
C++专栏:C++_Yupureki的博客-CSDN博客
目录
[1.1 数据类型](#1.1 数据类型)
[1.1.1 整型家族](#1.1.1 整型家族)
[1.1.2 浮点型](#1.1.2 浮点型)
[1.1.3 查看类型范围](#1.1.3 查看类型范围)
[1.1.4 自定义类型](#1.1.4 自定义类型)
[1.2 变量和常量](#1.2 变量和常量)
[1.3 运算符](#1.3 运算符)
[2. 控制结构](#2. 控制结构)
[2.1 条件语句](#2.1 条件语句)
[2.2 循环语句](#2.2 循环语句)
[3. 函数](#3. 函数)
[3.1 函数定义和调用](#3.1 函数定义和调用)
[4. 数组和字符串(重要)](#4. 数组和字符串(重要))
[4.1 数组基础](#4.1 数组基础)
[4.2 二维数组](#4.2 二维数组)
[4.3 字符串](#4.3 字符串)
[5. 指针(重要)](#5. 指针(重要))
[5.1 指针基础](#5.1 指针基础)
[5.2 指针高级应用](#5.2 指针高级应用)
[5.2.1 指针作为函数参数](#5.2.1 指针作为函数参数)
[5.2.2 指针的指针(二级指针)](#5.2.2 指针的指针(二级指针))
[5.2.3 指针数组](#5.2.3 指针数组)
[5.2.4 数组指针](#5.2.4 数组指针)
[5.2.5 函数指针](#5.2.5 函数指针)
[5.3 数组与指针(重要)](#5.3 数组与指针(重要))
[5.3.1 数组名](#5.3.1 数组名)
[5.3.2 数组和指针笔试题解析](#5.3.2 数组和指针笔试题解析)
[6. 字符函数和字符串函数(重要)](#6. 字符函数和字符串函数(重要))
[6.1 strlen - 字符串长度计算](#6.1 strlen - 字符串长度计算)
[6.2 strcpy - 字符串复制](#6.2 strcpy - 字符串复制)
[6.3 strcmp - 字符串比较](#6.3 strcmp - 字符串比较)
[6.4 strstr - 字符串查找](#6.4 strstr - 字符串查找)
[7. 结构体和联合体](#7. 结构体和联合体)
[7.1 结构体](#7.1 结构体)
[7.1.1 结构的声明](#7.1.1 结构的声明)
[7.1.2 结构体函数](#7.1.2 结构体函数)
[7.1.3 结构体指针](#7.1.3 结构体指针)
[7.1.4 结构体数组](#7.1.4 结构体数组)
[7.2 结构体内存对齐(重要)](#7.2 结构体内存对齐(重要))
[7.2.1 为什么需要内存对齐?](#7.2.1 为什么需要内存对齐?)
[7.2.2 结构体内存对齐规则](#7.2.2 结构体内存对齐规则)
[7.3 联合体](#7.3 联合体)
[7.3.1 判断大小端](#7.3.1 判断大小端)
[7.4 枚举](#7.4 枚举)
[8. 内存函数(重要)](#8. 内存函数(重要))
[8.1 内存分配函数](#8.1 内存分配函数)
[8.1.1 malloc - 分配未初始化的内存](#8.1.1 malloc - 分配未初始化的内存)
[8.1.2 calloc - 分配并初始化为0的内存](#8.1.2 calloc - 分配并初始化为0的内存)
[8.1.3 realloc - 重新分配内存](#8.1.3 realloc - 重新分配内存)
[8.1.4 释放内存](#8.1.4 释放内存)
[8.2 memcpy和memmove](#8.2 memcpy和memmove)
[8.2.1 函数原型和基本概念](#8.2.1 函数原型和基本概念)
[8.2.2 关键区别:内存重叠处理](#8.2.2 关键区别:内存重叠处理)
[8.2.3 内存重叠示例](#8.2.3 内存重叠示例)
[8.2.4 模拟实现](#8.2.4 模拟实现)
[9. 文件操作](#9. 文件操作)
[9.1 文件的打开和关闭](#9.1 文件的打开和关闭)
[9.1.3 文件指针](#9.1.3 文件指针)
[9.2 二进制文件操作](#9.2 二进制文件操作)
[10.2 预处理阶段 (Preprocessing)](#10.2 预处理阶段 (Preprocessing))
[10.2.1 预处理的主要工作](#10.2.1 预处理的主要工作)
[条件编译 (#if, #ifdef, #ifndef)](#if, #ifdef, #ifndef))
[10.3 编译阶段 (Compilation)](#10.3 编译阶段 (Compilation))
[10.3.1 编译过程详解](#10.3.1 编译过程详解)
[10.4 汇编阶段 (Assembly)](#10.4 汇编阶段 (Assembly))
[10.4.1 目标文件的结构](#10.4.1 目标文件的结构)
[10.5 链接阶段 (Linking)](#10.5 链接阶段 (Linking))
[10.5.1 创建多个源文件示例](#10.5.1 创建多个源文件示例)
[10.5.2 分步编译链接过程](#10.5.2 分步编译链接过程)
[10.5.3 符号解析和重定位](#10.5.3 符号解析和重定位)
[10.6. 预处理中的重要细节](#10.6. 预处理中的重要细节)
[10.6.2 宏使用的注意事项](#10.6.2 宏使用的注意事项)
[10.6.3 预定义宏](#10.6.3 预定义宏)
上一篇:从零开始的C++学习生活 17:异常和智能指针-CSDN博客
前言
C++的知识学习告一段落,但是复习是不可或缺的。其中C语言更是基础中的基础,无论是准备面试、考试,还是希望夯实编程基础,系统性地复习C语言都是非常有价值的。
我将按照C语言的知识体系,从基础语法到高级特性,全面梳理核心知识点,帮助你构建完整的C语言知识框架。每个部分都配有实用的代码示例和注意事项,让复习更加高效。

1.C语言基础
1.1 数据类型
C语言提供了丰富的数据类型来描述生活中的各种数据。 使用整型类型来描述整数,使用字符类型来描述字符,使用浮点型类型来描述小数。 所谓"类型",就是相似的数据所拥有的共同特征,编译器只有知道了数据的类型,才知道怎么操作数据。
1.1.1 整型家族
cpp
char c = 'A'; // 1字节,-128到127
unsigned char uc = 255; // 1字节,0到255
short s = 32767; // 2字节,-32768到32767
int i = 2147483647; // 4字节,-2147483648到2147483647
long l = 2147483647; // 4或8字节
long long ll = 9223372036854775807; // 8字节1.1.2 浮点型
cpp
float f = 3.14159f; // 4字节,约6-7位有效数字
double d = 3.141592653589793; // 8字节,约15-16位有效数字
long double ld = 3.14159265358979323846L; // 10或16字节1.1.3 查看类型范围
cpp
printf("int范围: %d 到 %d\n", INT_MIN, INT_MAX);
printf("float精度: %d 位\n", FLT_DIG);1.1.4 自定义类型
cpp
struct Date{
int _year;
int _month;
int _day;
}重要提示:
- 注意有符号和无符号类型的区别。有符号包括我们常见的正负数,而无符号只有正数
- 浮点数比较时避免直接使用==,因为往往计算的精度不同
- 了解不同平台的类型大小差异
1.2 变量和常量
变量由数据类型和变量名组成
其中常量指具有常属性的变量,这些变量无法被更改。用define定义或者const修饰的变量为常变量
cpp
#include <stdio.h>
// 宏定义常量
#define PI 3.14159
#define MAX_SIZE 100
// const常量
const int MIN_SIZE = 10;
int main() {
// 变量声明和初始化
int count = 0;
float price = 99.99;
char grade = 'A';
// 不同类型常量
const int days_in_week = 7;
enum boolean { FALSE, TRUE };
enum boolean status = TRUE;
// 变量作用域演示
{
int local_var = 42; // 块作用域
printf("局部变量: %d\n", local_var);
}
// printf("%d\n", local_var); // 错误:local_var不可见
return 0;
}1.3 运算符
| 优先级 | 类别 | 运算符 | 名称 / 含义 | 结合性 | 用法示例 |
|---|---|---|---|---|---|
| 1 | 括号、结构体 | () [] . -> |
函数调用 数组下标 结构体成员访问 结构体指针成员访问 | 从左到右 | func() arr[5] obj.member ptr->member |
| 2 | 单目运算符 | ! ~ ++ -- + - * & (type) sizeof |
逻辑非 按位取反 自增 自减 正号 负号 解引用 取地址 强制类型转换 求类型大小 | 从右到左 | !flag ~a ++i / i++ --i / i-- +5 -10 *ptr &var (float)i sizeof(int) |
| 3 | 算术运算符 | * / % |
乘法 除法 取模(求余) | 从左到右 | a * b a / b a % b |
| 4 | 算术运算符 | + - |
加法 减法 | 从左到右 | a + b a - b |
| 5 | 位运算符 | << >> |
左移 右移 | 从左到右 | a << 2 a >> 1 |
| 6 | 关系运算符 | < <= > >= |
小于 小于等于 大于 大于等于 | 从左到右 | a < b a <= b a > b a >= b |
| 7 | 关系运算符 | == != |
等于 不等于 | 从左到右 | a == b a != b |
| 8 | 位运算符 | & |
按位与 | 从左到右 | a & b |
| 9 | 位运算符 | ^ |
按位异或 | 从左到右 | a ^ b |
| 10 | 位运算符 | ` | ` | 按位或 | 从左到右 |
| 11 | 逻辑运算符 | && |
逻辑与 | 从左到右 | a && b |
| 12 | 逻辑运算符 | ` | ` | 逻辑或 | |
| 13 | 条件运算符 | ? : |
三目条件运算符 | 从右到左 | a > b ? a : b |
| 14 | 赋值运算符 | = += -= *= /= %= &= ^= ` |
= <<= >>=` |
赋值 复合赋值 | 从右到左 |
| 15 | 逗号运算符 | , |
逗号(顺序求值) | 从左到右 | a=1, b=2 |
关键概念与注意事项
-
优先级 (Precedence):
- 当表达式中出现多个运算符时,优先级决定了谁先计算。例如,乘除 (
*,/) 的优先级高于加减 (+,-),所以a + b * c等价于a + (b * c)。
- 当表达式中出现多个运算符时,优先级决定了谁先计算。例如,乘除 (
-
结合性 (Associativity):
-
当相邻运算符的优先级相同时,结合性决定了计算顺序。
-
从左到右 :大部分运算符如此,如
a + b + c等价于(a + b) + c。 -
从右到左 :单目、赋值和三目运算符如此。如
a = b = c等价于a = (b = c)。
-
-
单目运算符的"前缀"与"后缀"
-
++和--作为前缀和后缀时,优先级不同。 -
后缀 (
i++,i--):优先级为 1,与函数调用同级。 -
前缀 (
++i,--i):优先级为 2,与其他单目运算符同级。 -
示例 :
*ptr++等价于*(ptr++),因为后缀++优先级高于解引用*。而*++ptr等价于*(++ptr)。
-
-
"短路求值 (Short-Circuit Evaluation)"
-
逻辑与 (
&&) 和逻辑或 (||) 具有此特性。 -
对于
a && b,如果a为假,则整个表达式结果已确定为假,不再计算b。 -
对于
a || b,如果a为真,则整个表达式结果已确定为真,不再计算b。
-
-
运算符的"重载"
-
某些符号根据上下文有不同的含义。
-
*:乘法 (a * b) 或 解引用 (*ptr)。 -
&:按位与 (a & b) 或 取地址 (&var)。 -
-:减法 (a - b) 或 负号 (-5)。
-
2. 控制结构
2.1 条件语句
C语言提供if-else语句和switch语句来控制代码的执行
cpp
#include <stdio.h>
int main() {
int score = 85;
// if-else语句
if (score >= 90) {
printf("优秀\n");
} else if (score >= 80) {
printf("良好\n");
} else if (score >= 60) {
printf("及格\n");
} else {
printf("不及格\n");
}
// switch语句
char grade = 'B';
switch (grade) {
case 'A':
printf("优秀\n");
break;
case 'B':
printf("良好\n");
break;
case 'C':
printf("及格\n");
break;
default:
printf("不及格\n");
}
// 条件运算符(三元运算符)
int max = (a > b) ? a : b;
printf("较大值: %d\n", max);
return 0;
}2.2 循环语句
C语言提供while,do-while和for语句来使一段代码循环执行
cpp
#include <stdio.h>
int main() {
int i;
// for循环
printf("for循环: ");
for (i = 0; i < 5; i++) {
printf("%d ", i);
}
printf("\n");
// while循环
printf("while循环: ");
i = 0;
while (i < 5) {
printf("%d ", i);
i++;
}
printf("\n");
// do-while循环
printf("do-while循环: ");
i = 0;
do {
printf("%d ", i);
i++;
} while (i < 5);
printf("\n");
// 循环控制:break和continue
printf("break示例: ");
for (i = 0; i < 10; i++) {
if (i == 5) break; // 跳出循环
printf("%d ", i);
}
printf("\n");
printf("continue示例: ");
for (i = 0; i < 5; i++) {
if (i == 2) continue; // 跳过本次循环
printf("%d ", i);
}
printf("\n");
return 0;
}3. 函数
3.1 函数定义和调用
我们日常所执行的程序都在函数内执行。同时函数之间也能相互调用
函数包括返回值,函数名,参数列表和函数体
函数声明(原型)
cpp
int add(int a, int b);
void print_hello();
int factorial(int n);函数定义
cpp
int add(int a, int b) {
return a + b;
}函数参数传递:值传递
cpp
void swap_wrong(int a, int b) {
int temp = a;
a = b;
b = temp;
printf("函数内: a=%d, b=%d\n", a, b);
}函数调用
cpp
int result = add(5, 3);
printf("5 + 3 = %d\n", result);4. 数组和字符串(重要)
4.1 数组基础
数组是⼀组相同类型元素的集合
在内存中,数组是连续开辟的一段空间,因此数组中的每个元素都是紧挨着的
cpp
int numbers[] = {5, 2, 8, 1, 9};在数组中,下标并不等同于我们所认定的序号,第一个元素下标为0,以此开始
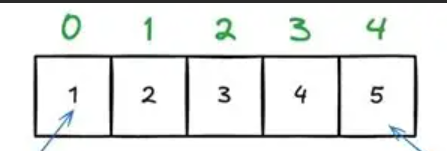
4.2 二维数组
其实二维数组访问也是使用下标的形式的,二维数组是有行和列的,只要锁定了行和列就能唯一锁定数组中的一个元素。
cpp
int arr[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};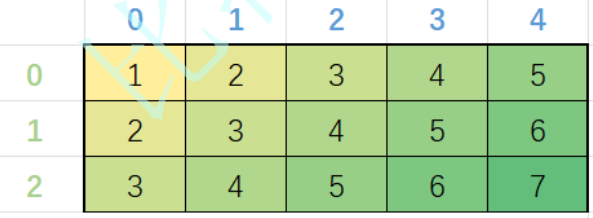
4.3 字符串
其实可以把字符串看作是一种数组,但是对于对于字符串的访问可以直接通过数组首地址来访问,直到遇到尾部的\0停止,因此\0必须存在于字符串中
对于字符数组,末尾添加\0也是必要的
cpp
#include <stdio.h>
#include <string.h>
int main() {
// 字符串初始化
char str1[] = "Hello"; // 自动包含'\0'
char str2[10] = "World";
char str3[] = {'H', 'i', '\0'}; // 手动添加'\0'
// 字符串操作
printf("str1: %s\n", str1);
printf("str1长度: %lu\n", strlen(str1));
// 字符串复制
char copy[10];
strcpy(copy, str1);
printf("复制后: %s\n", copy);
// 字符串连接
strcat(copy, " ");
strcat(copy, str2);
printf("连接后: %s\n", copy);
// 字符串比较
printf("比较str1和str2: %d\n", strcmp(str1, str2));
// 字符串查找
char *pos = strchr(str1, 'l');
if (pos) {
printf("找到字符'l'在位置: %ld\n", pos - str1);
}
// 安全的字符串函数(C11)
char buffer[10];
strncpy(buffer, "Hello World", sizeof(buffer) - 1);
buffer[sizeof(buffer) - 1] = '\0'; // 确保以'\0'结尾
printf("安全复制: %s\n", buffer);
return 0;
}5. 指针(重要)
5.1 指针基础
指针严格来说是指针变量,有自己的类型和值,在内存中开辟了空间
而指针变量的值就是变量的地址,即内存编号
cpp
#include <stdio.h>
int main() {
int num = 42;
int *ptr = # // ptr指向num的地址
printf("变量值: %d\n", num);
printf("变量地址: %p\n", &num);
printf("指针值: %p\n", ptr);
printf("指针指向的值: %d\n", *ptr); // 解引用
// 指针运算
int arr[] = {10, 20, 30, 40, 50};
int *arr_ptr = arr;
printf("\n数组元素:\n");
for (int i = 0; i < 5; i++) {
printf("arr[%d] = %d, *(arr_ptr + %d) = %d\n",
i, arr[i], i, *(arr_ptr + i));
}
// 指针和数组的关系
printf("\n指针和数组:\n");
printf("arr = %p\n", arr);
printf("&arr[0] = %p\n", &arr[0]);
printf("arr_ptr = %p\n", arr_ptr);
return 0;
}5.2 指针高级应用
5.2.1 指针作为函数参数
函数参数传递的是形参,在函数体内对形参的改变不会影响外部的实参。因此如果要改变实参,就得传递指针
cpp
void modify_value(int *ptr) {
*ptr = 100; // 修改指针指向的值
}5.2.2 指针的指针(二级指针)
我们说过,指针也是变量,因此也可以创建指向指针的指针,俗称二级指针
二级指针可以改变一级指针指向哪个元素
cpp
void pointer_to_pointer_demo() {
int value = 42;
int *ptr = &value;
int **pptr = &ptr;
printf("\n指向指针的指针:\n");
printf("value = %d\n", value);
printf("*ptr = %d\n", *ptr);
printf("**pptr = %d\n", **pptr);
}5.2.3 指针数组
指针数组指的是一个数组中存的的元素每个都是指针
由于\[\]的优先级比*高,因此ptr_arr被优先为数组
cpp
void pointer_array_demo() {
int a = 1, b = 2, c = 3;
int *ptr_arr[] = {&a, &b, &c};
printf("指针数组:\n");
for (int i = 0; i < 3; i++) {
printf("ptr_arr[%d] = %p, *ptr_arr[%d] = %d\n",
i, ptr_arr[i], i, *ptr_arr[i]);
}
}5.2.4 数组指针
数组指针是一个指针,指向的是整个数组
cpp
int arr[10] = {0}
int (*p)[10] = &arr;由于p指向的是整个数组,因此p解引用不是arr的首元素,而是整个数组,加1和减1也是跳过一整个数组
5.2.5 函数指针
函数指针指向函数,可以调用函数
cpp
int add(int a, int b) { return a + b; }
int subtract(int a, int b) { return a - b; }
int multiply(int a, int b) { return a * b; }
void function_pointer_demo() {
// 函数指针声明
int (*operation)(int, int);
operation = add;
printf("加法: %d\n", operation(5, 3));
operation = subtract;
printf("减法: %d\n", operation(5, 3));
operation = multiply;
printf("乘法: %d\n", operation(5, 3));
}5.3 数组与指针(重要)
5.3.1 数组名
数组名是数组首元素的地址
只有两种情况下数组名不是数组首元素的地址
- sizeof(数组名)中数组名表示的是整个数组,计算的是整个数组的大小
2.&数组名取出的是整个数组,也就是数组指针
5.3.2 数组和指针笔试题解析
一维数组
cpp
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a));//16
printf("%d\n",sizeof(a+0));//4
printf("%d\n",sizeof(*a));//4
printf("%d\n",sizeof(a+1));//4
printf("%d\n",sizeof(a[1]));//4
printf("%d\n",sizeof(&a));//4
printf("%d\n",sizeof(*&a));//16
printf("%d\n",sizeof(&a+1));//4
printf("%d\n",sizeof(&a[0]));//4
printf("%d\n",sizeof(&a[0]+1));//4逐行分析
printf("%d\n",sizeof(a));
-
a作为数组名,单独出现在sizeof中,表示整个数组 -
结果 :
16(4个int × 4字节)
printf("%d\n",sizeof(a+0));
-
a+0中,数组名a退化为指向首元素的指针(int*) -
a+0仍然是int*类型 -
结果 :
4(32位系统下指针的大小)
printf("%d\n",sizeof(*a));
-
*a等价于a[0],即数组的第一个元素 -
类型是
int -
结果 :
4(int类型的大小)
printf("%d\n",sizeof(a+1));
-
a+1中,a退化为指针,指向第二个元素 -
类型是
int* -
结果 :
4(指针大小)
printf("%d\n",sizeof(a[1]));
-
a[1]是数组的第二个元素 -
类型是
int -
结果 :
4
printf("%d\n",sizeof(&a));
-
&a是取整个数组的地址 -
类型是
int(*)[4](指向包含4个int的数组的指针) -
但仍然是指针,所有数据指针在32位系统都是4字节
-
结果 :
4
printf("%d\n",sizeof(*&a));
-
*&a先取数组地址再解引用,等价于a -
所以就是整个数组
-
结果 :
16
printf("%d\n",sizeof(&a+1));
-
&a+1指向数组末尾的下一个位置 -
类型仍然是
int(*)[4] -
结果 :
4(指针大小)
printf("%d\n",sizeof(&a[0]));
-
&a[0]取第一个元素的地址 -
类型是
int* -
结果 :
4
printf("%d\n",sizeof(&a[0]+1));
-
&a[0]+1指向第二个元素 -
类型是
int* -
结果 :
4
二维数组
cpp
int a[3][4] = {0};
printf("%d\n",sizeof(a));//48
printf("%d\n",sizeof(a[0][0]));//4
printf("%d\n",sizeof(a[0]));//16
printf("%d\n",sizeof(a[0]+1));//4
printf("%d\n",sizeof(*(a[0]+1)));//4
printf("%d\n",sizeof(a+1));//4
printf("%d\n",sizeof(*(a+1)));//4
printf("%d\n",sizeof(&a[0]+1));//4
printf("%d\n",sizeof(*(&a[0]+1)));//16
printf("%d\n",sizeof(*a));//16
printf("%d\n",sizeof(a[3]));//16逐行分析
printf("%d\n",sizeof(a));
-
a作为二维数组名,单独出现在sizeof中,表示整个二维数组 -
结果 :
48(3×4=12个int × 4字节)
printf("%d\n",sizeof(a[0][0]));
-
a[0][0]是第一行第一列的元素 -
类型是
int -
结果 :
4(int类型的大小)
printf("%d\n",sizeof(a[0]));
-
a[0]是第一行的数组名,单独出现在sizeof中 -
类型是
int[4](包含4个int的一维数组) -
结果 :
16(4个int × 4字节)
printf("%d\n",sizeof(a[0]+1));
-
a[0]+1中,a[0]退化为指向第一行第一个元素的指针(int*) -
a[0]+1指向第一行的第二个元素 -
类型是
int* -
结果 :
4(指针大小)
printf("%d\n",sizeof(*(a[0]+1)));
-
*(a[0]+1)解引用得到第一行第二个元素的值 -
类型是
int -
结果 :
4
printf("%d\n",sizeof(a+1));
-
a+1中,二维数组名a退化为指向第一行的指针(int(*)[4]) -
a+1指向第二行 -
类型是
int(*)[4] -
结果 :
4(指针大小)
printf("%d\n",sizeof(*(a+1)));
-
*(a+1)解引用得到第二行 -
类型是
int[4](包含4个int的一维数组) -
结果 :
16(4个int × 4字节)
printf("%d\n",sizeof(&a[0]+1));
-
&a[0]取第一行的地址,类型是int(*)[4] -
&a[0]+1指向第二行 -
类型是
int(*)[4] -
结果 :
4(指针大小)
printf("%d\n",sizeof(*(&a[0]+1)));
-
*(&a[0]+1)解引用得到第二行 -
类型是
int[4] -
结果 :
16
printf("%d\n",sizeof(*a));
-
*a中,a退化为指向第一行的指针,解引用得到第一行 -
类型是
int[4] -
结果 :
16
printf("%d\n",sizeof(a[3]));
-
a[3]是访问第四行(数组越界),但sizeof在编译时确定类型 -
a[3]的类型是int[4] -
结果 :
16(编译时根据类型确定,不实际访问内存)
6. 字符函数和字符串函数(重要)
6.1 strlen - 字符串长度计算
cpp
#include <string.h>
size_t strlen(const char *str);strlen用来计算一个字符串的长度,即从头开始直到遇到\0,计算这之间的长度,但是不计入\0的长度
示例
cpp
#include <stdio.h>
#include <string.h>
int main() {
char str[] = "Hello, World!";
printf("字符串长度: %zu\n", strlen(str)); // 输出: 13
return 0;
}模拟实现
cpp
// 方法1: 计数器方式
size_t my_strlen1(const char *str) {
size_t count = 0;
while (*str != '\0') {
count++;
str++;
}
return count;
}
// 方法2: 指针相减方式
size_t my_strlen2(const char *str) {
const char *start = str;
while (*str != '\0') {
str++;
}
return str - start;
}
// 方法3: 递归方式
size_t my_strlen3(const char *str) {
if (*str == '\0') {
return 0;
}
return 1 + my_strlen3(str + 1);
}6.2 strcpy - 字符串复制
cpp
#include <string.h>
char *strcpy(char *dest, const char *src);示例
cpp
#include <stdio.h>
#include <string.h>
int main() {
char src[] = "Hello, World!";
char dest[20];
strcpy(dest, src);
printf("复制后的字符串: %s\n", dest); // 输出: Hello, World!
return 0;
}模拟实现
cpp
// 基础版本
char *my_strcpy1(char *dest, const char *src) {
char *ret = dest;
while (*src != '\0') {
*dest = *src;
dest++;
src++;
}
*dest = '\0'; // 添加字符串结束符
return ret;
}
// 简化版本
char *my_strcpy2(char *dest, const char *src) {
char *ret = dest;
while ((*dest++ = *src++) != '\0') {
// 空循环体
}
return ret;
}
// 更简洁版本
char *my_strcpy3(char *dest, const char *src) {
char *ret = dest;
while (*dest++ = *src++) {
// 空循环体
}
return ret;
}6.3 strcmp - 字符串比较
cpp
#include <string.h>
int strcmp(const char *str1, const char *str2);返回值:
-
< 0:str1 < str2 -
= 0:str1 = str2 -
> 0:str1 > str2
示例
cpp
#include <stdio.h>
#include <string.h>
int main() {
char str1[] = "apple";
char str2[] = "banana";
char str3[] = "apple";
printf("str1 vs str2: %d\n", strcmp(str1, str2)); // 负数
printf("str1 vs str3: %d\n", strcmp(str1, str3)); // 0
printf("str2 vs str1: %d\n", strcmp(str2, str1)); // 正数
return 0;
}模拟实现
cpp
// 标准实现
int my_strcmp1(const char *str1, const char *str2) {
while (*str1 && *str2 && *str1 == *str2) {
str1++;
str2++;
}
return *(unsigned char*)str1 - *(unsigned char*)str2;
}
// 更易理解的版本
int my_strcmp2(const char *str1, const char *str2) {
while (*str1 != '\0' && *str2 != '\0') {
if (*str1 != *str2) {
return *str1 - *str2;
}
str1++;
str2++;
}
// 处理一个字符串已结束的情况
if (*str1 == '\0' && *str2 == '\0') {
return 0;
} else if (*str1 == '\0') {
return -1;
} else {
return 1;
}
}6.4 strstr - 字符串查找
cpp
#include <string.h>
char *strstr(const char *haystack, const char *needle);示例
cpp
#include <stdio.h>
#include <string.h>
int main() {
char str[] = "Hello, World! Welcome to C programming.";
char substr[] = "World";
char *result = strstr(str, substr);
if (result != NULL) {
printf("找到子串: %s\n", result); // 输出: World! Welcome to C programming.
printf("位置: %ld\n", result - str); // 输出: 7
} else {
printf("未找到子串\n");
}
return 0;
}模拟实现
cpp
// 暴力匹配算法
char *my_strstr1(const char *haystack, const char *needle) {
if (*needle == '\0') {
return (char*)haystack;
}
const char *h = haystack;
const char *n = needle;
while (*h != '\0') {
const char *h_pos = h;
n = needle;
// 尝试匹配
while (*h_pos != '\0' && *n != '\0' && *h_pos == *n) {
h_pos++;
n++;
}
// 如果needle完全匹配
if (*n == '\0') {
return (char*)h;
}
// 如果haystack已到结尾
if (*h_pos == '\0') {
return NULL;
}
h++;
}
return NULL;
}
// 更简洁的版本
char *my_strstr2(const char *haystack, const char *needle) {
if (*needle == '\0') return (char*)haystack;
for (int i = 0; haystack[i] != '\0'; i++) {
int j = 0;
while (needle[j] != '\0' && haystack[i + j] == needle[j]) {
j++;
}
if (needle[j] == '\0') {
return (char*)(haystack + i);
}
}
return NULL;
}7. 结构体和联合体
7.1 结构体
7.1.1 结构的声明
cpp
struct tag
{
member-list;
}variable-list;例如描述⼀个学生:
cpp
struct Student {
char name[50];
int age;
float score;
};7.1.2 结构体函数
结构体对象使用 **.**来访问成员变量
cpp
void print_student(struct Student s) {
printf("姓名: %s, 年龄: %d, 分数: %.2f\n",
s.name, s.age, s.score);
}7.1.3 结构体指针
结构体的指针用**->**来访问成员变量
cpp
void modify_student(struct Student *s) {
strcpy(s->name, "修改后的名字");
s->age = 25;
s->score = 95.5;
}7.1.4 结构体数组
cpp
void struct_array_demo() {
struct Student class[3] = {
{"张三", 20, 88.5},
{"李四", 21, 92.0},
{"王五", 19, 76.5}
};
printf("\n学生信息:\n");
for (int i = 0; i < 3; i++) {
print_student(class[i]);
}
}7.2 结构体内存对齐(重要)
7.2.1 为什么需要内存对齐?
内存对齐是为了提高CPU访问内存的效率。大多数CPU访问对齐的数据(地址是数据大小的整数倍)比访问非对齐的数据要快得多。
7.2.2 结构体内存对齐规则
基本规则
-
第一个成员:从结构体起始地址的0偏移处开始
-
其他成员 :对齐到
min(#pragma pack指定的数值, 这个成员自身长度)的整数倍地址 -
结构体总大小 :必须是
min(#pragma pack指定的数值, 最大成员长度)的整数倍 -
默认对齐值:visual studio中默认为8
示例分析
示例1:基础结构体
cpp
#include <stdio.h>
struct Example1 {
char a; // 1字节
int b; // 4字节
short c; // 2字节
};
int main() {
printf("sizeof(struct Example1) = %zu\n", sizeof(struct Example1));
return 0;
}内存布局分析:
偏移地址: 0 1 2 3 4 5 6 7 8 9 10 11
成员: [a] 填充 填充 填充 [b] [b] [b] [b] [c] [c] 填充 填充
大小: 1字节 + 3字节填充 + 4字节 + 2字节 + 2字节填充 = 12字节示例2:调整成员顺序优化
cpp
struct Example2 {
char a; // 1字节
short c; // 2字节
int b; // 4字节
};
int main() {
printf("sizeof(struct Example2) = %zu\n", sizeof(struct Example2));
return 0;
}优化后的内存布局:
cpp
偏移地址: 0 1 2 3 4 5 6 7
成员: [a] 填充 [c] [c] [b] [b] [b] [b]
大小: 1字节 + 1字节填充 + 2字节 + 4字节 = 8字节复杂结构体示例
示例4:嵌套结构体
cpp
struct Inner {
char x; // 1字节
double y; // 8字节
}; // 大小: 16字节
struct Outer {
char a; // 1字节
struct Inner b; // 16字节
int c; // 4字节
};
int main() {
printf("sizeof(Inner) = %zu\n", sizeof(struct Inner));
printf("sizeof(Outer) = %zu\n", sizeof(struct Outer));
return 0;
}内存分析:
Outer布局:
[char a] + 7字节填充 + [Inner结构体(16字节)] + [int c] + 4字节填充 = 32字节7.3 联合体
像结构体一样,联合体也是由⼀个或者多个成员构成,这些成员可以不同的类型。
但是编译器只为最大的成员分配足够的内存空间。联合体的特点是所有成员共用同⼀块内存空间所
以联合体也叫:共用体。 给联合体其中⼀个成员赋值,其他成员的值也跟着变化。
cpp
union Data {
int i;
float f;
char str[20];
};7.3.1 判断大小端
cpp
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;//返回1是⼩端,返回0是⼤端
}7.4 枚举
枚举顾名思义就是一一列举。
cpp
enum Color { RED, GREEN, BLUE };
enum Week { MON = 1, TUE, WED, THU, FRI, SAT, SUN };
cpp
// 枚举使用
enum Color c = RED;
enum Week today = WED;
printf("颜色: %d\n", c);
printf("今天是星期: %d\n", today);8. 内存函数(重要)
8.1 内存分配函数
8.1.1 malloc - 分配未初始化的内存
cpp
int *arr1 = (int*)malloc(5 * sizeof(int));
if (arr1 == NULL) {
printf("内存分配失败\n");
return 1;
}
// 使用分配的内存
for (int i = 0; i < 5; i++) {
arr1[i] = i * 10;
}
printf("malloc分配数组: ");
for (int i = 0; i < 5; i++) {
printf("%d ", arr1[i]);
}
printf("\n");8.1.2 calloc - 分配并初始化为0的内存
cpp
int *arr2 = (int*)calloc(5, sizeof(int));
printf("calloc分配数组(初始为0): ");
for (int i = 0; i < 5; i++) {
printf("%d ", arr2[i]);
}
printf("\n");8.1.3 realloc - 重新分配内存
cpp
arr1 = (int*)realloc(arr1, 10 * sizeof(int));
for (int i = 5; i < 10; i++) {
arr1[i] = i * 10;
}
printf("realloc扩展后数组: ");
for (int i = 0; i < 10; i++) {
printf("%d ", arr1[i]);
}
printf("\n");8.1.4 释放内存
cpp
free(arr1);
free(arr2);8.2 memcpy和memmove
8.2.1 函数原型和基本概念
函数原型
cpp
#include <string.h>
void *memcpy(void *dest, const void *src, size_t n);
void *memmove(void *dest, const void *src, size_t n);基本功能
两个函数都用于从源内存区域复制n个字节到目标内存区域。
8.2.2 关键区别:内存重叠处理
| 特性 | memcpy | memmove |
|---|---|---|
| 内存重叠处理 | 不处理,行为未定义 | 安全处理,保证正确复制 |
| 性能 | 通常更快 | 稍慢(需要额外检查) |
| 使用场景 | 确定内存不重叠时 | 不确定内存是否重叠时 |
memcpy从source的位置开始向后复制num个字节的数据到destination指向的内存位置。
这个函数在遇到 '\0' 的时候并不会停下来。
如果source和destination有任何的重叠,复制的结果都是未定义的,因此需要memmove来处理。
8.2.3 内存重叠示例
cpp
#include <stdio.h>
#include <string.h>
int main() {
char str1[] = "Hello, World!";
char str2[] = "Hello, World!";
// 内存重叠情况:目标在源之后
printf("原始字符串: %s\n", str1);
// 使用memcpy(可能有问题)
memcpy(str1 + 7, str1, 6);
printf("memcpy结果: %s\n", str1);
// 使用memmove(安全)
memmove(str2 + 7, str2, 6);
printf("memmove结果: %s\n", str2);
return 0;
}输出结果可能不同,因为memcpy在重叠时的行为是未定义的。
8.2.4 模拟实现
memcpy的模拟实现
cpp
// 基础版本 - 逐字节复制
void *my_memcpy(void *dest, const void *src, size_t n) {
if (dest == NULL || src == NULL) {
return NULL;
}
char *d = (char *)dest;
const char *s = (const char *)src;
for (size_t i = 0; i < n; i++) {
d[i] = s[i];
}
return dest;
}
// 优化版本 - 使用字长复制(假设系统为32位)
void *my_memcpy_optimized(void *dest, const void *src, size_t n) {
if (dest == NULL || src == NULL || n == 0) {
return dest;
}
char *d = (char *)dest;
const char *s = (const char *)src;
// 按字节复制直到对齐边界
while (((uintptr_t)d % sizeof(int)) != 0 && n > 0) {
*d++ = *s++;
n--;
}
// 按字长(4字节)复制
int *d_int = (int *)d;
const int *s_int = (const int *)s;
while (n >= sizeof(int)) {
*d_int++ = *s_int++;
n -= sizeof(int);
}
// 复制剩余的字节
d = (char *)d_int;
s = (const char *)s_int;
while (n > 0) {
*d++ = *s++;
n--;
}
return dest;
}memmove的模拟实现
cpp
// memmove的模拟实现 - 处理内存重叠
void *my_memmove(void *dest, const void *src, size_t n) {
if (dest == NULL || src == NULL || n == 0) {
return dest;
}
char *d = (char *)dest;
const char *s = (const char *)src;
// 判断内存是否重叠以及重叠的方式
if (d < s) {
// 目标在源之前,从前往后复制(不会覆盖未复制数据)
for (size_t i = 0; i < n; i++) {
d[i] = s[i];
}
} else if (d > s) {
// 目标在源之后,从后往前复制(避免覆盖未复制数据)
for (size_t i = n; i > 0; i--) {
d[i - 1] = s[i - 1];
}
}
// 如果地址相等,不需要复制
return dest;
}
// 更简洁的memmove实现
void *my_memmove_simple(void *dest, const void *src, size_t n) {
if (dest == NULL || src == NULL || n == 0) {
return dest;
}
char *d = (char *)dest;
const char *s = (const char *)src;
// 创建临时缓冲区避免重叠问题
char *temp = (char *)malloc(n);
if (temp == NULL) {
return NULL; // 内存分配失败
}
// 先复制到临时缓冲区
for (size_t i = 0; i < n; i++) {
temp[i] = s[i];
}
// 再从临时缓冲区复制到目标
for (size_t i = 0; i < n; i++) {
d[i] = temp[i];
}
free(temp);
return dest;
}9. 文件操作
9.1 文件的打开和关闭
9.1.1流和标准流
C语言中,所有的I/O操作都是通过"流"来进行的。流是数据在输入输出设备之间流动的抽象概念。
一般情况下,我们要向流里写入数据或读取数据,都需要打开流
9.1.2标准流
stdin:标准输入流(键盘)
stdout:标准输出流(屏幕)
stderr:标准错误流(屏幕)
我们使用scanf利用键盘读取数据,所利用的就是stdin标准输入流
我们使用printf向屏幕输出数据,所利用的就是stdout标准输出流
而C语言默认打开了这三个流,因此我们无需说明打开什么流,系统会默认为我们操作
9.1.3 文件指针
我们通过FILE*类型的指针来操作文件。
写入文件
cpp
FILE *file;
char buffer[100];
file = fopen("example.txt", "w");
if (file == NULL) {
printf("无法打开文件\n");
return 1;
}读取文件
cpp
file = fopen("example.txt", "r");
if (file == NULL) {
printf("无法打开文件\n");
return 1;
}关闭文件
cpp
fclose(file);9.2 二进制文件操作
cpp
struct Student {
char name[50];
int age;
float score;
};
struct Student students[3] = {
{"张三", 20, 88.5},
{"李四", 21, 92.0},
{"王五", 19, 76.5}
};
// 写入二进制文件
file = fopen("students.dat", "wb");
if (file) {
fwrite(students, sizeof(struct Student), 3, file);
fclose(file);
}
// 读取二进制文件
struct Student read_students[3];
file = fopen("students.dat", "rb");
if (file) {
fread(read_students, sizeof(struct Student), 3, file);
fclose(file);
printf("\n从二进制文件读取的学生信息:\n");
for (int i = 0; i < 3; i++) {
printf("姓名: %s, 年龄: %d, 分数: %.2f\n",
read_students[i].name,
read_students[i].age,
read_students[i].score);
}10.编译与链接
10.1编译过程的四个主要阶段
源代码(.c) → 预处理(.i) → 编译(.s) → 汇编(.o) → 链接(可执行文件)10.2 预处理阶段 (Preprocessing)
预处理是编译过程的第一步,由预处理器完成。
10.2.1 预处理的主要工作
头文件包含 (#include)
预处理阶段编译器会将包含的头文件展开到.c文件中,可以理解为复制粘贴
cpp
// 示例:math_utils.h
#ifndef MATH_UTILS_H
#define MATH_UTILS_H
#define PI 3.14159
double circle_area(double radius);
double circle_circumference(double radius);
#endif
cpp
// main.c
#include <stdio.h> // 系统头文件
#include "math_utils.h" // 用户头文件
int main() {
double r = 5.0;
printf("面积: %.2f\n", circle_area(r));
return 0;
}预处理后:
cpp
// 预处理后的main.i文件(简化版)
// stdio.h的数千行代码被插入到这里
// math_utils.h的内容被插入到这里
double circle_area(double radius);
double circle_circumference(double radius);
int main() {
double r = 5.0;
printf("面积: %.2f\n", circle_area(r));
return 0;
}宏定义和展开 (#define)
编译器会将宏的内容直接覆盖到代码中
cpp
#include <stdio.h>
#define MAX(a, b) ((a) > (b) ? (a) : (b))
#define SQUARE(x) ((x) * (x))
#define DEBUG 1
int main() {
int x = 5, y = 10;
#if DEBUG
printf("调试信息: x=%d, y=%d\n", x, y);
#endif
printf("较大值: %d\n", MAX(x, y));
printf("平方: %d\n", SQUARE(x + 1)); // 展开为 ((x + 1) * (x + 1))
return 0;
}预处理后:
cpp
// stdio.h内容...
int main() {
int x = 5, y = 10;
printf("调试信息: x=%d, y=%d\n", x, y);
printf("较大值: %d\n", ((x) > (y) ? (x) : (y)));
printf("平方: %d\n", ((x + 1) * (x + 1)));
return 0;
}条件编译 (#if, #ifdef, #ifndef)
cpp
#include <stdio.h>
#define VERSION 2
#define DEBUG
int main() {
#if VERSION == 1
printf("版本1\n");
#elif VERSION == 2
printf("版本2\n");
#else
printf("未知版本\n");
#endif
#ifdef DEBUG
printf("调试模式开启\n");
#endif
#ifndef RELEASE
printf("不是发布版本\n");
#endif
return 0;
}其他预处理指令
cpp
#include <stdio.h>
// #error 在条件不满足时报错
#ifndef __STDC__
#error "需要ANSI C编译器"
#endif
// #pragma 编译器特定指令
#pragma pack(1) // 设置结构体对齐方式
// #line 改变行号信息
#line 100 "myfile.c"
int main() {
printf("当前行号: %d\n", __LINE__);
printf("文件名: %s\n", __FILE__);
return 0;
}10.3 编译阶段 (Compilation)
编译阶段将预处理后的C代码转换为汇编代码。
10.3.1 编译过程详解
cpp
// 示例代码:compute.c
int add(int a, int b) {
return a + b;
}
double multiply(double x, double y) {
return x * y;
}
int main() {
int result = add(5, 3);
double product = multiply(2.5, 4.0);
return 0;
}编译为汇编代码:
gcc -S compute.c -o compute.s生成的汇编代码示例(x86架构):
cpp
.file "compute.c"
.text
.globl add
.type add, @function
add:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %edx
movl -8(%rbp), %eax
addl %edx, %eax
popq %rbp
ret
.size add, .-add
.globl multiply
.type multiply, @function
multiply:
// ... 类似代码
.size multiply, .-multiply
.globl main
.type main, @function
main:
// ... 主函数代码
.size main, .-main10.4 汇编阶段 (Assembly)
汇编阶段将汇编代码转换为机器代码(目标文件)。
10.4.1 目标文件的结构
cpp
# 生成目标文件
gcc -c compute.s -o compute.o
# 查看目标文件信息
objdump -t compute.o # 符号表
nm compute.o # 符号表(另一种格式)
readelf -h compute.o # ELF头信息目标文件包含:
-
代码段(.text):编译后的机器指令
-
数据段(.data):已初始化的全局变量
-
BSS段(.bss):未初始化的全局变量
-
符号表:函数和变量名及其地址信息
-
重定位表:需要链接时解析的符号引用
10.5 链接阶段 (Linking)
链接阶段将一个或多个目标文件与库文件合并,生成可执行文件。
链接过程详解
10.5.1 创建多个源文件示例
math_ops.c:
cpp
#include "math_ops.h"
int add(int a, int b) {
return a + b;
}
int subtract(int a, int b) {
return a - b;
}math_ops.h:
cpp
#ifndef MATH_OPS_H
#define MATH_OPS_H
int add(int a, int b);
int subtract(int a, int b);
#endifmain.c:
cpp
#include <stdio.h>
#include "math_ops.h"
int main() {
int x = 10, y = 5;
printf("%d + %d = %d\n", x, y, add(x, y));
printf("%d - %d = %d\n", x, y, subtract(x, y));
return 0;
}10.5.2 分步编译链接过程
cpp
# 1. 预处理
gcc -E main.c -o main.i
gcc -E math_ops.c -o math_ops.i
# 2. 编译为汇编代码
gcc -S main.i -o main.s
gcc -S math_ops.i -o math_ops.s
# 3. 汇编为目标文件
gcc -c main.s -o main.o
gcc -c math_ops.s -o math_ops.o
# 4. 链接为可执行文件
gcc main.o math_ops.o -o program
# 或者一步完成
gcc main.c math_ops.c -o program10.5.3 符号解析和重定位
查看符号表:
cpp
# 查看目标文件中的符号
nm main.o
nm math_ops.o
# 查看可执行文件中的符号
nm program输出示例:
cpp
main.o:
U add # 未定义符号,需要链接时解析
U printf # 未定义符号,来自C标准库
0000000000000000 T main # 已定义符号
math_ops.o:
0000000000000000 T add # 已定义符号
0000000000000014 T subtract # 已定义符号
program:
0000000000001139 T add # 链接后已解析
000000000000114d T main
0000000000001159 T subtract
U printf@@GLIBC_2.2.5 # 动态链接符号10.6. 预处理中的重要细节
10.6.1防止头文件重复包含
cpp
// math.h
#ifndef MATH_H
#define MATH_H
// 头文件内容...
#endif10.6.2 宏使用的注意事项
cpp
// 错误的宏定义
#define SQUARE(x) x * x
// 问题:SQUARE(1+2) 展开为 1+2*1+2 = 5,而不是9
// 正确的宏定义
#define SQUARE(x) ((x) * (x))
// 多行宏定义
#define SWAP(a, b) do { \
typeof(a) temp = a; \
a = b; \
b = temp; \
} while(0)10.6.3 预定义宏
cpp
#include <stdio.h>
int main() {
printf("文件名: %s\n", __FILE__);
printf("行号: %d\n", __LINE__);
printf("编译日期: %s\n", __DATE__);
printf("编译时间: %s\n", __TIME__);
printf("函数名: %s\n", __func__);
#ifdef __STDC__
printf("ANSI C兼容: %d\n", __STDC__);
#endif
return 0;
}