- 引言
- 问题根源分析
- [Celery 的多进程模型:隐性的陷阱](#Celery 的多进程模型:隐性的陷阱 "Celery 的多进程模型:隐性的陷阱")
- [Async SQLAlchemy 与事件循环的绑定](#Async SQLAlchemy 与事件循环的绑定 "Async SQLAlchemy 与事件循环的绑定")
- [当 Celery fork 子进程后会发生什么](#当 Celery fork 子进程后会发生什么 "当 Celery fork 子进程后会发生什么")
- [一个 socket 的例子揭开真相](#一个 socket 的例子揭开真相 "一个 socket 的例子揭开真相")
- 解决方案设计
- [在 worker 初始化阶段创建独立资源](#在 worker 初始化阶段创建独立资源 "在 worker 初始化阶段创建独立资源")
- [在 task 中执行异步 SQLAlchemy 操作](#在 task 中执行异步 SQLAlchemy 操作 "在 task 中执行异步 SQLAlchemy 操作")
- [解决衍生问题:为什么依然会是 NoneType](#解决衍生问题:为什么依然会是 NoneType "解决衍生问题:为什么依然会是 NoneType")
- [动态 import:延迟绑定的正确姿势](#动态 import:延迟绑定的正确姿势 "动态 import:延迟绑定的正确姿势")
- 工程经验与最佳实践总结
- 参考
引言
在现代 Python 后端开发中,FastAPI + SQLAlchemy + Celery 已成为一个常见且看似"完美"的组合:
- FastAPI 提供高性能的异步框架;
- SQLAlchemy Async 负责异步数据库访问;
- Celery 承担异步任务调度与执行。
理论上,它们各司其职、协同高效。但当我尝试在 Celery Worker 中执行异步 SQLAlchemy 操作 时,却没有那么顺利。我遇到了一系列诡异的错误:
- 数据库连接异常;
- event loop 未绑定;
- 子进程中连接池复用失败;
- engine、session 莫名变为 NoneType。
这些问题看似随机、多点暴雷,但背后却是同一个根源:
多进程模型与异步事件循环之间的冲突。
进一步调试后,我还发现另一个隐藏陷阱:
Python 的 模块导入机制 导致在 Celery 主进程中创建的全局变量被子进程"冻结",即使在子进程中重新初始化,也可能引用到无效对象。
最终我发现,要想让 Celery 和 Async SQLAlchemy 和谐共处,核心思路只有一个:
在每个 Celery 子进程中独立创建事件循环(
loop)、异步数据库引擎(engine)和会话工厂(sessionmaker)。
接下来,我们就从问题的根源出发,看看这场"多进程 vs 异步"的冲突究竟是如何产生的。
问题根源分析
在项目初期,我的数据库操作模块运行得一切正常。
典型的初始化代码大概是这样:
python
engine = create_async_engine(async_db_connection_url)
async_session_maker = sessionmaker(engine, class_=AsyncSession, expire_on_commit=False)所有的数据库读写都通过 async_session_maker 执行,运行平稳。
问题出现在我把部分耗时任务(例如文件解析、数据写入)"外包"给 Celery 之后。
当前的系统架构:
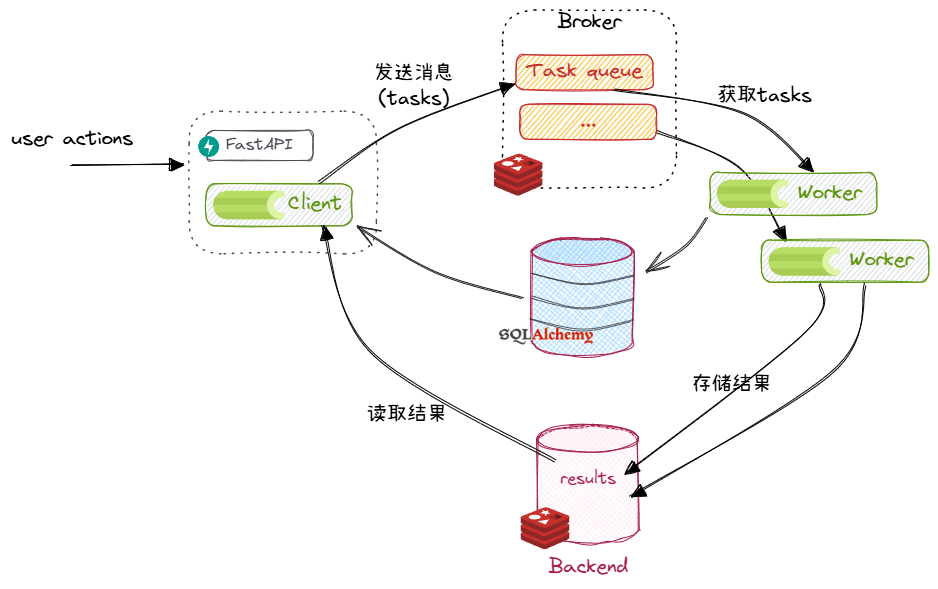
Celery 的多进程模型:隐性的陷阱
Celery 支持多种并发模型:prefork、eventlet、gevent、solo 等1。
为了保持配置简单,我最初采用了默认的 prefork 模式。
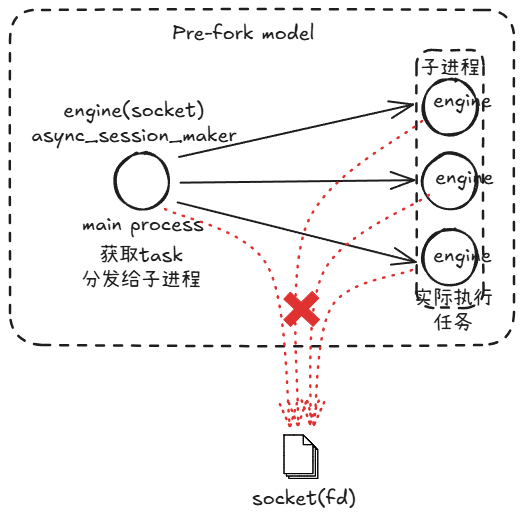
在 prefork 模型 下,Celery 主进程在启动时会:
- 预加载应用模块(包括导入的 Python 对象与全局变量);
- fork 出多个 worker 子进程;
- 每个子进程都会继承主进程的内存状态,包括:
- Python 对象;
- 文件描述符;
- socket 句柄等资源。
然后主进程负责从消息队列中获取任务,然后分发给各个子任务进行处理。
这种"复制内存快照"的方式在同步程序中问题不大。但当程序中涉及到 异步事件循环(event loop) 和 数据库连接池 时,问题就出现了。
Async SQLAlchemy 与事件循环的绑定
AsyncEngine 是 SQLAlchemy 为异步场景提供的引擎封装。
它在内部会管理一个连接池(pool),而连接池中的每个连接对象都持有一个底层 socket 。
这些 socket 是在创建引擎时通过当前事件循环(event loop)初始化的。
可以理解为:
AsyncEngine ← 连接池 ← socket ← event loop
因此,当我们在主进程中创建 engine 时,它就已经和主进程的 event loop "绑定"在了一起。
当 Celery fork 子进程后会发生什么
在 Celery 主进程中创建的 engine 和 event loop 会被子进程继承。
但问题在于:
-
子进程继承的 socket 是"同一个"连接;
-
子进程的 event loop 与主进程 loop 并不兼容;
-
原 loop 在 fork 后通常已经关闭或失效。
结果是:
-
子进程拿到的 engine 无法再使用;
-
调用 await 时触发异常;
-
连接池复用失败或行为异常。
典型报错包括:
RuntimeError: Event loop is closed
sqlalchemy.exc.InvalidRequestError: Can't operate on closed connection
AttributeError: 'NoneType' object has no attribute 'run_until_complete'这类错误的共同点是 ------ 它们都不是语法问题,而是资源被 fork 复制后处于无效状态。
一个 socket 的例子揭开真相
为了更直观地理解,我们可以用最简单的 socket 例子来还原这种问题:
python
# z1.py
import os, socket
s = socket.socket()
s.connect(("example.com", 80))
pid = os.fork()
if pid == 0: # 子进程
s.send(b"GET / HTTP/1.0\r\n\r\n")
data = s.recv(100)
print("child:", data)
else:
s.send(b"HEAD / HTTP/1.0\r\n\r\n")
data = s.recv(100)
print("parent:", data)运行的结果大概是这样的:
# python z1.py
parent: b'ength: 310\r\nExpires: Sat, 01 Nov 2025 11:22:08 GMT\r\nDate: Sat, 01 Nov 2025 11:22:08 GMT\r\nConnection:'
child: b'HTTP/1.0 400 Bad Request\r\nServer: AkamaiGHost\r\nMime-Version: 1.0\r\nContent-Type: text/html\r\nContent-L'虽然没有报错,但父子进程的 TCP 数据完全"串台 "。
原因很简单 ------ 它们复用了同一个 socket 文件描述符。
同样的事也发生在 Async SQLAlchemy 的连接池上:
fork 后共享 socket 不会立刻报错,但会导致不可预测的行为。
问题的本质:
Async SQLAlchemy 是事件循环驱动的资源系统,而 Celery 的多进程模型是内存复制驱动的资源系统。两者在设计理念上并不兼容。
| 层级 | 关键点 | 问题表现 |
|---|---|---|
| Celery 模型 | 多进程 fork,继承主进程资源 | 子进程复用了主进程的 socket 和内存 |
| Async SQLAlchemy | engine 与 event loop 绑定 | fork 后 loop 无效、连接池混乱 |
| 结果 | 异步任务报错、engine 失效、连接池崩溃 | RuntimeError: Event loop is closed、NoneType 异常等 |
解决方案设计
在 worker 初始化阶段创建独立资源
Celery 提供了一个非常有用的信号:worker_process_init。
它会在每个 worker 子进程启动时被触发,非常适合用来初始化异步环境。
python
from celery import signals
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.orm import sessionmaker
import asyncio
@signals.worker_process_init.connect
def init_worker(**kwargs):
global worker_loop, async_engine, async_session_maker
# 1 为每个 worker 创建独立的事件循环
worker_loop = asyncio.new_event_loop()
asyncio.set_event_loop(worker_loop)
# 2 为当前进程创建独立的 async engine
async_engine = create_async_engine(DB_URL, pool_pre_ping=True)
# 3 为当前进程创建独立的 sessionmaker
async_session_maker = sessionmaker(
async_engine, class_=AsyncSession, expire_on_commit=False
)这样,每个 Celery 子进程在启动时都会完成以下三件事:
- 拥有自己的 event loop;
- 拥有自己的数据库连接池;
- 拥有独立的 session 工厂。
从此,主进程与 worker 子进程的异步上下文彻底隔离。
在 task 中执行异步 SQLAlchemy 操作
在 Celery 的任务函数中,可以通过 run_until_complete() 在同步上下文中运行异步函数。
python
from app.instance_database.database.session import worker_loop, async_session_maker
@celery_app.task(bind=True, max_retries=3)
def parse_qr_task(self, url: str, key: str):
async def get_audio_source_by_qr_hash(qr_text_hash: str):
async with async_session_maker() as session:
stmt = select(AudioSource).where(AudioSource.qr_text_hash == qr_text_hash)
result = await session.execute(stmt)
return result.scalar_one_or_none()
existing = worker_loop.run_until_complete(get_audio_source_by_qr_hash(key))
return existing虽然这种写法看起来有点"曲线救国",但它在多进程模型下非常稳定。
因为此时所有异步相关资源(loop、engine、sessionmaker)都在当前子进程中创建并绑定。
解决衍生问题:为什么依然会是 NoneType
当我首次采用上述方案时,仍然出现了一个奇怪的问题:
AttributeError: 'NoneType' object has no attribute 'run_until_complete'原因在于:
- Celery 主进程在启动时,会预加载模块;
- 此时导入的
worker_loop、async_session_maker变量还未初始化; - fork 后子进程继承的变量就是
None。
虽然 init_worker() 在每个子进程启动时执行,但如果 task 函数在导入阶段就引用了这些变量(即在文件顶部导入),就会发生"引用时机错误"的问题。
动态 import:延迟绑定的正确姿势
最简单、最可靠的办法是 ------ 延迟导入这些变量,确保它们在使用时已经被初始化。
python
@celery_app.task(bind=True)
def parse_qr_task(self, url: str, key: str):
from app.instance_database.database.session import worker_loop, async_session_maker
async def get_audio_source_by_qr_hash(qr_text_hash: str):
async with async_session_maker() as session:
stmt = select(AudioSource).where(AudioSource.qr_text_hash == qr_text_hash)
result = await session.execute(stmt)
return result.scalar_one_or_none()
result = worker_loop.run_until_complete(get_audio_source_by_qr_hash(key))
return result这种"动态 import"方式能确保在 Celery 任务运行时,获取到的 worker_loop 与 async_session_maker 已经被子进程正确初始化。
为了避免重复编写导入语句,可以将其封装为通用函数:
python
# db_runtime.py
def get_runtime_objects():
from app.instance_database.database.session import worker_loop, async_session_maker
return worker_loop, async_session_maker然后在任务中简洁地调用:
python
loop, session_maker = get_runtime_objects()
loop.run_until_complete(...)工程经验与最佳实践总结
回顾整个排查和解决过程,可以发现,问题的核心并不在于某个框架或库的"缺陷",而在于 不同运行模型(多进程 vs 异步事件循环)之间的边界模糊。这种问题往往出现在系统集成阶段,而非单一模块内部。以下是我在这次实践中总结的几条工程经验与最佳实践。
-
明确运行模型的边界
在一个系统中,异步编程模型(asyncio)和多进程模型(multiprocessing / Celery)不能直接混用资源。
-
异步模型依赖事件循环(Event Loop)来调度协程。
-
多进程模型通过 fork() 或 spawn() 创建子进程,进程之间不共享 loop、socket、或连接池。
-
因此,只要存在多进程,就应当假定所有 loop 与连接池都需在子进程中重新初始化,而非从父进程继承。
-
区分全局状态与进程本地状态
Python 的模块导入机制会导致全局变量在不同进程间被复制,而非共享。
这意味着:
- 父进程中的 worker_loop 变量在子进程中虽然存在,但引用的 loop 实际已经失效。
- 若在模块顶层执行异步初始化(如 engine = create_async_engine()),所有子进程会继承一个无效的资源对象。
所以:
- 避免在模块顶层执行异步初始化逻辑。
- 使用 惰性加载 或 依赖注入 机制,确保每个进程独立创建和销毁自身资源。
这次遇到的问题让我再次认识到:
工程能力的成熟,不仅体现在"写出异步代码",更体现在"知道异步代码应该在哪里被执行"。理解框架底层运行机制、建立稳定的初始化边界、保持模块化思维------这些都是让系统在复杂场景中依然可控的关键。