目录
[1. Where](#1. Where)
[1.1 >, >=, <, <=](#1.1 >, >=, <, <=)
[1.2 =](#1.2 =)
[1.3 <=>](#1.3 <=>)
[1.3 !=, <>](#1.3 !=, <>)
[1.5 BETWEEN a0 AND a1](#1.5 BETWEEN a0 AND a1)
[1.6 IN (option, ...)](#1.6 IN (option, ...))
[1.7 IS NULL](#1.7 IS NULL)
[1.8 IS NOT NULL](#1.8 IS NOT NULL)
[1.9 LIKE](#1.9 LIKE)
[1.9.1 %](#1.9.1 %)
[1.9.2 _](#1.9.2 _)
[1.10 AND](#1.10 AND)
[1.11 OR](#1.11 OR)
[1.12 别名不能用在 WHERE 条件中](#1.12 别名不能用在 WHERE 条件中)
[1.13 结果排序](#1.13 结果排序)
[1.13.1 多重排序](#1.13.1 多重排序)
[ORDER BY 子句中可以使用列别名。](#ORDER BY 子句中可以使用列别名。)
[1.14 联合使用](#1.14 联合使用)
[2. Update](#2. Update)
1. Where
语法:
sql
SELECT 想要查询的列名 FROM 表名 where 条件;| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
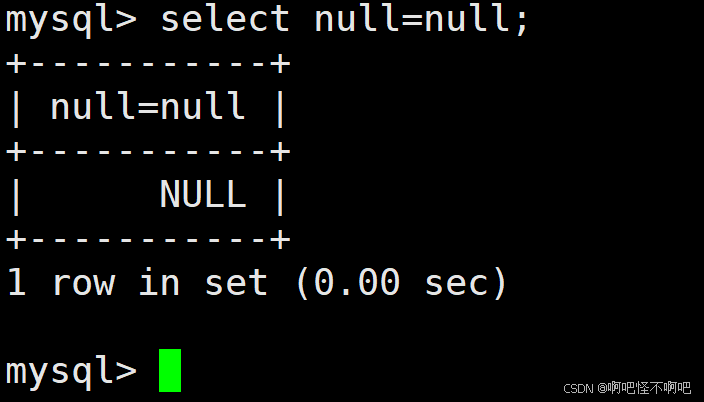
| = | 等于, NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于, NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配, a0, a1 ,如果 a0 <= value <= a1 ,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。 % 表示任意多个(包括 0 个)任意字符; _ 表示任意一个字符 |
| AND | 多个条件必须都为 TRUE(1),结果才是TRUE(1) |
| OR | 任意一个条件为 TRUE(1),结果为TRUE(1) |
| NOT | 条件为 TRUE(1),结果为FALSE(0) |
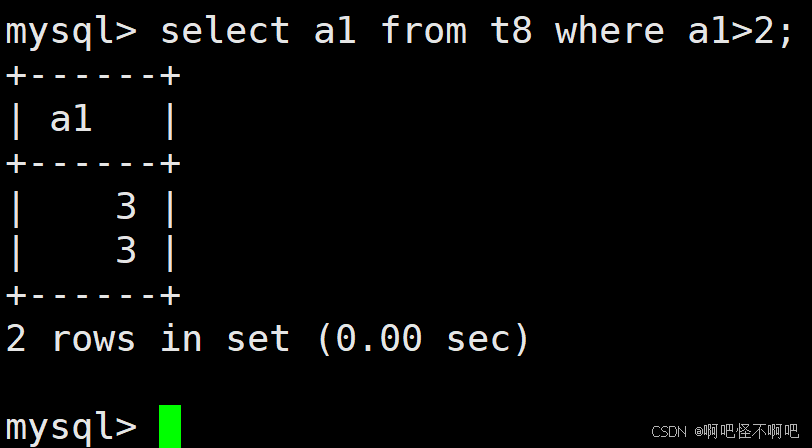
1.1 >, >=, <, <=
这个的话也比较简单。就像下面这张图一样使用就好了。
1.2 =
这个的话也比较简单。就像下面这张图一样使用就好了。
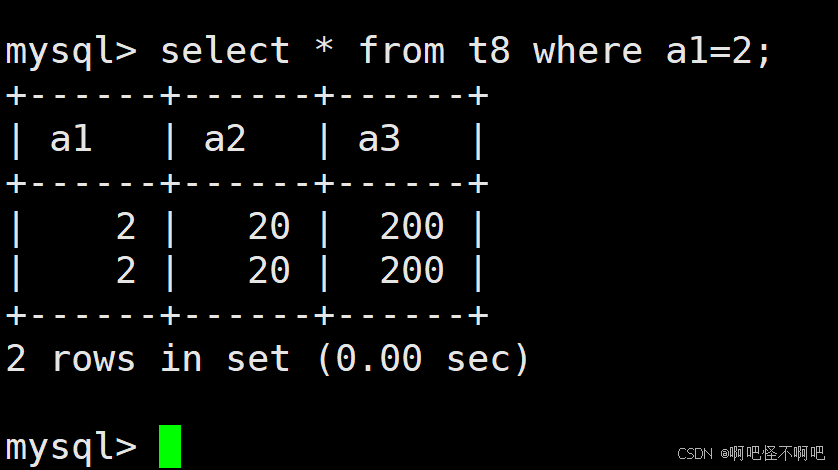
这边唯一要注意的就是在遇到下面这张情况,如果我们用的是=的话,那么不可以进行下面这个操作。
1.3 <=>
这个的话也比较简单。就像下面这张图一样使用就好了。
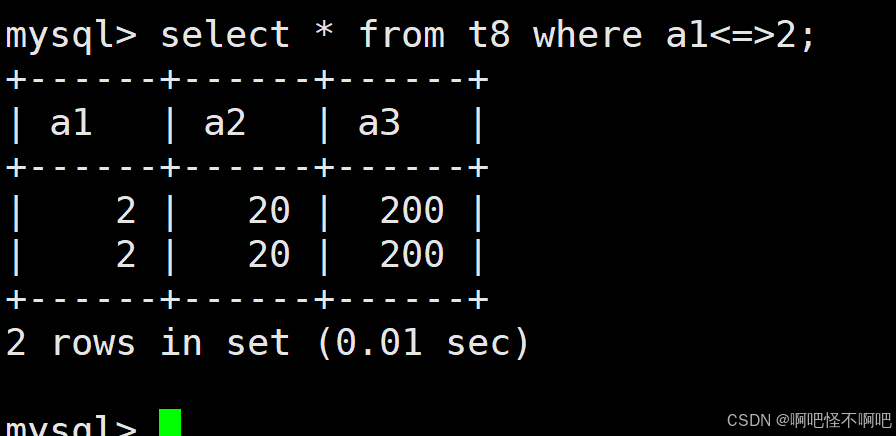
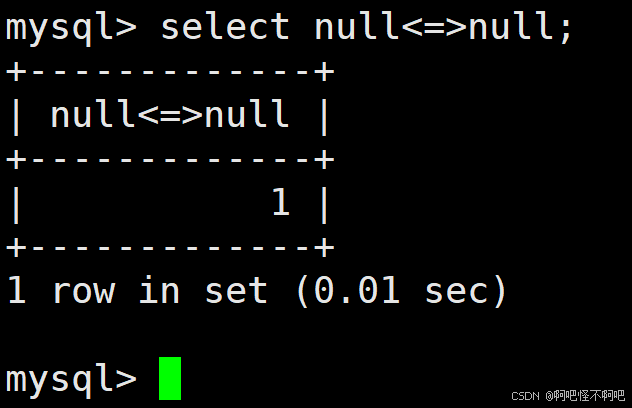
在这边唯一需要注意的就是这个<=>是可以使用null比较的。
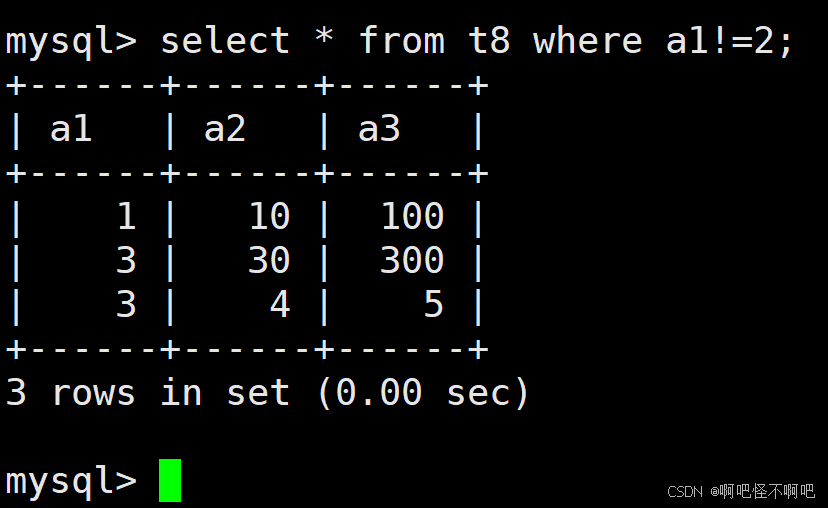
1.3 !=, <>
这个的话也比较简单。就像下面这张图一样使用就好了。
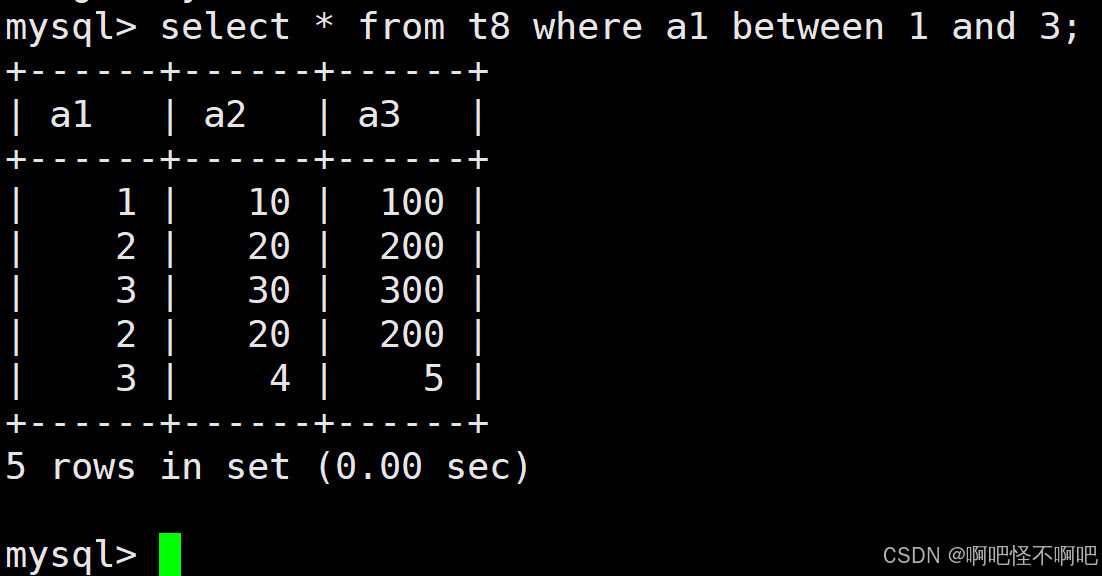
1.5 BETWEEN a0 AND a1
这个的话也比较简单。就像下面这张图一样使用就好了。
1.6 IN (option, ...)
这个的话也比较简单。就像下面这张图一样使用就好了。
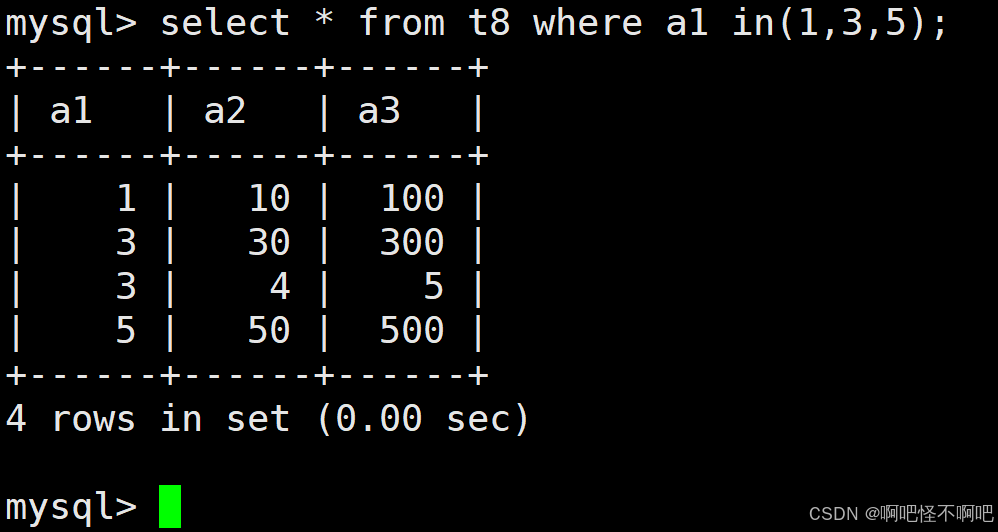
1.7 IS NULL
这个的话也比较简单。就像下面这张图一样使用就好了。
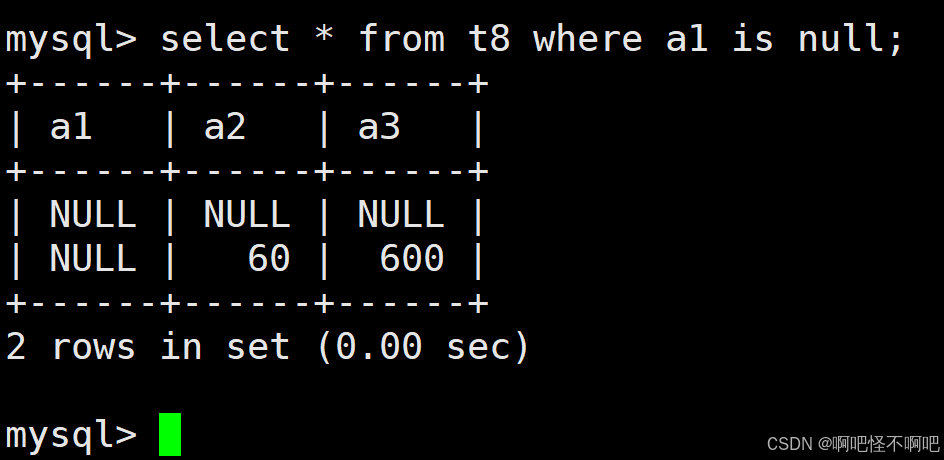
1.8 IS NOT NULL
这个的话也比较简单。就像下面这张图一样使用就好了。
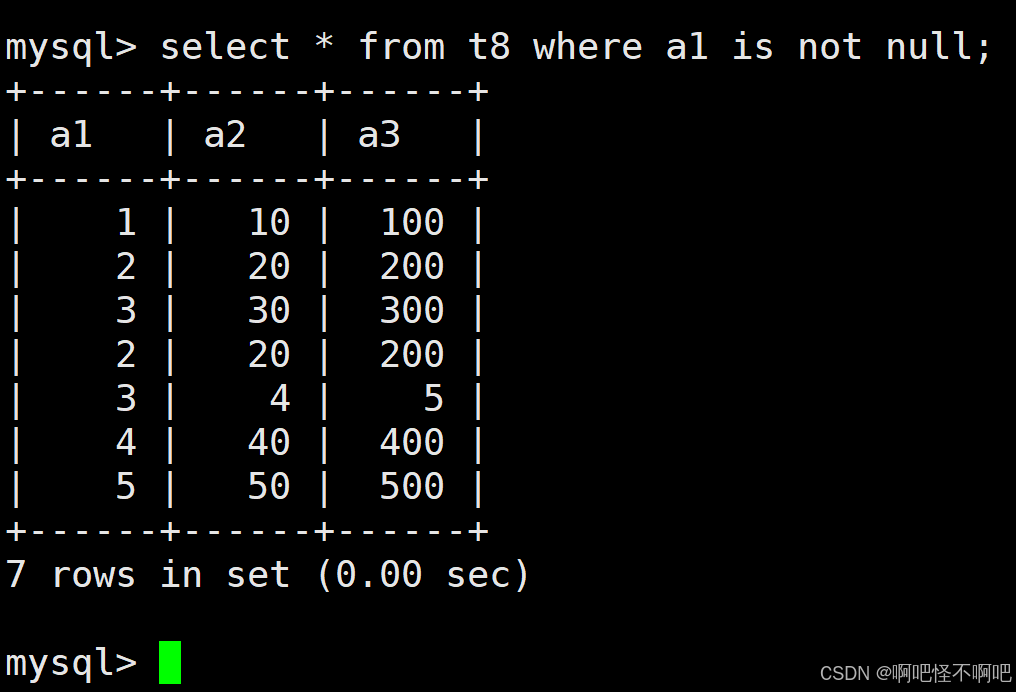
1.9 LIKE
这个的话稍微需要说一下。
1.9.1 %
% 是用来匹配任意多个(包括 0 个)任意字符。
比如说1%,那么它的额意思就是说包括1在内的所有以1开头的都要被包括在内。
就像下面这张图一样,因为这里t8就一个以1开头的,所以这边就取出来一个。
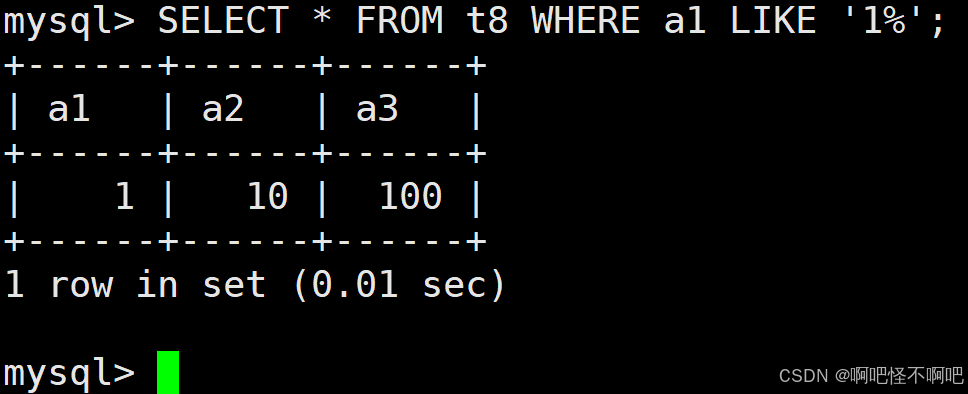
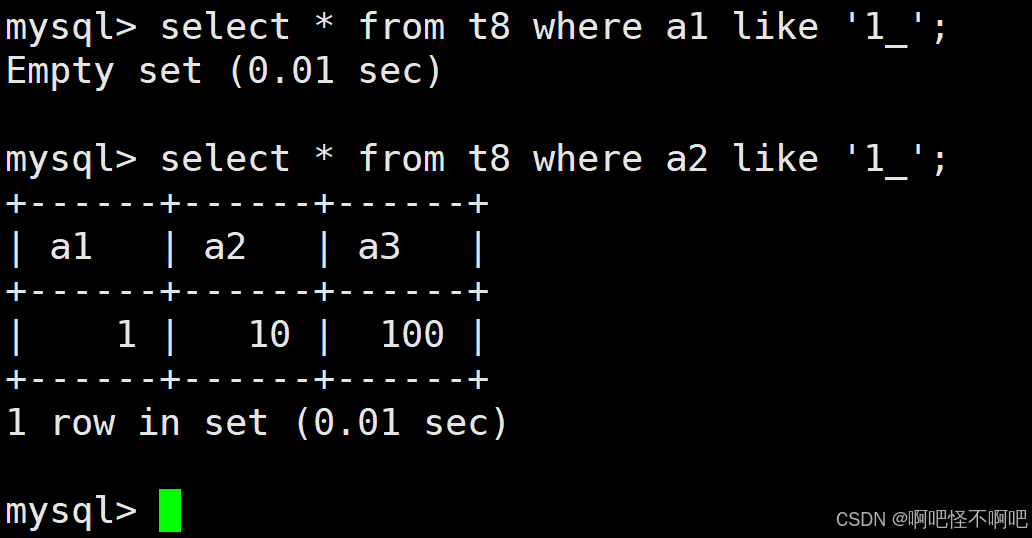
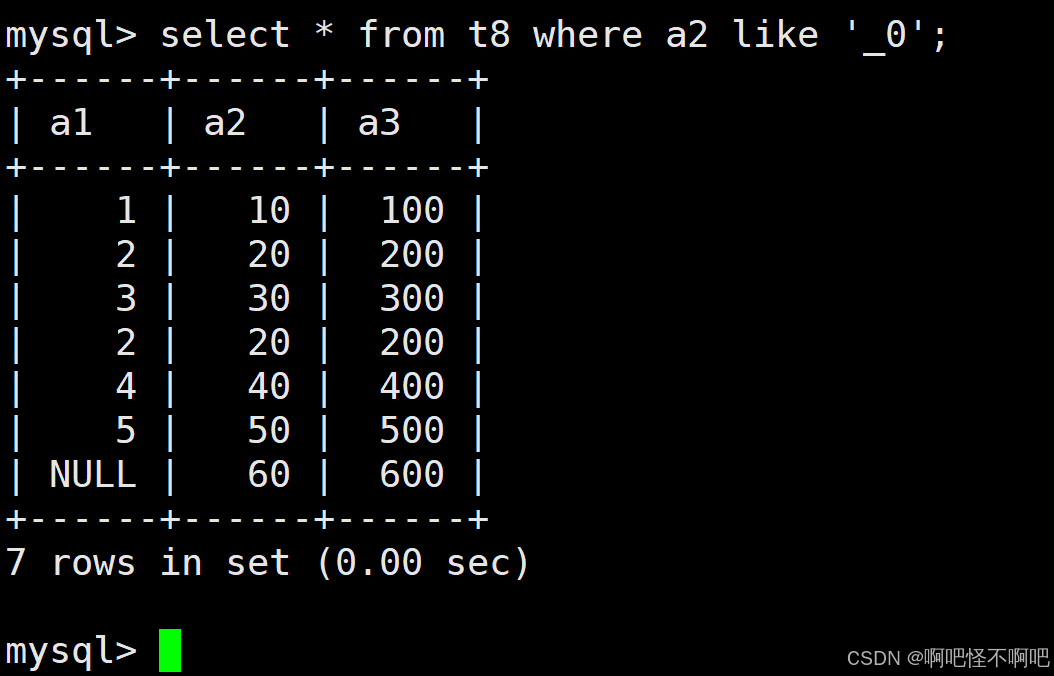
1.9.2 _
_ 匹配严格的一个任意字符
还是比如说1_,那么就是从10到19内的所有数。我们看下面这张图,这个_是必须要有一个数的,所以上面这个a1=1_的查询条件为空。
但是如果是_1的话,那么就是指11,21,31,41,51,61,71,81,91这些数。
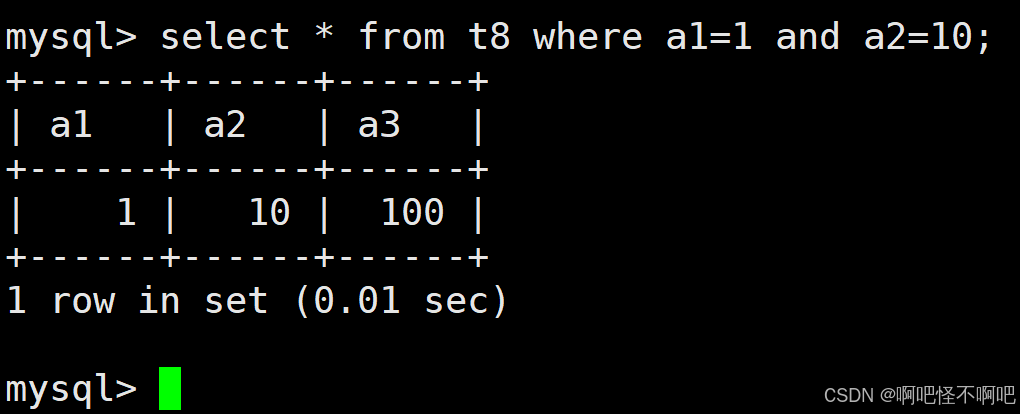
1.10 AND
这个的话也比较简单。就像下面这张图一样使用就好了。
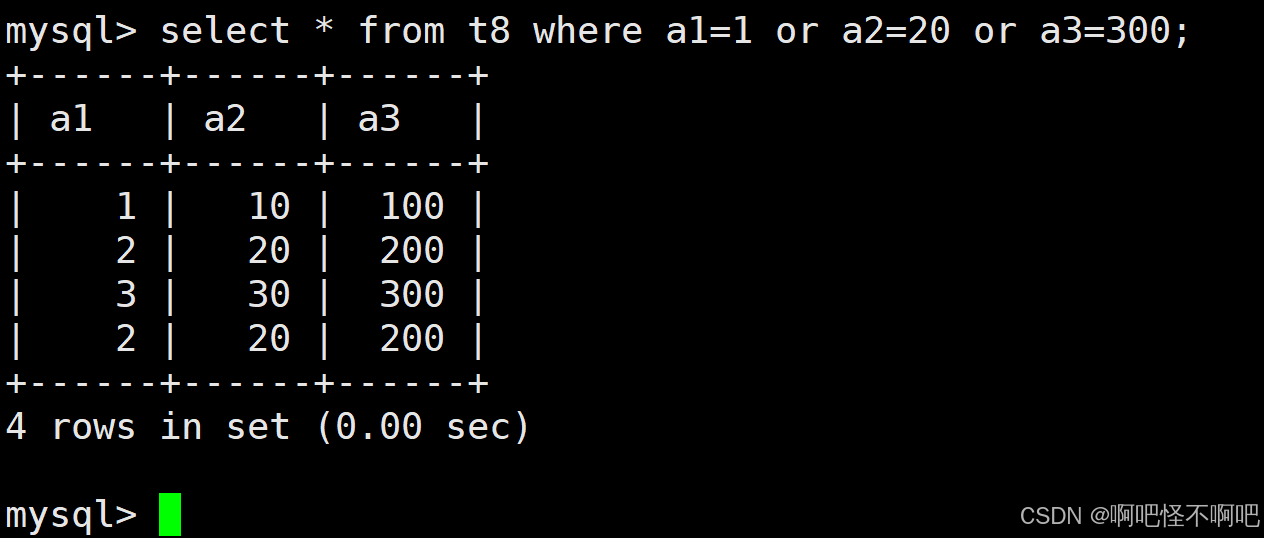
1.11 OR
这个的话也比较简单。就像下面这张图一样使用就好了。
1.12 别名不能用在 WHERE 条件中
SQL 语句的编写顺序和实际执行顺序是不同的。大致执行顺序如下:
-
先执行 from子句(确定数据来源表)。
-
然后执行 where子句(筛选行)。
-
再执行 select子句(选择列,并可能定义别名)。
也就是说,where子句的执行早于 select子句。当 where执行时,select中定义的别名还未被解析(相当于 "还不存在"),因此无法直接使用。
1.13 结果排序
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
语法:
sql
select 想要查询的列 别名 from 表名 order by 列名 desc或者asc我们看下面这张图,我们可以发现排序的话是不用加where的。最后在后面加上desc的话就实现了降序排序,也就是从大到小。
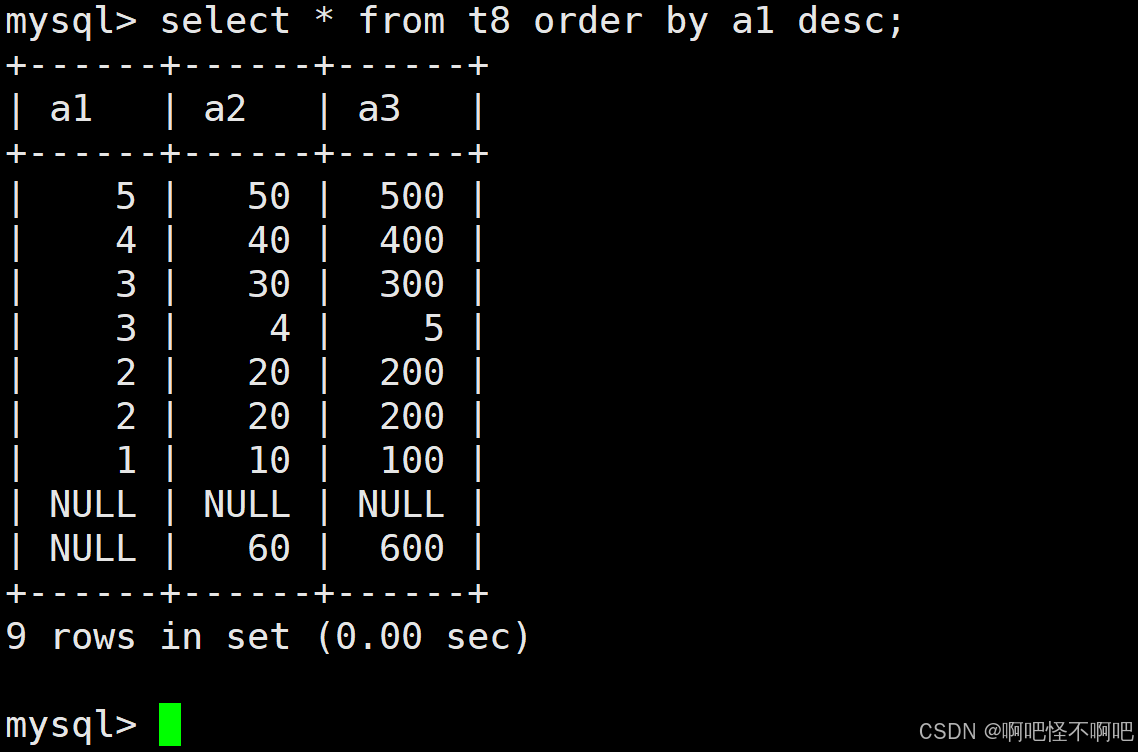
PS:null比任何值都要小,所以在降序排序的时候是在最后面的。
1.13.1 多重排序
多重排序是我自己取的名字,就是指那些写了多个排序条件的排序。
我们看下面这张图,我们写了很多条件,那么它是怎么执行的呢?它的执行顺序是什么呢?
很简单,首先它是从左往右执行的(当然这边说的从左往右专指order by后面的那部分代码)。然后是当我们在第一个排序指令遇到相同的值的时候才会去执行其后面这个。
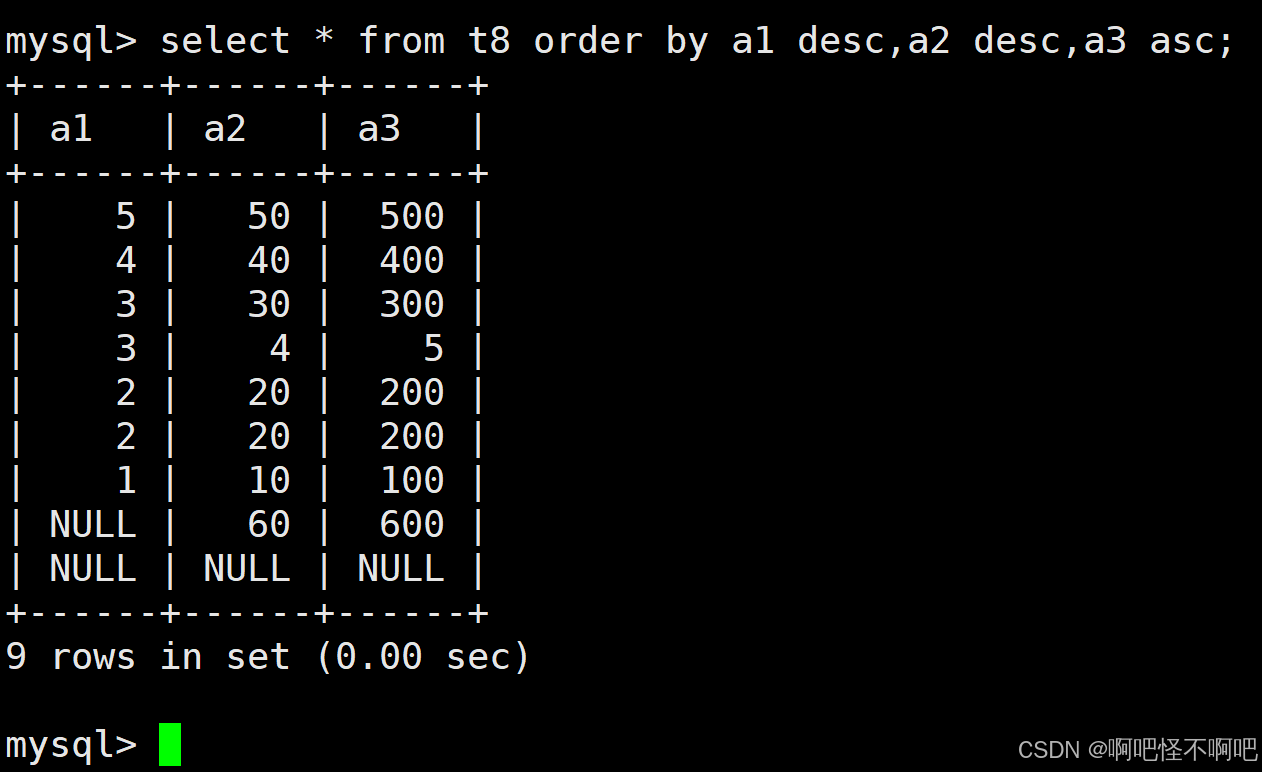
ORDER BY 子句中可以使用列别名。
1.14 联合使用
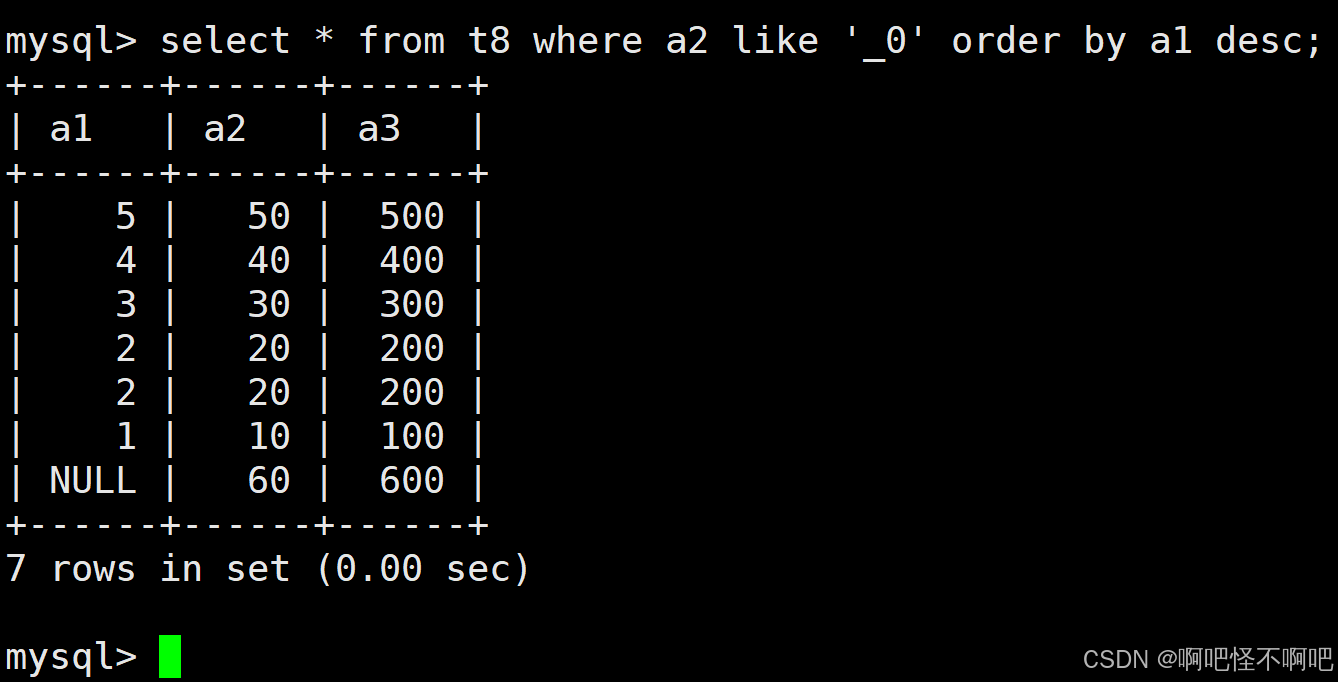
上面的各种筛选条件是可以在一起使用的。就像下面这张图一样。我们可以先找出两位数并且个位数是0的,然后在找出来的数据里面对其进行排序。
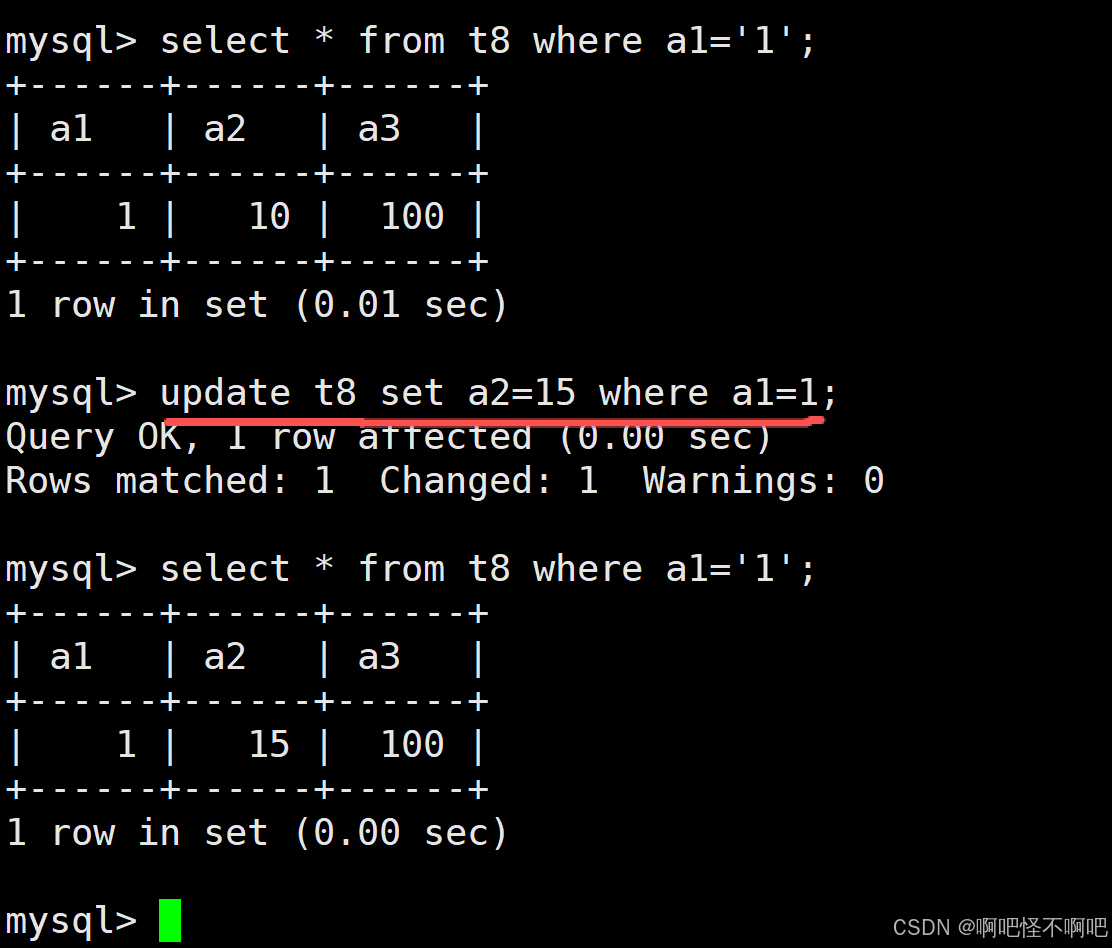
2. Update
接下来我们来聊聊表的更改。
语法:
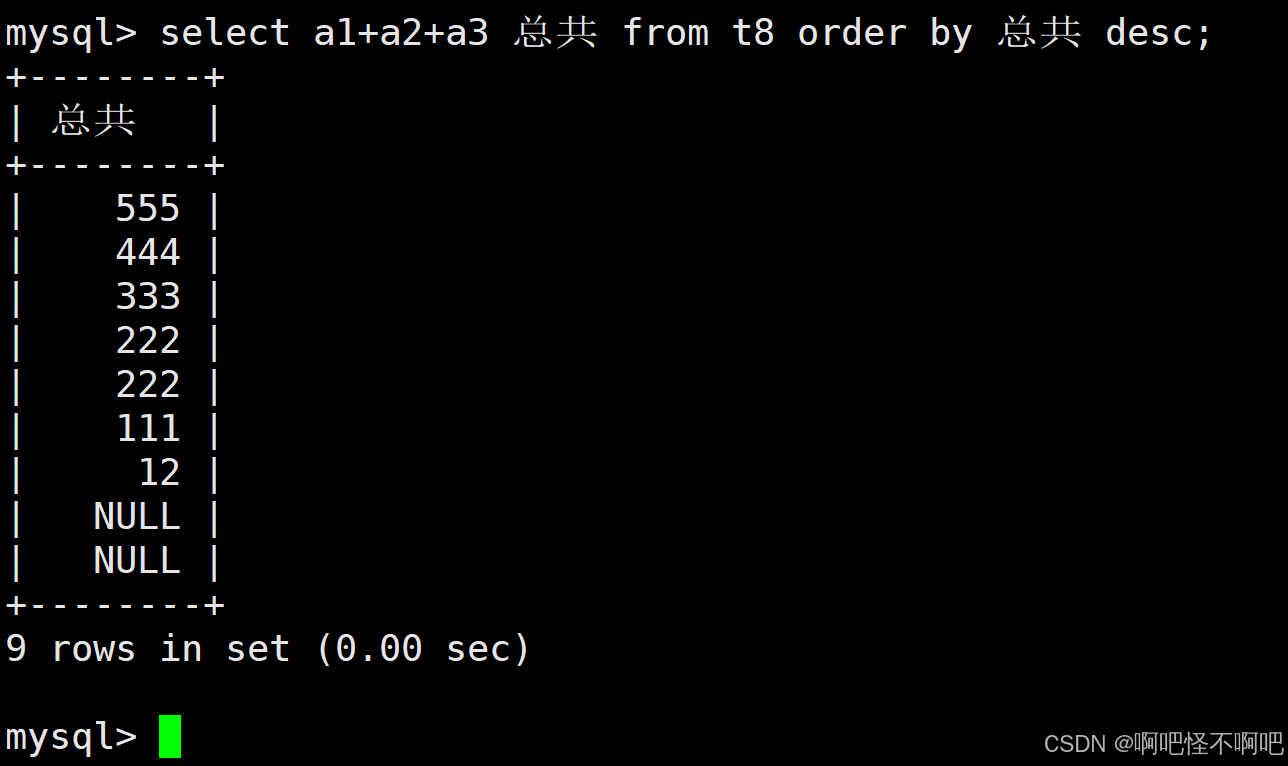
sql
update table_name set 想要更改的列=新值 确定列这么看好像还有点抽象,给各位举个例子各位就明白了。我们看下面这张图,where a1=1就是为了找到具体要改的是那个数据,这边没有固定的写法,我们只要让计算机知道我们想要让他更改的是那个数据就好。
如果我们不写后面的where a1=1的话,那么默认就是给整张表里面的所有列的a2都改为15。