在人工智能迅猛发展的今天,多模态大模型已经展现出令人惊叹的图像编辑能力。然而,在专业性极强的医学影像领域,AI编辑的研究却一直受限于高质量、大规模、可公开访问数据集的缺失。
医学影像编辑不仅要求视觉效果逼真,更必须严格遵循解剖结构、病理特征和成像设备的物理特性------这些苛刻条件让通用领域的编辑模型难以直接应用。
为此,新加坡国立大学的研究团队推出了Med-Banana-50K------一个专为医学影像编辑设计的大规模数据集,为这一领域的研究提供了坚实基石。
数据集亮点:规模与质量的双重保障

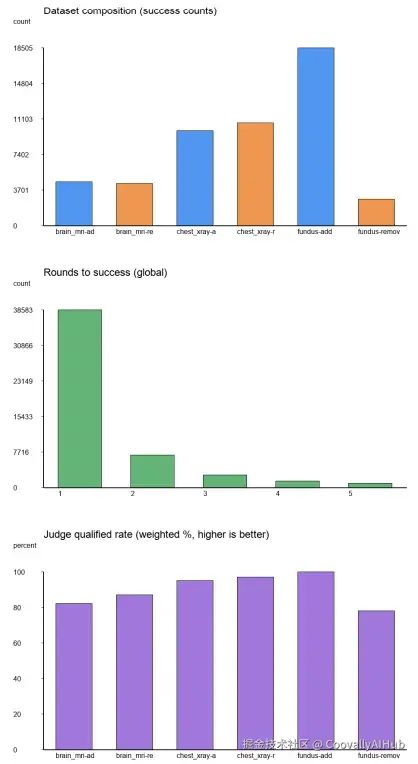
50,635次高质量医学影像编辑,涵盖三大成像模态:
- 胸部X光(12种病理类型)
- 脑部MRI(4种肿瘤类型)
- 眼底摄影(7种疾病类型)
双向编辑任务设计:
- 病灶添加: 从正常图像生成病变图像,支持数据增强和反事实推理
- 病灶移除: 从病变图像恢复为正常图像,模拟治疗效果
创新质量控制:LLM作为医学评判官
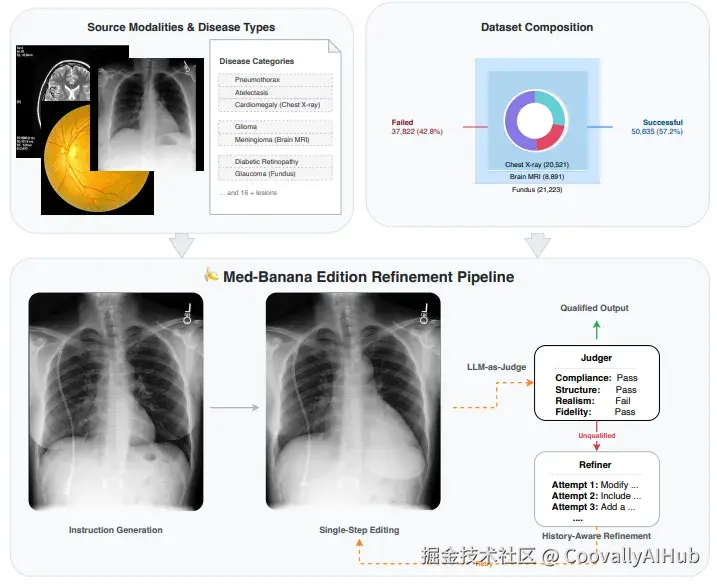
与传统数据集不同,Med-Banana-50K引入了创新的LLM-as-Judge质量控制系统。研究团队使用Gemini-2.5-Pro作为自动评判官,从四个医学关键维度严格评估每次编辑:
- 指令遵循度(40%): 编辑是否准确执行了文本指令
- 结构合理性(25%): 解剖结构是否保持正确
- 视觉真实感(20%): 图像是否像真实的医学扫描
- 保真度保持(15%): 是否保留了原始图像的噪声、纹理和设备特征
每个编辑任务最多经过5轮迭代优化,失败尝试也被完整保留,为偏好学习研究提供了宝贵资源。
数据集价值:推动医学AI多领域发展
Med-Banana-50K不仅仅是一个数据集,更是医学AI研究的多功能平台:
- 模型训练与评估
为医学影像编辑模型提供大规模监督微调数据,支持下一代医学AI模型的开发。
- 反事实解释研究
通过"假设-编辑"范式,帮助理解疾病特征和诊断决策,增强AI的可解释性。
- 数据增强与对齐学习
37,822次失败尝试为DPO、奖励建模等对齐方法研究提供了丰富的负样本。
- 多模态LLM研究
完整的对话日志支持反思、推理和迭代优化能力的研究。
技术细节:严谨的医学设计理念
数据集构建过程体现了研究团队对医学专业性的深刻理解:
- 医学约束优先: 所有编辑指令强调保真度保持(保留噪声、纹理)、负面规则(无文本标签、无锐利边缘)和反事实最小化(仅修改病灶相关区域)。
- 历史感知优化: 优化过程分析先前失败模式,生成改进指令,避免循环错误。
- 质量验证: 初步人工验证显示,LLM评判官与放射科医生的判断一致性达到81%,证明了该质量评估体系的有效性。
开放获取与负责任使用
数据集采用开放许可证发布:
- 编辑图像:CC BY 4.0
- 元数据:ODC-By 1.0
- 代码:MIT许可证
重要提示:该数据集仅限研究使用,不适用于临床诊断或治疗规划。研究团队强调,任何临床部署都需要严格的验证、监管批准和医疗专业人员监督。
数据集地址
bash
数据集地址:https://github.com/richardChenzhihui/med-banana-50k未来展望
尽管Med-Banana-50K在规模和质量上实现了突破,研究团队也坦承其局限性:覆盖模态和疾病类型有限,LLM评判官的可靠性需要进一步验证,对特定编辑模型的依赖等。
未来工作将扩展至更多成像模态(如CT、超声),开展系统性专家验证,并探索与开源模型的集成,推动医学影像编辑技术的普惠发展。这个数据集不仅为技术发展提供了燃料,更建立了医学AI数据构建的质量标准。
相信在不久的将来,基于此类高质量数据训练的AI模型,将在医学教育、诊断辅助和治疗规划中发挥越来越重要的作用。
Coovally平台
Coovally AI平台包含400+数据集。你无需配置环境、修改代码,只需选择任务类型(目标检测)、选择模型(如YOLOv8、RT-DETR),即可启动完整训练流程。

Coovally平台还提供强大的数据增强功能,可以自由应用多样化的数据增强功能(如旋转、翻转、色彩调整、噪声添加等) ,有效扩充训练数据,从而显著提升模型的泛化能力、鲁棒性并降低过拟合风险,用户可通过直观配置轻松实现。
平台优势包括:
- 无缝衔接: 从数据标注到模型训练、预测、部署,省去格式转换和平台迁移的麻烦
- 模型预设丰富: 平台包含1000+数据集,YOLO, Transformer 等主流结构随取随用
- 可视化实验日志: 训练结果可视化展示,指标一目了然
- 部署无门槛: 支持模型导出、API调用,一键集成业务流程
**!!点击下方链接,立即体验Coovally!!**
**平台链接:** **https://www.coovally.com**