前面讲了训练集上效果比较差的场景分别对激活函数和学习率进行了优化,现在考虑在测试集上效果比较差的场景如何去调整
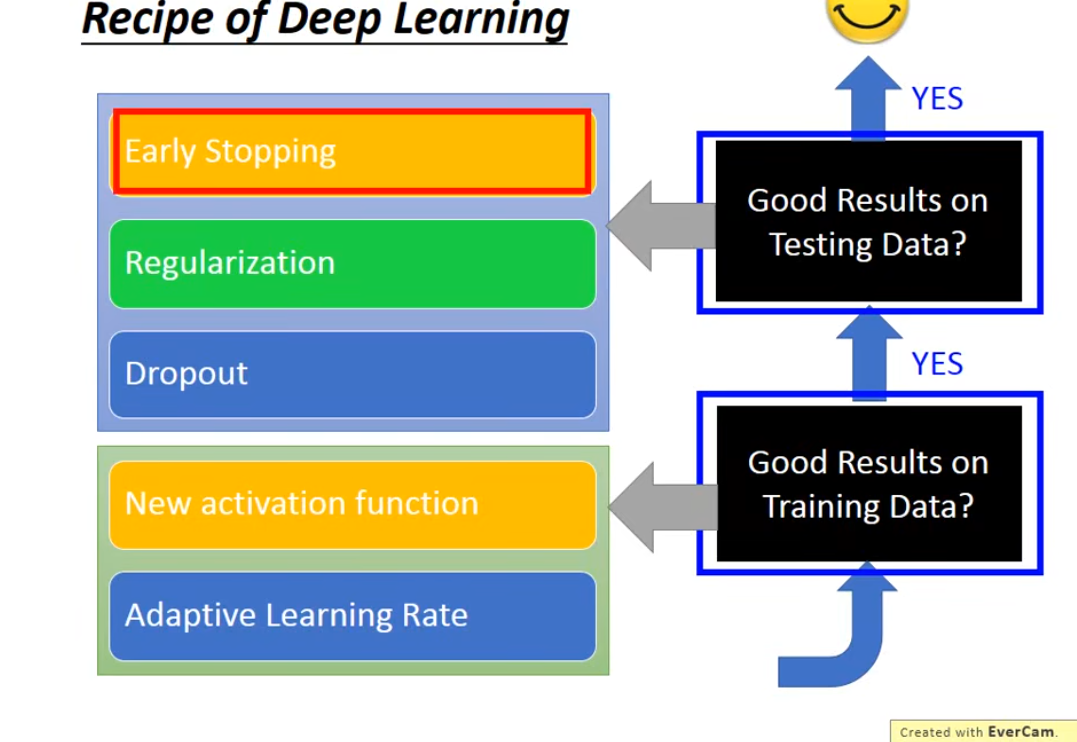
通常有三种方法:
(1)early stopping
(2)regularization
(3)dropout
early stopping
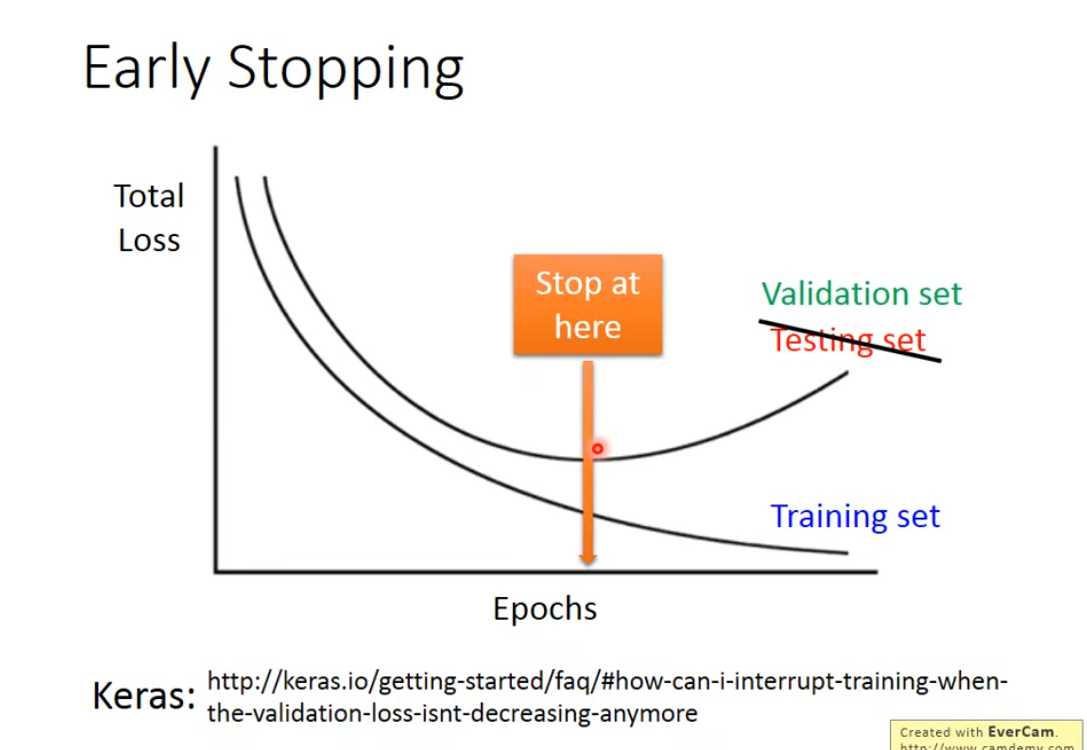
这个方案就是说,当我们在测试集上得到的误差开始增大时,就该停下梯度下降,由于testing set时不可知的,一般用验证集来取代,也就是说每完成一次epoch,就要去计算一下validation set上的误差
regularization
L2正则化
- 核心概念
L2正则化,也常被称为 权重衰减 或 岭回归,是一种用于防止机器学习模型过拟合 的技术。
它的核心思想非常直观:在损失函数中,除了原本的损失项(如均方误差、交叉熵),额外添加一个与模型权重的平方大小成正比的惩罚项。 这样做的目的是迫使模型学习到"更小"的权重。
-
要解决什么问题?(过拟合)
过拟合:模型在训练数据上表现非常好,但在未见过的测试数据上表现很差。这意味着模型过度学习了训练数据中的细节和噪声,而不是底层的一般规律。
复杂模型的风险:一个拥有大量参数的模型很容易通过"记住"训练数据来拟合各种复杂的、不必要的模式,从而导致过拟合。
L2正则化通过惩罚大的权重,来鼓励模型变得"更简单"。
- L2正则化如何工作?
a) 修改损失函数
L2正则化通过修改我们想要最小化的目标函数来实现。
原始损失函数:
J(w;X,y)J(w;X,y)J(w;X,y)
其中 w代表模型的所有权重参数,XX和 y 是数据和标签。
加入L2正则化后的新损失函数:
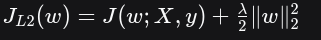
让我们来分解这个公式:
原始损失项 J(w;X,y):衡量模型预测与真实标签之间的差距。我们的目标是让它最小化。
L2惩罚项 λ2∥w∥22\frac{\lambda}{2} \lVert w \rVert^2_22λ∥w∥22 :
∥w∥22\lVert w \rVert^2_2∥w∥22 是权向量 ww 的 L2范数的平方。具体计算就是所有权重的平方和:w12+w22+...+wn2w_1^2+w_2^2+...+w_n^2w12+w22+...+wn2。
λλ(lambda):这是一个超参数,称为正则化强度。它控制着我们对大权重的惩罚力度。
λ=0:正则化无效,模型退回到原始状态。
λ 很小:惩罚很轻,模型几乎不受影响。
λ很大:惩罚很重,模型会极力保持权重接近零,可能导致欠拟合(模型过于简单,无法捕捉数据中的有效模式)。
系数 2分之1:这是一个为了数学推导方便的缩放因子。在求导时,平方项会产生一个2,与之抵消,使得后续的梯度形式更整洁。b) 对权重更新的影响(为什么叫"权重衰减"?
我们来看一下在梯度下降中,权重是如何更新的。
原始SGD的权重更新(无正则化):
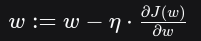
其中 ηη 是学习率。
加入L2正则化后的权重更新:
我们先求新损失函数的梯度:
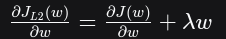
然后代入更新公式:
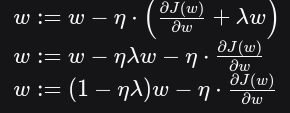
请注意这个更新公式的第一项 (1−ηλ)w。在每次更新时,权重 w 都会先被乘以一个小于1的因子 (1−ηλ),然后再减去正常的梯度。这个"在每一步都让权重线性缩小"的行为,就像物理中的衰减一样,所以L2正则化又得名 权重衰减。
-
为什么L2正则化能防止过拟合?------直观理解
鼓励小权重和分散责任:通过惩罚大的权重,L2正则化鼓励网络使用所有输入特征,而不是过分依赖少数几个特征。每个特征都对输出有较小但广泛的贡献,这使得模型对个别特征噪声的敏感度降低,从而提升了泛化能力。
促进平滑性:一个具有较小权重的模型,其输出对于输入的变化通常会更平缓、更不敏感。这意味着模型学习到的是更宏观、更稳定的模式,而不是去拟合训练数据中那些急剧变化的、可能是噪声的点。
奥卡姆剃刀原理:在效果相同的情况下,更简单的模型通常是更好的。L2正则化通过惩罚复杂度(大权重),倾向于选择一个更简单的模型。
与L1正则化的对比

简单来说,L2正则化就像给模型加上一个"紧箍咒",告诉它在拟合数据的同时,也要保持"谦虚"(权重小一点),不要过于复杂,从而学得更通用、更稳健。L2相当于减去参数乘一个固定的值,L1相当于减去一个固定值
L1正则化


很好理解L2对比较大的参数减少比较多,L1会平均
dropout
- 核心概念
Dropout 是一种在深度学习领域非常流行且强大的正则化技术,用于防止神经网络过拟合。
它的核心思想非常简单,却极其有效:
在训练过程的每次迭代中,随机地"丢弃"(即暂时隐藏)网络中的一部分神经元。- 要解决什么问题?(过拟合)
过拟合是指模型在训练数据上表现非常好,但在未见过的测试数据上表现很差。在神经网络中,过拟合常常发生在:
网络规模过大(参数过多)。
训练数据量不足。
训练时间过长。神经元之间可能会发展出复杂的协同依赖关系("共适应"),这种关系在训练集上很有效,但无法泛化到新数据。Dropout 通过破坏这种协同依赖来强制增强网络的鲁棒性。
- Dropout 如何工作?
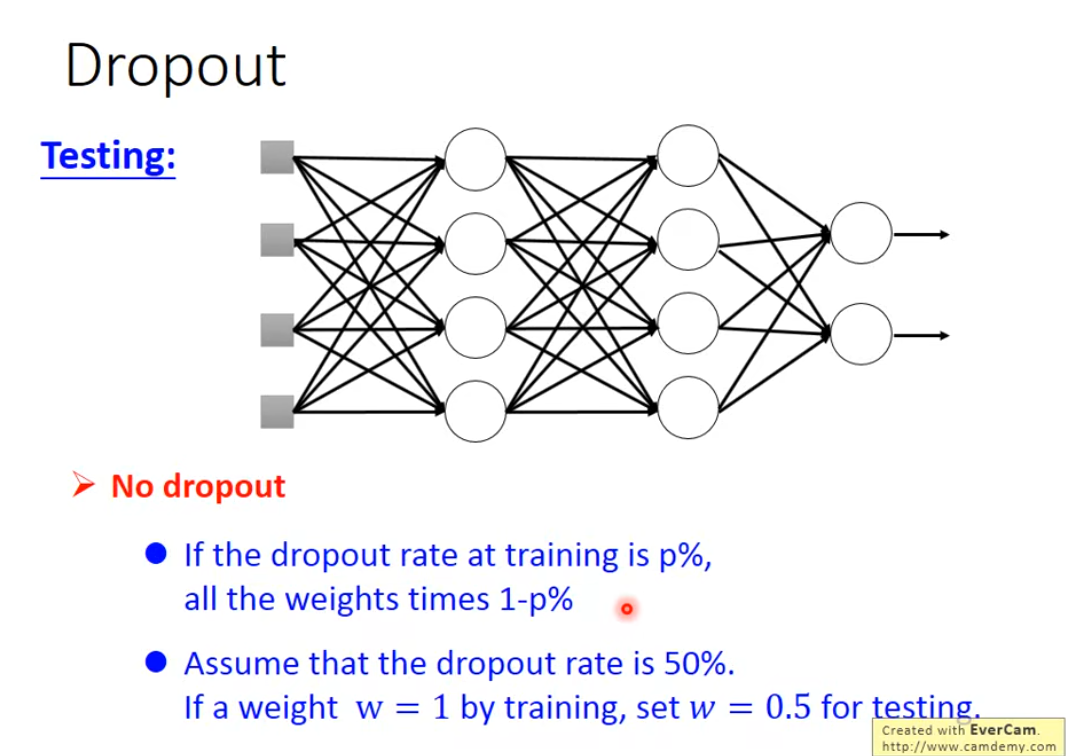
Dropout 的操作分为训练和预测(测试)两个阶段,这两个阶段的处理方式不同。
a) 训练阶段
每次前向传播和反向传播时,我们都会遍历网络的每一层。
对于每一层,我们以一个预先设定的概率 p(例如 0.5)随机地选择一部分神经元,将其"关闭"(将其激活值设置为0)。
被关闭的神经元在这次迭代中不参与前向传播,也不参与反向传播的权重更新。举个例子:
假设你有一个全连接层,有1000个神经元。
你设置 Dropout 概率 p=0.5p=0.5。
在每次训练迭代中,这1000个神经元中大约有500个会被随机选中并暂时从网络中移除。剩下的500个神经元用于完成本次迭代。
下一次迭代时,又会重新随机选择一批要丢弃的神经元。b) 预测/测试阶段
在模型训练完成,用于进行预测(推理)时,我们不再使用 Dropout。所有神经元都保持激活状态。
但是,这里有一个关键步骤:为了补偿训练时只有一部分神经元被激活,在测试时,该层的每一个神经元的输出都需要乘以一个缩放因子 (1−p)。
为什么? 假设训练时,由于Dropout,每个神经元平均只以 (1−p) 的概率被激活。为了让测试时整个网络的"总激活期望"与训练时保持一致,我们需要在测试时将每个神经元的输出乘以 (1−p)。
现代实现( inverted dropout):为了提升效率,现在的深度学习框架(如PyTorch, TensorFlow)通常采用一种叫 "反向Dropout" 的技巧。它在训练时就将保留下来的神经元的激活值除以 (1−p) 进行放大。这样,在测试时网络就可以原封不动地运行,无需做任何额外调整,因为期望值已经在训练时被校正了。- 为什么 Dropout 有效?------直观解释
Dropout 的强大之处在于它通过一种非常巧妙的方式提高了模型的泛化能力:
防止复杂的协同适应:
由于神经元会随机消失,一个神经元不能过分依赖于少数几个其他特定的神经元。它必须学会在"队友"随时可能缺席的情况下也能有效工作。
这迫使网络学习到更加鲁棒的特征,这些特征在随机子集的神经元组合下仍然有用,而不是依赖于某些固定的神经路径。
相当于训练多个子模型并集成:
每次随机丢弃神经元,都相当于创建了一个新的、更薄的网络架构。
一个具有 nn 个神经元的网络,使用 Dropout 后,在训练过程中可以看作是采样并训练了 2n2n 个不同的"子网络"的集合。
在测试时,我们实际上是在使用所有这些子网络的平均预测(通过缩放激活值来近似实现)。而模型集成是一种被证明非常有效的提升性能的方法。
引入噪声,增强鲁棒性:
Dropout 可以看作是为网络的激活值引入了噪声,这类似于一种数据增强的形式。模型为了克服这种噪声,必须学习更具代表性的特征。-
超参数与使用技巧
Dropout 率 pp:这是最重要的超参数,表示一个神经元被丢弃的概率。
输入层:pp 通常设置得较小(如 0.1 或 0.2),因为丢失太多输入信息可能有害。 隐藏层:pp 通常设置在 0.5 附近,这是一个常用的默认值,可以取得不错的效果。 输出层:通常不应用 Dropout。适用网络:Dropout 在全连接层上最常用,因为全连接层参数最多,最容易过拟合。在卷积层中,有时也会应用 Spatial Dropout,即随机丢弃整个特征图(通道),而不是单个像素。