引言:无处不在的AI朋友
想象一下这样的场景:
- 你正在撰写一封工作邮件,键盘上方自动跳出几个简洁得体的句子开头,帮你省下不少时间。
- 你对一个复杂的科学概念感到困惑,在搜索引擎中输入问题后,得到的不再是零散的链接列表,而是一段清晰、有逻辑的解释,仿佛一位博学的老师在为你娓娓道来。
- 你突发奇想,想写一首关于"夏日蝉鸣与数据流"的诗,只需输入几个关键词,一首风格独特的诗歌便跃然屏上。
- 你正在学习一门新语言,一个AI伙伴不仅能纠正你的语法错误,还能与你进行流畅的对话练习,甚至模仿莎士比亚的风格与你互动。
这些看似科幻的场景,如今正通过"大语言模型"这一核心技术,悄然融入我们的日常生活。你可能已经与它们打过交道,比如ChatGPT、DeepSeek、豆包、文心一言、通义千问或是 Claude,但你是否好奇,这些能够"理解"和"生成"人类语言的AI,究竟是如何工作的?它们是拥有思想的"硅基生命",还是一个无比精巧的"文字预测机器"?
本文将从"语言模型"这个最基本的概念说起,理解AI是如何从"鹦鹉学舌"一步步进化到"通情达理";然后,我们会聚焦于那个被誉为"AI界瑞士军刀"的神奇架构------Transformer,看看它是如何彻底改变游戏规则的;接着,我们会亲手体验如何与这些模型进行有效沟通,掌握提问的"艺术";再然后,我们会探讨一个激动人心的现象------"缩放法则",它揭示了为何模型越大往往越聪明;最后,我们会回归理性,冷静地审视这些强大工具的局限性,并展望它们如何演变为更具自主性的"AI智能体"。
第一章:从"鹦鹉"到"学者"------语言模型的进化之路
在深入大语言模型之前,我们必须先理解一个更基础的概念:语言模型(Language Model)。你可以把它想象成一个"文字预测器"或"语言概率计算器"。
1.1 语言模型的本质:预测下一个词
想象一下,你正在和朋友聊天。你说:"今天天气真......",你的朋友几乎可以毫不犹豫地接上"好"或者"糟糕"。这是因为人类大脑在长期的语言实践中,形成了对词语之间关联性的深刻直觉。我们知道"天气"后面常常跟着"好"、"坏"、"晴朗"、"阴沉"等词,而几乎不会跟着"香蕉"或"微积分"。
语言模型的核心任务,就是模拟这种直觉。 给定一个词序列(比如"今天天气真"),它会计算出下一个词最可能出现的概率分布。
- P(好 | 今天天气真) = 80%
- P(糟糕 | 今天天气真) = 15%
- P(热 | 今天天气真) = 4%
- P(香蕉 | 今天天气真) = 0.0001%
- ...
然后,模型会根据这个概率分布,选择一个词(可能是概率最高的"好",也可能是随机采样)作为输出。接着,它会把新生成的词加入上下文,继续预测再下一个词("今天天气真好,我们去..."),如此往复,就能生成一整段连贯的文字。
所以,从根本上说,大语言模型就是一个极其复杂的"下一个词预测器"。它并不真正"理解"语言的含义,但它通过海量数据的学习,掌握了词语之间统计上的、模式化的关联,从而能够生成在人类看来非常"合理"甚至"智慧"的文本。
1.2 从n-gram到神经网络:模型的进化简史
语言模型并非新鲜事物,它的进化史就是一部AI处理语言能力的进化史。我们可以将其大致分为三个阶段:
阶段一:规则与统计------n-gram模型("记忆碎片")
早期的语言模型非常简单朴素,叫做 n-gram模型。它的核心思想是:"一个词出现的概率,只取决于它前面的n-1个词"。
- Unigram (1-gram): 只看单个词的出现频率。比如,"好"这个词本身就比"糟糕"出现得多。但它完全忽略了上下文,所以预测能力很弱。
- Bigram (2-gram): 看前面1个词。它会统计"天气 真"后面跟"好"的频率是多少,跟"糟糕"的频率是多少。这比Unigram好多了,但视野太窄。
- Trigram (3-gram): 看前面2个词。"今天 天气 真"后面跟什么?视野稍宽。
- n-gram: 以此类推。
n-gram模型的优缺点:
- 优点:原理简单,易于实现和理解。
- 缺点 (致命的):
- 数据稀疏问题:语言是无穷无尽的。对于一个较长的、不常见的词序列(比如"量子计算机的未来发展前景"),很可能在训练数据中从未出现过,导致概率为0,模型无法处理。
- 上下文窗口太短:n值不能太大。n=5就已经需要海量的存储空间来记录所有可能的5元组组合,而且大部分组合根本不会出现。这就意味着模型无法利用距离较远的上下文信息。例如,在句子"巴黎是法国的首都。它以其艺术和文化闻名。"中,要理解"它"指代的是"巴黎",n-gram模型几乎做不到,因为"巴黎"离"它"太远了。
你可以把n-gram模型想象成一个记忆力超强但只会死记硬背短语片段的人。它能流利地背诵常见的问候语,但一旦遇到稍微复杂或新颖的句子,就立刻露怯。
阶段二:理解语义------循环神经网络(RNN)与长短期记忆(LSTM)("记忆的河流")
为了解决n-gram的缺点,研究人员引入了神经网络 ,特别是循环神经网络(Recurrent Neural Network, RNN)。
RNN的核心思想是引入一个"隐藏状态(hidden state)",这个状态就像一条贯穿整个句子的"记忆河流"。当你逐个处理词语时,RNN会将当前词和之前的"记忆"结合起来,更新这条"河流",并用它来预测下一个词。
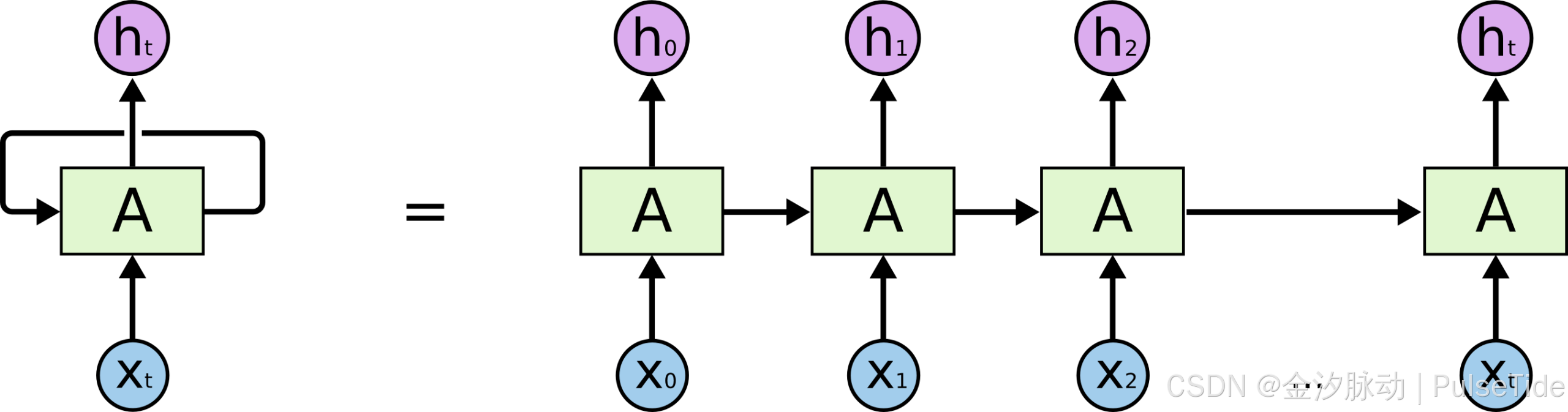
(图1: RNN结构。同一个神经网络单元在时间上被重复使用,隐藏状态h在时间步之间传递信息。)
这样,RNN理论上可以记住任意长度的上下文,因为它将所有历史信息都压缩在了隐藏状态里。
然而,现实很骨感。标准的RNN存在一个严重的梯度消失/爆炸问题。在训练过程中,需要通过"反向传播"算法来调整模型参数。当信息需要跨越很长的距离(比如几十个甚至上百个词)时,误差信号在反向传递过程中会变得极其微弱(消失)或极其巨大(爆炸),导致模型根本无法有效地学习到长距离的依赖关系。
长短期记忆网络(Long Short-Term Memory, LSTM) 是RNN的一个重大改进。它通过引入精巧的"门控机制"(输入门、遗忘门、输出门),像一个智能的水闸一样,有选择地让信息流入、流出或保留在记忆单元中,从而在很大程度上缓解了梯度消失问题,能够更好地捕捉长距离依赖。
RNN/LSTM的优缺点:
- 优点:能够处理变长序列,理论上能捕捉长距离依赖,引入了对语义的初步"理解"(通过向量表示)。
- 缺点 :
- 顺序计算,无法并行:RNN必须一个词一个词地处理,前一个词的计算结果是后一个词计算的前提。这使得训练速度非常慢,尤其是在处理长文本时。
- 长距离依赖依然困难:虽然LSTM有所改善,但当距离过长时(比如上千个词),性能依然会显著下降。
- 信息瓶颈:所有历史信息都被压缩在一个固定大小的向量里,对于非常长的文本,这个向量可能无法承载所有必要的信息。
RNN/LSTM就像是一个记忆力不错但性格内向的学者,他需要按顺序听完你的每一句话,才能综合思考并回答你。如果你的问题很长,他可能会忘记你开头说了什么。
阶段三:全局视野与并行计算------Transformer的诞生("一目了然")
2017年,一篇名为《Attention is All You Need》的论文横空出世,彻底改变了自然语言处理领域的格局。它提出的 Transformer 架构,一举解决了RNN/LSTM的上述痛点,并为大语言模型的爆发奠定了基础。
Transformer的核心思想是"自注意力机制(Self-Attention)" 。它抛弃了RNN的顺序处理模式,让模型在处理任何一个词时,都能同时 关注到输入序列中的所有其他词,并根据它们之间的相关性,动态地分配注意力权重。
想象一下,你正在阅读这句话:"The animal didn't cross the street because it was too tired." 你想知道"it"指代的是"animal"还是"street"?一个聪明的读者会立刻将注意力集中在"animal"和"tired"上,因为"动物会累"是常识。自注意力机制就是让模型自动学会做这件事。

(图2: 自注意力机制可视化。在计算"it"的表示时,模型会赋予"animal"很高的注意力权重(用粗线表示),而对"street"的权重则很低。)
Transformer的优势(革命性的):
- 并行化:由于不再依赖顺序计算,整个输入序列可以一次性喂给模型,所有词的表示可以同时计算。这极大地加速了训练过程,使得训练超大规模模型成为可能。
- 强大的长距离依赖建模:无论两个词相隔多远,自注意力机制都能直接建立它们之间的联系,没有任何信息衰减。
- 可扩展性:其结构非常适合在现代GPU/TPU等硬件上进行大规模并行计算。
Transformer的出现,就像是给语言模型戴上了一副"全景眼镜",让它能够一眼看清整个句子的全局信息,并快速做出判断。正是基于Transformer架构,我们才有了今天所熟知的GPT、BERT、PaLM等大语言模型。
1.3 小结:语言模型的核心能力
到此,我们对语言模型的进化有了一个清晰的脉络。无论架构如何变化,其核心目标始终未变:给定上下文,预测下一个最可能出现的词 。大语言模型之所以"大",是因为它在Transformer架构的基础上,通过海量数据 和巨大参数量,将这个"预测"能力推向了极致,从而展现出我们所惊叹的"智能"行为。
接下来,我们将深入Transformer的内部,看看这个神奇的"全景眼镜"究竟是如何工作的。
第二章:解构"全景眼镜"------Transformer架构深度剖析
Transformer架构是大语言模型的基石。为了真正理解LLMs的强大之处,我们必须深入其内部,看看这个被誉为"AI界瑞士军刀"的模块是如何运作的。别担心,我们会用最直观的比喻和图示,一步步拆解它的奥秘。
2.1 整体蓝图:编码器-解码器 vs. 纯解码器
标准的Transformer模型(如原始论文中提出的)包含两个主要部分:编码器(Encoder) 和 解码器(Decoder)。
- 编码器-解码器架构 :主要用于序列到序列(Seq2Seq) 任务,如机器翻译。编码器负责读取并"理解"输入序列(如一句英文),将其编码成一个富含语义的向量表示;解码器则根据这个表示,逐步生成输出序列(如对应的中文)。
然而,像GPT这样的主流大语言模型,采用的是纯解码器(Decoder-only) 架构。因为它只需要一个任务:根据前面的词,预测下一个词。它不需要一个独立的编码器来处理一个完整的输入句子,而是将整个提示(prompt)和已经生成的部分都视为一个连续的输入序列,由解码器来一并处理并预测后续内容。
因此,我们的重点将放在 Transformer解码器 的核心模块上。
2.2 核心引擎:自注意力机制(Self-Attention)
自注意力是Transformer的心脏。让我们用一个具体的例子来理解它。
假设输入序列只有三个词: "Thinking", "Machines", "Learn"。我们的目标是为"Machines"这个词生成一个新的、富含上下文信息的表示。
步骤1:从词到向量(Embedding)
首先,每个词都会被转换成一个固定长度的词嵌入向量(Word Embedding)。这个词向量就像一个词的"身份证",包含了这个词的语义信息。
- Thinking -> 向量 V1
- Machines -> 向量 V2
- Learn -> 向量 V3
步骤2:生成Q, K, V(查询、键、值)
Transformer的聪明之处在于,它不直接使用原始的词嵌入向量进行计算,而是通过三个不同的线性变换(权重矩阵Wq, Wk, Wv),为每个词生成三组新的向量:
- Query (Q,查询向量):代表当前词在"寻找"什么信息。可以理解为"我想知道关于我的哪些信息?"。
- Key (K,键向量):代表当前词"提供"什么信息。可以理解为"我能提供关于我的什么信息?"。
- Value (V,值向量):代表当前词的实际内容信息。可以理解为"我的具体内容是什么?"。
所以,对于"Machines"这个词:
- Q2 = V2 * Wq
- K2 = V2 * Wk
- V2 = V2 * Wv
同样,我们也会为"Thinking"和"Learn"生成各自的Q1, K1, V1 和 Q3, K3, V3。
步骤3:计算注意力分数
现在,我们要计算"Machines"对序列中每个词(包括自己)的注意力分数。方法很简单:计算"Machines"的Query(Q2)与每个词的Key(K1, K2, K3)的点积(Dot Product)。
- Score(Q2, K1) = Q2 · K1 ("Machines"对"Thinking"的关注度)
- Score(Q2, K2) = Q2 · K2 ("Machines"对自身的关注度)
- Score(Q2, K3) = Q2 · K3 ("Machines"对"Learn"的关注度)
点积的结果可以衡量两个向量的相似度。相似度越高,说明"Machines"越应该关注那个词。
步骤4:缩放与Softmax
这些原始分数通常很大,直接使用会导致梯度不稳定。因此,会将它们除以一个缩放因子(通常是Key向量维度的平方根),然后通过 Softmax 函数进行归一化。Softmax的作用是将这些分数转换成一个概率分布,所有权重加起来等于1。
- Weight1 = Softmax(Score(Q2, K1) / sqrt(dk))
- Weight2 = Softmax(Score(Q2, K2) / sqrt(dk))
- Weight3 = Softmax(Score(Q2, K3) / sqrt(dk))
这些权重就代表了在为"Machines"生成新表示时,应该从"Thinking"、"Machines"、"Learn"各自的Value(V1, V2, V3)中"吸收"多少信息。
步骤5:加权求和,得到输出
最后,将每个Value向量乘以其对应的权重,然后全部加起来,就得到了"Machines"这个词经过自注意力机制"洗礼"后的新表示(Output for Machines)。
- Output = Weight1 * V1 + Weight2 * V2 + Weight3 * V3
这个新的Output向量,不仅包含了"Machines"本身的语义,还融合了上下文"Thinking"和"Learn"的相关信息。模型通过这种方式,为序列中的每个词都生成了一个全新的、富含全局上下文信息的表示。
多头注意力(Multi-Head Attention)
为了捕捉不同类型的依赖关系(例如,一个头关注主谓关系,另一个头关注指代关系),Transformer会并行地执行多次上述的自注意力计算,每次使用不同的权重矩阵(Wq, Wk, Wv)。这就是多头注意力(Multi-Head Attention)。最后,将所有头的输出拼接起来,再经过一次线性变换,得到最终的输出。这大大增强了模型的表达能力。
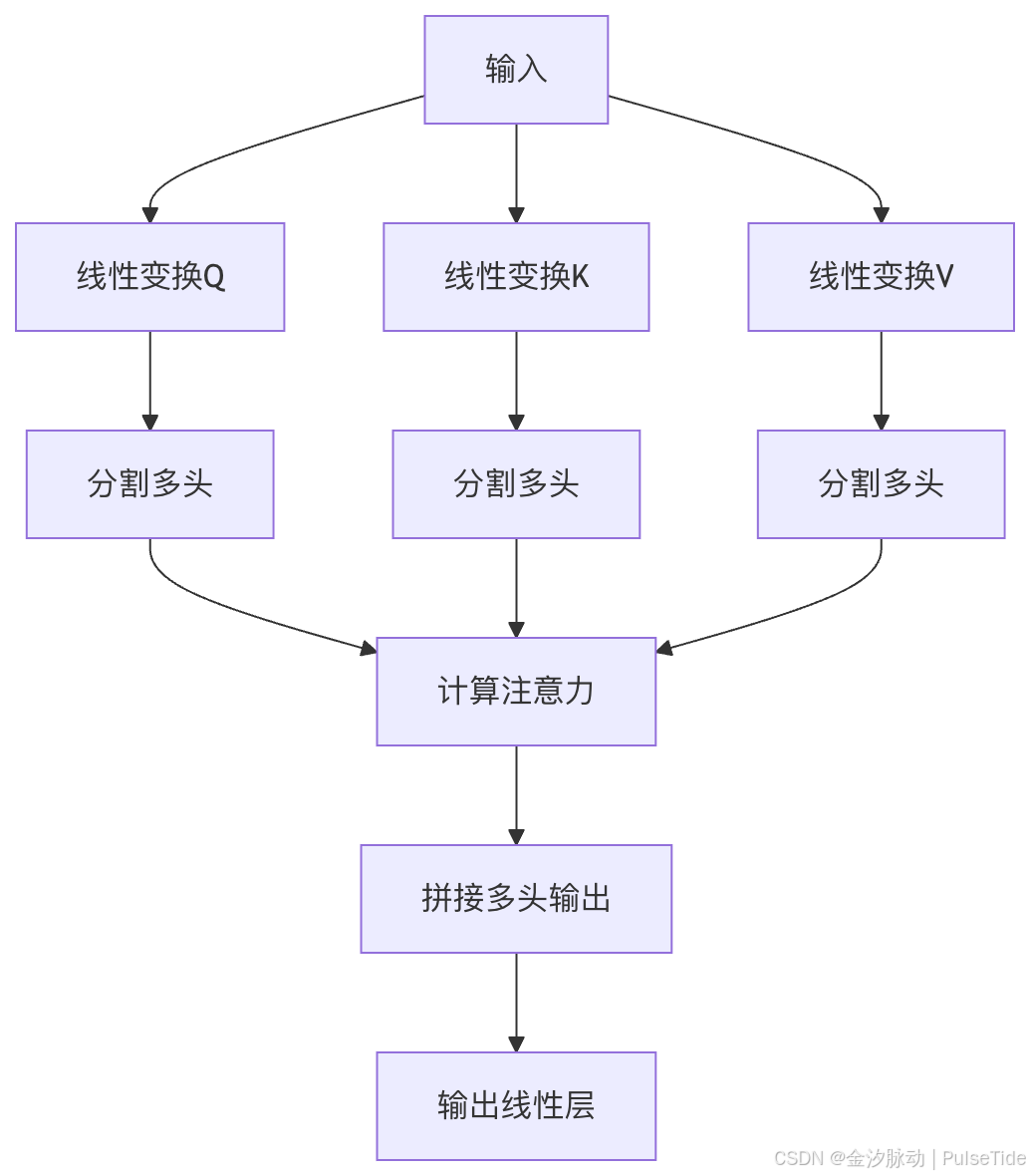
(图3: 多头自注意力机制。多个注意力头并行工作,每个头学习输入序列中不同子空间的表示,最后将结果拼接。)
2.3 解码器的其他关键组件
除了自注意力机制,Transformer解码器还包含几个使其更强大的组件。
掩码自注意力(Masked Self-Attention)
在语言模型的生成任务中,有一个铁律:模型在预测第t个词时,只能看到第1到t-1个词,绝不能看到第t个及之后的词。否则就成了作弊。
为了保证这一点,解码器中的自注意力层会使用一个掩码(Mask)。这个掩码是一个上三角矩阵,在计算注意力分数后、应用Softmax之前,会将所有非法连接(即未来词对当前词的影响)的分数设置为负无穷大。经过Softmax后,这些非法连接的权重就变成了0。
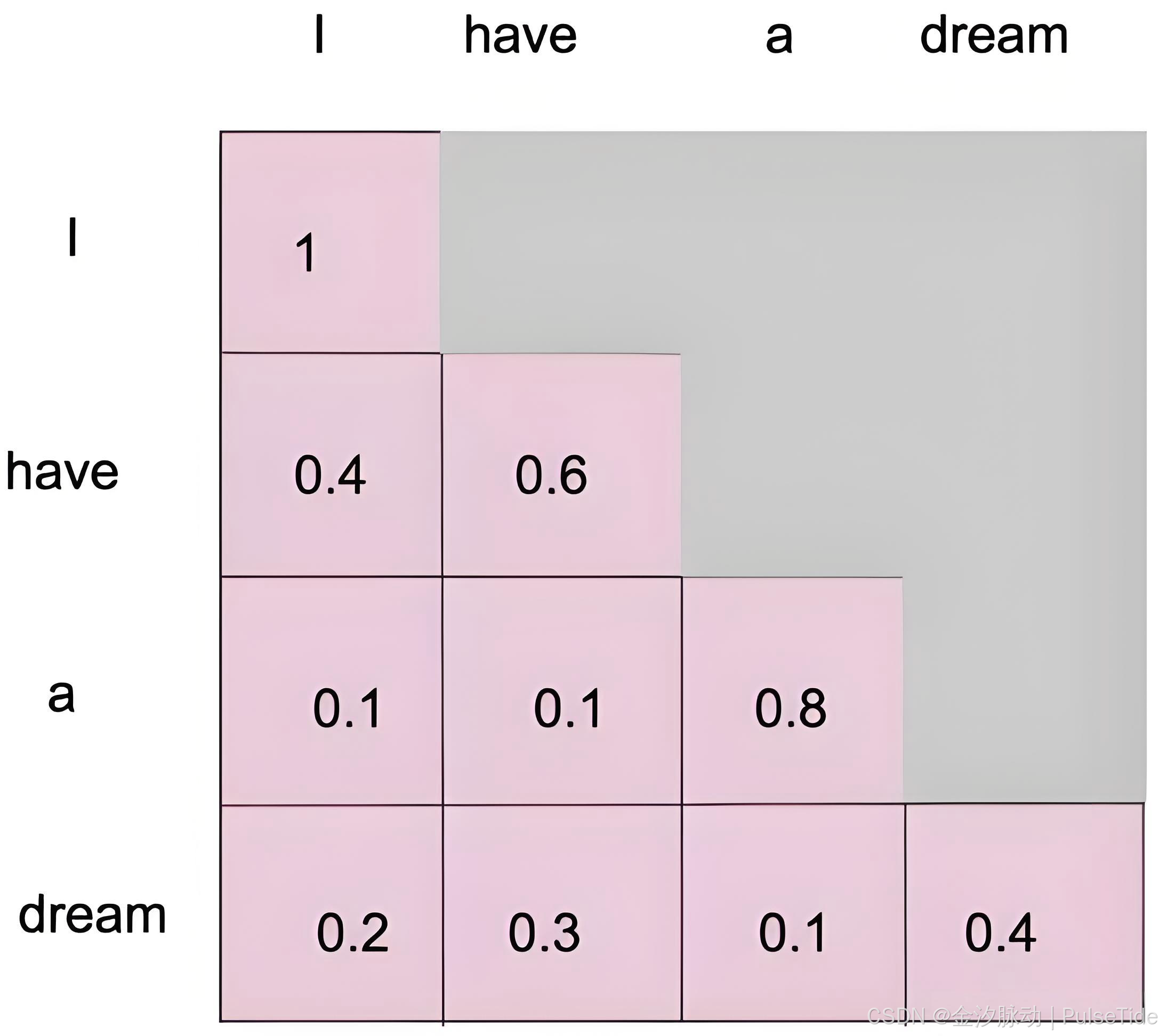
(图4: 掩码自注意力。在预测第二个词(位置2)时,模型只能看到第一个词(位置1)的信息,对第三个词(位置3)的注意力被完全屏蔽(权重为0)。)
前馈神经网络(Feed-Forward Network, FFN)
在多头注意力之后,每个位置的输出还会通过一个独立的、简单的全连接前馈神经网络 。这个网络的作用是对自注意力提取出的特征进行进一步的非线性变换和加工,增加模型的表达能力。值得注意的是,这个FFN在序列的每个位置上是独立且相同的。
层归一化(Layer Normalization)与残差连接(Residual Connection)
为了稳定和加速深层网络的训练,Transformer在每个子层(自注意力层和FFN层)之后都应用了残差连接 (将输入直接加到输出上)和层归一化。这些技术是现代深度学习模型能够堆叠数十甚至上百层而不崩溃的关键。
2.4 从词到位置:位置编码(Positional Encoding)
这里有一个至关重要的问题:Transformer本身没有序列的概念! 自注意力机制在计算时,是对所有词一视同仁、同时处理的。这意味着,如果我们将输入序列的词顺序打乱,只要词的集合不变,自注意力的计算结果就不会改变。这显然是不行的,因为"狗追猫"和"猫追狗"的意思天差地别。
为了解决这个问题,Transformer引入了位置编码(Positional Encoding) 。这是一种与词嵌入维度相同的向量,它包含了词在序列中位置 的信息。在将词嵌入输入到模型之前,会先将其与对应的位置编码相加。
位置编码可以是固定的(如使用正弦和余弦函数生成),也可以是可学习的。无论哪种方式,它都让模型能够区分不同位置上的相同词语。
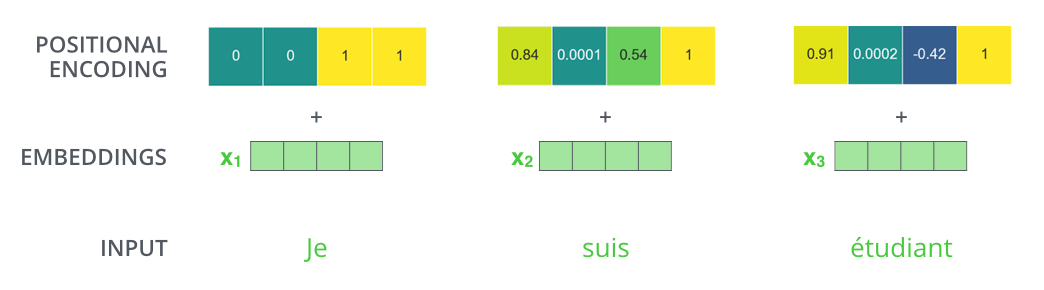
(图5: 位置编码。每个词的最终输入表示 = 词嵌入(语义) + 位置编码(位置)。)
2.5 Transformer解码器的完整流程
现在,让我们把所有组件拼凑起来,看看一个Transformer解码器层是如何工作的:
- 输入:一个词序列,每个词由词嵌入+位置编码构成。
- 掩码多头自注意力层:为序列中每个词计算新的表示,这个表示融合了它前面所有词的信息。
- Add & Norm:将自注意力的输出与输入进行残差连接,然后进行层归一化。
- 前馈神经网络层:对每个位置的表示进行独立的非线性变换。
- Add & Norm:再次进行残差连接和层归一化,得到该解码器层的最终输出。
- 堆叠:这个输出会被送入下一个解码器层,进行更深层次的特征提取。GPT-3这样的模型有96层之多!
最终,经过所有解码器层处理后,每个位置的输出向量会被送入一个线性层(Linear Layer) 和 Softmax,从而得到一个词汇表上所有词的概率分布。模型根据这个分布,选择概率最高的词(或通过采样)作为下一个输出词。这个新词被添加到输入序列末尾,整个过程重复进行,直到生成完整的文本或达到停止条件。
2.6 小结:Transformer的魔力
Transformer架构的强大,在于它用一种优雅的方式,同时解决了并行计算 、长距离依赖 和全局信息整合这三大难题。自注意力机制就像一个动态的、可学习的聚光灯,让模型在处理每个词时,都能精准地聚焦到对它最有用的上下文信息上。这种机制不仅高效,而且极具表现力,为大语言模型的涌现能力(Emergent Abilities)提供了肥沃的土壤。
现在,我们已经了解了大语言模型的"大脑"是如何构建的。接下来,让我们将理论付诸实践,看看如何与这位AI朋友进行有效的对话。
第三章:与AI共舞------如何与大语言模型进行有效交互
理解了大语言模型的原理,我们就可以更聪明地与它互动。与LLM的交互,远不止于简单地"输入问题,得到答案"。它更像是一场精心编排的对话艺术。掌握一些核心技巧,能让你的AI伙伴从"答非所问"变得"得心应手"。
3.1 提示工程(Prompt Engineering):引导AI思维的魔法
提示(Prompt) 就是你给大语言模型的输入指令。提示的质量,直接决定了输出的质量。提示工程(Prompt Engineering) 就是设计和优化提示词的艺术和科学。
基础技巧
-
明确任务(Be Specific):
- 差:"告诉我关于光合作用。"
- 好:"用通俗易懂的语言,向一名10岁的孩子解释光合作用是什么,以及它为什么对地球上的生命至关重要。"
- 分析:好的提示明确了任务(解释)、受众(10岁孩子)和关键点(是什么、为什么重要)。
-
提供上下文(Provide Context):
- 差:"帮我写个邮件。"
- 好:"我需要给我的经理李明写一封邮件,请求在下周三休假一天,去参加一个重要的家庭活动。邮件需要礼貌、简洁,并提供我的紧急联系方式。"
- 分析:上下文(收件人、请假原因、具体日期、额外要求)让模型能生成高度定制的内容。
-
给出示例(Use Examples / Few-shot Learning) :
大语言模型非常擅长"举一反三"。通过在提示中给出1-3个输入-输出的示例,可以极大地引导模型遵循你想要的格式或风格。
-
提示 :
将以下非正式的句子改写成正式的商务邮件用语: 非正式:嘿,那个报告搞定了吗? 正式:您好,请问那份报告是否已经完成? 非正式:我这边卡住了,能帮我看一下吗? 正式:我在处理过程中遇到了一些困难,不知您是否方便提供一些指导? 现在请改写:那个会议几点开始? -
输出: "您好,请问会议的开始时间是几点?"
-
-
设定角色(Assign a Role) :
让模型"扮演"一个特定角色,可以激活其相关的知识和语气。
- 差:"帮我分析一下这篇文章。"
- 好:"你现在是一位经验丰富的科技专栏作家,请以犀利且风趣的笔触,分析一下这篇关于AI最新进展的文章。"
高级技巧
-
思维链(Chain-of-Thought, CoT) :
对于复杂的推理问题,直接问答案往往效果不佳。要求模型"一步步思考"(Let's think step by step)可以显著提升其推理能力。
- 问题:"小明有5个苹果,他吃了2个,然后又买了3倍于他剩下的苹果数量。他现在一共有多少个苹果?"
- 普通提示:直接问答案。模型可能给出错误答案(如5-2+3=6)。
- CoT提示:"请一步步思考这个问题:小明有5个苹果... 问题描述 ... 他现在一共有多少个苹果?"
- 期望输出:"好的,让我们一步步思考。首先,小明有5个苹果。他吃了2个,所以剩下5-2=3个苹果。然后,他又买了3倍于他剩下的苹果数量,即3 * 3 = 9个苹果。因此,他现在一共有3 + 9 = 12个苹果。"
-
分隔符(Use Delimiters) :
使用清晰的分隔符(如```、###、---)来划分提示的不同部分,可以避免指令和内容混淆。
-
提示 :
您是一位专业的文案编辑。请对以下段落进行校对,修正语法和拼写错误,并使其语言更流畅。 ###待编辑文本### 这个项目对我们公司来说非常重要,因为它将帮助我们开拓新市场。我们需要确保所有团队成员都全力以赴。 ###待编辑文本###
-
3.2 模型"人格"与温度(Temperature)
大语言模型的输出并非完全确定。你可以通过调整一些参数来控制其"性格"。
- 温度(Temperature) :
- 低温度(如0.1-0.5):模型会更"保守"和"确定",总是选择概率最高的词。输出更可预测、更事实性,但可能缺乏创意和多样性。适合问答、摘要等任务。
- 高温度(如0.8-1.5):模型会更"大胆"和"随机",会探索概率较低的词。输出更具创意、更有趣,但也可能产生事实性错误或荒谬的内容。适合写故事、写诗、头脑风暴等任务。
想象温度就像一个创造力旋钮。你需要根据任务需求来调节它。
3.3 并非万能:理解模型的"认知"局限
与LLM交互时,务必牢记一点:它不是一个全知全能的神,而是一个基于统计的模式匹配大师。
- 它没有记忆(在单次对话中):虽然它可以记住你当前对话的历史(取决于上下文窗口长度),但它不会记得你昨天问过什么。每次对话对它来说都是"第一次"。
- 它会"一本正经地胡说八道"(幻觉):当遇到不确定的问题时,模型不会说"我不知道",而是会基于其学到的模式,编造一个听起来很合理的答案。这是当前LLM最大的挑战之一。
- 它没有常识和情感:它能谈论情感,但并不真正感受情感。它的"常识"来源于训练数据中的统计共现,而非对世界的物理理解。
因此,在使用LLM的输出时,尤其是在涉及重要决策、事实核查或敏感信息时,批判性思维和人工审核是必不可少的。把它看作一个极其高效的"智能助手"或"创意伙伴",而不是一个可以完全信赖的"权威"。
3.4 小结:成为AI的"指挥家"
与大语言模型的交互,本质上是通过精心设计的提示,引导其庞大的参数网络朝向你期望的方向进行"下一个词预测"。掌握提示工程的技巧,理解模型的内在机制和局限,你就能从一个被动的使用者,转变为主动的"指挥家",指挥这场由数十亿参数参与的宏大交响乐,为你奏出最动听的乐章。
第四章:大即是美?------大语言模型的缩放法则与局限性
大语言模型之所以"大",不仅仅是为了炫耀。在AI领域,一个被反复验证的经验法则就是:模型越大、数据越多、算力越强,模型的性能就越好 。这个现象被称为"缩放法则(Scaling Laws)"。然而,"大"并非没有代价,它也带来了显著的局限性。
4.1 缩放法则:性能随规模增长的密码
由OpenAI等机构的研究发现,大语言模型的性能(通常用在测试集上的损失函数值来衡量)与三个关键因素------模型参数量(N) 、训练数据量(D) 和 计算量(C) ------之间存在着近似幂律的关系。
简单来说,公式可以表示为:
Loss ≈ (N^α + D^β + C^γ)
其中,α, β, γ 是一些常数。这意味着,无论是增加模型大小、增加数据,还是增加计算量,都能平滑地、可预测地降低模型的损失(即提升性能)。
缩放法则带来的启示
-
涌现能力(Emergent Abilities):这是缩放法则最神奇的地方。当模型规模小到一定程度时,它可能完全无法完成某些复杂任务(如多步推理、代码生成)。但一旦模型规模突破某个临界阈值,这些能力会突然"涌现"出来,而且能力会随着规模的继续增大而不断增强。这就像一个量变引起质变的过程。
- 例子:一个小模型可能只能做简单的加法,但一个超大模型(如GPT-4)却能理解并执行复杂的编程指令,甚至通过律师资格考试。这种能力在小模型上是完全看不到的。
-
数据效率:在同等参数量下,用更高质量、更多样化的数据进行训练,效果往往优于简单地堆砌数据量。这催生了数据"配比"(Data Mixture)的研究,即如何最优地混合不同来源的数据(网页、书籍、代码、对话等)。
-
计算最优模型:对于给定的计算预算(C),存在一个最优的模型大小(N)和数据量(D)的组合,使得最终模型的性能最好。盲目地追求超大模型并不总是最有效率的做法。
4.2 大语言模型的局限性:光环下的阴影
尽管缩放法则带来了惊人的进步,但大语言模型依然存在深刻的、甚至是根本性的局限。
1. 幻觉(Hallucination)
这是最广为人知的问题。模型会自信地生成与事实不符、逻辑错误或完全虚构的信息。根源在于其训练目标是最大化下一个词的概率,而不是追求事实的准确性。只要生成的文本在统计上"流畅"且"合理",它就完成了任务。
- 后果:在医疗、法律、新闻等对准确性要求极高的领域,幻觉可能带来灾难性后果。
2. 缺乏真正的理解与推理
如前所述,LLM是一个"模式匹配器",而非"推理机"。它的推理能力(如CoT展示的)更多是模仿了训练数据中看到的推理模式,而非基于对世界的一致性理解。它很容易被逻辑陷阱迷惑,也无法进行真正的因果推理。
- 例子:问"如果把一头大象放进冰箱,需要几步?"一个理解物理世界常识的人会指出问题的荒谬性。而LLM可能会一本正经地回答:"三步:打开冰箱门,把大象放进去,关上冰箱门。"
3. 知识的静态性与滞后性
大语言模型的知识完全来源于其训练数据截止日期之前的数据。它无法获取训练之后发生的事件(如最近的新闻、新发布的科学发现)。虽然可以通过"检索增强生成(Retrieval-Augmented Generation, RAG)"等技术来弥补,但这增加了系统的复杂性。
4. 偏见与有害内容
模型会忠实地反映其训练数据中存在的社会偏见、刻板印象和有害言论。如果训练数据中充斥着性别歧视、种族歧视或虚假信息,模型就有可能在输出中放大这些问题。对齐(Alignment)研究(如RLHF)正是为了解决这个问题而生。
5. 资源消耗与环境影响
训练和运行超大模型需要消耗巨量的计算资源和电力,对环境造成不小的负担。这引发了关于AI可持续发展的广泛讨论。
6. 安全性与滥用风险
强大的生成能力也可能被滥用于生成虚假信息(深度伪造文本)、网络钓鱼邮件、恶意代码等,带来严重的安全和社会风险。
4.3 前沿探索:超越当前的局限
研究界正积极探索各种方法来克服这些局限:
- 检索增强生成(RAG):将LLM与一个外部知识库(如维基百科、公司文档)结合。在生成答案前,先检索相关的真实信息,再让LLM基于这些信息生成回答,从而减少幻觉。
- 微调(Fine-tuning)与人类反馈强化学习(RLHF):在通用模型的基础上,用特定领域的高质量数据进行微调,或利用人类的偏好反馈来训练一个奖励模型,再用强化学习来优化LLM,使其输出更符合人类的期望(更安全、更有用、更无害)。
- 多模态模型:将语言模型与视觉、听觉等其他模态的模型结合(如GPT-4V, Gemini),让AI能"看图说话",获得更丰富的世界理解。
- 具身智能(Embodied AI):让AI代理在物理世界或模拟环境中进行交互和学习,通过与环境的互动来获得真正的因果理解和常识。
4.4 小结:理性的乐观
缩放法则告诉我们,规模是通向更强AI的一条有效路径。但我们也必须清醒地认识到,仅仅依靠规模的扩大,并不能解决所有问题,尤其是关于"理解"、"常识"和"安全"等核心挑战。未来的进步,将更多地依赖于架构创新、数据质量、对齐技术 以及多学科的融合 。我们需要一种理性的乐观:拥抱其巨大的潜力,同时警惕其固有的风险。
第五章:迈向自主------大语言模型作为AI智能体
到目前为止,我们讨论的大语言模型更像是一个被动的、响应式的工具。你提问,它回答。然而,LLM的真正潜力,或许在于成为AI智能体(AI Agent) 的核心"大脑",赋予机器前所未有的自主规划和行动能力。
5.1 什么是AI智能体?
一个AI智能体,是一个能够感知(Perceive)环境、思考(Reason/Plan)、行动(Act) ,并能从经验中学习(Learn) 的自主实体。它不再仅仅是回答问题,而是能主动地、有目标地完成复杂的任务。
- 一个简单的AI智能体循环 :
- Goal(目标): "帮我预订下周五从北京到上海的机票。"
- Perceive: 智能体感知到用户的指令。
- Plan: 智能体(由LLM驱动)开始规划:需要知道具体日期、时间偏好、舱位要求;需要调用一个航班搜索API。
- Act: 智能体调用API,获取航班列表。
- Perceive: 智能体接收到API返回的数据。
- Plan/Act: 智能体分析数据,选择最符合要求的航班,并生成预订请求。
- Act: 智能体调用预订API,完成操作。
- Return: 向用户返回预订成功的确认信息。
在这个过程中,LLM扮演了规划者(Planner) 和 控制器(Controller) 的角色。
5.2 LLM作为智能体核心的优势
- 强大的通用知识库:LLM在预训练阶段吸收了人类文明的绝大部分知识,这为智能体提供了丰富的背景知识来理解任务和制定计划。
- 卓越的推理与规划能力:通过思维链等技术,LLM能够分解复杂任务,制定多步骤计划。
- 自然语言接口:LLM天然地能理解和生成自然语言,这使得人与智能体的交互变得极其直观和自然。用户可以用日常语言下达复杂的指令。
- 工具使用能力(Tool Use):LLM可以被设计成能够调用外部工具(API、计算器、代码解释器、搜索引擎等),从而弥补其在精确计算、实时信息获取等方面的不足。
5.3 智能体架构的关键组件
一个基于LLM的智能体通常包含以下几个核心部分:
- 大脑(LLM):负责高层次的推理、规划、决策和自然语言生成。
- 记忆(Memory) :
- 短期记忆:即当前的上下文窗口,存储正在进行的任务信息。
- 长期记忆:一个外部向量数据库,存储过往的经验、用户偏好、重要事实等,可以通过检索来增强LLM的上下文。
- 工具箱(Tools):一系列可被LLM调用的外部函数或API,如Web搜索、代码执行、数据库查询、发送邮件等。
- 行动器(Actuator):负责执行LLM规划出的具体操作,比如调用某个工具。
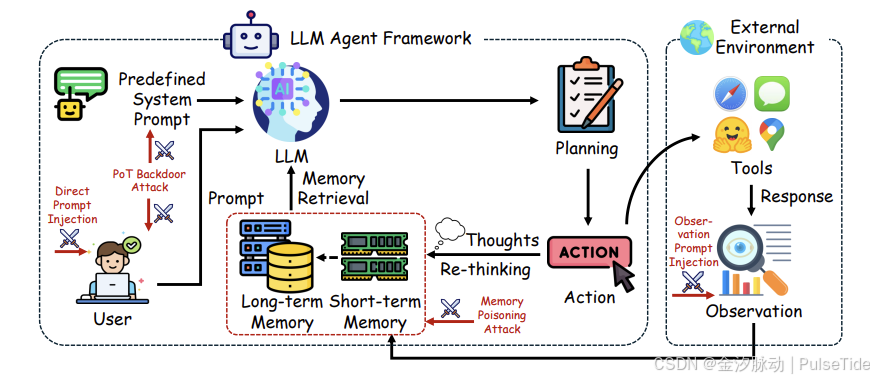
(图6: 一个典型的基于LLM的AI智能体架构。LLM作为核心,通过记忆和工具与环境进行交互。)
5.4 实例:一个更复杂的智能体
想象一个"个人AI研究员"智能体:
- 目标: "帮我调研一下'基于Transformer的医学图像分割'领域的最新进展,总结三篇关键论文,并指出未来的研究方向。"
- 智能体的行动流程 :
- 规划: LLM将任务分解为:a) 搜索相关论文;b) 阅读并理解论文摘要;c) 提取关键信息(方法、数据集、结果);d) 比较分析;e) 总结未来方向。
- 行动: 调用学术搜索引擎API(如Semantic Scholar)。
- 感知/规划: 获取论文列表后,选择最相关的几篇。调用PDF解析工具获取全文或摘要。
- 行动/推理: LLM阅读并分析每篇论文的内容。
- 整合/输出: LLM将分析结果整合成一份结构化的报告。
在这个过程中,LLM不仅是信息的生成者,更是整个研究过程的项目经理。
5.5 挑战与未来
尽管前景广阔,但构建可靠的AI智能体仍面临巨大挑战:
- 幻觉的放大:如果LLM在规划阶段就产生了错误的步骤,后续的所有行动都会建立在错误的基础上。
- 工具使用的可靠性:LLM需要精确地理解工具的接口和参数,错误的调用会导致任务失败。
- 安全与失控风险:一个拥有行动能力的自主智能体,如果其目标与人类不一致,可能会造成无法预料的后果。确保智能体的安全性和可控性是至关重要的研究方向。
- 长期规划与反思:当前的智能体多擅长处理短期、明确的任务。如何让它们具备长期目标、进行自我反思和调整,是通向更通用人工智能(AGI)的关键一步。
5.6 小结:从工具到伙伴
大语言模型作为AI智能体的核心,正在将AI从一个被动的工具,转变为一个主动的、能干的伙伴。它不再是"问答机器",而是能够"思考-行动-学习"循环的自主实体。虽然道路充满挑战,但这一方向无疑代表了AI发展的未来。我们正站在一个新时代的门槛上,人与AI的关系将变得更加协作和共生。
结语:与智能共处的未来
我们走过了从语言模型的基本概念,到Transformer架构的精妙设计,再到与AI交互的艺术,以及对其规模法则、局限性的深刻反思,最后展望了它作为自主智能体的未来图景。
大语言模型是一个令人惊叹的技术奇迹,它凝聚了人类在数学、计算机科学、语言学等多个领域的智慧。然而,它终究是由人类创造、为人类服务的工具。它的"智能"是统计的、模式化的,而非意识的、体验式的。
作为这个时代的见证者和参与者,我们应当:
- 拥抱其力量: 利用LLM来提升效率、激发创意、探索未知。
- 保持其清醒: 永远不要放弃自己的批判性思维,对AI的输出保持审慎。
- 引导其向善: 积极参与关于AI伦理、安全和治理的讨论,确保技术的发展符合人类的共同利益。
未来已来,而探索才刚刚开始。