交叉熵(Cross-Entropy)和交叉验证(Cross-Validation)是机器学习中两个不同维度的概念,前者是损失函数 (用于训练模型),后者是模型评估方法(用于检验模型泛化能力),但两者最终目标都是提升模型性能。以下通过 "狗、猫、鸟分类" 案例详细说明它们的区别、联系和应用。
一、核心定义与本质区别
|----------|------------------------------------------|-----------------------------------------------|
| 维度 | 交叉熵(Cross-Entropy) | 交叉验证(Cross-Validation) |
| 本质 | 一种损失函数,用于量化 "预测概率分布" 与 "真实标签分布" 的差距。 | 一种模型评估策略,通过划分数据集多次训练和验证,检验模型的泛化能力(避免过拟合)。 |
| 作用阶段 | 模型训练过程中(每次前向传播后计算,指导权重更新)。 | 模型训练后或训练中(用于评估模型性能,选择最优参数或结构)。 |
| 核心目标 | 让模型的预测概率尽可能接近真实标签(如狗的预测概率接近 100%)。 | 确保模型在未见过的数据上表现稳定(如训练好的模型对新狗图像也能准确识别)。 |
二、具体区别:用 "狗、猫、鸟分类" 案例说明
1. 交叉熵:训练时的 "误差计算器"
假设我们用一个神经网络训练识别狗、猫、鸟,训练集有 1000 张图像(300 狗、300 猫、400 鸟)。
- 计算逻辑:
对每张图像,模型输出预测概率(如某张狗图像的预测为 0.4, 0.3, 0.3),真实标签为独热编码 1, 0, 0。交叉熵损失公式为:
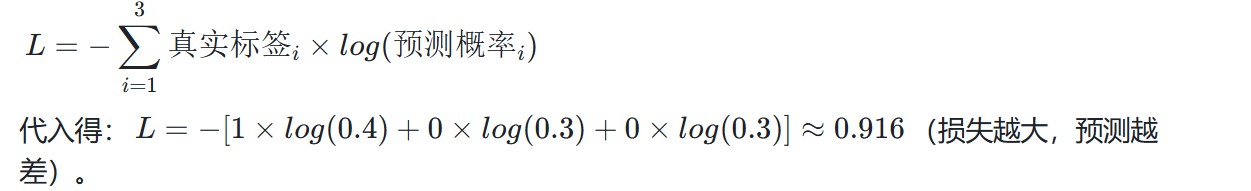
- 作用:
这个损失值通过反向传播指导网络调整权重(如增大狗神经元对 "耳朵""腿" 特征的权重),让下次预测时狗的概率升高(如从 0.4→0.8),损失降低(如从 0.916→0.223)。
- 总结:交叉熵是训练过程中 "衡量单次预测错误" 的工具,直接参与权重优化。
2. 交叉验证:评估时的 "泛化能力检验仪"
假设我们训练了一个模型,想知道它是否能准确识别 "未训练过的新图像"(避免过拟合,即只记住训练集,对新数据表现差),此时用交叉验证。
- 常用方法:k 折交叉验证(以 5 折为例):
① 将 1000 张图像随机分成 5 份(每折 200 张,含 60 狗、60 猫、80 鸟);
② 每次用 4 折(800 张)作为训练集,1 折(200 张)作为验证集:
-
- 第 1 次:用折 1-4 训练(用交叉熵损失优化权重),用折 5 验证(计算准确率,如 80%);
-
- 第 2 次:用折 1-3、5 训练,用折 4 验证(准确率 82%);
-
- 重复 5 次,得到 5 个验证准确率(80%、82%、79%、83%、81%);
③ 取平均准确率(81%)作为模型的泛化能力评估结果。
- 作用:
若 5 次验证准确率差异小(如 79%-83%),说明模型稳定;若差异大(如 60%-90%),说明模型过拟合(依赖某部分训练数据),需要调整(如减少参数、增加数据)。
- 总结:交叉验证是 "通过多次训练 - 验证" 评估模型在新数据上的表现,不直接参与权重优化。
三、联系:共同服务于 "提升模型性能"
交叉熵和交叉验证虽功能不同,但目标一致 ------ 让模型更准确、更稳定:
- 交叉熵是交叉验证的 "基础工具":
交叉验证中,每次训练子数据集时,仍需用交叉熵损失计算误差、调整权重(否则模型无法训练)。例如 5 折交叉验证的每次训练,都依赖交叉熵指导权重优化。
- 交叉验证指导交叉熵的 "优化方向":
若交叉验证发现模型过拟合(验证准确率低),可能需要调整训练策略(如增加正则化),而正则化会影响交叉熵损失的计算(如在损失中加入权重惩罚项),间接改变交叉熵的优化目标。
四、一句话总结
- 交叉熵:"训练时算错多少",是模型优化的 "指南针";
- 交叉验证:"训练后能不能用",是模型泛化能力的 "质检仪";
- 案例中,交叉熵让模型学会区分狗、猫、鸟,交叉验证确保模型对新的狗、猫、鸟图像也能区分。
训练一批,就出求出平均误差,再反向传播,不可能训练一张就反向传播太费时间了
在实际训练中,几乎不会对单张图像计算交叉熵损失后立即反向传播 (即随机梯度下降 SGD 很少用),而是采用小批量训练:对一批图像(如 16 张、32 张)计算平均交叉熵损失,再用这个平均损失进行反向传播调整权重。这是因为单张图像的损失存在随机性(噪声),会导致权重波动过大;而批量平均损失能更稳定地反映模型的整体错误,让权重调整更可靠。
结合 "狗、猫、鸟分类" 案例具体说明:
1. 单张图像计算损失的问题(为什么不常用)
假设训练集中有一张狗的图像,模型预测概率为 0.4, 0.3, 0.3(交叉熵损失≈0.916),若立即反向传播:
- 权重会根据这张图像的损失 "单独调整"(比如大幅增大狗神经元的权重);
- 但下一张可能是一只耳朵被遮挡的狗,预测概率 0.3, 0.5, 0.2(损失更大≈1.204),反向传播又会 "反向调整" 权重;
- 结果:权重在 "剧烈波动" 中难以收敛,模型无法稳定学习通用特征(如 "狗通常有 4 条腿")。
2. 批量平均损失的优势(实际主流做法)
假设每批训练 16 张图像(5 狗、5 猫、6 鸟):
- 计算单张损失:
5 张狗的损失分别为 0.916、0.850、0.780、0.950、0.820;
5 张猫的损失分别为 0.720、0.680、0.810、0.750、0.690;
6 张鸟的损失分别为 0.650、0.700、0.590、0.630、0.710、0.670。
- 计算批量平均损失:
总损失 = (狗损失和)+(猫损失和)+(鸟损失和)≈ (0.916+0.850+0.780+0.950+0.820) + (0.720+0.680+0.810+0.750+0.690) + (0.650+0.700+0.590+0.630+0.710+0.670) ≈ 4.316 + 3.65 + 3.95 ≈ 11.916;
平均损失 = 总损失 ÷ 16 ≈ 11.916 ÷ 16 ≈ 0.745。
- 用平均损失反向传播:
这个平均损失综合了 16 张图像的错误(包括狗、猫、鸟的各类情况),能更客观反映模型当前的 "整体缺陷"(比如对狗的耳朵特征识别不足,对鸟的翅膀特征响应不够)。
反向传播时,权重会根据这个 "综合信号" 调整(如适度增大狗神经元对耳朵的权重,同时增大鸟神经元对翅膀的权重),避免被单张图像的极端情况干扰,让权重稳定收敛。
3. 为什么不等到 "所有图像训练完再反向传播"(全批量)?
若 1000 张图像作为 1 批,计算总平均损失后才反向传播:
- 优点:损失最稳定(几乎无噪声);
- 缺点:计算量极大(1000 张图像的特征同时存储、计算),内存无法承受;且 1 个 epoch 内权重仅更新 1 次,训练速度极慢(对狗、猫、鸟这类中等任务,可能需要几天才能收敛)。
总结
实际训练中,交叉熵损失的使用遵循 "批量平均,批量反向传播" 原则:
- 对一批图像(如 16 张)计算每张的交叉熵损失,取平均值作为 "批量损失";
- 用这个批量损失指导反向传播,调整所有权重(包括全连接层、输出层等);
- 这样既避免了单张图像的噪声干扰(稳定),又兼顾了计算效率(比全批量快得多),是狗、猫、鸟分类等绝大多数任务的默认选择。
训练一批、求平均误差、再反向传播,是平衡稳定性和效率的最优策略。