在这个信息爆炸的时代,我们每天面对堆积如山的文档、报告和表格,如何让机器真正读懂这些复杂排版下的文字信息,始终是技术领域的核心挑战。传统的 OCR 解决方案往往需要多个模块拼凑而成,流程繁琐且容易出错,尤其是在处理多语言混排或复杂版式时,更是力不从心。
而小红书 hi lab 最新开源的 dots.ocr 模型为解决这些困境带来了希望。这个仅 17 亿参数的轻量级选手,凭借统一的视觉语言架构,实现了从文本识别、版面分析到阅读顺序理解的一站式解决方案。它不仅能精准处理 100 种语言,更在模糊扫描件、倾斜拍摄等复杂场景下展现出了超越大规模模型的稳健性能。
教程链接:https://go.openbayes.com/UKdLR
使用云平台:OpenBayes
http://openbayes.com/console/signup?r=sony_0m6v
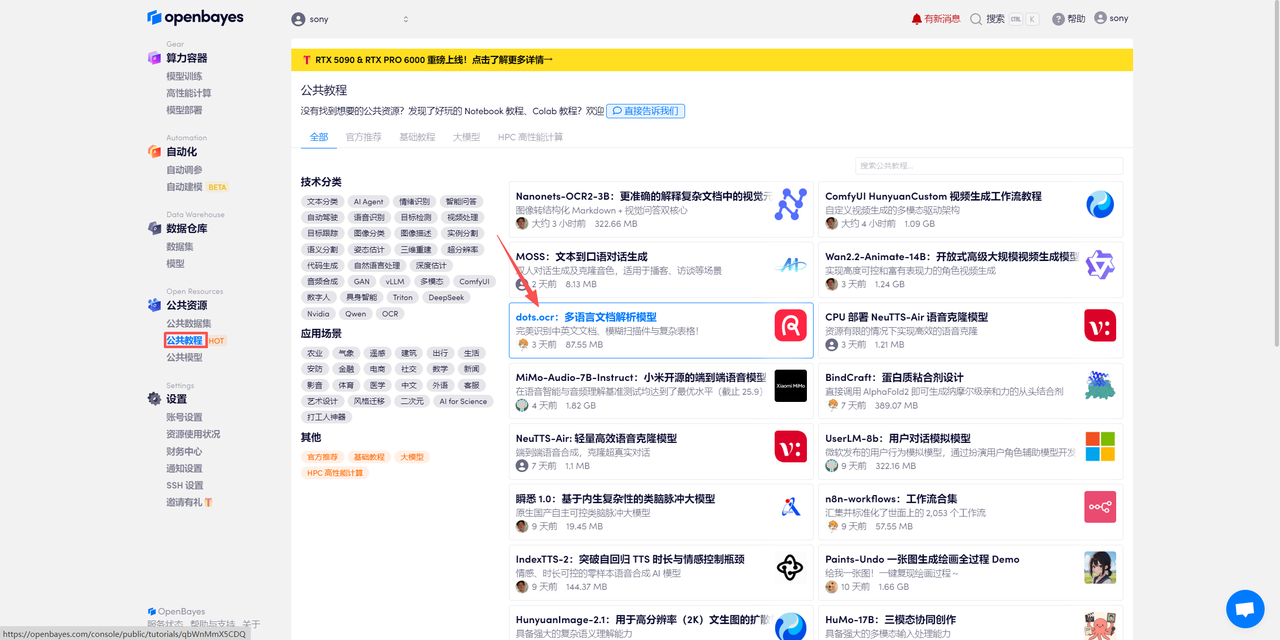
登录 OpenBayes.com,在「公共教程」页面,选择一键部署 「dots.ocr:多语言文档解析模型」教程。
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
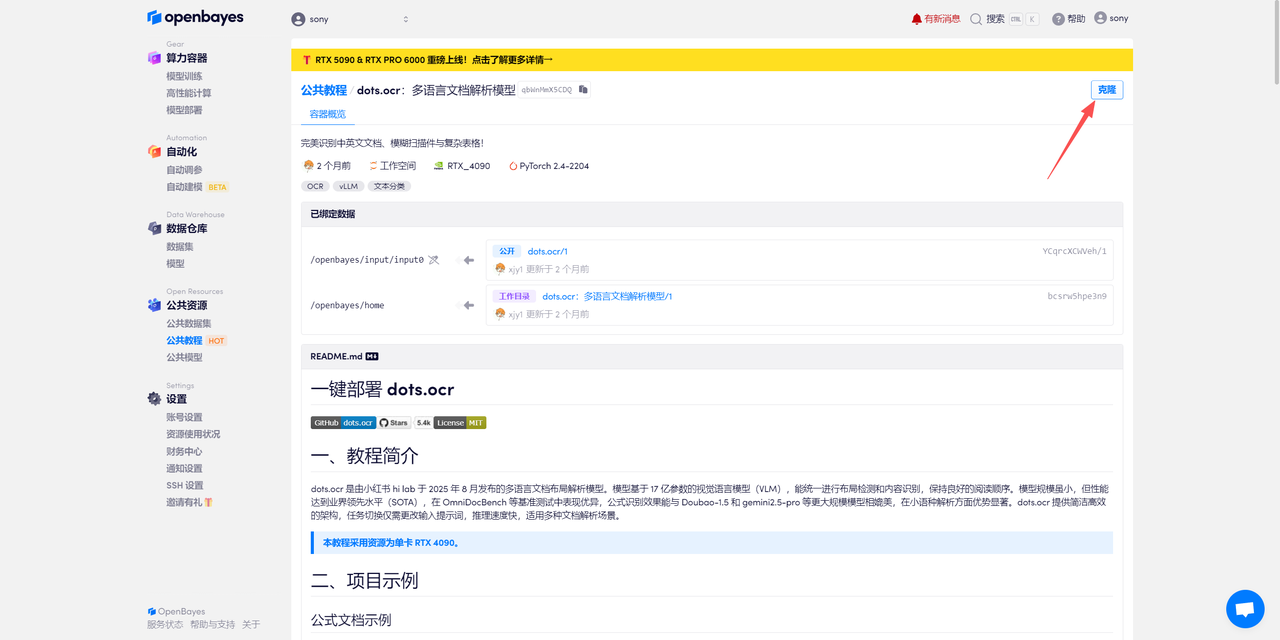
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
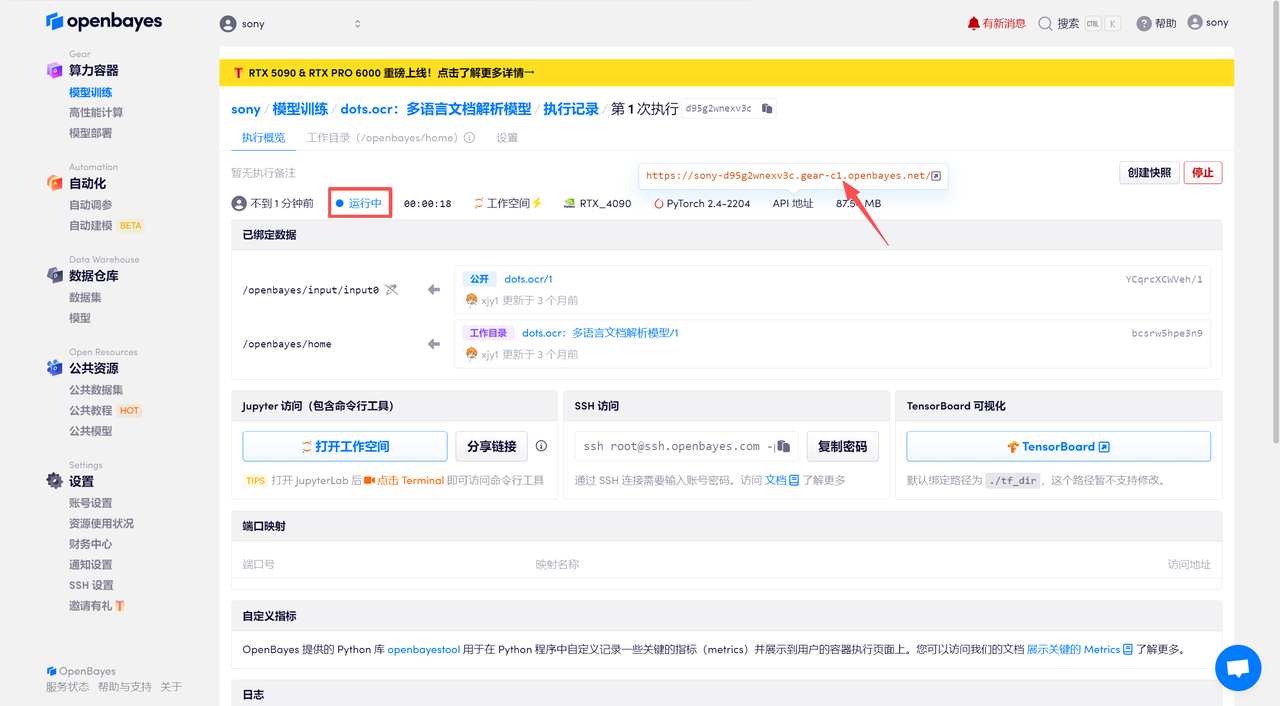
待系统分配好资源,当状态变为「运行中」后,点击「API 地址」边上的跳转箭头,即可跳转至 Demo 页面。
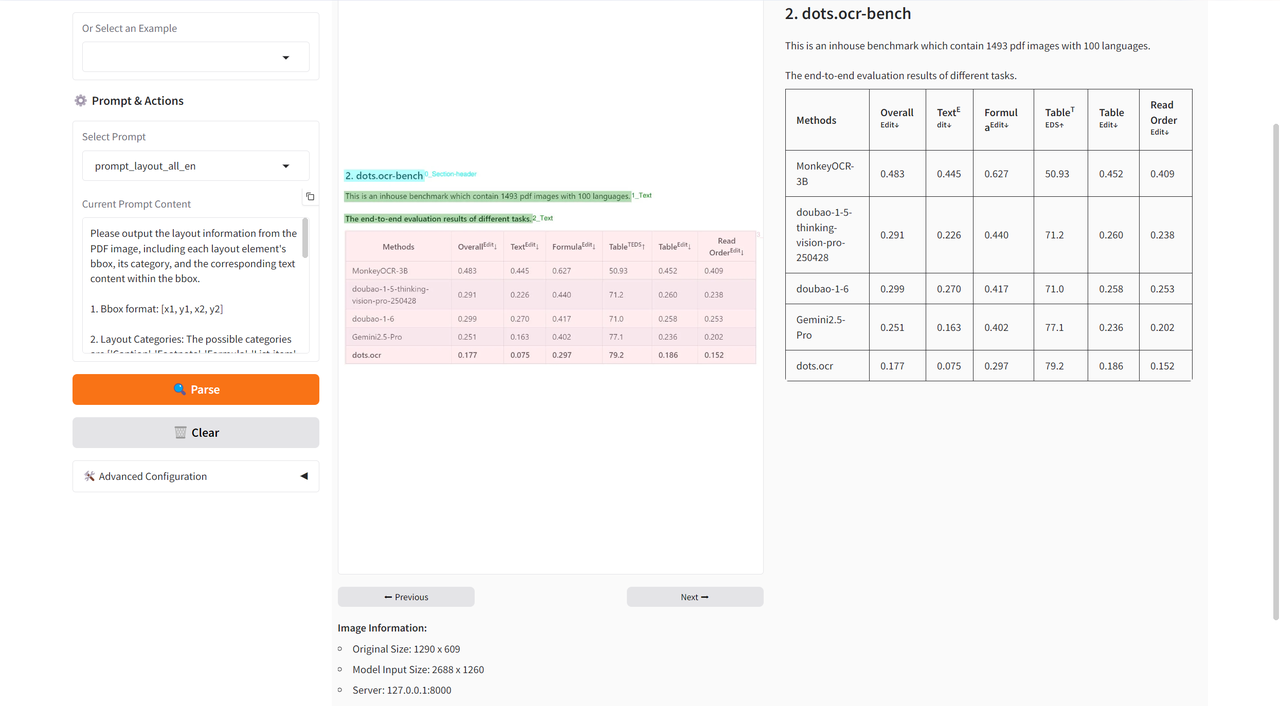
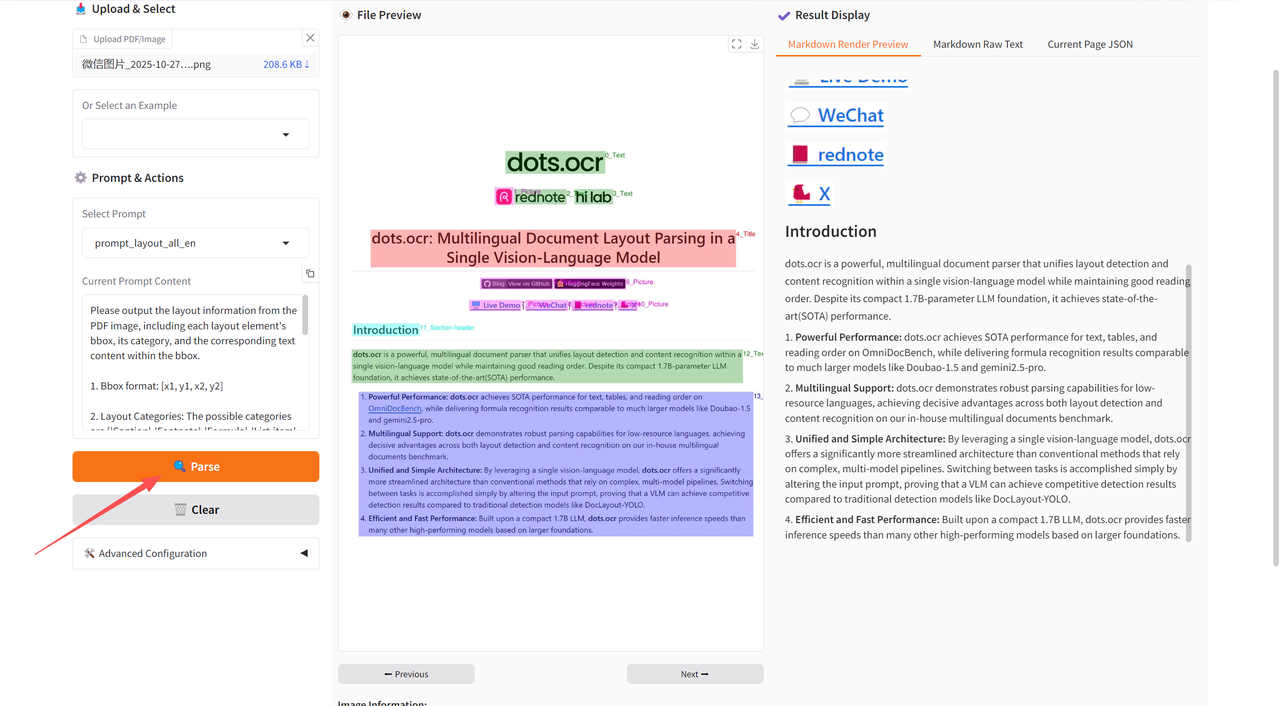
这里我们以「Parse」功能为例,上传一个英文文档,效果如下所示:
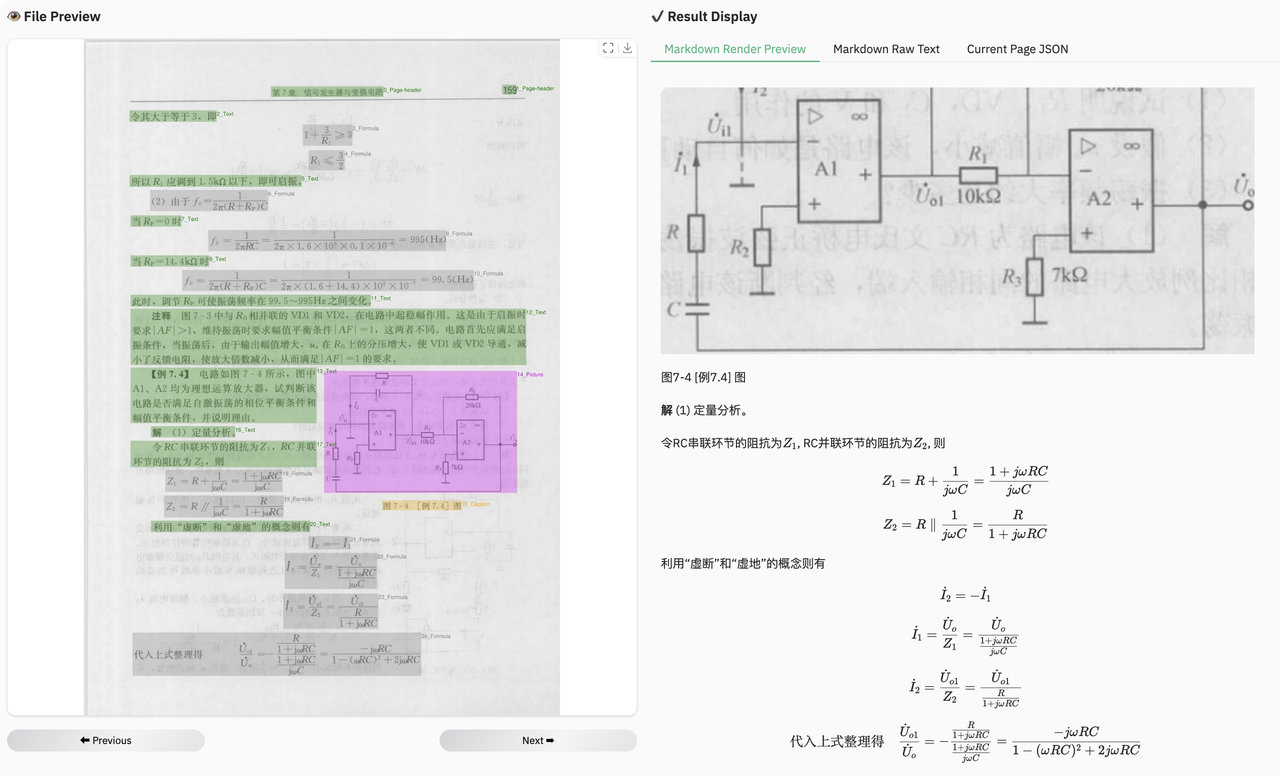
此外,无论是表格还是公式,模型都能出色地完成识别: