前言:YOLO V1的局限与挑战
在目标检测领域,YOLO V1无疑带来了一场革命性的变革。然而,正如所有初代产品一样,YOLO V1也存在一些明显的局限性:定位不够准确 、对小目标检测效果差 、召回率较低等问题逐渐凸显。
今天我们要深入解析的YOLO V2(又称YOLO9000),正是在这样的背景下应运而生。它通过一系列精巧的改进,实现了"更准(Better)、更快(Faster)、更强(Stronger)" 三大目标,成为目标检测发展历程中的重要里程碑。
一、YOLO V2的核心思想概述
1.1 设计理念
YOLO V2的核心思想不是推倒重来,而是对YOLO V1进行系统性的"手术式升级"。作者Joseph Redmon等人从多个维度入手,每一处改进都针对YOLO V1的一个具体痛点。
🎯 主要改进方向:
-
网络结构优化:引入Darknet-19主干网络
-
训练策略创新:批归一化、多尺度训练等
-
检测机制革新:Anchor机制、直接位置预测
-
特征融合技术:Passthrough层提升小目标检测
1.2 性能提升概览
通过这一系列改进,YOLO V2在保持实时性的前提下,mAP(平均精度)从YOLO V1的63.4%提升到了78.6%,同时速度仍然保持在高水平。
二、网络结构重大升级:Darknet-19
2.1 为什么需要新的主干网络?
YOLO V1基于GoogleNet修改的网络在特征提取能力上存在局限。YOLO V2引入了全新的Darknet-19作为主干网络,其名称中的"19"代表了19个卷积层。
DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约⅕,以保证更快的运算速度。识别对象更多。
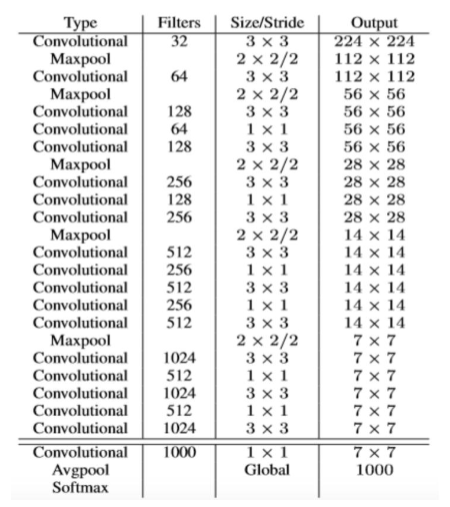
Darknet-19的优势:
-
使用连续的3×3卷积和1×1卷积交替堆叠
-
引入批量归一化(Batch Normalization) 稳定训练过程
-
去除全连接层,采用全卷积网络(FCN)设计
2.2 批量归一化的神奇效果
批量归一化是YOLO V2的重要改进之一,它在每个卷积层后添加BN层,带来以下好处:
✨ BN层的三大作用:
-
稳定训练过程:减少内部协变量偏移
-
加速收敛:允许使用更高的学习率
-
正则化效果:减少对Dropout的依赖
这一改进单独就为YOLO V2带来了2%的mAP提升。
三、Anchor机制的引入与优化
3.1 从直接预测到Anchor-Based
YOLO V1直接预测边界框的坐标,这种方式训练难度大且不稳定。YOLO V2借鉴Faster R-CNN的思路,引入了Anchor机制。
🔍 Anchor机制的工作原理:
-
将输入图像划分为S×S网格(通常S=13)
-
每个网格预设K个Anchor(先验框)
-
网络预测相对于Anchor的偏移量而非绝对坐标
3.2 维度聚类:更聪明的Anchor选择
传统方法手动设置Anchor的尺寸和比例,效果不理想。YOLO V2创新地使用k-means聚类方法从训练数据中学习最优的Anchor尺寸。
聚类过程的巧妙之处:
-
使用IOU作为距离度量而非欧氏距离
-
自动学习数据集中目标框的典型尺寸
-
最终选择5个聚类中心作为Anchor尺寸
这种方法得到的Anchor比手工设计的Anchor更符合实际数据分布,提高了检测效率。
四、直接位置预测:解决Anchor不稳定问题
4.1 传统Anchor的缺陷
直接采用Faster R-CNN的Anchor偏移预测方法会导致训练不稳定,因为偏移量没有约束,预测框可能"乱跑"。
4.2 YOLO V2的解决方案
YOLO V2沿用了一些V1的思路,预测边界框中心点相对于网格单元的偏移量,并使用sigmoid函数将偏移量约束在0-1之间。
📊 位置预测公式:
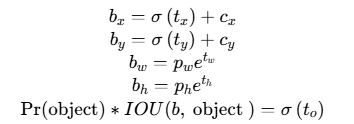
其中:
-
b_x, b_y, b_w, b_h是最终预测框的坐标 -
t_x, t_y, t_w, t_h是网络预测的偏移量 -
c_x, c_y是网格左上角坐标 -
p_w, p_h是Anchor的宽度和高度
这种方法确保了预测框中心不会偏离其所在的网格太远,大大提高了训练稳定性。
五、多尺度训练与特征融合
5.1 多尺度训练:适应不同分辨率
YOLO V2移除了全连接层,使得网络能够处理任意尺寸的输入图像 。作者利用这一特性,提出了多尺度训练策略。
🔄 多尺度训练的具体做法:
-
每10个batch随机更换输入尺寸
-
从{320, 352, ..., 608}中选择(32的倍数)
-
同一模型可适应不同分辨率需求
这种策略的优势:
-
高分辨率输入(608×608)→ 高精度,速度稍慢
-
低分辨率输入(320×320)→ 速度快,精度稍低
-
可根据实际需求灵活选择
5.2 Passthrough层:提升小目标检测
为了解决小目标检测难题,YOLO V2引入了Passthrough层,将浅层特征与深层特征融合。
特征融合过程示意图:
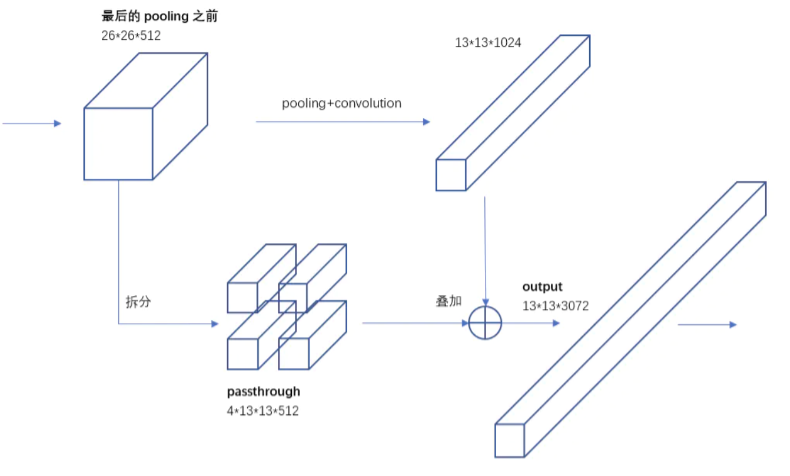
简单来说:就是在最后一个pooling之前,特征图大小是26×26×512,将其1拆4,直接传递到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。
浅层特征包含丰富的细节信息 (边缘、纹理),深层特征包含高级的语义信息。两者的结合使模型既能"看得清"(定位准),又能"懂得多"(分类准)。
六、YOLO V2的创新总结
6.1 技术改进全景图
下表总结了YOLO V2相对于YOLO V1的主要改进点:
| 改进领域 | 具体技术 | 带来的收益 |
|---|---|---|
| 网络结构 | Darknet-19主干网络 | 更强的特征提取能力 |
| 训练策略 | 批量归一化(BN) | 训练稳定,收敛更快 |
| Anchor机制 | 维度聚类 | 更匹配数据分布的先验框 |
| 位置预测 | 直接位置预测 | 解决训练不稳定问题 |
| 特征融合 | Passthrough层 | 显著提升小目标检测 |
| 训练策略 | 多尺度训练 | 灵活平衡速度与精度 |
6.2 性能对比
YOLO V2在保持高速度的同时,精度大幅提升:
-
PASCAL VOC数据集:mAP从63.4%提升至78.6%
-
COCO数据集:mAP从21.6%提升至44.0%
-
速度:在Titan X上达到40-90 FPS(取决于输入尺寸)
七、YOLO V2的深远影响
7.1 对后续发展的影响
YOLO V2的许多创新被后续版本继承和发展:
-
Darknet系列网络成为YOLO家族的标志
-
多尺度训练思想在YOLO V3、V4中进一步发扬光大
-
Anchor机制虽在最新版本中被替换,但其思想影响了整个领域发展
7.2 实际应用价值
YOLO V2在多个领域展现了实用价值:
-
自动驾驶:实时车辆和行人检测
-
视频监控:多目标实时跟踪
-
工业质检:快速缺陷检测
-
无人机应用:实时避障和目标识别
总结
YOLO V2通过一系列精心设计且相互配合的改进,成功解决了YOLO V1的多个痛点,在速度与精度之间找到了更好的平衡点。它的设计思想不仅影响了后续的YOLO系列发展,也为整个目标检测领域提供了宝贵借鉴。
YOLO V2的成功告诉我们:技术进步往往不是一蹴而就的革命,而是基于对细节的持续优化和对问题的深入思考。正是这种"积小胜为大胜"的工程思维,推动着人工智能技术不断向前发展。
希望这篇博客能帮助你全面理解YOLO V2的精髓!如果你有任何问题或想法,欢迎在评论区留言讨论~ 😊