刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。
在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。
该公司 CEO Mira Murati 表示,这种方法可用于小模型,使其具备强大的领域性能和持续学习能力。
值得注意的是,在这篇新博客中,TML 明确表示这项新成果受到了 Qwen 团队研究的启发,并且其实验过程中也大量用到了 Qwen3 系列模型。事实上,在原英文博客中,「Qwen」这个关键词一共出现了 38 次之多!比小米 17 系列发布会雷总提到「苹果」的 37 次还多一次。

作为一家明星创业公司,TML 的更新也吸引了广泛关注。有人总结其优势:

更是有网友盛赞,TML 才是真 Open AI。

博客地址:thinkingmachines.ai/blog/on-pol...
这篇博客的主要作者是 Thinking Machines Lab 研究者 Kevin Lu。他之前曾在 OpenAI 工作,领导了 4o-mini 的发布,并参与过 GPT-5 series、GPT-oss、o3 & o4-mini、4.1-nano & 4.1-mini、o1-mini、o3-mini 等模型的研发工作。
下面我们就来详细看看这篇博客的内容。
大型语言模型(LLM)能够在特定领域展现出专家级的水平。这是几种能力共同作用的结果,包括:对输入的感知、知识检索、规划选择和可靠执行。
要实现这一点,需要一系列的训练方法。我们可以将其大致分为三个阶段:
-
预训练(Pre-training):教授通用能力,例如语言使用、宽泛的推理和世界知识。
-
中训练(Mid-training):传授领域知识,例如代码、医疗数据库或公司内部文件。
-
后训练(Post-training):引导出目标行为,例如遵循指令、解决数学问题或聊天。
在特定专业领域,经过强化训练的小型模型,其表现往往优于那些大型的通用模型。使用小型模型有很多好处:
-
出于隐私或安全考虑,它们可以进行本地部署。
-
它们可以更轻松地持续训练和更新。
-
它们还能节省推理成本。
想要利用这些优势,就需要为训练的后续阶段选择正确的方法。
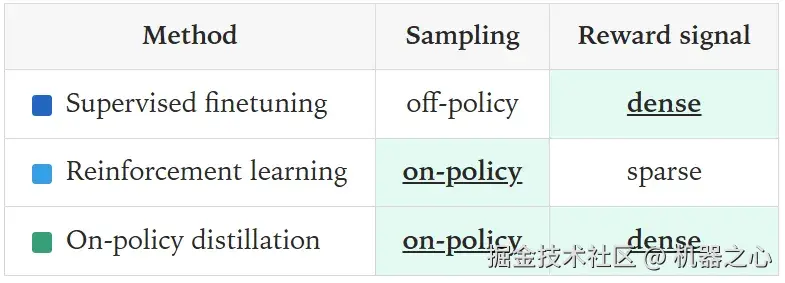
后训练「学生」模型的方法可以分为两种:
-
在策略(On-policy)训练:从学生模型自身采样轨迹(rollouts),并为这些轨迹分配某种奖励。
-
离策略(Off-policy)训练:依赖于某个外部来源的目标输出,学生模型需要学习模仿这些输出。
例如,我们可能希望训练一个紧凑模型来解决如下的数学问题:

我们可以通过强化学习(RL)来进行在策略训练。具体做法是根据学生模型的每个轨迹是否解决了问题来为其评分。这个评分可以由人工完成,也可以由一个能可靠给出正确答案的「教师」模型来完成。

在策略训练的优势在于,学生通过在自己的样本上训练,能更直接地学会避免错误。
但 RL 有一个主要缺点:它提供的反馈非常稀疏(sparse feedback)。无论使用多少 token,它在每个训练回合(episode)中教授的比特数是固定的。
在我们上面的例子中,学生只知道「21」是错误答案,并更新模型以避免产生这个轨迹。但它并没有学到究竟错在哪里 ------ 是搞错了运算顺序,还是算术本身出了错。这种反馈的稀疏性使得 RL 在许多应用中效率低下。
离策略训练通常通过监督微调(SFT)来完成,即在一组精心策划的、针对特定任务的有标注示例上进行训练。这些有标注示例的来源可以是一个在当前任务上表现出色的教师模型。
我们可以使用一种称为蒸馏(distillation)的机制:训练学生模型来匹配教师模型的输出分布。我们在教师的轨迹上进行训练,这些轨迹是生成的 token 的完整序列,包括中间的思考步骤。
在每一步,我们既可以使用教师完整的「下一个 token 分布」(常被称为 「logit 蒸馏」),也可以只采样给定的序列。实践证明,采样序列提供了对教师分布的无偏估计,并能达到相同的目标。学生模型会根据自己生成该 token 的概率有多低,来相应地更新对序列中每个 token 的学习(在下例中用深色表示):

事实证明,蒸馏大型教师模型,在训练小型模型方面非常有效,使其能够:
-
遵循指令
-
进行数学和科学推理
-
从医疗笔记中提取临床信息
-
以及参与多轮聊天对话
用于这些应用和其他应用的蒸馏数据集通常是开源和公开发布的。
离策略训练的缺点是,学生是在教师经常遇到的上下文中学习,而不是在学生自己将来会经常遇到的上下文中学习。
这可能会导致复合错误(compounding error):如果学生早期犯了一个教师从未犯过的错误,它会发现自己越来越偏离在训练中观察到的状态。
当我们关心学生在长序列上的表现时,这个问题变得尤为突出。为了避免这种偏离,学生必须学会从自己的错误中恢复。
离策略蒸馏观察到的另一个问题是,学生可以学会模仿教师的风格和自信,但不一定能学会其事实的准确性。
打个比方:如果你在学习国际象棋,在策略 RL 就好比在没有教练指导的情况下自己下棋。赢棋或输棋的反馈与你自己的下法直接相关,但每局只收到一次反馈,而且不会告诉你哪些棋步对结果贡献最大。离策略蒸馏则类似于观看一位特级大师下棋 ------ 你观察到的是非常高超的棋步,但这些棋步是在新手玩家很少会遇到的棋局状态下走出的。
我们希望能将 RL 的在策略相关性与蒸馏的密集奖励信号结合起来。
对于学习国际象棋来说,这就好比有一位老师来为你自己的每一步棋打分,从「大错特错」到「妙不可言」。对于 LLM 的后训练来说,这就是在策略蒸馏(on-policy distillation)。
在策略蒸馏 ------ 集两者之长
在策略蒸馏的核心思想是:从学生模型中采样轨迹,并使用一个高性能的教师模型来为每个轨迹的每一个 token 评分。
回到我们上面的数学例子,在策略蒸馏会给解题的每一步打分,惩罚那些导致学生得出错误答案的错误步骤,同时强化那些执行正确的步骤。

在这篇文章中,我们探讨了在策略蒸馏在以下任务上的应用:
-
训练模型进行数学推理。
-
训练一个兼具领域知识和指令遵循能力的助手模型。
我们在已经具备预训练和中训练基础能力的模型上应用在策略蒸馏。我们发现,这是一种廉价而强大的后训练方法,它成功将在策略训练的优势和密集奖励信号结合到了一起。
我们的在策略蒸馏工作借鉴了 DAGGER(Ross et al, 2010),这是一种迭代式的 SFT 算法,它包含了教师对学生访问过的状态的评估。
它也类似于过程奖励建模(Lightman et al, 2023),这是一种 RL 方法,会对学生模型思维链中的每一步都进行评分。
我们扩展了 Agarwal et al.(2023)和 Qwen3 团队(2025)之前的在策略蒸馏工作。使用 Tinker 训练 API,我们复刻了 Qwen3 的成果,即通过在策略蒸馏在推理基准上实现了同等性能,而成本仅为 RL 的一小部分。
实现
你可以在这个 Tinker cookbook 中跟着学习实现的每一步:
损失函数:反向 KL
在策略蒸馏可以使用多种损失函数来为学生的轨迹评分。为简单起见,我们选择逐 token 的反向 KL(reverse KL)------ 即在给定相同先前轨迹的条件下,学生(π_θ)和教师(π_teacher)在每个 token 上的分布之间的散度:
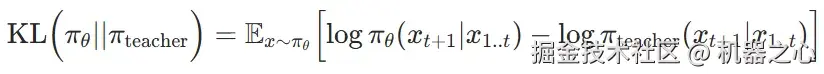
我们的奖励函数会最小化反向 KL,这会促使学生在自己所处的每种状态下都去近似教师的行为。当学生的行为与教师完全一致时,反向 KL 为零。为简单起见,我们使用的折扣因子为零:在任何给定的时间步,学生只优化眼前的下一个 token,不考虑未来的 token。
反向 KL 与 RL 有着天然的协同作用,RL 通常优化由奖励模型引导的某种序列级反向 KL。然而,与实践中的大多数奖励模型不同,反向 KL 是「不可破解的」(unhackable),因为从教师模型的角度来看,低 KL 总是对应着高概率的期望行为。反向 KL 的另一个有用特性是它是「寻找众数(mode seeking)」的 ------ 它学习一种特定行为(教师的行为),而不是将其分布分散在几个次优选项上。
这种方法可节省大量计算资源。因为它不需要等待一个轨迹完成采样才能计算奖励,所以我们可以使用更短或部分的轨迹进行训练。查询教师的对数概率也只需要大型模型进行一次前向传播,而轨迹则是由更小、更廉价的学生模型生成的。
我们也不需要单独的奖励或标注模型。将基于蒸馏的逐 token 奖励与序列级的环境奖励结合起来可能会有好处;这是未来一个有趣的潜在研究领域。
图解
下面我们来看一个真实的例子,这是一个错误的学生轨迹,由教师模型进行评分。这个例子来自 SimpleBench,它要求模型做出一个关键观察:问题的前提很重要。正确答案是 「B. 0」,因为冰块在煎锅里会融化。而学生模型(Qwen3-4B-Instruct-2507)错误地将其视为一个纯粹的数学问题,没有考虑物理背景。

颜色越深,代表该 token 受到教师模型(Qwen3-235B-A22B-Instruct-2507)的惩罚越高(教师模型正确解决了这个问题)。
我们看到,它惩罚了那些引导学生误入歧途的短语的起始 token,这直观上对应了引导推理的重要「分叉 token」(forking tokens)。最终答案(虽然是错的)并没有受到惩罚 ------ 因为在给定前面所有序列的条件下,这个答案是完全可预测的。
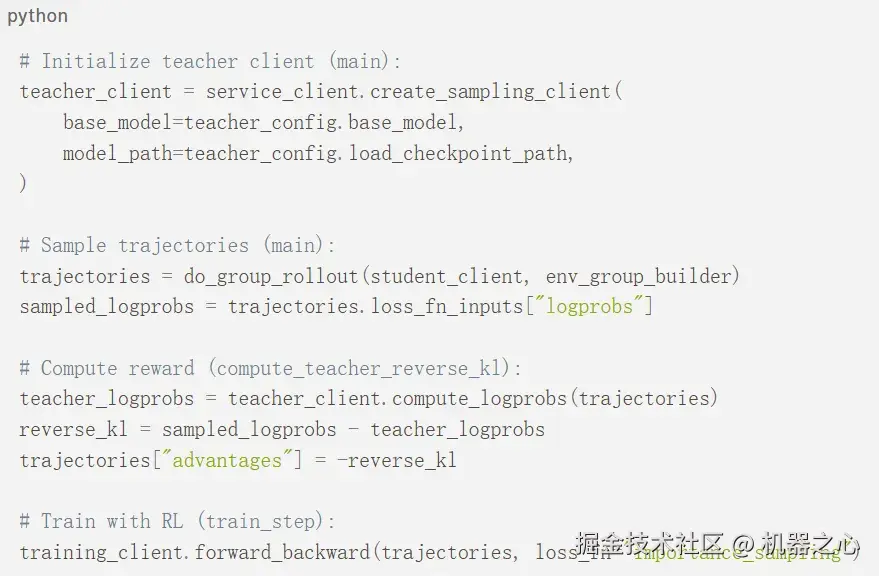
伪代码
我们在 Tinker 的 RL 脚本之上实现了在策略蒸馏,该脚本已经实现了采样、奖励计算和策略梯度式的训练。
地址:thinkingmachines.ai/blog/on-pol...
-
初始化教师客户端:Tinker API 可以轻松地为不同模型创建不同的客户端。我们使用采样客户端,因为我们不需要通过教师模型传播对数概率。
-
采样轨迹:我们像在 RL 中一样从学生模型中采样轨迹。在采样期间,RL 已经计算了学生的对数概率 log π_θ(x),用作重要性采样损失的一部分。
-
计算奖励:我们用 compute_logprobs 函数在采样出的轨迹上查询教师客户端,它会返回教师在学生采样的 token x 上的对数概率 log π_teacher (x)。然后我们用这个来计算反向 KL。
-
使用 RL 进行训练:我们将逐 token 的优势(advantage)设置为负的反向 KL,并调用 RL 的重要性采样损失函数来对学生模型执行训练更新。
伪代码如下:
在下面的实验中,我们通常将在策略蒸馏应用于已经过特定领域知识中训练的模型。这种训练提高了学生生成教师分布范围内的 token 的概率,尽管这通常远不足以复刻教师的性能。通常,正如我们将在个性化示例中看到的,生成相关 token 的概率开始时为零,因为学生缺乏任何相关的领域知识。
我们将使用在策略蒸馏进行后训练,并将其与训练专家模型的其他最后关键阶段的方法进行比较。
蒸馏以获得推理能力
我们使用蒸馏来训练 Qwen3-8B-Base 模型的数学推理能力,并使用 Qwen3-32B 作为教师模型。教师(Qwen3-32B)和学生(Qwen3-8B-Base)都是目前 Tinker 上支持的模型,因此你可以使用 Tinker cookbook 复现我们的实验。
离策略蒸馏
如前所述,我们所有的实验都以离策略蒸馏(即在教师生成的示例数据集上进行监督微调)的形式作为中训练的起点。用于数学推理的数据集是 OpenThoughts-3,这是一个由 QwQ-32B(一个类似于 Qwen3-32B 的推理模型)生成的推理提示和响应的集合。
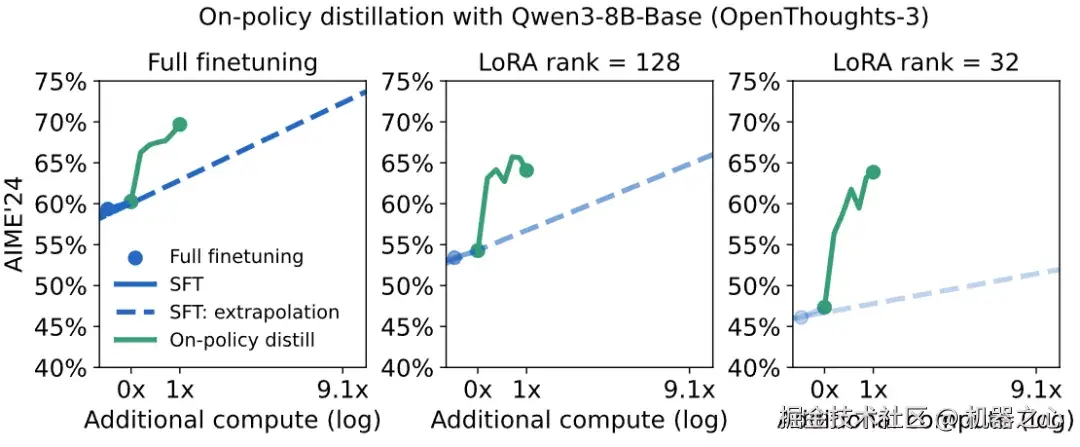
在 40 万个提示上对学生模型(Qwen3-8B-Base)进行全参数微调(full fine-tuning),在 AIME'24(一个数学问题基准测试)上获得了 60% 的分数。我们也可以使用 LoRA 进行训练,但在高容量数据集上训练时,它落后于全参数微调。在所有情况下,我们都看到性能呈对数线性增长 ------ 最初的性能提升很廉价,但后期的提升成本高昂。
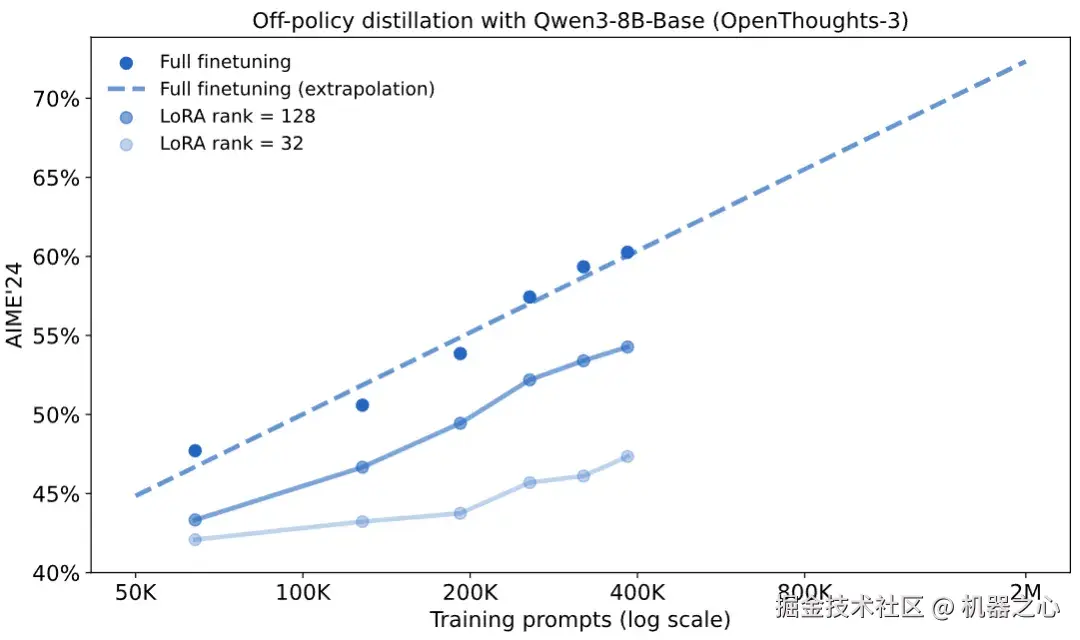
我们可以将在 40 万个提示上微调过的模型视为一个检查点,然后尝试各种后训练方法,将其在 AIME'24 基准上的分数从 60% 提高到 70%。
默认方法是在更多提示上进行微调,即继续离策略蒸馏的过程。根据对数线性趋势推断,我们估计模型在大约 200 万个提示上能达到 70% 的分数。这个推断需要 scaling law 持续有效而不停滞,这并不简单。
强化学习
Qwen3 技术报告称,在类似的 SFT 初始化基础上,通过 17,920 个 GPU 小时的 RL,在基准测试上达到了 67.6% 的性能。这很难与蒸馏的成本直接比较,但基于对 SFT 训练堆栈的一些合理假设,这与在 200 万个离策略蒸馏提示上训练的成本相似。
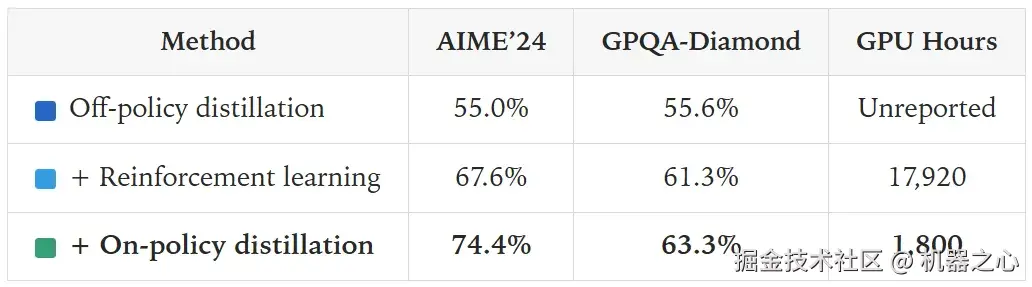
Qwen 团队还报告称,使用在策略蒸馏,能以 RL 成本的十分之一,在 AIME'24 上达到了 74.4% 的更高分数。这也启发了我们的工作。
在策略蒸馏
作为替代方案,我们运行了在策略蒸馏。从 40 万 SFT 检查点开始,在策略蒸馏在大约 150 个步骤内就达到了 AIME'24 70% 的成绩。
跨方法比较计算成本并非易事。下面,我们用 FLOPs(浮点运算次数)来计算成本。
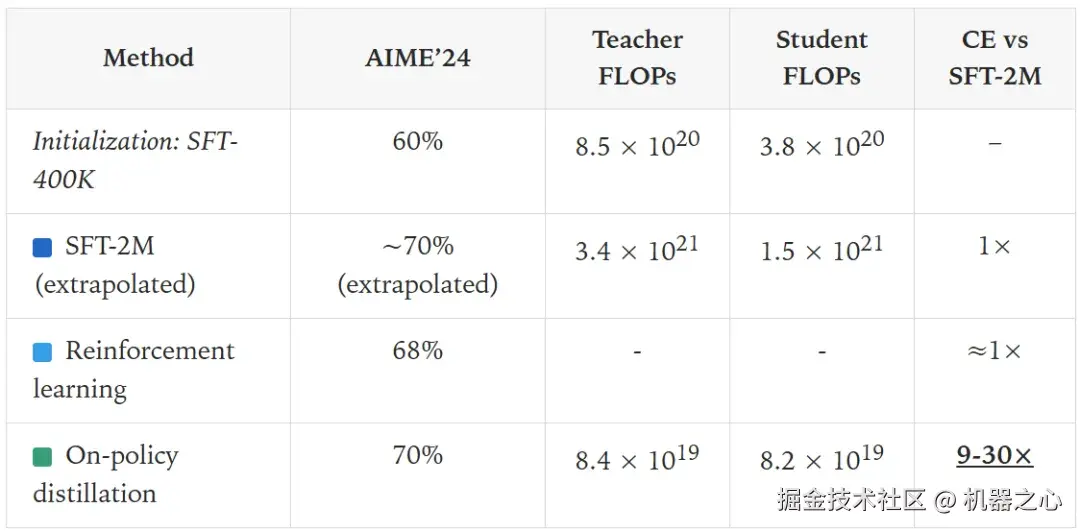
我们发现,当 SFT 数据集是现成的(如我们的 OpenThoughts-3 示例)或在多次训练中被摊销时,基线成本降低了 9 倍。
然而,我们经常希望在一个没有现成离策略蒸馏数据集的新任务上训练一个小模型。如果我们将教师模型的全部成本(即包括从教师模型采样的额外成本)计算在离策略蒸馏中,那么总成本可降低约 30 倍。
用于个性化的蒸馏
除了将小型模型训练到在通用任务上表现出色之外,蒸馏的另一个用例是个性化。例子包括在对话中遵循特定的语气和输出格式,或者像工具使用和成本预算这样的能力。我们经常希望在传授新领域知识的同时训练这种行为。
同时训练这两者通常很困难,轻量级微调(如 LoRA)往往不足以实现这一目标,因此需要更大规模的中训练。在掌握新知识的基础上学习后训练行为,需要一个复杂的后训练堆栈,通常由专有数据和奖励模型组成。虽然前沿实验室可以做到这一点,但其他从业者要复刻可能很困难或成本高昂。
在本节中,我们展示了在策略蒸馏可以有效地用于后训练专业化行为。这种方法也适用于持续学习或「测试时训练」:即在模型部署后更新它们,而不会导致基础性能下降。我们使用一个在公司内部文档上进行中训练的模型作为应用示例。
训练一个内部助手
定制模型的一个常见目标是充当助手:在某个领域拥有专家知识,并且具有可靠的助手式行为。我们可能需要对这两者进行单独训练,尤其是当专业领域知识无法仅从预训练数据中学到,或者学习它会干扰行为时。
我们的例子是一个公司内部助手,我们有两个期望:
-
模型对该领域(公司文档)知识渊博。预训练模型没有见过任何公司内部文档,因此无论模型规模多大,都只能猜测。我们将使用内部知识召回评估(「内部 QA」)来衡量这一点。
-
模型表现出强大的后训练行为,即遵循指令。我们将使用常用的 IF-eval 来衡量这一点。
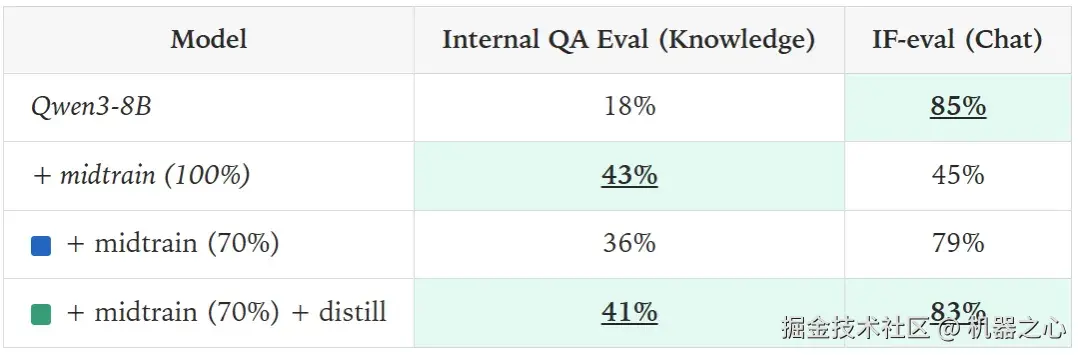
训练新知识会降低已学到的行为
我们将从 Qwen3-8B(而不是基础模型)开始。Qwen3-8B 已经通过 RL 进行了后训练,掌握了作为助手有用的技能,如指令遵循和推理。先前的研究表明,这种强化学习只训练了原始模型的一小部分子网络,因此当网络在大量数据上进一步训练时,可能会变得很脆弱。我们研究了这种情况发生的程度,以及如何恢复所需的行为。
为了减少这种灾难性遗忘(catastrophic forgetting),中训练中一种常见的做法是混入来自模型原始预训练分布的「背景数据」。
在这种情况下,我们无法访问 Qwen3 的预训练分布。因此,我们考虑一个更强、成本更高的基线:我们获取 Tulu3 提示(一个广泛的聊天和指令遵循数据集),并使用 Qwen3-8B 重新采样它们,以充当聊天背景数据。
然后,我们在内部文档和聊天数据的不同混合比例上微调 Qwen3-8B。提高文档数据比例会直接提升模型的知识水平。然而,尽管混入至少 30% 的聊天数据有助于保留大部分指令遵循能力,但没有任何一种权重配比能维持在 IF-eval 上的原始性能。
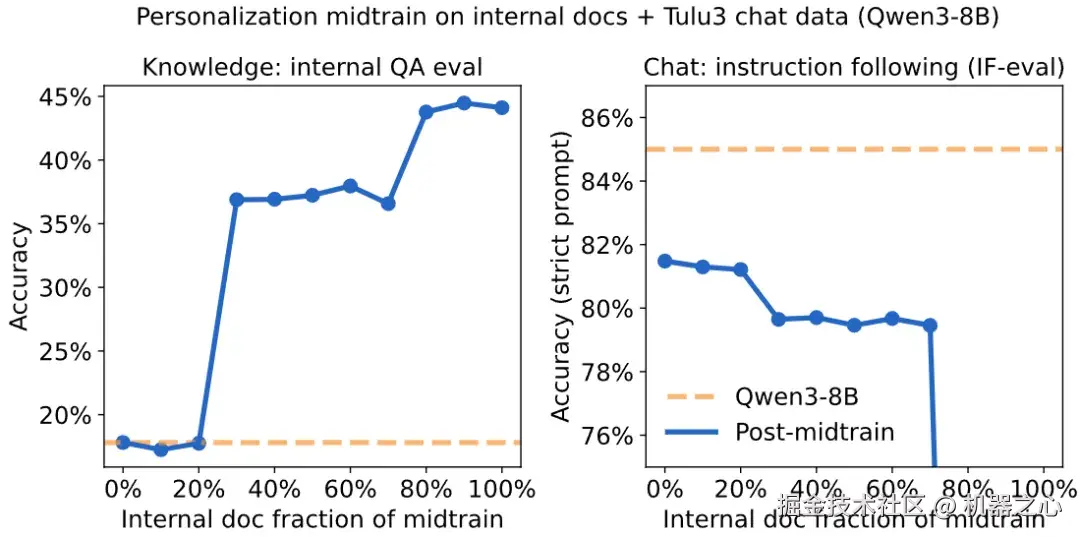
对于任何给定的混合比例,我们都观察到 IF-eval 性能在微调过程中下降。
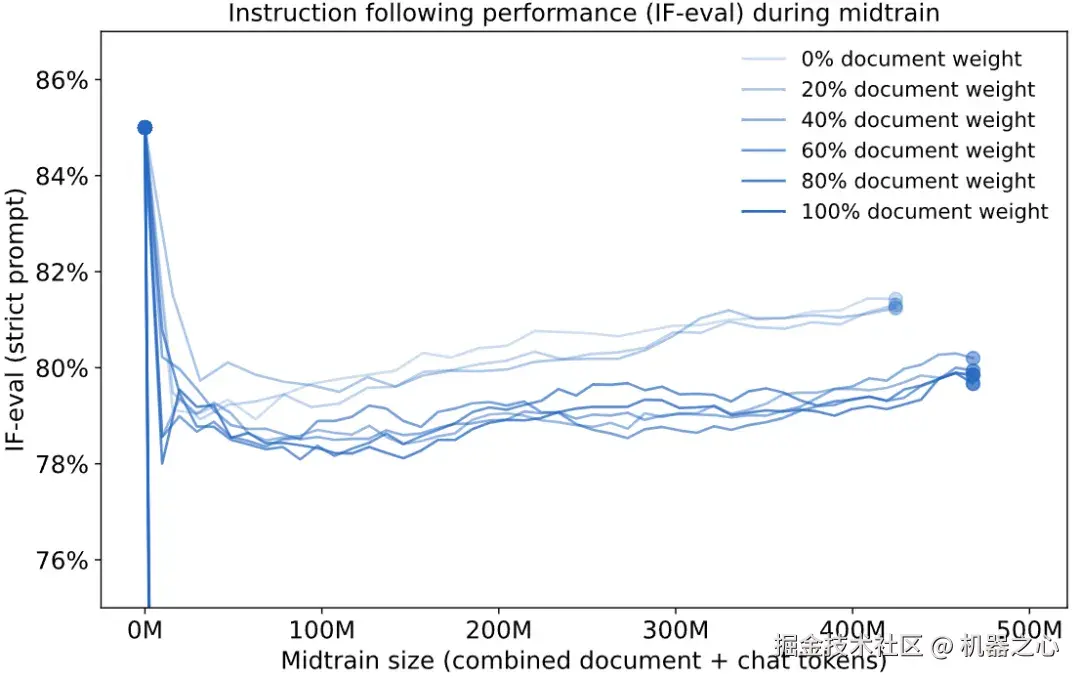
另一种常用的方法是使用 LoRA 来约束参数更新,从而减少灾难性遗忘的可能性。然而,这种方法仍然不足以保留 IF-eval,而且 LoRA 学到的知识也更少。
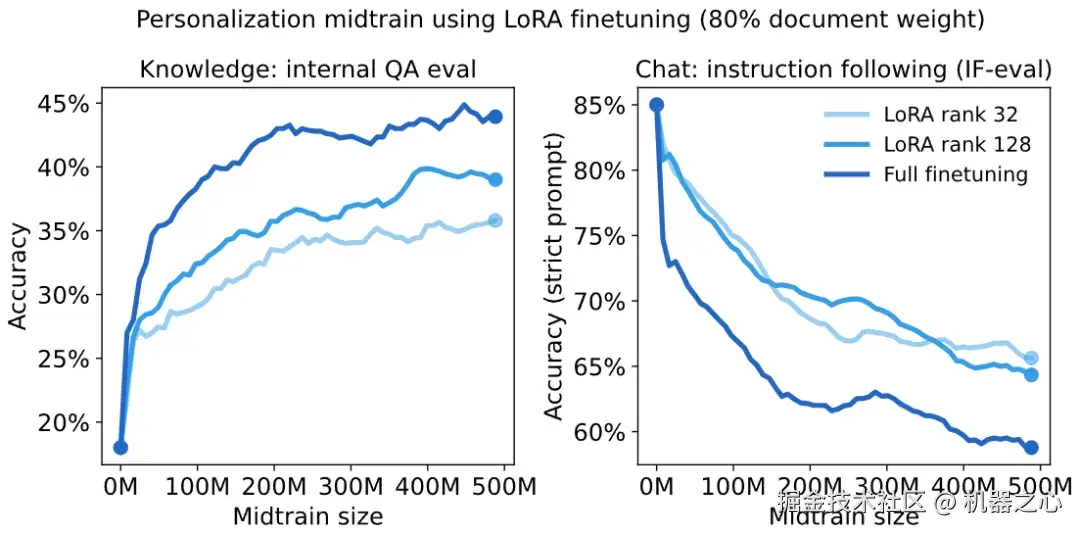
在策略蒸馏恢复后训练行为
接下来,我们试图在对内部文档进行微调后,恢复指令遵循行为。这种行为最初是用 RL 训练的,成本高昂,而且正如我们所见,很脆弱。
取而代之的是,我们在 Tulu3 提示上,使用模型的早期版本 Qwen3-8B 作为教师,来进行在策略蒸馏。请注意,这个训练阶段与内部文档数据无关,其唯一目的是恢复指令遵循能力。
使用模型的早期版本作为教师来「重新唤起」在微调过程中丢失的能力,这使得在策略蒸馏在持续学习(continuous learning)方面非常有前景。我们可以交替进行「在新数据上微调」和「蒸馏以恢复行为」这两个阶段,使我们的模型能够随着时间的推移学习并保持知识的最新状态。
在 70-30 混合的内部文档数据和聊天数据上微调后,在策略蒸馏几乎完全恢复了在 IF-eval 上的性能,且没有损失任何知识;我们还观察到聊天能力和模型在内部 QA 评估中的「知识」性能之间存在一些正向迁移。
从本质上讲,我们将语言模型本身视为一个奖励模型,高概率的行为会受到奖励。这与逆向 RL(inverse RL)有关:高概率的行为对应于假定的潜在偏好模型中的有利奖励。任何经过指令调优的开源权重模型都可以在这个意义上用作奖励模型;我们只需要能访问 compute_logprobs 函数。
讨论
密集监督可极大提高计算效率
强化学习和在策略蒸馏都通过反向 KL 进行学习,修剪基础策略中存在的动作空间。区别在于奖励的密度。
在 LoRA Without Regret 中,我们提出了信息论的观点,即强化学习每个回合只教授 O (1) 的比特。相比之下,蒸馏每个回合教授 O (N) 比特,其中 N 是 token 的数量。通过更密集的奖励,我们到底能获得多少训练效率的提升?
我们做了一个实验来直接比较两者:
-
从 Qwen3-8B-Base(没有额外的 SFT)开始。
-
在 DeepMath 上运行 RL。我们使用 128 的 LoRA rank。生成的模型是蒸馏的教师。
-
从 RL 训练的模型(2)在策略蒸馏回基础模型(1)。
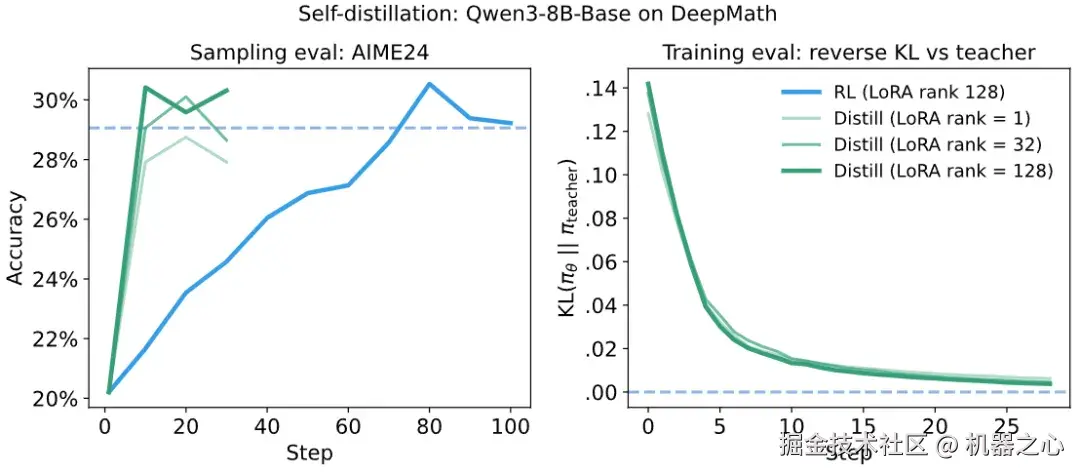
从相同的初始化开始,在策略蒸馏学习 RL 训练的策略所需的梯度步数大约少 7-10 倍,这对应于 50-100 倍的计算效率提升。
我们看到,蒸馏达到教师性能水平的速度比 RL 快了大约 7-10 倍。反向 KL 下降到接近零,AIME 分数在 10 个梯度步内就得以恢复,而 RL 则需要 70 步才能达到该水平。
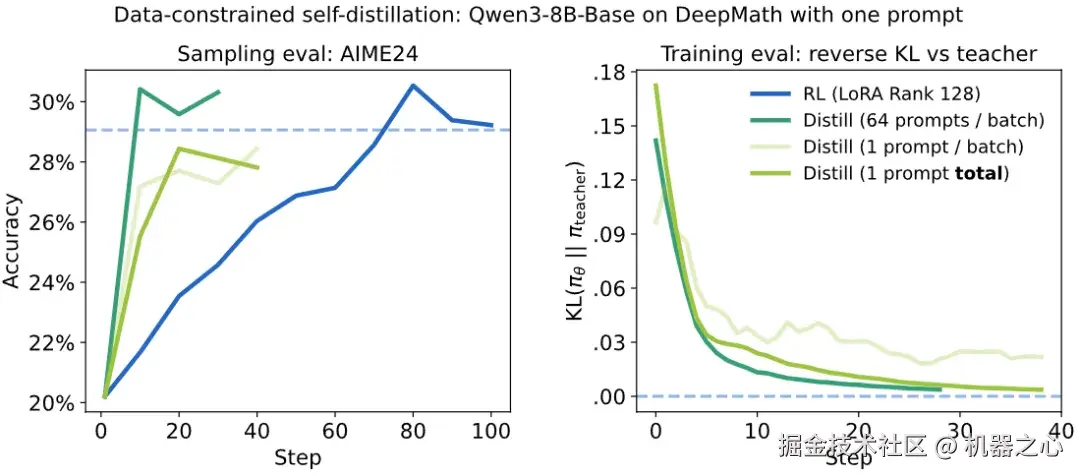
蒸馏可以有效地重用训练数据以提高数据效率
对于从业者来说,收集大量的训练提示可能既困难又耗时。因此,我们希望能够在训练中多次重用提示。
使用 RL 时,在同一个提示上训练多个轮次(epochs)常常导致对最终答案的简单记忆。
相比之下,在策略蒸馏学习的是近似教师的完整分布,而不是记忆单个答案。这使我们能够用同一个提示训练多个样本。
我们重复了上述在数学上训练 Qwen3-8B-Base 的实验,但这次只使用数据集中随机选择的一个提示。我们在这个提示上连续训练了 20 步。尽管我们只在一个提示上训练,但我们确实达到了与教师模型相当的性能。
RL 在语义策略空间中搜索
我们已经看到,在策略蒸馏可以用少得多的训练步骤来复刻 RL 提供的学习效果。
一种解释是,与预训练不同,RL 并未在梯度步骤本身上花费大量计算。我们应该认为 RL 将其大部分计算用在了搜索(search)上 ------ 即推出一个策略并分配功劳 ------ 而不是进行更新。
预训练通过随机梯度下降探索高维参数空间。预训练需要海量信息,并且非常难以蒸馏。
相比之下,我们应该认为 RL 是在探索语义策略(semantic strategies)的空间。RL 不是在参数空间中探索,而是靠运气「偶然」发现新策略 ------ 它只是从它已有的权重集合中随机抽样。
一旦找到了一个好的策略,蒸馏就成了学习它的捷径:在策略蒸馏不需要对 RL 课程中的中间策略进行建模,而只需要学习最终的策略。
打个比方:在科学研究中,我们花费大量时间和资源来寻找答案和探索新思想。一旦发现一个结果,用自然语言将其教给别人就简单得多。相比之下,像运动这样的直觉性身体技能,就很难教给别人,因为这些知识存在于一种天生的语言中(例如,肌肉记忆),只有我们自己才能轻易理解。运动只能通过反复练习来学习。
作为持续学习工具的在策略学习
在关于个性化的部分,我们探讨了在策略蒸馏将专业训练行为重新引入模型的能力。这可以推广到更广泛的持续学习(continual learning)任务,这些任务要求在不降低先前能力的情况下获取新知识。
先前的工作发现,在策略学习(RL)比较少地遗忘。然而,RL 只能塑造行为 ------ 它不能很好地教授新知识,因此不足以用于持续学习。
在上一节中,我们看到 SFT(包括离策略蒸馏)在支持持续学习方面是失败的,因为它会降低行为。
我们更深入地研究了这个问题。当我们在模型自己的样本数据集上运行 SFT 时会发生什么?我们看到,任何大于零的实用学习率都会导致指令遵循评估的性能下降!
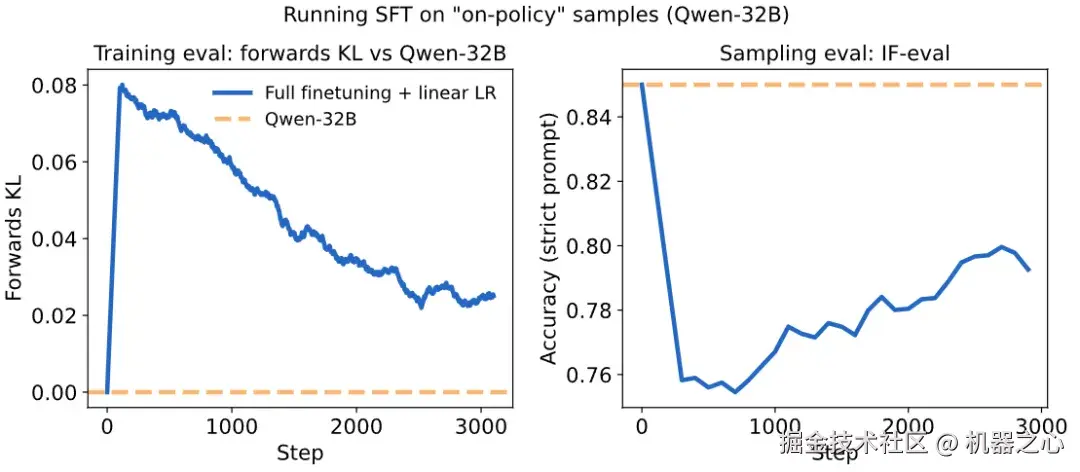
一个可能的解释是,虽然 KL 散度在期望上为 0,但每个有限的批次(batch)在实践中都会表现出略微不同的分布。在这些有限批次上训练会导致非零的梯度更新,这会使更新后的模型策略偏离其原始状态。
在策略蒸馏始终保持在在策略状态,并且由于教师保持不变,学生会收敛于教师的期望行为,而不会像 SFT 那样在自蒸馏设置中出现性能衰退。这使得在策略蒸馏成为一种非常有前景的持续学习工具。
总结
我们探讨了在策略蒸馏在训练小型模型进行数学推理或持续学习助手等方面的应用。我们将在策略蒸馏与其他两种后训练方法进行了比较:离策略蒸馏和在策略 RL。
我们发现,在策略蒸馏结合了两者的优点:在策略训练的可靠性能以及密集奖励信号带来的成本效益。
后训练是达到前沿模型能力的关键部分。通过利用来自学生的在策略采样和来自教师的密集监督,在策略蒸馏方案能够以前沿高计算量 RL 运行成本的一小部分,达到这些能力。
我们的实现可以在 Tinker cookbook 中找到。我们的工作探索了在策略蒸馏的简单直接的实例化,以清晰地展示其优势。我们希望继续研究蒸馏的新应用、改进教师监督的新方法,以及提高数据效率和持续学习的方法。
在 Thinking Machines,我们的使命是为人们提供兼具前沿性能、适应性和个性化的 AI 模型。在策略蒸馏是实现这一目标的有力工具。
参考链接