中文摘要
本实验围绕基于卷积神经网络(CNN)的手写数字识别展开,通过 PyTorch 框架实现对 MNIST 数据集及自定义手写数字图片的识别,并分析模型性能。实验首先介绍了手写数字识别的应用背景与发展历程,该任务在降低人工成本、提升单据检测效率等场景中具有重要价值,而 CNN 自 1987 年首次提出后,逐渐成为处理图像识别任务的主流模型。
实验采用PyTorch与PyQt开发,构建了包含卷积层、最大池化层及全连接层的 CNN 模型。数据预处理阶段将图片转为 (10, 1, 28, 28) 维矩阵,其中 10 为分类数,1 为通道数,28×28 为图像尺寸。模型训练设置批次大小为 128,迭代 50 个 epoch,使用交叉熵损失函数与 SGD 优化器。实验结果显示,训练集准确率平均为 0.89885,测试集平均为 0.90715,对部分自定义手写数字(如 0、2、3 等)可正确识别,但对风格差异较大的输入(如数字 1、9)存在误判。
此外,实验通过 PyQt5 设计了可视化界面,支持模型训练、图片加载与实时预测。研究表明,CNN 在手写数字识别中表现出较好的泛化能力,但仍受输入图像风格、噪声等因素影响,未来可通过优化网络结构(如引入残差连接)或数据增强进一步提升性能。
关键词
卷积神经网络;手写数字识别;MNIST 数据集;PyTorch;图像分类。
正文
1、实验背景与内容
数字识别是人工智能领域很重要的一种经典任务,它考验的是计算机从纸质文档、照片或者其他来源接收、理解并识别可读数字的能力。数字的来源可能多种多样,比如手写数字、印刷体数字等。这种识别具有很大的实际应用价值。手写数字识别在许多领域都可以降低人工成本,可高效用于手写单据、邮编等的检测。
1965年至1970年,数字识别技术被应用在邮编识别等工作场景中。到了1985年,学者们提出了能够准确识别手写数字的算法,使用拓扑特征,结合语法分类器用于高精度识别手写数字。1989年,有学者使用反向传播算法训练的卷积神经网络优化了邮编识别手写数字的算法。1998年,几位学者列举了应用于手写字符识别的各种方法,并用标准手写数字识别基准任务对这些模型进行比较,结果都显示了卷积神经网络的优秀性。从那个时候开始,神经网络和他们提出的MNIST数据集成为手写数字识别的基本数据集。
2、开发工具,程序设计及实现目的及参数介绍
开发工具:pytorch pyqt
本次实验通过卷积神经网络来对手写的数字来进行识别,手写的数字是提前准备好的图片。
因为本网络使用pytorch 实现,部分参数隐藏于模型中,故这里只列出超参数。
|------------|---------------------------------------------|
| 参数或超参数 | 说明 |
| BATCH_SIZE | 超参数:批次大小 |
| EPOCH_SIZE | 超参数:epoch大小 |
| criterion | 超参数:交叉熵损失函数 |
| optimizer | 超参数:随机梯度下降(stochastic gradient descent,SGD) |
3、关键算法的理论介绍和程序实现步骤
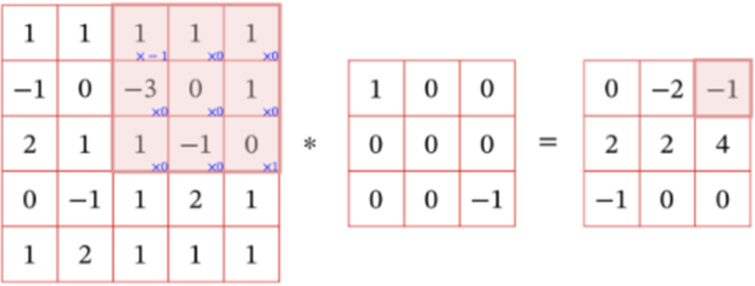
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。1987年,由Alexander Waibel等提出了时间延迟网络(Time Delay Neural Network, TDNN),这就是第一个卷积神经网络。TDNN是一个应用于语音识别问题的卷积神经网络,使用FFT预处理的语音信号作为输入,其隐含层由2个一维卷积核组成,以提取频率域上的平移不变特征。TDNN使用BP框架进行学习,超越了当时用于余美颜识别的主流算法。
首先进行数据预处理,从源文件获取数据,获取之后将图片转为(10, 1, 28, 28) 维矩阵,其中10等于输出的种类数,1表示图片通道数为1(因为图片为黑白图片),28表示图片的长和宽都是28pixels。
然后进行模型搭建与训练、测试。
4、实验运行屏幕截图,可多张图,分析运行结果,及存在问题
对该卷积神经网络训练十次,获得如下的精确度的图像:
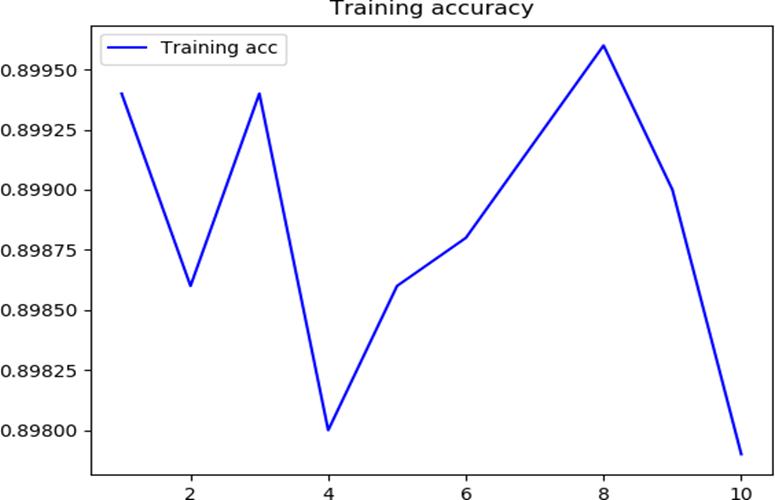
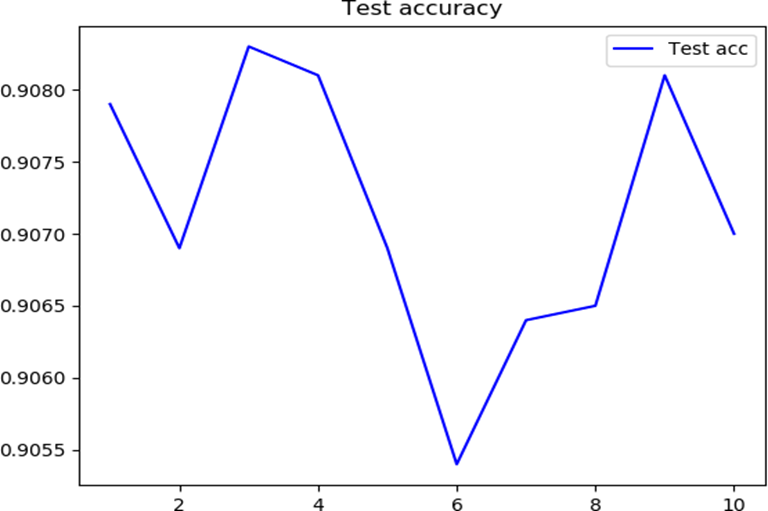
下面给出精确度的实验结果:
|-------------------|---------|---------|---------|----------------------|
| 指标 | 最优解 | 最差解 | 平均值 | 标准差 |
| Training accuracy | 0.8996 | 0.8979 | 0.89885 | 0.000583571380000371 |
| Test accuracy | 0.9083 | 0.9054 | 0.90715 | 0.000936008072139943 |
自定义手写输入结果:
|----------|----------------------------------------------------------------------------------------------------------------|----------|
| 实际输入 | 输入图片 | 预测结果 |
| 0 |  | 0 |
| 0 |
| 1 | 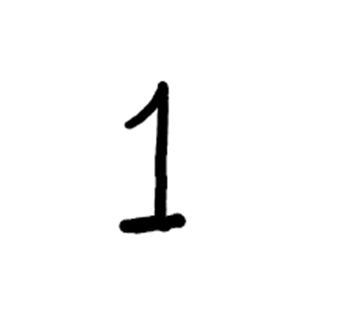 | 9 |
| 9 |
| 2 |  | 2 |
| 2 |
| 3 |  | 3 |
| 3 |
|----------|----------------------------------------------------------------------------------------------------------------|----------|
| 实际输入 | 输入图片 | 预测结果 |
| 4 |  | 4 |
| 4 |
| 5 |  | 5 |
| 5 |
| 6 |  | 6 |
| 6 |
| 7 |  | 7 |
| 7 |
|----------|----------------------------------------------------------------------------------------------------------------|----------|
| 实际输入 | 输入图片 | 预测结果 |
| 8 |  | 8 |
| 8 |
| 9 |  | 2 |
| 2 |
可以看到对1和9的识别并不准确,其余的正确。
5、实验体会及小结
实验中运用图像预处理技术,将手写数字图片灰度转换并归一化为 28×28 像素,通过二值化处理(像素≥100 设为 0)增强数字与背景对比度,这是图形学中像素操作与几何变换的基础应用。卷积层通过 3×3 核提取边缘特征,本质上是图形学 "局部感知" 思想的体现,每个神经元仅响应图像局部区域,符合视觉识别逻辑。
这次实验是我首次使用 PyTorch 搭建 CNN 模型,掌握了卷积层、最大池化层及全连接层的组合逻辑:卷积层提取边缘等局部特征,池化层降维减少参数,全连接层整合特征完成分类。训练中采用交叉熵损失函数与 SGD 优化器,通过 DataLoader 实现批量数据加载,理解了深度学习框架对计算图的自动化处理能力。此外,借助 PyQt5 开发可视化界面,实现模型训练、图片加载与实时预测的交互功能。
初期遇到自定义图片识别误差大的问题,发现是输入图像灰度分布不均导致,通过动态二值化和尺寸强制标准化解决;训练时学习率设置过高导致收敛波动,调整至 1e-4 并引入动量后稳定性提升;界面卡顿则通过独立线程分离训练与 UI 渲染解决。
CNN 对标准化手写数字(如 MNIST 数据集)识别效果稳定,但对风格差异大的输入(如手写 1、9)准确性不足。实验体会到图形学预处理是深度学习的重要前提,而模型调优需结合数据特性反复迭代。未来可通过数据增强和残差网络优化等,进一步提升模型识别的准确性。
附录(所有代码,包括代码注释)
import sys
import os
import struct
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
from PyQt5.QtGui import *
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as Data
torch.manual_seed(1)
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
class Net(nn.Module):
def init(self):
super(Net, self).init()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=2),
)
self.fc = nn.Sequential(
nn.Linear(16 * 14 * 14, 128),
nn.Linear(128, 10),
)
def forward(self, x):
out = self.conv(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
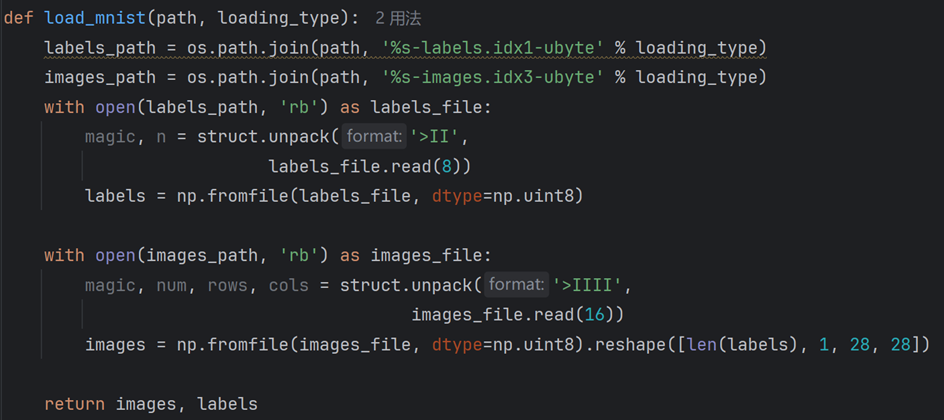
def load_mnist(path, loading_type):
labels_path = os.path.join(path, '%s-labels.idx1-ubyte' % loading_type)
images_path = os.path.join(path, '%s-images.idx3-ubyte' % loading_type)
with open(labels_path, 'rb') as labels_file:
magic, n = struct.unpack('>II',
labels_file.read(8))
labels = np.fromfile(labels_file, dtype=np.uint8)
with open(images_path, 'rb') as images_file:
magic, num, rows, cols = struct.unpack('>IIII',
images_file.read(16))
images = np.fromfile(images_file, dtype=np.uint8).reshape(len(labels), 1, 28, 28)
return images, labels
def load_model():
PATH = './model/CNN/cnn.pth'
model = Net()
model.load_state_dict(torch.load(PATH))
print(model)
return model
def readImage(path):
image = Image.open(path).convert('L')
width, height = image.size
pixel = image.load()
image.show()
for i in range(width):
for j in range(height):
if pixeli, j >= 100:
pixeli, j = 0
else:
pixeli, j = 255 - pixeli, j
image.show()
if width != 28 or height != 28:
image = image.resize((28, 28))
image_np = np.array(image)
image_np = image_np.reshape(1, 1, 28, 28)
return image_np
def test_image(image_path):
self_test = readImage(image_path)
print(self_test.shape)
self_test = torch.from_numpy(self_test)
model = load_model()
if torch.cuda.is_available():
device = torch.device("cuda")
self_test = self_test.to(device, dtype=torch.float32)
model = model.cuda()
outputs = model(self_test)
predicted = torch.argmax(outputs)
print(predicted.item())
return predicted.item()
class fileDialogdemo(QWidget):
def init(self,parent=None):
super(fileDialogdemo, self).init(parent)
#垂直布局
layout = QGridLayout()
self.setGeometry(600, 600, 400, 400)
self.input_epoch = QLineEdit("")
self.input_epoch.setPlaceholderText("请输入epoch大小")
layout.addWidget(self.input_epoch, 1, 0)
#创建按钮,绑定自定义的槽函数,添加到布局中
self.btn_train=QPushButton("训练模型(时间较长)")
self.btn_train.clicked.connect(self.train_image)
layout.addWidget(self.btn_train, 2, 0)
self.progress = QProgressBar(self)
self.progress.setMaximum(100)
self.progress.setValue(0)
layout.addWidget(self.progress, 3, 0)
self.train_loss = QLabel("训练集Loss: ")
layout.addWidget(self.train_loss, 4, 0)
self.train_pre = QLabel("训练集Precision: ")
layout.addWidget(self.train_pre, 5, 0)
self.test_loss = QLabel("测试集Loss: ")
layout.addWidget(self.test_loss, 6, 0)
self.test_pre = QLabel("测试集Precision:")
layout.addWidget(self.test_pre, 7, 0)
self.btn=QPushButton("加载图片")
self.btn.clicked.connect(self.getimage)
layout.addWidget(self.btn, 8, 0)
self.le=QLabel('')
layout.addWidget(self.le, 9, 0)
self.btn_test=QPushButton("开始预测")
self.btn_test.clicked.connect(self.begintest)
layout.addWidget(self.btn_test, 10, 0)
self.targetLabel = QLabel('目标结果: ')
layout.addWidget(self.targetLabel, 11, 0)
self.predictLabel = QLabel('模型预测结果: ')
layout.addWidget(self.predictLabel, 12, 0)
#设置主窗口的布局及标题
self.setLayout(layout)
self.setWindowTitle('模型训练与测试')
def getimage(self):
self.predictLabel.setText('模型预测结果: ')
#从当前路径打开文件格式(*.jpg *.gif *.png *.jpeg)文件,返回路径
self.image_file,_= QFileDialog.getOpenFileName(self,'Open file','../tc/','Image files (*.jpg *.gif *.png *.jpeg *.bmp)')
toprint = '目标结果: ' + os.path.basename(self.image_file)
toprint = toprint.split('.')0
self.targetLabel.setText(toprint)
#设置标签的图片
self.le.setPixmap(QPixmap(self.image_file))
def begintest(self):
self.predictLabel.setText('检测中,请稍后...')
print(len(self.image_file)) # str
preresult = test_image(self.image_file)
toprint_result = '模型预测结果: ' + str(preresult)
self.predictLabel.setText(toprint_result)
def train_image(self):
images, labels = load_mnist('./MNIST', 'train')
image_input_train = torch.from_numpy(images)
label_train = torch.from_numpy(labels)
model = Net()
print(model)
if torch.cuda.is_available():
model = model.cuda()
device = torch.device("cuda")
image_input_train = image_input_train.to(device, dtype=torch.float32)
label_train = label_train.to(device, dtype=torch.long)
BATCH_SIZE = 128 # 每个batch的大小
EPOCH_SIZE = 50
torch_dataset_train = Data.TensorDataset(image_input_train, label_train)
把 dataset 放入 DataLoader
loader_train = Data.DataLoader(
dataset=torch_dataset_train, # 数据,封装进Data.TensorDataset()类的数据
batch_size=BATCH_SIZE, # 每块的大小
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=0, # 多进程(multiprocess)来读数据,在windows下面,不要设置
)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
PATH = './model/CNN/cnn.pth'
for epoch in range(EPOCH_SIZE):
guest_train_count = 0
right_train_count = 0
running_loss = 0.0
for _, (batch_x, batch_y) in enumerate(loader_train, 0):
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
running_loss += loss.item()
for i in range(BATCH_SIZE):
if i > outputs.shape1:
break
one_output = outputsi
one_output = one_output.unsqueeze(0)
predicted = torch.argmax(one_output)
guest_train_count += 1
if (predicted.item() == batch_yi):
right_train_count += 1
print('epoch: %d loss: %.3f' % (epoch + 1, running_loss / BATCH_SIZE))
torch.save(model.state_dict(), PATH)
self.progress.setValue(epoch * 100 / EPOCH_SIZE)
self.progress.setValue(100)
fin1 = "训练集Loss: " + str(running_loss / BATCH_SIZE)
fin2 = "训练集Precision: " + str(right_train_count / guest_train_count)
self.train_loss.setText(fin1)
self.train_pre.setText(fin2)
images_test, labels_test = load_mnist('./MNIST', 't10k')
image_input_test = torch.from_numpy(images_test)
label_test = torch.from_numpy(labels_test)
if torch.cuda.is_available():
device = torch.device("cuda")
image_input_test = image_input_test.to(device, dtype=torch.float32)
label_test = label_test.to(device, dtype=torch.long)
BATCH_SIZE_test = 64 # 每个batch的大小
torch_dataset_test = Data.TensorDataset(image_input_test, label_test)
把 dataset 放入 DataLoader
loader_test = Data.DataLoader(
dataset=torch_dataset_test, # 数据,封装进Data.TensorDataset()类的数据
batch_size=BATCH_SIZE_test, # 每块的大小
shuffle=False, # 要不要打乱数据 (打乱比较好)
num_workers=0, # 多进程(multiprocess)来读数据,在windows下面,不要设置
)
running_loss = 0.0
right_num = 0
all_num = 0
self.progress.setValue(0)
for step, (batch_x, batch_y) in enumerate(loader_test, 0):
running_loss = 0.0
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
running_loss += loss.item()
for i in range(BATCH_SIZE_test):
if i > outputs.shape1:
break
one_output = outputsi
one_output = one_output.unsqueeze(0)
predicted = torch.argmax(one_output)
all_num += 1
if (predicted.item() == batch_yi):
right_num += 1
print出来一些数据
print('step: %d loss: %.3f predict: %.4f' % (step + 1, running_loss, right_num / all_num))
self.progress.setValue(step * 100 / (10000 / BATCH_SIZE_test))
self.progress.setValue(100)
fin3 = "测试集Loss: " + str(running_loss)
fin4 = "测试集Precision: " + str(right_num / all_num)
self.test_loss.setText(fin3)
self.test_pre.setText(fin4)
if name == 'main':
app=QApplication(sys.argv)
ex=fileDialogdemo()
ex.show()
sys.exit(app.exec_())