([
'jobname',
])
df = pd.DataFrame(columns=[
'salarydesc',
'jobname',
])
for (jobname), group in grouped:
y_predict = to_forecast(group,req_dict,''.join((jobname)).replace("/",""))
if not y_predict.empty:
y_predict['jobname'] = jobname
df = pd.concat([df, y_predict], ignore_index=True)
#9.创建数据库连接,将DataFrame 插入数据库
connection_string = f"mysql+pymysql://{mysql_config['user']}:{mysql_config['password']}@{mysql_config['host']}:{mysql_config['port']}/{mysql_config['database']}"
engine = create_engine(connection_string)
try:
if req_dict :
#遍历 DataFrame,并逐行更新数据库
with engine.connect() as connection:
for index, row in df.iterrows():
sql = """
INSERT INTO zhipincxyforecast (id
,salarydesc
)
VALUES (%(id)s
,%(salarydesc)s
)
ON DUPLICATE KEY UPDATE
salarydesc = VALUES(salarydesc)
"""
connection.execute(sql, {'id': id
, 'salarydesc': row['salarydesc']
})
else:
df.to_sql('zhipincxyforecast', con=engine, if_exists='append', index=False)
print("数据更新成功!")
except Exception as e:
print(f"发生错误: {e}")
finally:
engine.dispose() # 关闭数据库连接
return JsonResponse(msg, encoder=CustomJsonEncoder)
def to_forecast(data,req_dict,value):
if len(data) < 5:
print(f"的样本数量不足: {len(data)}")
return pd.DataFrame()
#3.处理特征值和目标值
labels={}
for key in data.keys():
if pd.api.types.is_string_dtype(data[key]):
label_encoder = LabelEncoder()
labels[key] = label_encoder
data[key] = label_encoder.fit_transform(data[key])
#4.数据集划分
X = data[[
'cityname',
'jobdegree',
'jobexperience',
]]
y = data[[
'salarydesc',
]]
x_train, x_test, y_train, y_test = train_test_split(X, y,test_size=0.2, random_state=22)
#5.构建预测特征值
#根据输入的特征值去预测
if req_dict:
req_dict.pop('addtime',None)
future_df = pd.DataFrame([req_dict])
for key in future_df.keys():
if key in labels:
encoder = labels[key]
values = future_df[key][0]
try:
values = encoder.transform([values])[0]
except ValueError as e: #处理未见过的标签
values = np.array([encoder.transform([v])[0] if v in encoder.classes_ else -1 for v in values]).sum()
future_df[key][0] = values
else:
future_df = x_test
#特征工程-标准化
estimator_file = os.path.join(parent_directory, "zhipincxyforecast.pkl")
estimator = RandomForestRegressor(n_estimators=100, random_state=42)
_, num_columns = y_train.shape
if num_columns>=2:
estimator.fit(x_train, y_train)
else:
estimator.fit(x_train, y_train.values.ravel())
y_pred = estimator.predict(x_test)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体 SimHei
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
# 绘制预测值与实际值的散点图
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.5)
plt.xlabel("实际值")
plt.ylabel("预测值")
plt.title("实际值与预测值(随机森林回归)")
directory =os.path.join(parent_directory, "templates","upload","zhipincxyforecast","figure.png")
os.makedirs(os.path.dirname(directory), exist_ok=True)
plt.savefig(directory)
plt.clf()
# 绘制特征重要性
feature_importances = estimator.feature_importances_
features = [
'cityname',
'jobdegree',
'jobexperience',
]
sns.barplot(x=feature_importances, y=features)
plt.xlabel("重要性得分")
plt.ylabel("特征")
plt.title("特征重要性")
if value!=None:
directory =os.path.join(parent_directory, "templates","upload","zhipincxyforecast","{value}_figure.png")
os.makedirs(os.path.dirname(directory), exist_ok=True)
plt.savefig(directory)
else:
directory =os.path.join(parent_directory, "templates","upload","zhipincxyforecast","figure_other.png")
os.makedirs(os.path.dirname(directory), exist_ok=True)
plt.savefig(directory)
plt.clf()
#保存模型
joblib.dump(estimator, estimator_file)
y_pred = estimator.predict(x_test)
comparison_df = pd.DataFrame({'实际值': y_test.values.flatten(), '预测值': y_pred.flatten()})
comparison_df = comparison_df.sort_values(by='实际值') # 按实际销量排序,方便可视化
# 绘制实际值 vs 预测值散点图
plt.figure(figsize=(10, 6))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体 SimHei
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
sns.scatterplot(x=comparison_df['实际值'], y=comparison_df['预测值'], color='blue', label='预测值')
plt.plot([comparison_df['实际值'].min(), comparison_df['实际值'].max()],
[comparison_df['实际值'].min(), comparison_df['实际值'].max()],
color='red', linestyle='--', label='完美预测线')
plt.xlabel('实际值')
plt.ylabel('预测值')
plt.title('实际值 vs 预测值')
plt.legend()
directory =os.path.join(parent_directory, "templates","upload","zhipincxyforecast","figure.png")
os.makedirs(os.path.dirname(directory), exist_ok=True)
plt.savefig(directory)
plt.clf()
plt.close()
#7.进行预测
y_predict = estimator.predict(future_df)
if isinstance(y_predict[0], numbers.Number) or len(y_predict[0])<2:
y_predict = np.mean(y_predict, axis=0)
if not isinstance(y_predict, np.ndarray):
y_predict = np.expand_dims(y_predict, axis=0)
df = pd.DataFrame(y_predict, columns=[
'salarydesc',
])
df['salarydesc']=df['salarydesc'].astype(int)
df['salarydesc'] = labels['salarydesc'].inverse_transform(df['salarydesc'])
return df系统测试
首先,我们将Boss直聘数据分析及可视化划分为多个大模块,并逐一进行功能测试。通过反复多次的测试,确保每个模块的功能均正常,且测试结果与预期一致。在模块化测试通过后,我们将采用数据跟踪的方式,对程序中的数据进行全面的跟踪和测试。这一步骤旨在确保程序中的数据保持统一性、完整性和正确性。最后,我们将对整个程序进行综合性的测试。在程序整体测试通过后,我们将对程序的整体性能进行评价,以确认其是否满足实际需求。
结论
在此次基于随机森林算法的Boss直聘数据分析及可视化研究之旅中,我们成功迈出了探索性的关键步伐。通过运用先进的数据挖掘技术与可视化工具,深入剖析了海量招聘数据,从职位需求、薪资水平、技能要求等多个维度,揭示了就业市场的内在规律与发展趋势。随机森林算法在薪资预测、职位匹配等关键环节展现出强大的优势,为企业精准招聘、求职者高效求职提供了科学依据。可视化成果以直观易懂的图表形式,将复杂的数据转化为清晰的信息,极大地提升了数据的可读性与应用价值。