时序数据库选型指南:从大数据视角看高效存储与分析
在大数据时代,时序数据已成为众多行业核心资产之一。随着物联网(IoT)、工业互联网、智能制造和实时监控等应用的爆发式增长,时序数据------即按时间顺序记录的指标、事件或测量值------的规模和复杂度急剧增加。根据相关报告,大数据环境中时序数据的占比已超过传统结构化数据的许多领域,如何选择合适的时序数据库(Time Series Database,TSDB)成为企业和开发者面临的关键挑战。本文从大数据角度出发,提供时序数据库选型的实用指南,并重点介绍Apache IoTDB作为一种高效解决方案的亮点,帮助读者在海量数据处理中做出明智决策。
时序数据在大数据中的作用与挑战
大数据的核心在于"4V"特征:Volume(海量)、Velocity(高速)、Variety(多样)和Value(价值)。时序数据完美体现了这些特性,尤其在Velocity和Volume上表现突出。例如,在工业物联网中,传感器每秒可能产生数千条数据点;在金融领域,股票行情数据实时流动;在能源管理中,智能电网的监测数据源源不断。这些数据不仅体量巨大,还要求高频写入、实时查询和长期存储。
然而,时序数据管理面临诸多挑战:
- 高并发写入:大数据系统需支持每秒数百万甚至亿级的写入操作,而传统关系型数据库(如MySQL)在时序场景下效率低下。
- 高效查询与分析:需要支持时间窗口聚合、降采样、下钻分析等操作,同时集成大数据生态如Hadoop、Spark等。
- 存储优化:时序数据往往具有高压缩性和生命周期管理需求(如冷热数据分离),以降低存储成本。
- 可扩展性:在分布式环境中,支持水平扩展以应对数据爆炸式增长。
- 可靠性与安全性:确保数据一致性、容错机制和访问控制,尤其在边缘计算与云端混合部署中。
选型时,应优先评估数据库是否能无缝融入大数据架构,如支持Kafka、Flink等流式处理工具,并提供与HDFS或S3兼容的存储层。
时序数据库选型关键标准
在大数据背景下,选择时序数据库需综合考虑以下维度,确保其能处理TB/PB级数据并支持复杂分析:
-
性能指标:
- 写入吞吐量:评估在分布式集群下的每秒写入点数(Points Per Second, PPS)。
- 查询延迟:针对时间序列特有的操作,如范围查询和聚合,应在毫秒级响应。
- 压缩效率:优秀TSDB可将存储空间压缩至原始数据的1/10甚至更低,利用Delta编码或Gorilla算法。
-
架构设计:
- 分布式支持:是否原生支持集群模式,实现数据分片和复制,以应对大数据的横向扩展。
- 生态集成:与大数据工具链的兼容性,例如支持SQL-like查询语言,便于与Spark SQL或Presto集成。
- 部署灵活性:支持云原生、容器化(如Kubernetes)和边缘部署,适应多云环境。
-
功能特性:
- 时间序列优化:内置时间索引、序列对齐和异常检测功能。
- 数据模型:灵活支持多维度标签(如设备ID、位置),便于元数据管理。
- 监控与运维:提供可视化仪表盘、自动备份和故障恢复机制。
-
成本与社区支持:
- 开源 vs 商用:开源选项可降低初始成本,但需评估社区活跃度。
- 扩展成本:考虑 license、硬件需求和维护开销。
-
应用场景匹配:
- 针对大数据场景,如IoT监控、日志分析或预测维护,选择专为时序优化的数据库而非通用NoSQL。
通过这些标准,企业可构建评估矩阵,例如使用基准测试工具如TSBS(Time Series Benchmark Suite)模拟真实负载。
Apache IoTDB:大数据时代时序数据库的优选方案
在众多时序数据库中,Apache IoTDB(Internet of Things Database)脱颖而出,作为Apache基金会顶级项目,它专为物联网和时序大数据设计,提供端到端的解决方案。IoTDB从大数据视角优化了存储和分析流程,特别适合处理海量传感器数据和实时指标。

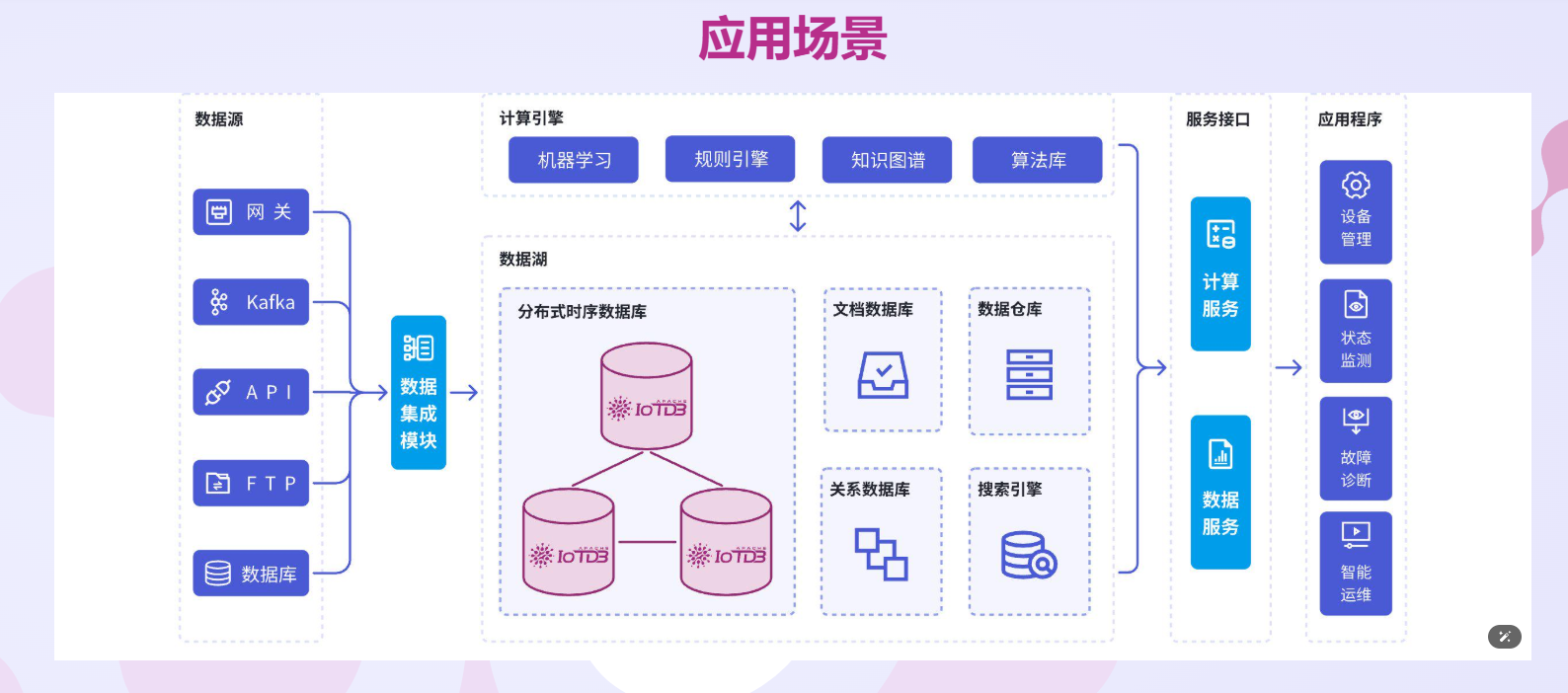
IoTDB的核心优势
- 高性能写入与查询:IoTDB采用TsFile格式,支持每秒数亿点的写入,支持分布式集群模式,可线性扩展到数百节点。在大数据环境中,它能高效处理PB级时序数据,查询速度远超传统方案。
- 大数据生态无缝集成:IoTDB兼容Apache生态,支持与Spark、Flink和Hadoop的集成。例如,通过IoTDB的JDBC驱动,可直接在Spark中进行时序数据分析;它还提供UDF(User-Defined Function)支持,方便自定义聚合操作。
- 存储优化与压缩:内置多级压缩算法和数据分层存储(热数据在内存,冷数据在磁盘),显著降低大数据存储成本。同时,支持TTL(Time To Live)机制自动清理过期数据。
- 灵活数据模型:IoTDB使用树形结构建模设备和传感器,支持多层级元数据管理,适用于复杂的大数据场景如智能工厂或城市大脑。
- 可靠性与可扩展性:原生分布式架构,确保高可用性和故障转移。在Kubernetes上部署简便,支持边缘-云同步,完美契合大数据的混合云策略。
- 开源社区活跃:作为Apache项目,IoTDB拥有全球开发者社区,提供丰富文档和插件扩展,助力企业快速上手。
在实际应用中,IoTDB已被广泛用于工业物联网、能源管理和车辆监控等领域。例如,在一个典型的大数据管道中,Kafka采集实时数据,IoTDB存储并分析,Grafana可视化输出,实现闭环。
获取与部署IoTDB
要开始使用Apache IoTDB,您可以从官方网站下载最新版本。下载链接:https://iotdb.apache.org/zh/Download/。
对于企业级需求,推荐探索Timecho企业版,它提供增强的功能如高级安全、商用支持和优化性能。企业版官网链接:https://timecho.com。
结语:基于大数据的选型策略
时序数据库选型是大数据架构中的关键一环,应从性能、集成和成本等多维度评估。Apache IoTDB以其专为时序优化的设计和强大生态支持,成为许多企业的首选。通过引入IoTDB,您可以高效管理海量时序数据,解锁大数据的价值。建议在选型前进行POC(Proof of Concept)测试,以验证其在特定场景下的表现。未来,随着5G和AI的融合,时序数据库将在大数据中扮演更核心角色,推动数字化转型。