更多干货抢先看: 大数据干货合集
Apache Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供一种HQL语言进行查询,具有扩展性好、延展性好、高容错等特点,多应用于离线数仓建设。
1. Hive架构
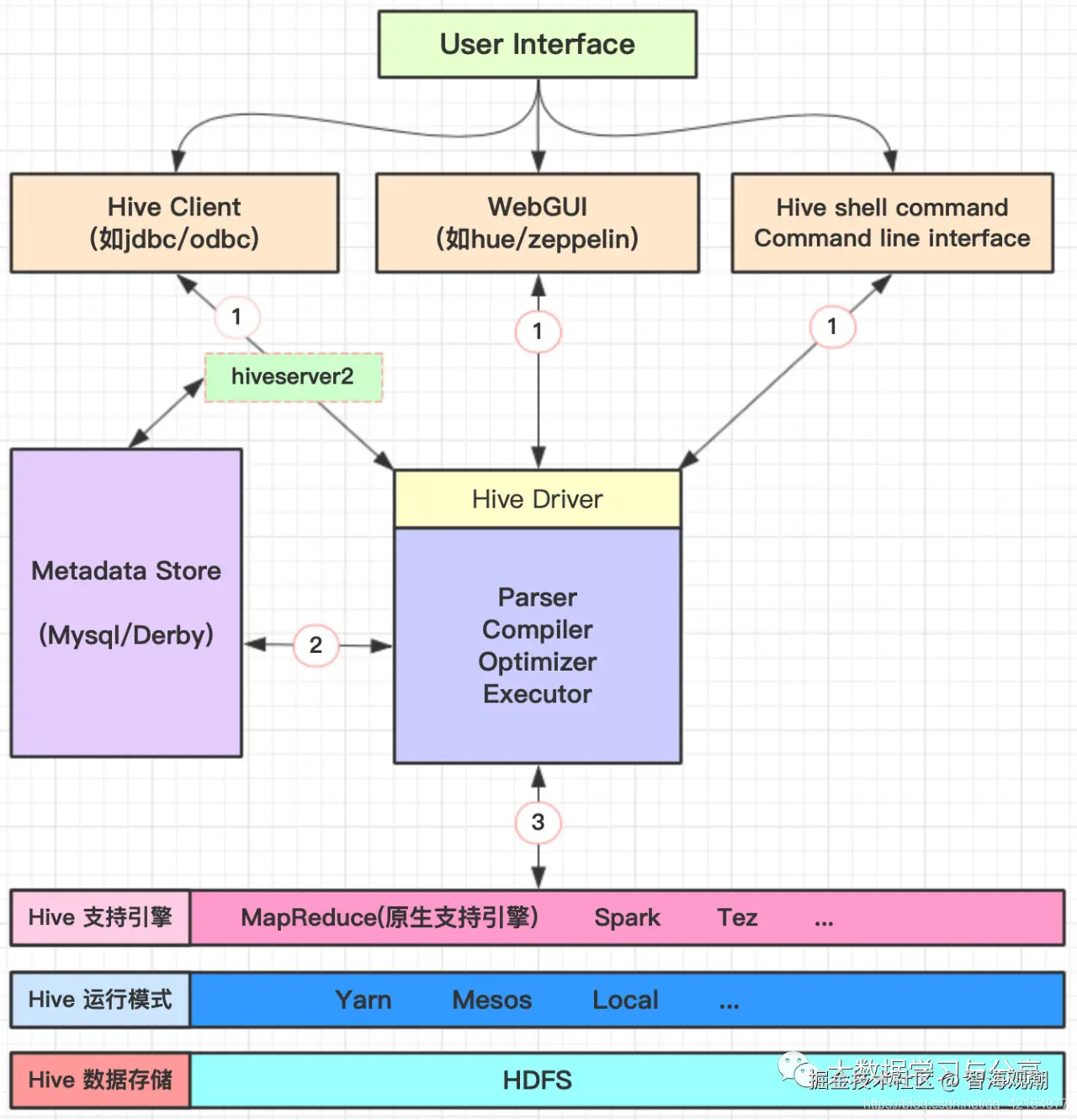
存储: Hive底层存储依赖于hdfs,因此也支持hdfs所支持的数据存储格式,如text、json、parquet等。当我们将一个文件映射为Hive中一张表时,只需在建表的时告诉Hive,数据中的列名、列分隔符、行分隔符等,Hive就可以自动解析数据。
支持多种压缩格式: bzip2、gzip、lzo、snappy等。通常采用parquet+snappy格式存储。
支持计算引擎: 原生支持引擎为MapReduce。但也支持其他计算引擎,如Spark、Tez
元数据存储: derby是Hive内置的元数据存储库,但是derby并发性能差且目前不支持多会话。实际生产中,更多的是采用mysql多为Hive的元数据存储库。
HQL语句执行: 解析器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在hdfs中,并在随后转化为MapReduce任务执行。
2.Hive的几种建表方式
1)create external table ...
css
create [external] table [if not exists] table_name
[(col_name data_type[comment col_comment],...)]
[comment table_comment]
[partitioned by (col_name data_type[comment col_comment],...)]
[clustered by (col_name,col_name,...)[sorted by (col_name[asc|desc],...)] into num_buckets buckets]
[row formatrow_format]
[stored as file_format]
[location hdfs_path];create、if not exists等跟传统的关系型数据库含义类似,就不赘述了。笔者这里主要说一下hive建表时的几个特殊关键字:
external: 创建外部表时需要指定该关键字,并通过location指定数据存储的路径
partitioned by: 创建分区表时,指定分区列。
clustered by和sort by: 通常连用,用来创建分桶表,下文会具体阐述。
row format delimited fields terminated by char collection items terminated by char map keys terminated by char lines terminated by char serde serde_name with serdeproperties (property_name=property_value, property_name=property_value, ...):指定行、字段、集合类型数据分割符、map类型数据key的分隔符等。用户在建表的时候可以使用Hive自带的serde或者自定义serde,Hive通过serde确定表具体列的数据。
stored as file_format: 指定表数据存储格式,如TextFile,SequenceFile,RCFile。默认textfile即文本格式,该方式支持通过load方式加载数据。如果数据需要压缩,则采用sequencefile方式,但这种存储方式不能通过load方式加载数据,必须从一个表中查询出数据再写入到一个表中insert overwrite table t1 select * from t1;
2) create table t_x as select ...
即ctas语句,复制数据但不复制表结构,创建的为普通表。如果复制的是分区表则新创建的不是分区表但有分区字段。 ctas语句是原子性的,如果select失败,将不再执行create操作。
3) create table t_x like t_y
like允许用户复制源表结构,但不复制数据。如,create table t2 like t1;
更多干货抢先看: 大数据干货合集