标题:VITRON: A Unified Pixel-level Vision LLM for Understanding, Generating, Segmenting, Editing
作者:Hao Fei、Shengqiong Wu、Hanwang Zhang、Tat-Seng Chua、Shuicheng Yan(其中 Shuicheng Yan 为通讯作者)
单位:1. Skywork AI, Singapore;2. National University of Singapore;3. Nanyang Technological University
发表:NeurIPS 2024
论文链接 :https://arxiv.org/pdf/2412.19806
项目链接 :https://vitron-llm.github.io/
代码链接 :https://github.com/SkyworkAI/Vitron
关键词:像素级视觉大语言模型(Pixel-level Vision LLM)、多模态通用模型(Multimodal Generalist)、视觉理解(Visual Understanding)、视觉生成(Visual Generating)、视觉分割(Visual Segmentation)、视觉编辑(Visual Editing)、跨任务协同(Cross-task Synergy)、混合指令传递(Hybrid Instruction Passing)
在多模态大语言模型(MLLM)领域,现有模型常面临图像与视频处理分离、任务覆盖不全面、细粒度理解不足等挑战。而 VITRON 的出现,以 "统一像素级视觉大语言模型" 为定位,实现了对图像与视频的理解、生成、分割、编辑四大核心任务集群的全覆盖,为统一多模态 AI 提供了新范式。
一、研究背景:多模态视觉大模型的现状与挑战
近年来,多模态大语言模型发展迅猛,在视觉理解领域涌现出如 BLIP2、LLaVA、MiniGPT-4 等知名模型,它们能较好地处理图像理解任务;在视频理解方向,VideoChat、Video-LLaMA 等模型也取得了一定进展。同时,部分研究进一步拓展 MLLM 能力,一方面朝着像素级细粒度理解方向发展,如 GLaMM、PixelLM 等模型实现了图像的区域定位,PG-Video-LLaVA 则聚焦视频像素级定位;另一方面,部分模型开始支持视觉生成任务,GILL、Emu 可生成图像,GPT4Video、NExT-GPT 能实现视频生成。
然而,当前视觉大语言模型仍存在三大关键挑战:
- 图像与视频处理分离:几乎所有现有模型仅支持图像或视频中的一种模态,无法将二者统一在同一框架下。但视觉世界本就包含静态图像与动态视频,二者在多数场景中可互换,统一处理对实际应用至关重要。
- 任务覆盖不全面:多数模型仅支持视觉理解,少数支持生成任务,而编辑、分割等核心视觉任务仍缺乏统一支持。在实际视觉创作中,用户常需完成 "文本生成图像 - 图像编辑 - 图像生成视频 - 视频编辑" 等一系列迭代操作,现有模型难以满足此类全流程需求。
- 跨任务协同与指令传递难题:即使集成多种视觉任务模块,如何确保 LLM 能精准将指令传递给下游解码器,以及如何避免不同任务间的性能干扰、实现协同优化,仍是未解决的关键问题。
为应对上述挑战,VITRON 应运而生,旨在构建一个能同时处理图像与视频、覆盖全视觉任务、具备跨任务协同能力的像素级统一视觉大语言模型。
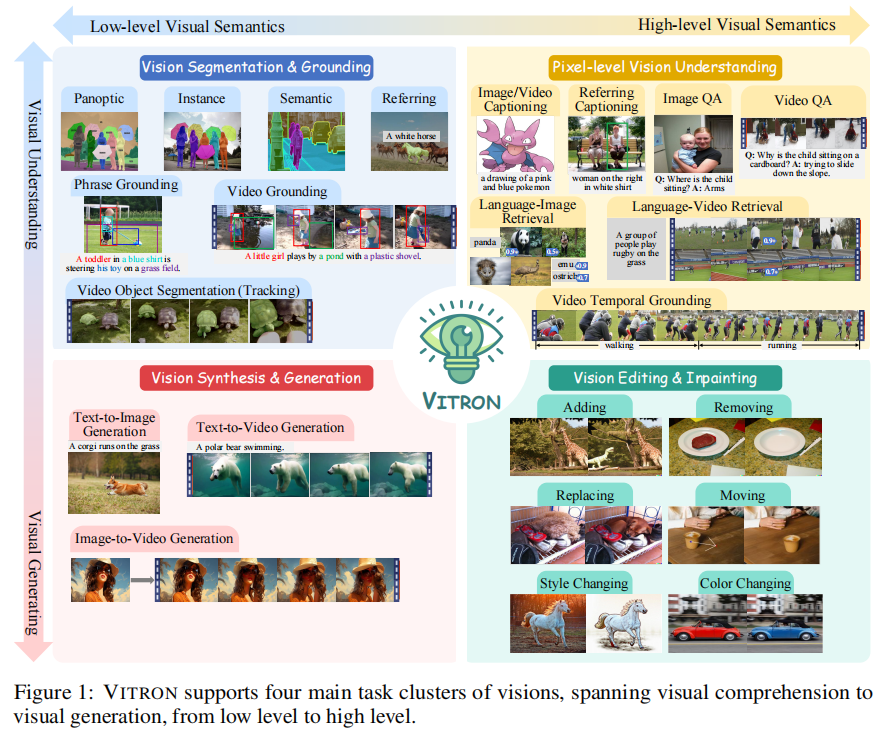
二、核心创新:四大突破性设计
VITRON 的核心竞争力源于四大创新性设计,从模态统一、任务覆盖、指令传递、跨任务协同四个维度,全面突破现有模型的局限:
1. 首次实现图像与视频的像素级统一处理
VITRON 摒弃了传统模型将图像与视频分离处理的思路,在前端编码器层便实现了二者的统一兼容。通过采用 CLIP ViT-L/14@336px 作为基础编码器,对视频帧进行独立处理后再通过时间维度平均池化获取时序特征,使图像与视频信号能映射到同一特征空间,为后续统一任务处理奠定基础。同时,针对用户交互场景,引入区域像素感知提取器(如草图编码器),支持用户通过点击、画框、涂鸦等方式指定区域,进一步强化了像素级交互能力。
2. 全栈视觉任务覆盖:从理解到生成、从分割到编辑
VITRON 创新性地整合了当前主流的视觉任务模块,形成覆盖 "视觉理解 - 生成 - 分割 - 编辑" 的全栈能力。具体任务集群及对应后端模块如下表所示:
| 任务集群 | 具体任务 | 后端模块 |
|---|---|---|
| 视觉理解 | 图像 QA、视频 QA、区域描述、语言 - 视觉检索 | LLM + 视觉编码器特征对齐 |
| 视觉生成 | 文本到图像生成、文本到视频生成、图像到视频生成 | GLIGEN(图像生成 / 编辑)、ZeroScope(文本到视频)、I2VGen-XL(图像到视频) |
| 视觉分割 | 图像实例分割、视频目标分割(跟踪)、区域定位 | SEEM(图像 / 视频分割) |
| 视觉编辑 | 图像修复、视频风格修改、目标添加 / 移除 / 替换 | GLIGEN(图像编辑)、StableVideo(视频编辑) |
这种全栈任务覆盖能力,使 VITRON 能满足用户从创意构思到最终输出的全流程视觉创作需求,例如 "文本生成初始图像 - 通过编辑添加细节 - 将图像转换为视频 - 视频风格优化" 的完整链路。
3. 混合指令传递机制:离散文本与连续特征的协同
为解决 LLM 到下游模块的精准指令传递问题,VITRON 提出混合指令传递方法,同时融合离散文本指令与连续信号嵌入的优势:
- 离散文本指令:LLM 生成结构化文本,包含 "模块名称 - 调用命令 - 区域信息(可选)" 三部分,确保下游模块能明确任务类型与执行目标。例如视频跟踪任务中,文本指令会指定 "Video Segmentation 模块 - 跟踪时钟目标 - 区域坐标 (0.23, 0.35, 0.11, 0.26)"。
- 连续信号嵌入:LLM 输出特殊令牌的特征嵌入,分为任务特定特征与任务不变细粒度特征。其中,任务不变特征可在不同任务间共享,任务特定特征则针对具体任务优化,二者拼接后输入下游模块,补充文本无法传递的模态特异性信息。
这种混合机制既解决了纯文本指令缺乏模态特征的问题,又避免了纯连续特征无法明确任务意图的缺陷,显著提升了复杂任务的执行精度。
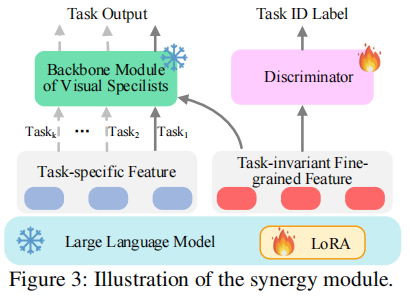
4. 跨任务协同模块:基于对抗训练的特征解耦
为最大化不同任务间的协同效应,VITRON 设计了跨任务协同模块,通过对抗训练实现任务特定特征与任务不变细粒度特征的解耦:
- 特征分解:将 LLM 输出的特征嵌入分解为任务特定特征(仅服务于单个任务)和任务不变细粒度特征(可在所有任务间共享)。
- 对抗训练:引入第三方任务判别器,其目标是仅通过任务不变特征判断当前任务类型。LLM 则通过优化使判别器无法准确识别任务,从而促使任务不变特征提纯为通用、可共享的细粒度视觉特征。
通过这一机制,不同任务可共享高质量的通用特征,避免任务间的负迁移,同时保留各任务的特异性优化空间,实现 "1+1>2" 的跨任务协同效果。
文中通过多维度对比当前主流视觉多模态大语言模型(Vision MLLM)的能力,清晰凸显了 VITRON 的核心优势(表1)。
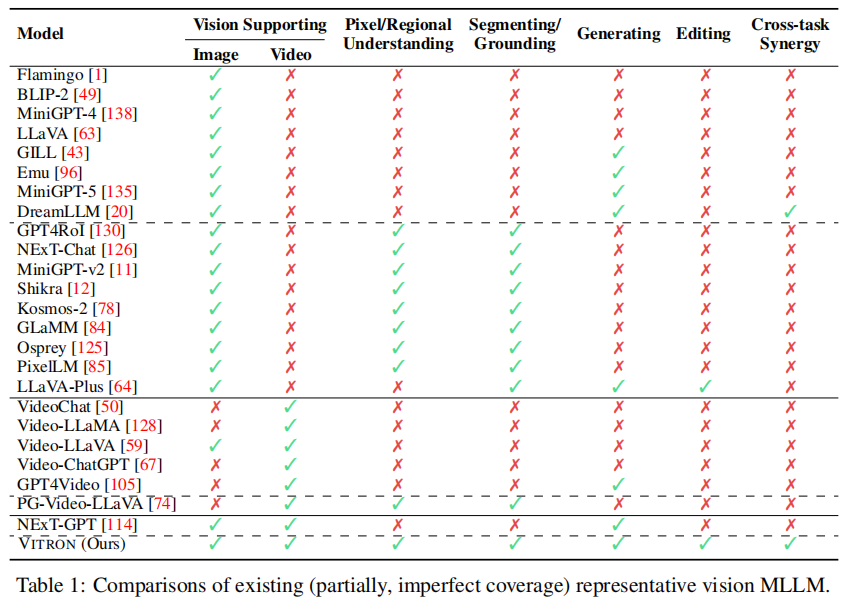
从表 1 数据可观察到:
- 模态支持局限:多数现有模型仅支持单一视觉模态,如 Flamingo、BLIP-2、MiniGPT-4、LLaVA 等仅支持图像(Image:✓,Video:✗),VideoChat、Video-LLaMA、Video-ChatGPT 等仅支持视频(Image:✗,Video:✓);即使少数模型(如 Video-LLaVA、NExT-GPT)同时支持图像与视频,也缺乏其他关键能力。
- 任务覆盖不全面:仅能支持部分视觉任务,例如 GILL、Emu、DreamLLM 等仅新增图像生成能力(Generating:✓),但无分割、编辑能力;GPT4RoI、NExT-Chat、MiniGPT-v2 等仅具备像素 / 区域理解与分割 / 定位能力(Pixel/Regional Understanding:✓,Segmenting/Grounding:✓),无法支持生成与编辑;LLaVA-Plus 虽支持分割、生成、编辑,但缺乏像素 / 区域理解与跨任务协同能力。
- VITRON 的唯一性:在所有对比模型中,仅有 VITRON 在 7 项维度上均实现支持(全部标注 "✓"),既同时兼容图像与视频模态,又覆盖从像素级理解到分割、生成、编辑的全流程任务,还具备跨任务协同能力,直观证明了其 "统一像素级视觉大语言模型" 的定位,填补了现有模型在多模态统一、全任务覆盖上的空白。
三、架构设计:Encoder-LLM-Decoder 的统一框架
VITRON 采用经典的 "前端编码器 - 核心 LLM - 后端解码器" 架构,但在各模块设计上进行了深度优化,确保全模态、全任务能力的高效集成。其整体架构如图 2 所示:
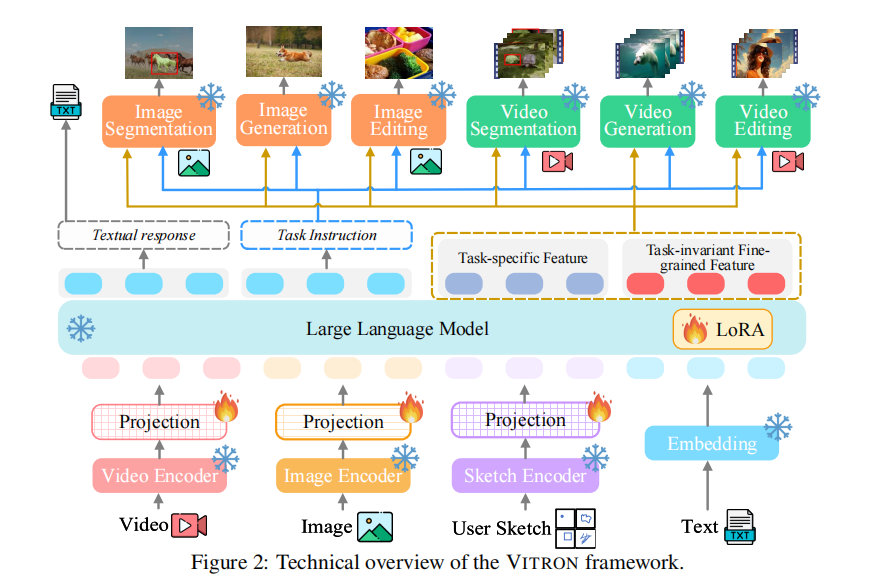
1. 前端视觉 - 语言编码器
前端模块负责将多模态输入(图像、视频、草图、文本)转换为 LLM 可理解的特征,具体包含:
- 图像编码器:基于 CLIP ViT-L/14@336px,将图像转换为视觉特征,并通过线性投影映射到 LLM 的特征空间。
- 视频编码器:同样基于 CLIP ViT-L/14@336px,对视频的每一帧独立编码后,通过时间维度平均池化得到视频的时序特征,实现与图像特征的维度统一。
- 草图编码器:参考 Osprey 的设计,基于用户输入的区域掩码(如框选、涂鸦区域),提取区域的像素级特征与空间位置信息,支持细粒度交互。
- 文本编码器:复用 LLM 的文本编码层,将用户指令、问题等文本信息转换为文本特征。
所有模态的特征通过线性投影后拼接,输入核心 LLM 进行统一处理。
2. 核心 LLM:语义理解与任务决策中枢
VITRON 选用 Vicuna-7B-v1.5 作为基础 LLM,承担语义理解、推理、决策与多轮交互的核心角色,其核心功能包括:
- 视觉理解任务处理:直接输出文本响应,例如回答图像 QA 问题 "孩子为什么坐在纸板上?" 时,LLM 基于视觉特征推理输出 "为了滑下斜坡"。
- 任务决策与指令生成:根据用户输入(如 "生成一只在草地上奔跑的柯基犬图像"),判断任务类型(文本到图像生成),生成结构化文本指令与连续特征嵌入,传递给下游解码器。
- 多轮上下文记忆:支持多轮交互,例如用户先要求 "生成柯基图像",后续要求 "将图像转换为视频并添加雪花特效",LLM 能记忆历史上下文,确保任务连贯性。
为适配视觉信号处理,VITRON 通过 LoRA(低秩适应)对 LLM 进行高效微调,仅更新少量参数即可实现视觉 - 语言特征的对齐,避免全量微调的高计算成本。
3. 后端视觉专家模块:任务执行与输出生成
后端模块由一系列当前最优(SoTA)的视觉任务专家组成,根据 LLM 传递的指令与特征,执行具体任务并生成非文本输出。各专家模块的功能、输入输出如下表所示(表 13):
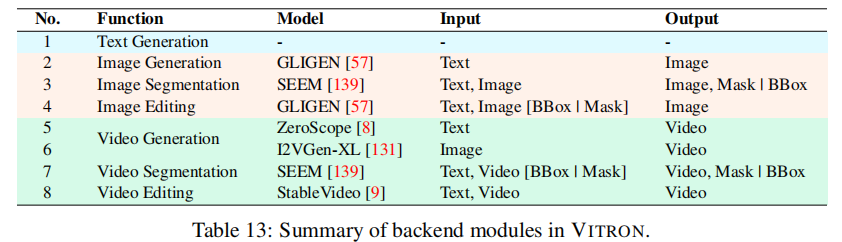
后端模块与 LLM 通过 "文本指令 + 特征嵌入" 双通道通信,确保任务执行的准确性与高效性。例如,图像编辑任务中,LLM 先通过文本指令指定 "GLIGEN 模块 - 移除图像中的花朵 - 区域坐标 (0.4, 0.3, 0.6, 0.5)",再传递连续特征嵌入,辅助 GLIGEN 精准定位并移除目标区域。
四、训练策略:三阶段渐进式优化
VITRON 的训练采用三阶段渐进式策略,从基础能力到细粒度优化,再到跨任务协同,逐步提升模型性能,具体流程如下:
1. 阶段一:基础多模态理解与生成能力训练
此阶段目标是让模型掌握基础的视觉 - 语言对齐与任务调用能力,包含三个子步骤:
- 步骤 1.1:视觉 - 语言对齐学习:使用 "图像 - 字幕"(CC3M)、"视频 - 字幕"(Webvid)、"区域 - 字幕"(RefCOCO)数据集,训练前端编码器与 LLM 的特征对齐,使 LLM 能基于视觉特征生成符合参考的文本描述。例如输入图像后,LLM 生成与参考字幕一致的图像描述。
- 步骤 1.2:文本调用指令微调:构建 5.5 万 + 指令微调样本,覆盖所有后端任务的调用场景(如 "文本生成图像""视频跟踪目标""图像修复" 等),训练 LLM 生成结构化文本指令。样本构建采用 "模板 + GPT-4 扩展" 方式,确保覆盖不同用户交互场景(如文本指令、草图交互)。
- 步骤 1.3:LLM - 解码器特征对齐:参考 NExT-GPT 的方法,训练 LLM 输出的连续特征嵌入与后端模块输入编码器的特征对齐。通过最小化 LLM 特征与后端模块(如 GLIGEN 的文本条件编码器、SEEM 的视觉编码器)特征的 L2 距离,实现特征层面的精准匹配。
2. 阶段二:细粒度时空视觉定位指令微调
此阶段聚焦提升模型的像素级细粒度理解能力,通过三类任务的指令微调,强化 LLM 对图像空间信息与视频时空信息的感知:
- 图像空间定位:包含 "接地图像描述" 与 "指代图像分割" 任务。前者要求 LLM 生成图像描述时,为每个物体标注边界框(如 "女孩:(0.1, 0.2, 0.3, 0.5),粉色裙子:(0.12, 0.25, 0.28, 0.48)");后者要求 LLM 根据文本查询(如 "穿黑色衬衫的男人")输出目标物体的边界框。训练数据集采用 RefCOCO、RefCOCO+、RefCOCOg 等指代分割数据集。
- 视频时空定位:包含 "接地视频描述" 与 "指代视频跟踪" 任务。与图像任务类似,但需额外标注目标在视频中的时间范围(如 "狗:(0.1, 0.2, 0.3, 0.5 | F1-F30)",表示第 1 到 30 帧的狗的位置)。训练数据集采用 LaSOT、GOT10K 等视频跟踪数据集。
- 定位感知视觉 QA:基于上述定位任务的结果,训练 LLM 进行高层语义推理。例如图像 QA 问题 "孩子坐在哪里?",LLM 需先定位 "孩子" 的边界框,再结合视觉特征推理输出 "手臂上";视频 QA 问题 "如果视频中的绳子断裂,人会怎样?",LLM 需定位 "绳子" 与 "人" 的时空位置,结合常识推理输出 "骨折"。训练数据集采用 OKVQA、GQA(图像 QA)与 ActivityNet-QA、MSRVTT-QA(视频 QA)。
此阶段通过 LoRA 微调 LLM 的少量参数,在不破坏基础能力的前提下,显著提升像素级理解精度。
3. 阶段三:跨任务协同学习
此阶段通过对抗训练实现任务特定特征与任务不变特征的解耦,最大化跨任务协同效应,具体流程如下:
- 特征分解 :将 LLM 输出的特征嵌入拆分为任务特定特征(
)与任务不变细粒度特征(
- 对抗训练 :引入 4 层 768 维 Transformer 结构的任务判别器(D),其目标是仅通过任务不变特征(
- 联合优化 :将对抗训练损失(
通过此阶段训练,不同任务可共享高质量的通用视觉特征,例如图像分割任务学到的边缘检测特征可辅助视频编辑任务中的目标边界优化,显著提升跨任务性能。
五、实验验证:12 项任务、22 个数据集的全面评估
VITRON 在 12 项视觉核心任务、22 个数据集上进行了全面实验,对比当前 SoTA 模型,验证了其在统一框架下的卓越性能。实验基于 10×A100(80G)GPU 完成,所有对比均采用与基线模型相同或相似的实验设置,确保公平性。
1. 视觉分割任务:像素级定位精度领先
视觉分割任务包含 "指代图像分割""视频空间定位""视频目标分割(跟踪)" 三类子任务,实验结果如下:
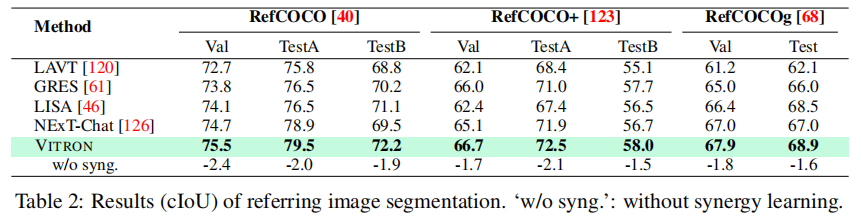
(1)指代图像分割(RefCOCO/RefCOCO+/RefCOCOg 数据集)
如表 2 所示,VITRON 在 RefCOCO 的 TestB、RefCOCO + 的全部分集、RefCOCOg 的全部分集上均超越 NExT-Chat 等基线模型,尤其在 RefCOCOg 的 Test 集上,cIoU 达到 68.9%,较 NExT-Chat 提升 1.9%。当移除协同模块(w/o syng.)后,性能平均下降 1.5-2.4%,验证了跨任务协同的有效性。
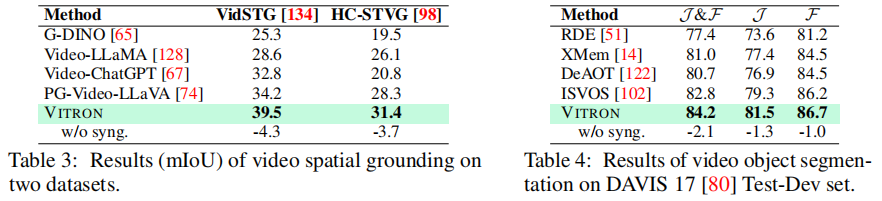
(2)视频空间定位(VidSTG/HC-STVG 数据集)
如表 3 所示,VITRON 在 VidSTG 数据集上的 mIoU 达到 39.5%,较当前最优的 PG-Video-LLaVA(34.2%)提升 5.3%;在 HC-STVG 数据集上达到 31.4%,较 PG-Video-LLaVA(28.3%)提升 3.1%。这表明 VITRON 的视频时空定位能力显著优于专用视频 LLM。
(3)视频目标分割(DAVIS 17 Test-Dev 数据集)
如表 4 所示,VITRON 的 J&F 值达到 84.2%,超越 ISVOS(82.8%)、XMem(81.0%)等专用视频分割模型。其中,J 值(81.5%)与 F 值(86.7%)分别较 ISVOS 提升 2.2% 与 0.5%,证明其在视频目标跟踪的连续性与准确性上的优势。
2. 细粒度视觉理解:语义推理能力突出
细粒度视觉理解任务聚焦区域级与语义级理解,包含 "图像区域描述""图像 QA""视频 QA" 三类子任务:
(1)图像区域描述(RefCOCOg 数据集)
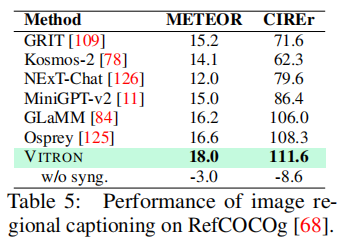
如表 5 所示,VITRON 在 METEOR(18.0)与 CIREr(111.6)指标上均超越 Osprey(METEOR 16.6、CIREr 108.3)、GLaMM(METEOR 16.2、CIREr 106.0)等模型,尤其 CIREr 指标提升 3.3,表明其能更精准地生成与区域匹配的细粒度描述。
(2)图像 QA(OKVQA/GQA/VSR 等 6 个数据集)
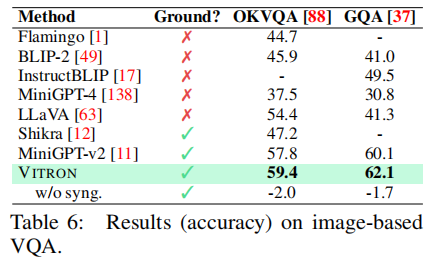
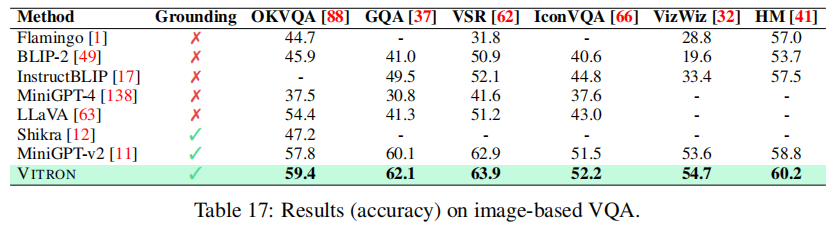
如表 6、表 17 所示,VITRON 在 OKVQA 数据集上准确率达到 59.4%,较 MiniGPT-v2(57.8%)提升 1.6%;在 GQA 数据集上达到 62.1%,较 MiniGPT-v2(60.1%)提升 2.0%。同时,对比无像素定位能力的模型(如 LLaVA、BLIP2),VITRON 的性能优势显著,证明细粒度定位对高层语义推理的促进作用。
(3)视频 QA(ActivityNet-QA/MSRVTT-QA 等 4 个数据集)

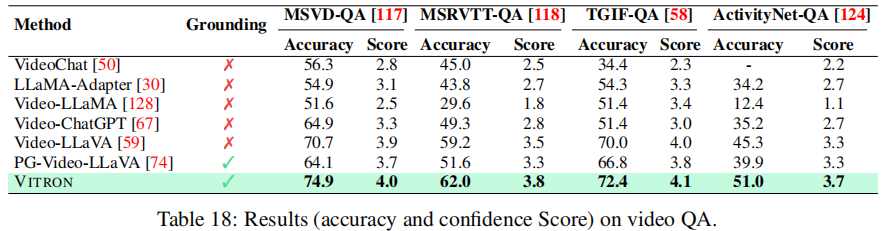
如表 7、表 18 所示,VITRON 在 ActivityNet-QA 数据集上准确率达到 51.0%,较 Video-LLaVA(45.3%)提升 5.7%,较具备定位能力的 PG-Video-LLaVA(39.9%)提升 11.1%;在 MSRVTT-QA 数据集上准确率达到 62.0%,较 Video-LLaVA(59.2%)提升 2.8%。这表明 VITRON 的视频时空定位能力能有效辅助语义理解,避免了 PG-Video-LLaVA 定位能力与 QA 性能脱节的问题。
3. 视觉生成任务:生成质量与多样性优异
视觉生成任务包含 "文本到图像""文本到视频""图像到视频" 三类子任务,采用 FID(越低越好)、CLIPSIM(越高越好)、FVD(越低越好)等指标评估:
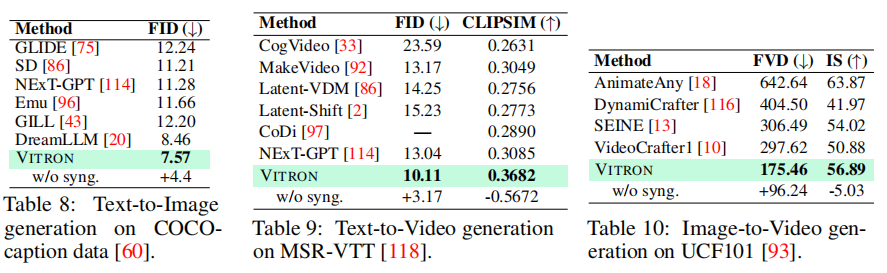
(1)文本到图像生成(COCOcaption 数据集)
如表 8 所示,VITRON 的 FID 达到 7.57,低于 DreamLLM(8.46)、NExT-GPT(11.28)等模型,甚至优于专用扩散模型 SD(11.21)。移除协同模块后,FID 上升 4.4,证明跨任务协同能提升生成质量。
(2)文本到视频生成(MSR-VTT 数据集)
如表 9 所示,VITRON 的 FID(10.11)低于 NExT-GPT(13.04)、MakeVideo(13.17),CLIPSIM(0.3682)显著高于 NExT-GPT(0.3085),表明其生成的视频不仅保真度高,且与文本指令的语义匹配度更强。
(3)图像到视频生成(UCF101 数据集)
如表 10 所示,VITRON 的 FVD(175.46)远低于 VideoCrafter1(297.62)、DynamiCrafter(404.50),IS(56.89)高于 VideoCrafter1(50.88),证明其能从静态图像中有效学习动态特征,生成连贯、高质量的视频。
4. 视觉编辑任务:精准编辑与内容保真兼顾
视觉编辑任务包含 "图像编辑"(MagicBrush 数据集)与 "视频编辑"(人工评估)两类:
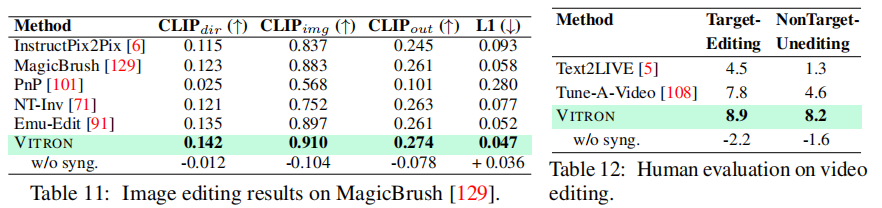
(1)图像编辑(MagicBrush 数据集)
如表 11 所示,VITRON 在 CLIP dir(0.142)、CLIP img(0.910)、CLIP out(0.274)指标上均超越 Emu-Edit、MagicBrush 等专用编辑模型,L1 损失(0.047)最低,表明其编辑结果不仅与指令语义匹配,且视觉质量高、与原图风格一致性强。
(2)视频编辑(人工评估)
如表 12 所示,VITRON 在 "目标编辑成功率"(8.9)与 "非目标内容保真度"(8.2)上均超越 Text2LIVE(4.5/1.3)、Tune-A-Video(7.8/4.6)。例如,在 "将视频背景替换为雪地森林并将棕熊改为北极熊" 的任务中,VITRON 能精准修改目标内容,同时保持非目标区域(如熊的动作)的连贯性。
5. 消融实验:核心设计的有效性验证
为验证各核心设计的必要性,VITRON 进行了三项关键消融实验:
(1)混合指令传递机制的有效性
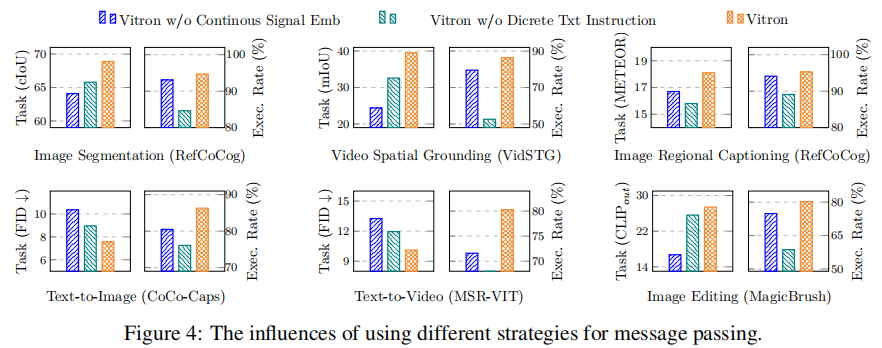
对比 "仅离散文本指令""仅连续信号嵌入""混合机制" 三种方案,在 6 项任务上的性能如图 4 所示。结果显示,混合机制在任务性能(如图像区域描述的 METEOR、视频空间定位的 mIoU)与模块执行成功率上均最优。其中,文本指令主要提升执行成功率(确保模块调用正确),连续特征主要提升任务性能(提供细粒度模态信息),二者协同实现 "调用准确 + 执行精准"。
(2)细粒度定位微调的贡献
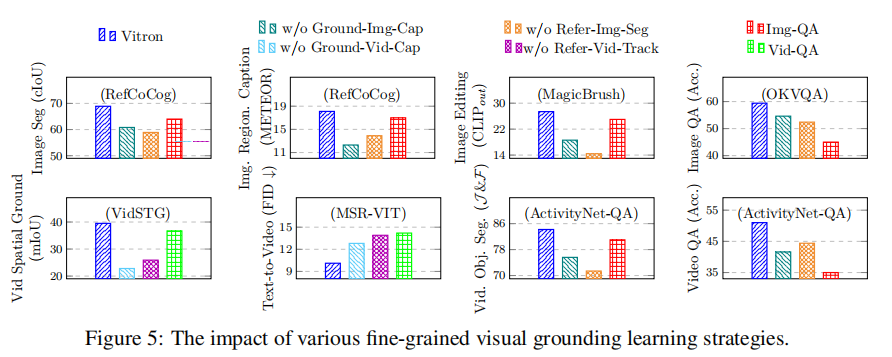
移除 "接地图像描述""指代图像分割""接地视频描述""指代视频跟踪" 四类定位微调任务后,各下游任务的性能下降如图 5 所示。结果表明,所有定位微调任务对下游性能均有正向贡献,其中 "指代图像分割" 对图像分割任务的影响最大(cIoU 下降 2.2),"接地视频描述" 对视频 QA 任务的影响最大(准确率下降 4.4),验证了细粒度定位是高层语义理解的基础。
(3)跨任务协同的效果
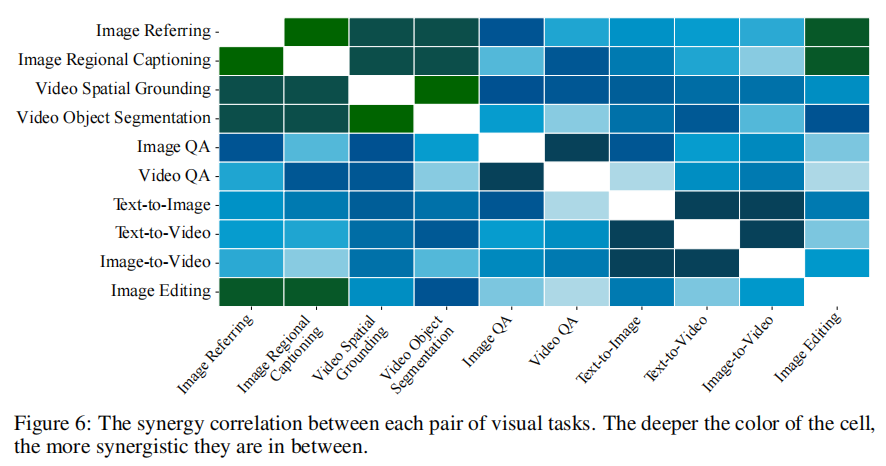
在所有任务中移除协同模块后,性能平均下降 1.0-4.4%(如表 2-12 的 w/o syng. 列)。同时,任务间协同热力图(图 6)显示,依赖细粒度特征的任务(如图像分割、视频跟踪、图像编辑)间的协同效应更强,例如图像分割与图像编辑的协同系数最高,证明任务不变特征能在同类细粒度任务中高效共享。
六、结论与展望
VITRON 通过 "统一模态处理、全栈任务覆盖、混合指令传递、跨任务协同" 四大核心创新,构建了首个能同时处理图像与视频的像素级统一视觉大语言模型。在 12 项任务、22 个数据集上的实验表明,VITRON 不仅在各单项任务上达到或超越当前 SoTA,还能支持全流程视觉创作,为多模态通用人工智能的发展提供了重要方向。
1. 主要贡献总结
- 统一框架创新:首次实现图像与视频的像素级统一处理,打破传统模型的模态壁垒。
- 全任务覆盖:整合理解、生成、分割、编辑四大任务集群,满足实际应用中的全流程需求。
- 指令传递优化:提出混合指令传递机制,解决 LLM 到下游模块的精准通信问题。
- 跨任务协同:通过对抗训练实现特征解耦,最大化任务间的协同效应。
2. 未来研究方向
尽管 VITRON 取得了显著突破,仍存在以下可优化方向:
- 模型效率提升:当前 VITRON 依赖多个后端专家模块,推理速度较慢,未来可探索模型压缩(如蒸馏、量化)或端到端统一建模,提升部署效率。
- 更高分辨率支持:当前图像 / 视频分辨率限于 336px,未来可引入超分辨率模块,支持高清视觉处理。
- 多模态扩展:当前仅支持视觉 - 语言模态,未来可整合音频、3D 等模态,实现更全面的多模态理解与生成。
- 安全与伦理考量:生成与编辑能力可能被用于制作虚假内容,未来需引入内容水印、指令过滤等安全机制,确保模型的负责任使用。
VITRON 的出现,标志着视觉大语言模型从 "单任务专用" 向 "多模态通用" 的重要跨越,为后续统一多模态 AI 系统的研发提供了宝贵的技术范式与实验依据。