目录
[1.1 什么是枚举算法?](#1.1 什么是枚举算法?)
[1.2 枚举算法的核心要素](#1.2 枚举算法的核心要素)
[1.3 枚举算法的适用场景](#1.3 枚举算法的适用场景)
[1.4 枚举算法的优缺点](#1.4 枚举算法的优缺点)
[1.5 枚举算法的通用解题步骤](#1.5 枚举算法的通用解题步骤)
[2.1 案例 1:铺地毯(洛谷 P1003 NOIP2011 提高组)](#2.1 案例 1:铺地毯(洛谷 P1003 [NOIP2011 提高组]))
[2.1.1 题目分析](#2.1.1 题目分析)
[2.1.2 解题思路](#2.1.2 解题思路)
[2.1.3 完整代码实现(ACM 模式)](#2.1.3 完整代码实现(ACM 模式))
[2.1.4 代码解析](#2.1.4 代码解析)
[2.1.5 易错点分析](#2.1.5 易错点分析)
[2.2 案例 2:回文日期(洛谷 P2010 NOIP2016 普及组)](#2.2 案例 2:回文日期(洛谷 P2010 [NOIP2016 普及组]))
[2.2.1 题目分析](#2.2.1 题目分析)
[2.2.2 解题思路](#2.2.2 解题思路)
[2.2.3 关键辅助函数](#2.2.3 关键辅助函数)
[1. 反转数字(如 2010 → 0102)](#1. 反转数字(如 2010 → 0102))
[2. 判断闰年(用于确定 2 月天数)](#2. 判断闰年(用于确定 2 月天数))
[3. 验证日期有效性](#3. 验证日期有效性)
[2.2.4 完整代码实现(ACM 模式)](#2.2.4 完整代码实现(ACM 模式))
[2.2.5 代码解析](#2.2.5 代码解析)
[2.2.6 易错点分析](#2.2.6 易错点分析)
[2.3 案例 3:扫雷(洛谷 P2327 SCOI2005)](#2.3 案例 3:扫雷(洛谷 P2327 [SCOI2005]))
[2.3.1 题目分析](#2.3.1 题目分析)
[2.3.2 解题思路](#2.3.2 解题思路)
[2.3.3 完整代码实现(ACM 模式)](#2.3.3 完整代码实现(ACM 模式))
[2.3.4 代码解析](#2.3.4 代码解析)
[2.3.5 易错点分析](#2.3.5 易错点分析)
[3.1 二进制枚举的核心原理](#3.1 二进制枚举的核心原理)
[3.1.1 状态映射](#3.1.1 状态映射)
[3.1.2 枚举范围](#3.1.2 枚举范围)
[3.1.3 位运算操作](#3.1.3 位运算操作)
[3.2 案例 1:子集(力扣 78. 子集)](#3.2 案例 1:子集(力扣 78. 子集))
[3.2.1 题目分析](#3.2.1 题目分析)
[3.2.2 解题思路](#3.2.2 解题思路)
[3.2.3 完整代码实现(核心代码模式)](#3.2.3 完整代码实现(核心代码模式))
[3.2.4 代码解析](#3.2.4 代码解析)
[3.2.5 易错点分析](#3.2.5 易错点分析)
[3.3 案例 2:费解的开关(洛谷 P10449)](#3.3 案例 2:费解的开关(洛谷 P10449))
[3.3.1 题目分析](#3.3.1 题目分析)
[3.3.2 解题思路](#3.3.2 解题思路)
[3.3.3 关键辅助函数](#3.3.3 关键辅助函数)
[1. 反转灯的状态(按开关)](#1. 反转灯的状态(按开关))
[3.3.4 完整代码实现(ACM 模式)](#3.3.4 完整代码实现(ACM 模式))
[3.3.5 代码解析](#3.3.5 代码解析)
[3.3.6 易错点分析](#3.3.6 易错点分析)
[3.3 案例3:Even Parity(UVA11464)(重点)](#3.3 案例3:Even Parity(UVA11464)(重点))
[3.3.1 题目描述](#3.3.1 题目描述)
[3.3.2 题目关键分析](#3.3.2 题目关键分析)
[(2) 为什么用二进制枚举?](#(2) 为什么用二进制枚举?)
[(3) 修改次数的计算](#(3) 修改次数的计算)
[3.3.3 解题思路详解](#3.3.3 解题思路详解)
[(1) 核心步骤](#(1) 核心步骤)
[(2) 关键推导公式推导](#(2) 关键推导公式推导)
[3.3.4 完整代码实现(ACM 模式)](#3.3.4 完整代码实现(ACM 模式))
[3.3.5 代码解析](#3.3.5 代码解析)
[(1) 二进制状态映射(第一行)](#(1) 二进制状态映射(第一行))
[(2) 合法性验证](#(2) 合法性验证)
[(3) 修改次数计算](#(3) 修改次数计算)
[3.3.6 易错点与避坑指南](#3.3.6 易错点与避坑指南)
[(1) 状态映射错误](#(1) 状态映射错误)
[(2) 推导公式边界处理遗漏](#(2) 推导公式边界处理遗漏)
[(3) 合法性验证不完整](#(3) 合法性验证不完整)
[(4) 最后一行未验证](#(4) 最后一行未验证)
[(5) 矩阵存储方式错误](#(5) 矩阵存储方式错误)
前言
在算法世界中,有一类算法看似 "简单粗暴",却能在很多场景下快速解决问题 ------ 这就是枚举算法。它不依赖复杂的数学推导或数据结构优化,而是通过 "穷尽所有可能情况,筛选出符合条件的解" 的思路,直接找到问题的答案。
很多初学者会认为枚举是 "低效""暴力" 的代名词,甚至不屑于使用。但实际上,枚举算法是解决问题的 "第一思路":当问题规模较小时,枚举能以最简单的逻辑快速得到结果;当问题复杂时,枚举也能作为基础框架,通过优化逐步提升效率。在算法竞赛中,枚举更是 "签到题" 和 "中等题" 的常用解法,掌握枚举的思路和优化技巧,能帮你快速拿下基础分。
本文将从枚举算法的本质出发,详细讲解枚举的核心思想、常见类型(普通枚举、二进制枚举)、解题步骤、优化技巧及实战案例。全文采用 C++ 实现,兼容 ACM 竞赛提交格式,同时包含大量实例、易错点分析和练习建议,无论你是编程新手还是竞赛选手,都能彻底掌握枚举算法的应用。下面就让我们正式开始吧!
一、枚举算法的本质与核心思想
1.1 什么是枚举算法?
枚举算法 (Enumeration Algorithm),又称 "穷举算法",是指将问题的所有可能解逐一列举出来,检查每个解是否符合问题的条件,最终筛选出所有有效解的算法。它的核心逻辑可以概括为:"遍历所有可能,验证条件是否成立"。
例如:
- 求 1~100 中所有能被 7 整除的数:枚举 1 到 100 的每个数,判断是否满足 "%7==0";
- 找出数组中所有和为 10 的两个数:枚举所有可能的数对,判断和是否为 10;
- 铺地毯问题中找到覆盖目标点的最上面地毯:枚举所有地毯,判断是否覆盖目标点,记录最后一个符合条件的地毯编号。
这些问题的共同特点是:可能解的范围明确,且验证条件简单。只要能明确 "枚举什么" 和 "如何验证",就能用枚举算法解决。
1.2 枚举算法的核心要素
要写出高效、正确的枚举代码,必须把握以下 3 个核心要素,缺一不可:
- 明确枚举对象:确定要遍历的 "可能解" 是什么(如数字、数对、地毯、日期等);
- 确定枚举范围:划定可能解的边界,避免遗漏或多余遍历(如 1~100、0~2ⁿ-1);
- 设计验证条件:判断当前枚举的可能解是否符合问题要求(如是否被 7 整除、是否覆盖目标点)。
1.3 枚举算法的适用场景
枚举算法并非 "万能算法",它有明确的适用场景,主要包括:
- 问题规模较小 :可能解的数量在 10⁵~10⁶以内,遍历不会超时;
- 可能解范围明确:能清晰界定枚举的边界(如日期范围、数组下标范围等);
- 验证条件简单:判断一个可能解是否有效时,时间复杂度低;
- 编程竞赛中的基础题:作为 "签到题" 或 "中等题" 的解法,快速拿分。
1.4 枚举算法的优缺点
优点
- 逻辑简单:无需复杂的算法设计,直接按 "列举 - 验证" 的思路编写,易于理解和实现;
- 正确性高:只要枚举范围不遗漏,验证条件正确,就能找到所有有效解,无逻辑漏洞;
- 调试方便:每一步枚举的过程都可跟踪,出现错误时能快速定位问题。
缺点
- 时间复杂度高:最坏情况下需要遍历所有可能解,时间复杂度通常为 O (k)(k 为可能解的数量),当 k 较大时(如 1e7 以上)会超时;
- 空间复杂度高:若需存储所有可能解,空间复杂度会随 k 增长而增加。
1.5 枚举算法的通用解题步骤
无论面对何种枚举问题,都可以按照以下 4 个步骤编写代码,确保逻辑清晰、无遗漏:
- 分析问题,明确枚举对象:回答 "要枚举什么?"(如枚举地毯、枚举日期、枚举二进制状态);
- 划定枚举范围,确定遍历顺序:回答 "从哪里枚举到哪里?按什么顺序枚举?"(如正序、逆序、二进制位序);
- 设计验证条件,筛选有效解:回答 "如何判断当前枚举的解是否符合要求?"(如覆盖判断、回文判断);
- 处理结果,输出答案:回答 "如何记录有效解?是否需要去重、排序或取最优解?"(如记录最后一个符合条件的解、统计有效解的数量)。
二、普通枚举:逐一枚举,筛选有效解
普通枚举是枚举算法的基础形式,指按顺序逐一枚举可能解,验证条件后筛选出有效解 。它的核心是**"顺序遍历 + 条件判断"**,适用于可能解范围连续、有序的场景。
2.1 案例 1:铺地毯(洛谷 P1003 NOIP2011 提高组)
2.1.1 题目分析
题目描述:
为了准备颁奖典礼,组织者在矩形区域(第一象限)铺设 n 张地毯,编号从 1 到 n,按编号从小到大顺序铺设(后铺的地毯覆盖前铺的)。每张地毯的信息包括左下角坐标 (a, b) 和 x 轴、y 轴方向的长度 (g, k)。要求找到覆盖目标点 (x, y) 的最上面的地毯编号,若未被覆盖则输出 - 1。
输入:
- 第一行:整数 n(地毯数量);
- 接下来 n 行:第 i+1 行包含 4 个整数 a_i, b_i, g_i, k_i(第 i 张地毯的左下角坐标和长度);
- 最后一行:两个整数 x, y(目标点坐标)。
输出:
覆盖目标点的最上面地毯编号,或 - 1。
示例输入:
3
1 0 2 3 # 地毯1:左下角(1,0),x长2(右到3),y长3(上到3)
0 2 3 3 # 地毯2:左下角(0,2),x长3(右到3),y长3(上到5)
2 1 3 3 # 地毯3:左下角(2,1),x长3(右到5),y长3(上到4)
2 2 # 目标点(2,2)示例输出:
3核心难点:
- 地毯是按顺序铺设的,后铺的覆盖前铺的,需找到 "最后一个覆盖目标点的地毯";
- 判断地毯是否覆盖目标点:目标点 (x,y) 需满足 "a ≤ x ≤ a+g 且 b ≤ y ≤ b+k"(左下角到右上角的矩形区域)。
题目链接: https://www.luogu.com.cn/problem/P1003
2.1.2 解题思路
- 明确枚举对象:枚举所有地毯(编号 1~n);
- 确定枚举范围与顺序 :
- 范围:1~n(所有地毯);
- 顺序:逆序枚举(从 n 到 1),因为后铺的地毯编号更大,一旦找到覆盖目标点的地毯,就是最上面的,可直接返回,无需继续枚举;
- 设计验证条件:判断目标点 (x,y) 是否在当前地毯的矩形区域内(a ≤ x ≤ a+g 且 b ≤ y ≤ b+k);
- 处理结果:若找到符合条件的地毯,立即返回编号;枚举结束未找到,返回 - 1。
2.1.3 完整代码实现(ACM 模式)
cpp
#include <iostream>
using namespace std;
const int N = 1e4 + 10; // 地毯数量最大为1e4
int a[N], b[N], g[N], k[N]; // 存储每张地毯的信息:a[i]左下角x,b[i]左下角y,g[i]x长,k[i]y长
// 查找覆盖(x,y)的最上面地毯编号
int findCarpet(int n, int x, int y) {
// 逆序枚举:从最后一张地毯开始,找到第一个覆盖的就是最上面的
for (int i = n; i >= 1; --i) {
// 验证条件:x在[a_i, a_i+g_i],y在[b_i, b_i+k_i]
if (a[i] <= x && x <= a[i] + g[i] && b[i] <= y && y <= b[i] + k[i]) {
return i; // 找到,立即返回
}
}
return -1; // 未找到
}
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; ++i) {
cin >> a[i] >> b[i] >> g[i] >> k[i];
}
int x, y;
cin >> x >> y;
cout << findCarpet(n, x, y) << endl;
return 0;
}2.1.4 代码解析
- 存储设计:用 4 个数组分别存储每张地毯的左下角坐标和长度,下标对应地毯编号(1~n),便于直接访问;
- 逆序枚举优化:相比正序枚举(需遍历所有地毯才能确定最后一个符合条件的),逆序枚举找到第一个符合条件的即可返回,时间复杂度从 O (n) 优化为 "最好 O (1),最坏 O (n)";
- 验证条件:严格按照矩形区域的定义判断,包含边界(题目明确了"边界和顶点上的点也算被覆盖")。
2.1.5 易错点分析
- 顺序错误:正序枚举后未记录最后一个符合条件的解,直接返回第一个,导致答案错误;
- 边界判断错误:将 "x ≤ a+g" 写成 "x < a+g",遗漏边界点(如地毯右上角点);
- 数组下标错误:地毯编号从 1 开始,但数组从 0 开始存储,导致访问错误(代码中数组下标从 1 开始,与地毯编号一致,避免此问题)。
2.2 案例 2:回文日期(洛谷 P2010 NOIP2016 普及组)
2.2.1 题目分析
题目描述:
用 8 位数字表示日期(YYYYMMDD),其中前 4 位是年份,中间 2 位是月份,最后 2 位是日期。一个日期是回文的,当且仅当 8 位数字从左到右读和从右到左读完全相同(如 20100102,即 2010 年 1 月 2 日)。给定两个 8 位日期 date1 和 date2,求两者之间(包含边界)的回文日期数量。
输入:
- 两行,每行一个 8 位整数(date1 ≤ date2,且均为有效日期)。
输出:
回文日期的数量。
示例输入 1:
20110101
20111231示例输出 1:
1 # 只有20111102(2011年11月2日)是回文日期示例输入 2:
20000101
20101231示例输出 2:
2 # 20011002(2001年10月2日)和20100102(2010年1月2日)核心难点:
- 直接枚举所有日期(date1 到 date2)会超时(若 date2-date1 达到 1e7,遍历耗时过长);
- 需验证日期的有效性(如月份 1~12,日期根据月份判断:2 月闰年 29 天,平年 28 天,4/6/9/11 月 30 天,其余 31 天);
- 回文日期的 8 位数字需满足 "第 i 位 = 第 9-i 位"(如第 1 位 = 第 8 位,第 2 位 = 第 7 位,...,第 4 位 = 第 5 位)。
题目链接: https://www.luogu.com.cn/problem/P2010
2.2.2 解题思路
- 优化枚举对象 :
- 直接枚举日期(date1 到 date2)效率低,可利用回文特性 "构造回文日期":8 位回文日期的前 4 位(年份)决定后 4 位(月份 + 日期),即 "YYYY" → "YYYY" + "反转 (YYYY 的前 4 位)" 的后 4 位?不,8 位回文的结构是 "ABCCBA"?不,8 位回文是 "ABCDEFGH" 满足 A=H,B=G,C=F,D=E,即前 4 位决定后 4 位:后 4 位是前 4 位的反转(如前 4 位 2010 → 后 4 位 0102,组成 20100102);
- 因此,枚举对象可改为 "前 4 位年份(YYYY)",构造出 8 位回文日期,再验证:
- 构造规则:8 位回文日期 = YYYY * 10000 + reverse (YYYY)(如 YYYY=2010 → reverse=0102 → 20100102);
- 验证条件 1:构造的日期是否在 date1, date2 范围内;
- 验证条件 2:构造的日期是否为有效日期(月份、日期合法);
- 确定枚举范围 :
- 年份范围:从 date1 的前 4 位(date1//10000)到 date2 的前 4 位(date2//10000);
- 例如 date1=20110101,date2=20111231 → 年份范围 2011~2011,只需枚举 2011 一个年份;
- 设计验证条件 :
- 回文构造:通过年份构造 8 位日期;
- 范围验证:构造的日期是否在 date1, date2;
- 有效性验证:拆分出月份(mm=date//100%100)和日期(dd=date%100),判断:
- 月份 mm∈1,12;
- 日期 dd∈1, 当月最大天数(需处理闰年 2 月);
- 处理结果:统计所有符合条件的回文日期数量。
2.2.3 关键辅助函数
1. 反转数字(如 2010 → 0102)
cpp
// 反转数字:如num=2010 → 返回102(注意:2010反转后是0102,即102,后续需补前导零到4位)
int reverseNum(int num) {
int res = 0;
while (num > 0) {
res = res * 10 + num % 10;
num /= 10;
}
return res;
}2. 判断闰年(用于确定 2 月天数)
cpp
// 判断是否为闰年:能被4整除且不能被100整除,或能被400整除
bool isLeapYear(int year) {
return (year % 4 == 0 && year % 100 != 0) || (year % 400 == 0);
}3. 验证日期有效性
cpp
// 验证日期是否有效:year-年份,mm-月份,dd-日期
bool isValidDate(int year, int mm, int dd) {
// 月份不合法
if (mm < 1 || mm > 12) return false;
// 每月最大天数
int maxDay[] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
// 闰年2月多1天
if (mm == 2 && isLeapYear(year)) maxDay[2] = 29;
// 日期不合法
return dd >= 1 && dd <= maxDay[mm];
}2.2.4 完整代码实现(ACM 模式)
cpp
#include <iostream>
using namespace std;
// 反转数字:如2010 → 102(后续补前导零到4位)
int reverseNum(int num) {
int res = 0;
while (num > 0) {
res = res * 10 + num % 10;
num /= 10;
}
return res;
}
// 判断是否为闰年
bool isLeapYear(int year) {
return (year % 4 == 0 && year % 100 != 0) || (year % 400 == 0);
}
// 验证日期有效性
bool isValidDate(int year, int mm, int dd) {
if (mm < 1 || mm > 12) return false;
int maxDay[] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
if (mm == 2 && isLeapYear(year)) maxDay[2] = 29;
return dd >= 1 && dd <= maxDay[mm];
}
// 统计[date1, date2]之间的回文日期数量
int countPalindromeDate(int date1, int date2) {
int count = 0;
// 枚举年份:从date1的前4位到date2的前4位
int startYear = date1 / 10000;
int endYear = date2 / 10000;
for (int year = startYear; year <= endYear; ++year) {
// 构造回文日期:YYYY * 10000 + 反转(YYYY)(补前导零到4位)
int reversed = reverseNum(year);
int palindromeDate = year * 10000 + reversed;
// 验证1:是否在范围内
if (palindromeDate < date1 || palindromeDate > date2) {
continue;
}
// 验证2:是否为有效日期
int mm = palindromeDate / 100 % 100; // 月份(第5-6位)
int dd = palindromeDate % 100; // 日期(第7-8位)
if (isValidDate(year, mm, dd)) {
count++;
}
}
return count;
}
int main() {
int date1, date2;
cin >> date1 >> date2;
cout << countPalindromeDate(date1, date2) << endl;
return 0;
}2.2.5 代码解析
- 枚举优化:通过 "年份构造回文日期",将枚举范围从 "可能的日期数" 缩减到 "年份数"(如 date1 到 date2 跨度 10 年,仅需枚举 10 个年份),效率大幅提升;
- 回文构造:利用 8 位回文的特性,前 4 位年份决定后 4 位,避免直接判断 8 位数字是否回文(减少计算量);
- 有效性验证:拆分月份和日期,结合闰年判断,确保构造的日期是真实存在的(如避免 20230230 这种无效日期)。
2.2.6 易错点分析
- 回文构造错误:将 "YYYY 反转" 直接作为后 4 位,但未补前导零(如 year=2000 → reversed=0 → 构造日期 20000000,而非 20000002);
- 闰年判断错误:遗漏 "能被 400 整除" 的条件(如 2000 年是闰年,1900 年不是);
- 范围验证顺序错误:先验证日期有效性,再判断是否在 date1, date2 范围内,导致无效日期也参与范围判断,浪费时间;
- 月份 / 日期拆分错误:将 mm 拆分为 "palindromeDate%10000/100"(正确),但代码中写成 "palindromeDate//100%100"(也是正确的,两种写法等价),需注意拆分逻辑。
2.3 案例 3:扫雷(洛谷 P2327 SCOI2005)
2.3.1 题目分析
题目描述:
扫雷游戏的棋盘是 n×2 的矩阵,第一列有若干地雷,第二列没有地雷。第二列的每个格子中的数字表示 "与该格子连通的 8 个格子中地雷的数量"(但由于是 n×2 矩阵,实际连通的是上下左右及斜对角的第一列格子)。给定第二列的数字,求第一列地雷的摆放方案数(地雷用 1 表示,无地雷用 0 表示)。
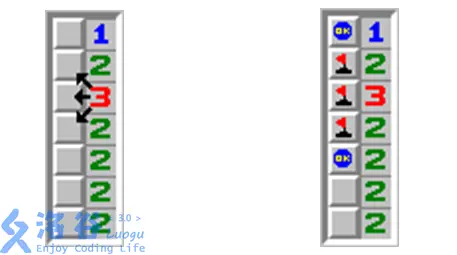
输入:
- 第一行:整数 n(矩阵行数,1≤n≤1e4);
- 第二行:n 个整数,依次为第二列格子的数字(b 1~b n)。
输出:
第一列地雷的摆放方案数(0、1 或 2)。
示例输入:
2
1 1示例输出:
2 # 方案1:第一列[0,1];方案2:第一列[1,0]核心难点:
- 第二列的数字由第一列相邻格子的地雷数量决定,需找到所有满足条件的第一列 01 序列;
- 第一列的地雷摆放具有 "连锁性":一旦确定第一行的状态(有雷 / 无雷),后续所有行的状态都能通过第二列的数字推导出来;
- 需验证推导的状态是否合法(地雷状态只能是 0 或 1),且最后一行的状态需满足边界条件。
题目链接: https://www.luogu.com.cn/problem/P2327
2.3.2 解题思路
- 明确枚举对象:枚举第一列第一行的状态(只有两种可能:0 或 1);
- 确定枚举范围与顺序 :
- 范围:仅两种可能(0 或 1);
- 顺序:分别枚举两种状态,独立验证是否能推导出合法的完整序列;
- 设计验证条件 :
- 推导规则:对于第 i 行(2≤i≤n),第一列的状态 a i = b i-1 - a i-1 - a i-2(因为第二列第 i-1 行的数字 b i-1 = a i-2 + a i-1 + a i,整理得 a i = b i-1 - a i-1 - a i-2);
- 合法性验证:推导的 a i 必须是 0 或 1,且最后一行的状态需满足 b n = a n-1 + a n(第二列最后一行的数字由第一列最后两行的地雷数量决定);
- 处理结果:统计两种枚举状态中,能推导出合法序列的数量。
2.3.3 完整代码实现(ACM 模式)
cpp
#include <iostream>
using namespace std;
const int N = 1e4 + 10;
int a[N]; // 第一列地雷状态:a[1]~a[n]
int b[N]; // 第二列的数字:b[1]~b[n]
int n;
// 验证第一行状态为first(0或1)时,是否存在合法方案
bool check(int first) {
a[1] = first;
// 推导第2~n行的状态
for (int i = 2; i <= n; ++i) {
// 公式:a[i] = b[i-1] - a[i-1] - a[i-2](a[0]默认0,因为第一行上方无格子)
a[i] = b[i-1] - a[i-1] - (i >= 2 ? a[i-2] : 0);
// 状态必须是0或1,否则不合法
if (a[i] < 0 || a[i] > 1) {
return false;
}
}
// 验证最后一行:b[n]必须等于a[n-1] + a[n](a[n+1]默认0)
return b[n] == a[n-1] + a[n];
}
int main() {
cin >> n;
for (int i = 1; i <= n; ++i) {
cin >> b[i];
}
// 枚举第一行的两种可能状态,统计合法方案数
int count = 0;
count += check(0); // 第一行无地雷
count += check(1); // 第一行有地雷
cout << count << endl;
return 0;
}2.3.4 代码解析
- 枚举简化:仅枚举第一行的两种状态,而非所有 n 行的 2ⁿ种可能,时间复杂度从 O (2ⁿ) 骤降为 O (n)(n≤1e4,完全可行);
- 推导逻辑:利用第二列数字与第一列相邻状态的关系,通过递推公式推导后续状态,避免暴力枚举;
- 边界处理:第一行上方无格子(a 0=0),最后一行下方无格子(a n+1=0),确保推导和验证的完整性。
2.3.5 易错点分析
- 边界条件遗漏:推导 a 2 时未考虑 a 0=0(第一行上方无格子),导致公式错误;
- 状态合法性判断延迟:未在推导 a i 后立即判断是否为 0 或 1,而是等到最后验证,导致无效状态继续推导,浪费时间;
- 最后一行验证错误:将验证条件写成 "b n == a n"(忽略 a n-1),导致判断错误。
三、二进制枚举:用位表示状态,枚举所有子集
二进制枚举是枚举算法的进阶形式,指用一个整数的二进制位表示 "是否选择某个元素",通过遍历所有可能的整数,枚举所有子集或组合情况 。它的核心是**"位运算 + 状态映射"**,适用于 "元素是否被选择" 的二选一场景。
3.1 二进制枚举的核心原理
3.1.1 状态映射
假设有 n 个元素(编号 0~n-1),用一个 n 位的二进制数表示一个子集:
- 二进制数的第 i 位(从 0 开始,右数第 i+1 位)为 1,表示选择第 i 个元素;
- 二进制数的第 i 位为 0,表示不选择第 i 个元素。
例如:
- n=3,元素为 1,2,3;
- 二进制数 011(十进制 3)→ 第 0 位和第 1 位为 1 → 子集 1,2;
- 二进制数 101(十进制 5)→ 第 0 位和第 2 位为 1 → 子集 1,3;
- 二进制数 111(十进制 7)→ 所有位为 1 → 子集 1,2,3。
3.1.2 枚举范围
对于 n 个元素,二进制数的范围是 0~2ⁿ-1(共 2ⁿ种可能,对应所有子集,包括空集):
- 0 → 二进制 000...0 → 空集;
- 2ⁿ-1 → 二进制 111...1 → 全集。
3.1.3 位运算操作
在二进制枚举中,常用的位运算操作包括:
- 判断第 i 位是否为 1 :(st >> i) & 1(st 为当前二进制数,将 st 右移 i 位,与 1 按位与,结果为 1 表示第 i 位是 1);
- 遍历所有位:循环 i 从 0 到 n-1,检查每一位的状态;
- 统计 1 的个数 :计算当前子集的大小(如**__builtin_popcount(st),C++ 内置函数,统计 st 的二进制中 1 的个数**)。
3.2 案例 1:子集(力扣 78. 子集)
3.2.1 题目分析
题目描述:
给你一个整数数组 nums(元素互不相同),返回该数组所有可能的子集(幂集)。解集不能包含重复的子集,可以按任意顺序返回。
输入:
- 一行,整数数组 nums(如 1,2,3)。
输出:
- 所有子集,如 \[,1,2,1,2,3,1,3,2,3,1,2,3]。
核心难点:
- 枚举所有子集,包括空集和全集;
- 确保子集不重复(由于元素互不相同,二进制枚举天然不重复)。
题目链接: https://leetcode.cn/problems/subsets/description/
3.2.2 解题思路
- 明确枚举对象:枚举二进制数 st(0~2ⁿ-1,n 为数组长度);
- 确定枚举范围 :st 从 0 到 (1<<n)-1(1<<n 表示 2ⁿ);
- 设计状态映射与验证 :
- 映射规则:st 的第 i 位为 1 → 选择 nums i 加入当前子集;
- 验证:无需额外验证(所有子集均有效);
- 处理结果:对每个 st,生成对应的子集,加入结果列表。
3.2.3 完整代码实现(核心代码模式)
cpp
#include <vector>
using namespace std;
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> result;
int n = nums.size();
// 枚举所有二进制状态:0 ~ 2^n - 1
for (int st = 0; st < (1 << n); ++st) {
vector<int> currentSubset;
// 检查每一位是否为1,若是则加入子集
for (int i = 0; i < n; ++i) {
if ((st >> i) & 1) {
currentSubset.push_back(nums[i]);
}
}
result.push_back(currentSubset);
}
return result;
}
};3.2.4 代码解析
- 二进制状态遍历 :for (int st = 0; st < (1 << n); ++st) 遍历所有 2ⁿ种状态,对应所有子集;
- 位运算判断 :(st >> i) & 1 检查第 i 位是否为 1,若为 1 则将 nums i 加入当前子集;
- 结果收集:每个 st 对应一个子集,直接加入结果列表,无需去重(元素互不相同,状态唯一)。
3.2.5 易错点分析
- 枚举范围错误 :将**(1 << n)写成(1 << n) - 1**,导致遗漏全集(st=2ⁿ-1);
- 位运算顺序错误 :将**(st >> i) & 1写成st >> (i & 1)**,逻辑错误;
- 数组下标错误:i 从 1 开始遍历,而非 0,导致遗漏第一个元素。
3.3 案例 2:费解的开关(洛谷 P10449)
3.3.1 题目分析
题目描述:
有一个 5×5 的灯阵,每个灯有 "开(1)" 和 "关(0)" 两种状态。按下一个灯的开关,会使该灯及其上下左右相邻的灯状态反转(1 变 0,0 变 1)。给定初始状态,求最少需要按多少次开关才能使所有灯变亮(全 1),若超过 6 次则输出 - 1。
输入:
- 第一行:整数 n(测试用例数,n≤500);
- 接下来 n 组数据:每组 5 行,每行 5 个字符('0' 或 '1'),表示灯阵的初始状态。
输出:
- 每组数据输出最少按开关次数,或 - 1。
示例输入:
3
00111
01011
10001
11010
11100
11101
11101
11110
11111
11111
01111
11111
11111
11111
11111示例输出:
3
2
-1核心难点:
- 灯的状态反转具有 "连锁性",按下一个灯影响多个灯;
- 直接枚举所有灯的按法(2²⁵种)会超时(2²⁵≈3.3e7,n=500 时总操作量过大);
- 需找到最优解(最少按次数),且超过 6 次则无效。
题目链接:https://www.luogu.com.cn/problem/P10449
3.3.2 解题思路
- 优化枚举对象 :
- 第一行的按法决定后续所有行的按法:要使第一行的灯全亮,第二行的开关必须按 "第一行未亮的灯正下方的灯"(因为第一行的灯只能被第二行的开关影响,第一行自身的开关已确定);
- 因此,枚举对象仅为 "第一行的按法"(5 个灯,共 2⁵=32 种可能),而非所有 25 个灯;
- 确定枚举范围:第一行的按法(0~31,对应 32 种状态);
- 设计验证与计算步骤 :
- 备份初始状态:每次枚举第一行按法前,备份原始灯阵(避免修改原始数据);
- 模拟第一行按法:根据当前按法,反转第一行对应灯及其相邻灯的状态;
- 推导后续行按法 :
- 对于第 i 行(2~5),遍历每一列 j:若第 i-1 行第 j 列的灯是灭的(0),则必须按第 i 行第 j 列的开关(反转该灯及其相邻灯);
- 统计按次数:记录总按次数,若超过 6 次则跳过;
- 验证结果:检查最后一行的灯是否全亮,若全亮则更新最少按次数;
- 处理结果:每组测试用例取最少按次数,若未找到则输出 - 1。
3.3.3 关键辅助函数
1. 反转灯的状态(按开关)
cpp
// 反转(x,y)位置的灯及其相邻灯的状态(x,y从0开始,5×5矩阵)
void flip(int x, int y, vector<vector<int>>& grid) {
// 定义当前灯及上下左右的坐标偏移
int dx[] = {0, 0, 0, 1, -1};
int dy[] = {0, 1, -1, 0, 0};
for (int d = 0; d < 5; ++d) {
int nx = x + dx[d];
int ny = y + dy[d];
// 确保坐标在5×5范围内
if (nx >= 0 && nx < 5 && ny >= 0 && ny < 5) {
grid[nx][ny] ^= 1; // 异或1反转状态(0→1,1→0)
}
}
}3.3.4 完整代码实现(ACM 模式)
cpp
#include <iostream>
#include <vector>
#include <cstring>
#include <climits>
using namespace std;
// 反转(x,y)及其相邻灯的状态
void flip(int x, int y, vector<vector<int>>& grid) {
int dx[] = {0, 0, 0, 1, -1};
int dy[] = {0, 1, -1, 0, 0};
for (int d = 0; d < 5; ++d) {
int nx = x + dx[d];
int ny = y + dy[d];
if (nx >= 0 && nx < 5 && ny >= 0 && ny < 5) {
grid[nx][ny] ^= 1;
}
}
}
// 计算初始状态grid下的最少按次数
int minPresses(vector<vector<int>>& original) {
int minCnt = INT_MAX;
// 枚举第一行的所有按法(0~31,32种可能)
for (int st = 0; st < (1 << 5); ++st) {
vector<vector<int>> grid = original; // 备份初始状态
int cnt = 0; // 记录当前按次数
// 1. 模拟第一行的按法
for (int j = 0; j < 5; ++j) {
if ((st >> j) & 1) { // 第j列需要按
flip(0, j, grid);
cnt++;
if (cnt > 6) break; // 超过6次,无需继续
}
}
if (cnt > 6) continue;
// 2. 推导第2~5行的按法
for (int i = 1; i < 5; ++i) {
for (int j = 0; j < 5; ++j) {
// 若上一行第j列是灭的,必须按当前行第j列的开关
if (grid[i-1][j] == 0) {
flip(i, j, grid);
cnt++;
if (cnt > 6) break;
}
}
if (cnt > 6) break;
}
if (cnt > 6) continue;
// 3. 验证最后一行是否全亮
bool allOn = true;
for (int j = 0; j < 5; ++j) {
if (grid[4][j] == 0) {
allOn = false;
break;
}
}
if (allOn && cnt < minCnt) {
minCnt = cnt;
}
}
// 若未找到有效方案,返回-1
return minCnt == INT_MAX ? -1 : minCnt;
}
int main() {
int n;
cin >> n;
while (n--) {
vector<vector<int>> original(5, vector<int>(5));
// 读取初始状态:'0'→0(灭),'1'→1(亮)
for (int i = 0; i < 5; ++i) {
string s;
cin >> s;
for (int j = 0; j < 5; ++j) {
original[i][j] = s[j] - '0';
}
}
// 计算并输出最少按次数
int res = minPresses(original);
cout << res << endl;
}
return 0;
}3.3.5 代码解析
- 枚举优化:仅枚举第一行的 32 种按法,后续行按法由前一行状态推导,时间复杂度从 O (2²⁵) 骤降为 O (32×5×5) = O (800),每组测试用例耗时极短;
- 状态备份:每次枚举前备份原始灯阵,避免修改原始数据(多组测试用例或多次枚举需独立状态);
- 剪枝优化:按次数超过 6 次时立即跳过,避免无效计算;
- 结果验证:最后检查第五行是否全亮,确保方案有效。
3.3.6 易错点分析
- 状态未备份:直接修改原始灯阵,导致后续枚举使用的状态错误;
- 反转范围错误:flip 函数中遗漏 "当前灯自身"(dx 0=0, dy 0=0),导致状态反转不完整;
- 剪枝不及时:未在按次数超过 6 次时立即跳过,导致无效计算;
- 最后一行验证错误:检查前 4 行是否全亮,而非最后一行,导致判断错误。
3.3 案例3:Even Parity(UVA11464)(重点)
3.3.1 题目描述
题目核心要求:
给定一个 n×n 的 01 矩阵(每个元素非 0 即 1),你可以将某些 0 修改为 1(不允许 1 修改为 0 ),使得最终矩阵成为 "偶数矩阵"。偶数矩阵的定义是:每个元素的上下左右相邻元素(若存在)之和为偶数。请计算最少的修改次数,若无法实现则输出 - 1。
输入格式:
- 第一行:数据组数 T(T≤30);
- 每组数据:
- 第一行:正整数 n(1≤n≤15);
- 接下来 n 行:每行 n 个非 0 即 1 的整数,代表初始矩阵。
输出格式:
- 每组数据输出 "Case X: 最少修改次数",若无解则输出 "Case X: -1"。
示例输入:
3
3
0 0 0
0 0 0
0 0 0
3
0 0 0
1 0 0
0 0 0
3
1 1 1
1 1 1
0 0 0示例输出:
Case 1: 0
Case 2: 3
Case 3: -1题目链接: https://www.luogu.com.cn/problem/UVA11464
3.3.2 题目关键分析
(1)偶数矩阵的核心性质
对于矩阵中的任意元素a[i][j](行号 i、列号 j,从 1 开始),其相邻元素之和为偶数,即:
- 若 i=1 且 j=1(左上角,仅右下相邻):**a[i+1][j] + a[i][j+1]**为偶数;
- 若 i=n 且 j=n(右下角,仅左上相邻):a[i-1][j] + a[i][j-1] 为偶数;
- 普通位置(上下左右均存在):**a[i-1][j] + a[i+1][j] + a[i][j-1] + a[i][j+1]**为偶数;
但通过推导可发现:矩阵的第一行状态确定后,后续所有行的状态均可唯一推导。原因如下:
对于第 i 行第 j 列的元素a[i][j](i≥2),其上方元素**a[i-1][j]**的相邻元素之和需为偶数。a[i-1][j]的相邻元素包括a[i-2][j](上方,若存在)、a[i][j](下方)、a[i-1][j-1](左方)、a[i-1][j+1](右方)。整理可得推导公式:a[i][j] = a[i-2][j] ^ a[i-1][j-1] ^ a[i-1][j+1]("^" 为异或运算,异或结果为 0 表示和为偶数,1 表示和为奇数,符合偶数矩阵要求)。
(2) 为什么用二进制枚举?
n 的最大值为 15,第一行有 n 个元素,每个元素有 "保持原状态" 或 "修改为 1" 两种可能(但需满足 "不允许 1 变 0")。因此第一行的可能状态数为 2ⁿ,当 n=15 时为 32768 种,完全在枚举范围内(不会超时)。
(3) 修改次数的计算
修改次数仅统计 "0 变 1" 的次数:对于每个位置,若初始状态为 0 且最终状态为 1,计数 + 1;若初始状态为 1 且最终状态为 0,属于非法操作(直接排除该方案)。
3.3.3 解题思路详解
(1) 核心步骤
- 枚举对象:第一行的所有可能状态(用二进制数表示,第 j 位为 1 表示第一行第 j 列最终状态为 1);
- 枚举范围:二进制数从 0 到 (1<<n)-1(共 2ⁿ种状态);
- 状态合法性验证 :
- 第一步:检查第一行状态是否合法(仅允许 0 变 1,即初始为 1 的位置,最终状态不能为 0);
- 第二步:根据第一行状态,用推导公式计算后续所有行的状态,每一步检查合法性(初始为 1 的位置不能变为 0);
- 修改次数计算:统计所有 "0 变 1" 的次数;
- 结果筛选:在所有合法方案中,选择修改次数最少的,若无合法方案则输出 - 1。
(2) 关键推导公式推导
以第 i 行第 j 列(i≥2,1≤j≤n)为例:
- 偶数矩阵要求**a[i-1][j]**的上下左右相邻元素之和为偶数;
- 相邻元素包括:上方a[i-2][j](若 i≥3)、下方a[i][j]、左方a[i-1][j-1](若 j≥2)、右方a[i-1][j+1](若 j≤n-1);
- 当 i=2 时,**a[i-2][j]**不存在(视为 0);当 j=1 时,**a[i-1][j-1]**不存在(视为 0);当 j=n 时,**a[i-1][j+1]**不存在(视为 0);
- 异或运算特性:"偶数个 1 异或为 0,奇数个 1 异或为 1",恰好对应 "和为偶数 / 奇数";
- 最终推导公式:a[i][j] = (i >= 3 ? a[i-2][j] : 0) ^ (j >= 2 ? a[i-1][j-1] : 0) ^ (j <= n-1 ? a[i-1][j+1] : 0)
3.3.4 完整代码实现(ACM 模式)
cpp
#include <iostream>
#include <cstring>
#include <climits>
using namespace std;
const int N = 20; // n最大为15,预留冗余
int n;
int initial[N][N]; // 初始矩阵(1-based)
int current[N][N]; // 当前枚举的最终矩阵(1-based)
// 检查并计算:第一行状态为st时的修改次数,非法返回-1
int check(int st) {
memset(current, 0, sizeof current);
int modify = 0; // 修改次数(0变1的次数)
// 1. 处理第一行,验证合法性并计算修改次数
for (int j = 1; j <= n; ++j) {
// 提取st的第j位(注意:st的第0位对应j=1,第1位对应j=2,...)
int bit = (st >> (j - 1)) & 1;
current[1][j] = bit;
// 合法性检查:初始为1,最终为0 → 非法
if (initial[1][j] == 1 && bit == 0) {
return -1;
}
// 计算修改次数:初始为0,最终为1 → +1
if (initial[1][j] == 0 && bit == 1) {
modify++;
}
}
// 2. 推导第2~n行的状态,验证合法性并计算修改次数
for (int i = 2; i <= n; ++i) {
for (int j = 1; j <= n; ++j) {
// 推导公式:current[i][j] = 上上行[j] ^ 上一行[j-1] ^ 上一行[j+1]
int up_up = (i >= 3) ? current[i-2][j] : 0; // 上上行(i-2),不存在为0
int up_left = (j >= 2) ? current[i-1][j-1] : 0; // 上一行左列(j-1),不存在为0
int up_right = (j <= n-1) ? current[i-1][j+1] : 0; // 上一行右列(j+1),不存在为0
current[i][j] = up_up ^ up_left ^ up_right;
// 合法性检查:初始为1,最终为0 → 非法
if (initial[i][j] == 1 && current[i][j] == 0) {
return -1;
}
// 计算修改次数:初始为0,最终为1 → +1
if (initial[i][j] == 0 && current[i][j] == 1) {
modify++;
}
}
}
// 3. 额外验证:最后一行的每个元素是否满足偶数矩阵要求(避免推导遗漏)
for (int j = 1; j <= n; ++j) {
int sum = 0;
// 最后一行的元素,仅需检查上方、左方、右方(无下方)
if (n >= 2) sum += current[n-1][j]; // 上方
if (j >= 2) sum += current[n][j-1]; // 左方
if (j <= n-1) sum += current[n][j+1]; // 右方
if (sum % 2 != 0) { // 之和为奇数,不满足偶数矩阵
return -1;
}
}
return modify; // 返回合法方案的修改次数
}
int main() {
int T;
cin >> T;
for (int case_num = 1; case_num <= T; ++case_num) {
cin >> n;
// 读取初始矩阵(1-based存储,方便后续推导)
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= n; ++j) {
cin >> initial[i][j];
}
}
int min_modify = INT_MAX; // 最少修改次数
// 枚举第一行的所有可能状态(0 ~ 2^n - 1)
for (int st = 0; st < (1 << n); ++st) {
int res = check(st);
if (res != -1 && res < min_modify) {
min_modify = res;
}
}
// 输出结果
if (min_modify == INT_MAX) {
printf("Case %d: -1\n", case_num);
} else {
printf("Case %d: %d\n", case_num, min_modify);
}
}
return 0;
}3.3.5 代码解析
(1) 二进制状态映射(第一行)
- 用整数
st表示第一行的最终状态:st的第j-1位(从 0 开始)对应第一行第j列的状态(1 表示最终为 1,0 表示最终为 0); - 例如 n=3,
st=5(二进制101)→ 第一行状态为[1,0,1](j=1 对应 bit0=1,j=2 对应 bit1=0,j=3 对应 bit2=1)。
(2) 合法性验证
- 第一行验证:初始为 1 的位置,最终状态不能为 0(不允许 1 变 0);
- 后续行验证:推导过程中,每一步都检查 "初始为 1→最终为 0" 的情况,一旦出现立即返回 - 1;
- 最后一行额外验证:推导完成后,检查最后一行是否满足偶数矩阵要求(避免因推导公式的边界处理遗漏问题)。
(3) 修改次数计算
- 仅统计 "初始为 0 且最终为 1" 的位置,每次满足条件时
modify++; - 合法方案的修改次数返回后,更新
min_modify(初始为无穷大),最终取最小值。
3.3.6 易错点与避坑指南
(1) 状态映射错误
- 问题 :将
st的第 j 位对应第一行第 j 列(而非第 j-1 位),导致第一行状态错位; - 解决 :明确
st的位序与列号的对应关系(bit0→j=1,bit1→j=2,...,bit (n-1)→j=n),提取位时用(st >> (j-1)) & 1。
(2) 推导公式边界处理遗漏
- 问题:忽略 "i=2 时无上行""j=1 时无左列""j=n 时无右列" 的情况,直接使用公式导致错误;
- 解决 :用三目运算符判断边界,不存在的相邻元素视为 0(如
up_up = (i >= 3) ? current[i-2][j] : 0)。
(3) 合法性验证不完整
- 问题:仅验证第一行,未验证后续行的 "1 变 0" 情况,导致非法方案被计入;
- 解决:推导后续行时,每计算一个位置的状态,立即检查 "初始为 1→最终为 0",若有则返回 - 1。
(4) 最后一行未验证
- 问题:推导完成后未检查最后一行是否满足偶数矩阵要求,导致部分非法方案被误判为合法;
- 解决:额外遍历最后一行,计算每个元素的相邻元素之和,确保为偶数。
(5) 矩阵存储方式错误
- 问题:使用 0-based 存储(行号从 0 开始),导致推导公式中的行号计算混乱;
- 解决:采用 1-based 存储(行号、列号从 1 开始),与推导公式中的 "i-1""i-2" 对应更直观,减少边界错误。
总结
枚举算法的关键不是 "暴力遍历",而是 "聪明地枚举"------ 通过分析问题特性,减少枚举次数,提升验证效率。在实际应用中,枚举往往是解决问题的 "第一思路":当问题规模较小时,枚举能快速得到结果;当问题复杂时,枚举也能作为基础框架,逐步优化。
如果本文对你有帮助,欢迎点赞、收藏、转发,也欢迎在评论区交流讨论~