国际计算机视觉与模式识别会议(CVPR 2025)和国际计算机视觉大会(ICCV 2025)作为计算机视觉领域的两大顶级会议,今年呈现了领域内的最新突破与前沿趋势。


CVPR 2025的整体接收率仅为22.1% ,创下近年新低,显示了学术标准的日益严苛,而ICCV 2025也保持了高度选择性,录用率为24% 。
2025 年的两场顶会(CVPR、ICCV)已经把近两年的研究潮流做了一次"年终盘点"------从论文与专题讨论可以清晰看到,计算机视觉正在从"单点模型"走向"多模态基础模型 + 生成能力 + 物理/几何感知"的复合发展方向。
会议全景:CVPR、ICCV 2025呈现哪些新动向?
今年两大顶会折射出计算机视觉领域的明显转变:从单一技术突破转向多元化应用融合,从独立模型训练转向统一框架构建。
CVPR 2025共收到13008份提交论文,最终接收2872篇。IDEA研究院有5篇论文入选,其中一篇获得Highlight荣誉。
同时,ICCV 2025的投稿量也达到了11239份,显示出学术界对这两大会议的高度认可。
这些论文不再局限于传统的图像识别、分割等基础任务,而是扩展到机器人交互、3D重建、视频理解等更为复杂的场景。
中国科学院空间应用中心的研究人员提出的跨模态船舶重识别算法TransOSS被ICCV 2025接收,这一研究突破了传统卫星跟踪瓶颈,为智慧海洋监测提供了全新解决方案。
从核心主题来看,多模态学习、3D内容生成、具身智能和底层架构创新成为今年会议的重点。
这些研究方向不再是孤立的,而是相互交织、共同推进,呈现出计算机视觉领域的整体演进脉络。
七大走向详解
- 视觉基础模型:多模态学习的融合与统一
视觉基础模型成为今年CVPR和ICCV的核心议题,研究者们不再满足于单一任务的专用模型,而是致力于构建能够处理多种任务的统一架构。
美团技术团队提出的MVP-LM框架 ,融合了视觉大语言模型的多粒度、多功能感知能力。
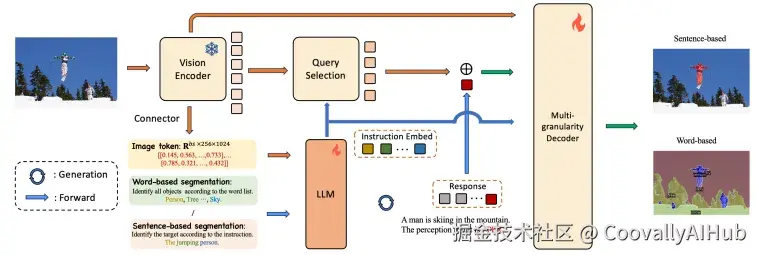
他们的框架旨在单一架构中整合基于词语和基于句子的感知任务,支持框及掩码的预测,在包括全景分割、检测、定位和指代表达分割等在内的广泛任务上实现无缝的有监督微调。
多模态大模型在融合视觉和语言信息方面存在根本性挑战------图像和文字两种模态的信息表示方式存在一道天然的鸿沟。
针对这一问题,北京大学、加州大学圣地亚哥分校等机构的研究者提出了Being-VL,创造性地将自然语言处理领域的BPE算法引入视觉领域。
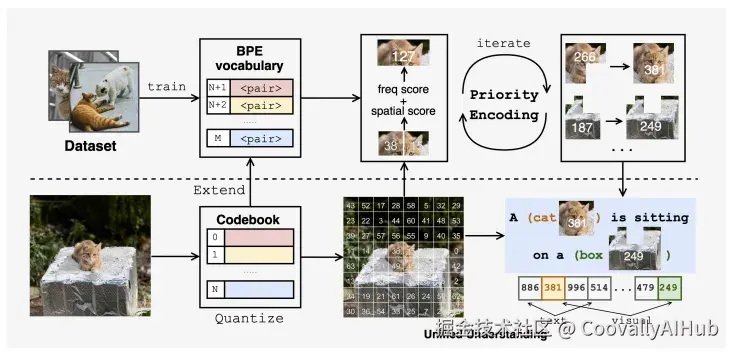
BPE算法的核心思想很简单: 在文本处理中,它会不断地把语料库里最高频出现的相邻字符对合并成一个新的、更长的子词。
Being-VL借鉴了这一思想,把图片看成一篇"文章",通过不断合并那些既频繁出现、空间位置又相对固定的相邻视觉Token对,构建出一个从基础纹理到复杂物体的层级化视觉词典。
- 生成式视觉:从静态图像到动态视频的跨越
生成式视觉尤其是视频生成与图像到视频的扩展,在今年的会议上显示出成熟期的特征。
文本到图像的diffusion模型已经进入产业化阶段,而研究者们正在向更复杂的时序生成任务迈进。
ICCV 2025中,格灵深瞳有6篇论文入选,成果涉及视觉基座模型、人脸3D重建等多个视觉AI研究关键方向。
在视频大型语言模型的时间理解方面,美团技术团队提出了DisTime,一种轻量级框架,旨在增强视频大型语言模型的时间理解能力。
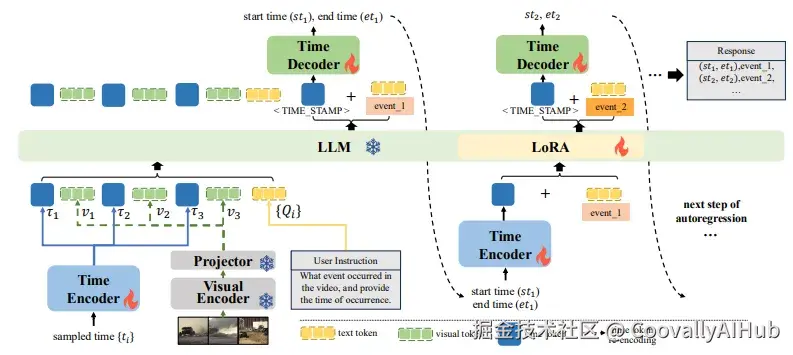
DisTime使用单个可学习的时间标记来创建一个连续的时间嵌入空间,并结合基于分布的时间解码器,生成时间概率分布,有效缓解边界模糊性并保持时间连续性。
为了克服现有无监督数据集中的时间粗粒度,他们还提出了一种自动化标注模式,促进了InternVidTG的创建------这是一个包含17.9万个视频和125万个时间定位事件的大型数据集,是ActivityNet-Caption的55倍。
在2D可交互数字人生成任务中,ARIG模型提出了一种基于自回归的逐帧生成框架,采用AR+diffusion框架以实现流式实时生成,并充分利用上下文语境和复杂对话状态理解实现了更高的交互真实感。
- 三维视觉与神经渲染:重建真实世界的高效探索
几何感知、神经渲染与4D动态场景恢复成为今年会议的亮点之一,显示出视觉社区对更真实、更物理一致的场景建模的追求。
MoRE模型提出了一个基于混合专家架构的稠密3D视觉基础模型,动态地将特征路由到特定任务的专家,使它们能够专注于互补的数据方面,同时增强可扩展性和适应性。

该模型结合了基于置信度的深度优化模块,稳定并优化几何估计,还将稠密语义特征与全局对齐的3D骨干表征相结合,实现高保真的表面法线预测。
在3D内容生成方面,LeanGaussian方法从单个RGB图像合成新视图的过程中直接建模3D高斯,打破像素或点云对应约束。
这一方法在三维重建速度和渲染速度上分别达到7.2 FPS和500 FPS,兼顾了效率与质量。
HRAvatar则从单目视频重建高质量、可重光照的3D人头头像。该方法采用可学习的形变表示和混合蒙皮策略,为每个高斯点独立学习形状和运动参数,使重建的头像更加逼真和精细。
3D内容生成的进步正在消弭虚拟与现实的边界,为元宇宙、数字孪生等应用提供技术基础。
- 具身智能与机器人视觉:连接感知与行动的桥梁
具身智能作为连接计算机视觉与机器人的桥梁,今年展现了从执行简单动作到解决复杂任务的跨越。
DUAL-STREAM扩散模型为世界模型增强的视觉-语言-动作模型提供了新思路。
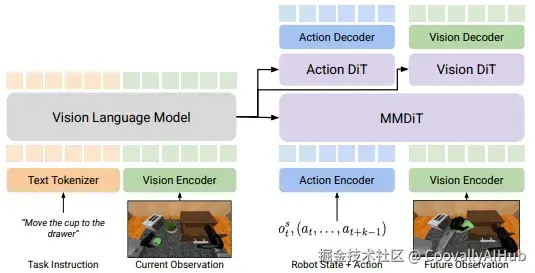
最近,通过世界建模增强视觉-语言-动作模型已在改进机器人策略学习方面显示出潜力。
然而,由于两种模态之间的固有差异,联合预测下一状态观察和动作序列仍然具有挑战性。
为了解决这一问题,研究者提出了DUal-STream扩散,这是一个世界模型增强的VLA框架,处理模态冲突并提高VLA在不同任务上的性能。
具体来说,他们提出了一个多模态扩散变换器架构,明确维护独立的模态流,同时仍然实现跨模态知识共享。
在机器人抓取研究方面,OR-ViT网络保留了关键空间细节,同时理解全局物体布局,从而在细长物体密集杂乱的真实工业环境中实现高成功率的抓取。
OR-ViT从ViT骨干网络的最浅层提取细粒度特征图,同时通过捕获融合特征图来理解全局物体布局。
链接:www.jstage.jst.go.jp/article/tra...
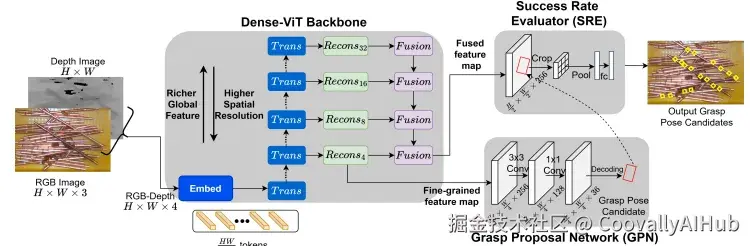
这种方式使OR-ViT能够以减少的碰撞概率预测精确的抓取姿态位置。
- 视频理解与时序高效推理:从算法优化到边缘部署
视频数据的高帧率、长时序特性导致计算负载激增,成为机器人实时决策的瓶颈。当前研究通过轻量化时序建模和跨模态特征复用,在边缘设备上实现低延迟处理。
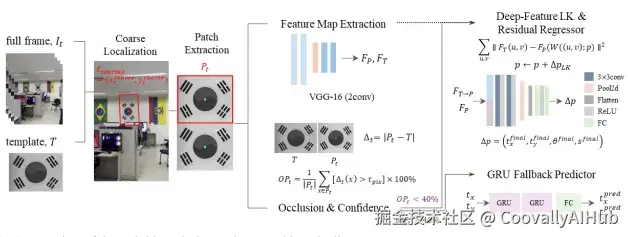
混合视觉伺服控制: 如GRU-Based Occlusion Recovery框架,通过GRU网络在遮挡期间预测运动轨迹,减少30%的计算冗余,在90%遮挡下仍保持<2px跟踪误差。这一方法融合传统Lucas-Kanade算法与深度学习,在30Hz实时控制中平衡精度与效率。
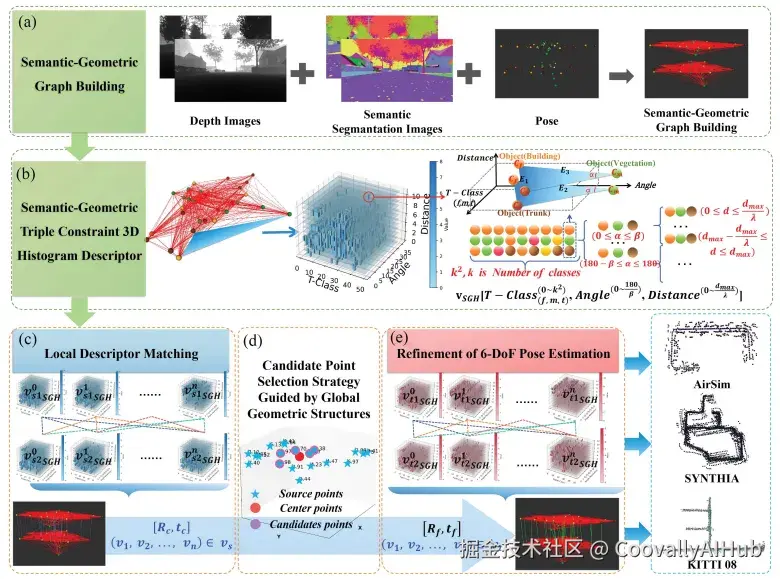
多机器人全局定位: 中科院提出的SGT-MGL方法,通过语义-几何三重约束优化多机器人协同定位,在KITTI数据集上降低40%位姿估计延迟,解决了动态环境中视角差异导致的关联难题。
链接:ieeexplore.ieee.org/document/10...
- 模型安全、可解释性与对抗防御:从生成内容到机器人行动
随着生成式AI普及,模型安全需求已从数字内容延伸至物理交互。研究重点包括对抗攻击防御、版权保护及决策可解释性。
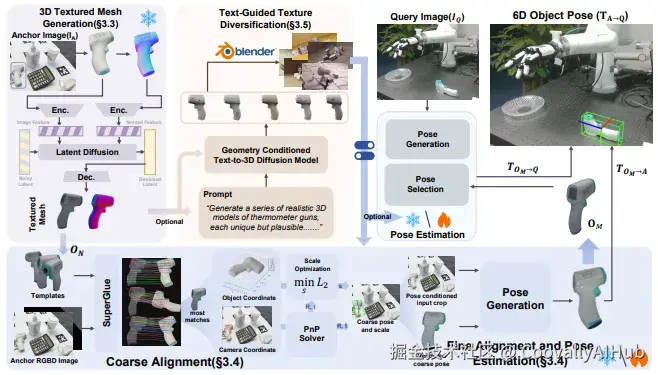
生成内容溯源: CVPR/ICCV 2025增设Workshop讨论生成模型水印与隐写技术。例如,文本引导的域随机化(如OnePoseViaGen方法),通过合成数据注入对抗噪声,提升模型对真实世界攻击的鲁棒性。
机器人操作可解释性: 部件分割模型(如Instant-Sem)在3秒内完成物体结构解析,为抓取生成提供透明决策依据,替代黑箱深度学习模型。通过神经辐射场(NeRF)渲染高分辨率模型,直观展示抓取位姿的物理合理性。
链接:www.sciencedirect.com/science/art...
- 数据效率与数据工程:从规模驱动到质量优先
数据瓶颈是制约机器人泛化能力的核心。研究趋势从大规模标注转向合成数据生成、自动化标注及领域自适应,以降低数据成本。
生成式数据增强: OnePoseViaGen利用单张RGB-D图像生成多样化3D训练数据,通过文本引导的域随机化创造光照、遮挡等长尾场景,在YCBInEOAT数据集上将标注需求减少70%。
真机数据闭环: 无锡实训中心构建八大工业场景功能区,年产能千万级高质量数据。其"数据工厂"模式使机器人一周内完成技能训练,数据复用率提升50%。
- 从学术走向工程:更多工业落地与跨学科应用(医学、自动化、制造)
计算机视觉技术正加速从实验室研究走向商业化应用,2025年涌现出多个实用化产品。
在医疗领域,数字孪生技术成为关注焦点。MICCAI 2025研讨会上的数字孪生医疗应用显示,计算机视觉技术正推动医疗诊断和治疗的精准化。
研究者提出了个性化3D心肌梗死几何重建从电影MRI与显式心脏运动建模的方法,以及从非侵入性临床图像的微血管视网膜数字孪生。
这些技术为精准医疗提供了新工具。
美团技术团队在ICCV 2025举办的多模态推理竞赛中,斩获了赛题1真实场景视觉定位冠军,赛题2空间感知视觉问答季军和赛题3创意广告视频视觉推理季军。
这些成就展示了计算机视觉技术在复杂多模态场景中的实际应用价值。
大推理模型时代已经来临,这为计算机视觉领域带来了新的机遇与挑战。
大语言模型强大的语义智能与大推理模型的链式推理能力,为视觉理解和解释开辟了新的前沿领域。
在工业应用方面,格灵深瞳与华为诺亚研究院合作的论文通过引入区域Transformer层和高效的区域聚类判别损失,有效提升视觉模型对局部区域信息的感知与表达能力,使其在OCR、目标检测和分割等密集视觉任务中表现突出。
对 2025 年底---2026 年的具体预测(研究与应用层面)
基于CVPR和ICCV 2025的成果,我们可以预测2026年计算机视觉领域的研究走向。
- 多模态大模型将进一步发展,突破"配对判断"的局限,转向更细粒度的语义关联理解。类似于RankCLIP的排序学习方法可能会成为主流。
- 视觉与语言的统一表示将成为重点研究课题。Being-VL展示的BPE视觉编码方法可能会被更多研究团队采纳,进一步弥合视觉与语言之间的表征鸿沟。
- 3D内容生成将更加注重效率与质量的平衡。类似MoRE的混合专家架构和LeanGaussian的轻量级方法将受到更多关注,特别是在移动设备和边缘计算场景。
- 具身智能将进一步强化复杂任务解决能力。DUAL-STREAM扩散展示的世界模型增强的VLA框架,将为家庭服务机器人、医疗机器人等领域带来突破。
- 视频理解与生成技术将向更长时序、更高一致性方向发展。DisTime展示的连续时间表示方法可能会被更多视频生成模型采用,实现更精确的时间控制。
- 尽管计算机视觉发展迅猛,但仍面临多重挑战。隐私问题是公众最担忧的方面,随着面部识别技术在智能手机和公共场所的普及,数据泄露的风险不容忽视。
- 模型安全、可解释性与对抗攻击也是重要议题。随着生成模型大规模应用,如何让生成内容可溯源、可防伪,以及如何检测对模型的隐蔽攻击将成为未来研究的重点。
这些年 CV 领域的突出成就 / 重要产品
- Diffusion 家族与 Stable Diffusion(图像生成):把高质量图像生成带进产业。
- CLIP / 对比学习系模型:把视觉与语言紧密绑定,成为多模态检索与理解的基石。
- Gaussian Splatting / 神经渲染技术:推动高质量 3D 表现与交互式渲染(近年学界、产业化同步发展)。
- 行业化产品示例:自动驾驶感知栈、工业检测系统(基于目标检测 / 分割的自动化质检)、医用影像辅助诊断原型等------这些都把学术进步落地到实际生产与服务场景。
(上面提到的技术/产品线在 CVPR/ICCV 的论文与 workshop 的内容中均有体现或延伸讨论。)
给研究者 / 工程师 /产品人的建议
- 把多模态 + 生成作为长期技术栈:学习基础模型调优、prompt 工程与微调技术。
- 投入数据工程(合成数据、数据清洗、标签质量控制),这是性价比最高的改进路径。
- 面向工业应用优先考虑效率与鲁棒性(而非单纯追求最SOTA的指标)。
- 关注模型安全与合规,在产品设计阶段就嵌入可溯源与版权保护机制。
结语
CVPR 与 ICCV 在 2025 年把一个清晰信号传达给研究与产业界:计算机视觉已经从单纯的"感知"研究走向以"理解 + 生成 + 物理/几何感知"为核心的新阶段。未来 1--2 年内,我们会看到这些方向在产品端的加速落地------特别是在视频生成、神经渲染、视觉基础模型与数据工程领域。