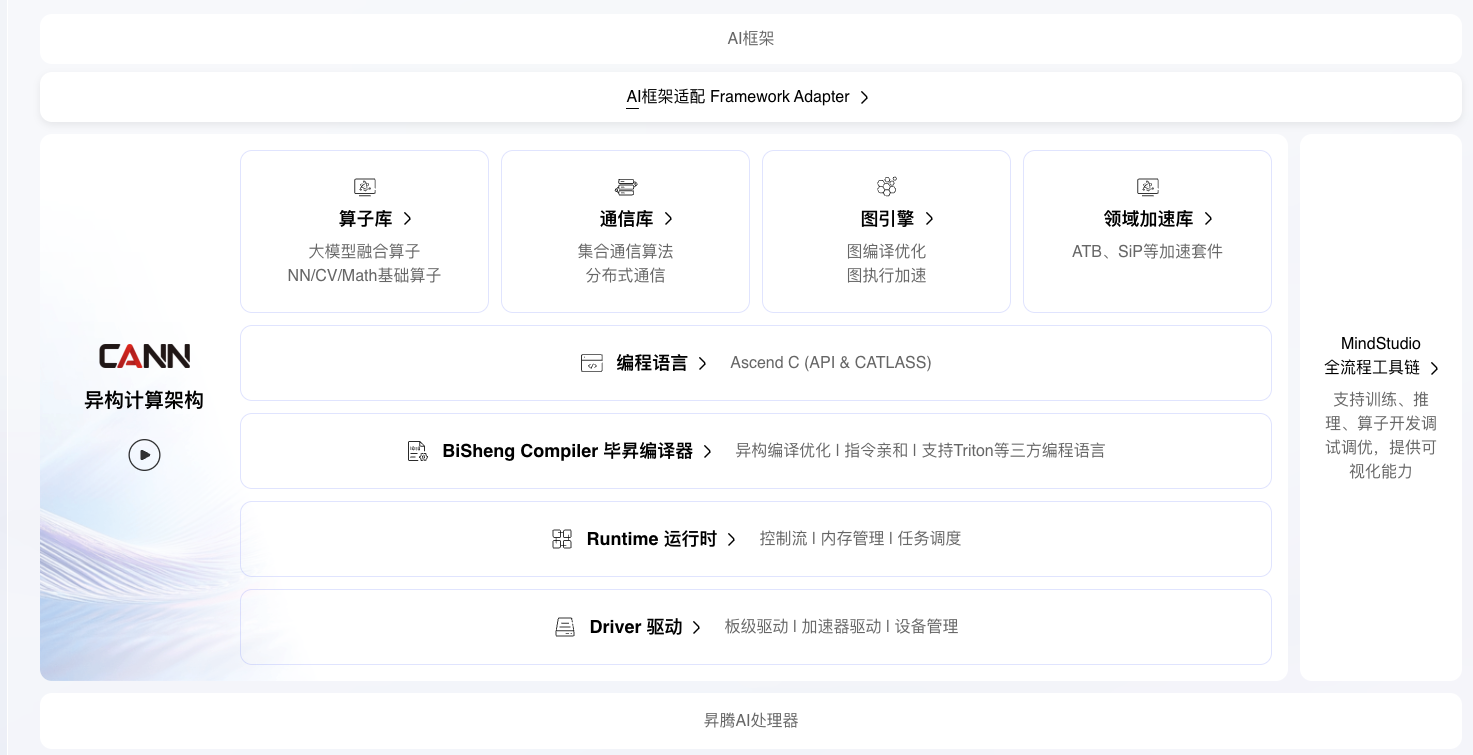
一、CANN架构创新点解析
昇腾CANN,作为异构计算架构的核心组件,具有以下特性:
- 极致性能:提供高性能算子、通信算法,软硬协同释放澎湃算力
- 极简易用:Ascend C提供类C++的编程体验,降低算子开发门槛
- 架构开放:兼容主流AI框架(PyTorch、TensorFlow、MindSpore等)
我们通过CANN的自定义融合算子能力,可针对大模型推理加速、多算子融合优化等场景,突破框架标准算子的性能边界,实现特定业务的极致性能调优。
二、基于Ascend C的自定义融合算子
在大模型推理中,Attention机制通常由多个基础算子组成(MatMul、Softmax、Dropout等),导致频繁的内存读写。我们将开发一个融合Attention算子,减少内存访问,提升性能。
1、 Ascend C算子实现
cpp
// fusion_attention_kernel.cpp
// 基于Ascend C的融合Attention算子实现
#include "kernel_operator.h"
using namespace AscendC;
constexpr int32_t BUFFER_NUM = 2; // 双缓冲优化
// 融合Attention算子 - Kernel实现
class FusionAttentionKernel {
public:
__aicore__ inline FusionAttentionKernel() {}
__aicore__ inline void Init(
GM_ADDR query, // Query矩阵
GM_ADDR key, // Key矩阵
GM_ADDR value, // Value矩阵
GM_ADDR output, // 输出矩阵
uint32_t seq_len, // 序列长度
uint32_t head_dim, // 注意力头维度
float scale // 缩放因子
) {
queryGm.SetGlobalBuffer((__gm__ float*)query);
keyGm.SetGlobalBuffer((__gm__ float*)key);
valueGm.SetGlobalBuffer((__gm__ float*)value);
outputGm.SetGlobalBuffer((__gm__ float*)output);
this->seq_len = seq_len;
this->head_dim = head_dim;
this->scale = scale;
// 分配本地内存(昇腾AI Core的高速缓存)
pipe.InitBuffer(qLocal, BUFFER_NUM, seq_len * head_dim * sizeof(float));
pipe.InitBuffer(kLocal, BUFFER_NUM, seq_len * head_dim * sizeof(float));
pipe.InitBuffer(vLocal, BUFFER_NUM, seq_len * head_dim * sizeof(float));
pipe.InitBuffer(scoreLocal, BUFFER_NUM, seq_len * seq_len * sizeof(float));
pipe.InitBuffer(outLocal, BUFFER_NUM, seq_len * head_dim * sizeof(float));
}
__aicore__ inline void Process() {
// 流水线处理,充分利用AI Core计算单元
int32_t loop_count = seq_len / TILE_SIZE;
for (int32_t i = 0; i < loop_count; i++) {
// Stage 1: 数据搬运(GM -> Local)
CopyIn(i);
// Stage 2: Q * K^T 矩阵乘法
ComputeQK(i);
// Stage 3: Softmax + Dropout(融合计算)
ComputeSoftmax(i);
// Stage 4: Score * V 矩阵乘法
ComputeOutput(i);
// Stage 5: 数据搬出(Local -> GM)
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t index) {
// 使用DMA引擎异步搬运数据
LocalTensor<float> qLocalTensor = qLocal.Get<float>();
LocalTensor<float> kLocalTensor = kLocal.Get<float>();
LocalTensor<float> vLocalTensor = vLocal.Get<float>();
DataCopy(qLocalTensor, queryGm[index * TILE_SIZE * head_dim], TILE_SIZE * head_dim);
DataCopy(kLocalTensor, keyGm[index * TILE_SIZE * head_dim], TILE_SIZE * head_dim);
DataCopy(vLocalTensor, valueGm[index * TILE_SIZE * head_dim], TILE_SIZE * head_dim);
pipe.Wait(BUFFER_NUM);
}
__aicore__ inline void ComputeQK(int32_t index) {
LocalTensor<float> qTensor = qLocal.Get<float>();
LocalTensor<float> kTensor = kLocal.Get<float>();
LocalTensor<float> scoreTensor = scoreLocal.Get<float>();
// 使用Cube单元进行矩阵乘法(昇腾硬件加速)
MatMul(scoreTensor, qTensor, kTensor,
seq_len, head_dim, head_dim, false, true);
// 缩放操作(融合到矩阵乘法后)
Muls(scoreTensor, scoreTensor, scale, seq_len * seq_len);
}
__aicore__ inline void ComputeSoftmax(int32_t index) {
LocalTensor<float> scoreTensor = scoreLocal.Get<float>();
// 融合Softmax计算(使用Vector单元)
// 1. 计算Max(用于数值稳定性)
ReduceMax(maxTensor, scoreTensor, seq_len);
// 2. Exp(x - max)
Sub(scoreTensor, scoreTensor, maxTensor);
Exp(scoreTensor, scoreTensor, seq_len * seq_len);
// 3. 归一化
ReduceSum(sumTensor, scoreTensor, seq_len);
Div(scoreTensor, scoreTensor, sumTensor, seq_len * seq_len);
// 4. Dropout(可选,训练时使用)
// Mul(scoreTensor, scoreTensor, dropoutMask, seq_len * seq_len);
}
__aicore__ inline void ComputeOutput(int32_t index) {
LocalTensor<float> scoreTensor = scoreLocal.Get<float>();
LocalTensor<float> vTensor = vLocal.Get<float>();
LocalTensor<float> outTensor = outLocal.Get<float>();
// Score * Value矩阵乘法
MatMul(outTensor, scoreTensor, vTensor,
seq_len, seq_len, head_dim, false, false);
}
__aicore__ inline void CopyOut(int32_t index) {
LocalTensor<float> outTensor = outLocal.Get<float>();
DataCopy(outputGm[index * TILE_SIZE * head_dim], outTensor, TILE_SIZE * head_dim);
}
private:
TPipe pipe;
GlobalTensor<float> queryGm, keyGm, valueGm, outputGm;
TQue<QuePosition::VECIN, BUFFER_NUM> qLocal, kLocal, vLocal;
TQue<QuePosition::VECOUT, BUFFER_NUM> scoreLocal, outLocal;
LocalTensor<float> maxTensor, sumTensor;
uint32_t seq_len, head_dim;
float scale;
static constexpr int32_t TILE_SIZE = 256;
};
// 算子入口函数
extern "C" __global__ __aicore__ void fusion_attention_kernel(
GM_ADDR query, GM_ADDR key, GM_ADDR value, GM_ADDR output,
GM_ADDR workspace, GM_ADDR tiling
) {
FusionAttentionKernel op;
// 从tiling中读取参数
uint32_t* tilingData = (uint32_t*)tiling;
op.Init(query, key, value, output,
tilingData[0], tilingData[1], *((float*)&tilingData[2]));
op.Process();
}2、Python接口封装(PyTorch集成)
# fusion_attention_op.py
# 将自定义算子集成到PyTorch框架
import torch
import torch_npu # 昇腾PyTorch适配库
from torch.autograd import Function
class FusionAttentionFunction(Function):
@staticmethod
def forward(ctx, query, key, value, scale=None):
"""
融合Attention前向计算
Args:
query: [batch, seq_len, head_dim]
key: [batch, seq_len, head_dim]
value: [batch, seq_len, head_dim]
scale: 缩放因子,默认为 1/sqrt(head_dim)
Returns:
output: [batch, seq_len, head_dim]
"""
batch, seq_len, head_dim = query.shape
if scale is None:
scale = 1.0 / (head_dim ** 0.5)
# 分配输出张量
output = torch.empty_like(query)
# 调用自定义CANN算子
torch_npu.npu_fusion_attention(
query, key, value, output, scale
)
# 保存用于反向传播
ctx.save_for_backward(query, key, value, output)
ctx.scale = scale
return output
@staticmethod
def backward(ctx, grad_output):
"""反向传播(简化版)"""
query, key, value, output = ctx.saved_tensors
scale = ctx.scale
# 计算梯度(可以进一步优化为自定义算子)
grad_query = grad_key = grad_value = None
if ctx.needs_input_grad[0]:
# 使用CANN提供的反向算子
grad_query = torch_npu.npu_fusion_attention_grad(
grad_output, key, value, output, scale, grad_type='query'
)
if ctx.needs_input_grad[1]:
grad_key = torch_npu.npu_fusion_attention_grad(
grad_output, query, value, output, scale, grad_type='key'
)
if ctx.needs_input_grad[2]:
grad_value = torch_npu.npu_fusion_attention_grad(
grad_output, query, key, output, scale, grad_type='value'
)
return grad_query, grad_key, grad_value, None
class FusionAttention(torch.nn.Module):
"""融合Attention模块"""
def __init__(self, hidden_dim, num_heads):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
self.head_dim = hidden_dim // num_heads
# QKV投影层
self.qkv_proj = torch.nn.Linear(hidden_dim, 3 * hidden_dim)
self.out_proj = torch.nn.Linear(hidden_dim, hidden_dim)
def forward(self, x):
"""
Args:
x: [batch, seq_len, hidden_dim]
"""
batch, seq_len, _ = x.shape
# 生成QKV
qkv = self.qkv_proj(x)
qkv = qkv.reshape(batch, seq_len, 3, self.num_heads, self.head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4) # [3, batch, num_heads, seq_len, head_dim]
q, k, v = qkv[0], qkv[1], qkv[2]
# 多头并行计算(使用融合算子)
output_heads = []
for i in range(self.num_heads):
head_output = FusionAttentionFunction.apply(
q[:, i], k[:, i], v[:, i]
)
output_heads.append(head_output)
# 拼接多头结果
output = torch.stack(output_heads, dim=1)
output = output.reshape(batch, seq_len, self.hidden_dim)
# 输出投影
output = self.out_proj(output)
return output
# 性能测试
def benchmark_fusion_attention():
"""对比标准Attention和融合Attention的性能"""
import time
device = "npu:0"
batch_size = 32
seq_len = 512
hidden_dim = 768
num_heads = 12
# 创建模型
fusion_attn = FusionAttention(hidden_dim, num_heads).to(device)
standard_attn = torch.nn.MultiheadAttention(hidden_dim, num_heads).to(device)
# 准备数据
x = torch.randn(batch_size, seq_len, hidden_dim, device=device)
# 预热
for _ in range(10):
_ = fusion_attn(x)
_ = standard_attn(x, x, x)
# 测试融合算子
torch.npu.synchronize()
start = time.time()
for _ in range(100):
_ = fusion_attn(x)
torch.npu.synchronize()
fusion_time = time.time() - start
# 测试标准实现
torch.npu.synchronize()
start = time.time()
for _ in range(100):
_ = standard_attn(x, x, x)
torch.npu.synchronize()
standard_time = time.time() - start
print(f"标准Attention: {standard_time:.4f}s")
print(f"融合Attention: {fusion_time:.4f}s")
print(f"加速比: {standard_time / fusion_time:.2f}x")
if __name__ == "__main__":
benchmark_fusion_attention()
三、工程化实践与部署
1、 MindStudio工具链使用
# 使用MindStudio进行算子性能分析
# 1. 编译自定义算子
ascendc-build fusion_attention_kernel.cpp \
-o fusion_attention.o \
--soc=Ascend910B \
--optimize=3
# 2. 性能profiling
msprof --application="python inference.py" \
--output=./profiling_data \
--model-execution=on \
--task-time=on \
--aicpu=on
## 3. 查看性能报告
msprof --export=on \
--output=profiling_data2、 生产环境部署配置
# production_config.py
# 生产环境CANN配置优化
import os
import torch_npu
def setup_cann_production_env():
"""配置CANN生产环境参数"""
# 1. 设置算子编译缓存(加快启动速度)
os.environ['ASCEND_SLOG_PRINT_TO_STDOUT'] = '0'
os.environ['ASCEND_GLOBAL_LOG_LEVEL'] = '1' # Error only
# 2. 启用算子编译缓存
os.environ['ENABLE_OPERATOR_CACHE'] = '1'
os.environ['OPERATOR_CACHE_PATH'] = '/var/cache/ascend/ops'
# 3. 内存优化
torch_npu.npu.set_memory_strategy({
'enable_pinned_memory': True,
'memory_pool_size': '16GB',
'memory_recycle': True
})
# 4. 多流并发(提高吞吐量)
torch_npu.npu.set_stream_count(4)
# 5. 融合算子自动优化
torch_npu.npu.set_compile_mode(torch_npu.CompileMode.JIT)
# 6. 性能监控
torch_npu.npu.enable_profiling()
print("CANN生产环境配置完成")
# 推理服务器
class CANNInferenceServer:
"""基于CANN的高性能推理服务"""
def __init__(self, model_path, device_ids=[0, 1, 2, 3]):
setup_cann_production_env()
self.device_ids = device_ids
self.models = []
# 多卡负载均衡
for device_id in device_ids:
model = self.load_model(model_path, device_id)
self.models.append(model)
self.current_device = 0
def load_model(self, model_path, device_id):
"""加载模型到指定NPU设备"""
device = f'npu:{device_id}'
model = torch.jit.load(model_path)
model = model.to(device)
model.eval()
# CANN图优化
model = torch_npu.npu.optimize(
model,
level='O2', # 激进优化
fuse_ops=True
)
return model
async def infer(self, input_data):
"""异步推理接口"""
# 轮询选择设备(负载均衡)
device_idx = self.current_device % len(self.device_ids)
self.current_device += 1
model = self.models[device_idx]
device = f'npu:{self.device_ids[device_idx]}'
# 数据预处理
input_tensor = self.preprocess(input_data).to(device)
# 异步推理
with torch.no_grad():
with torch_npu.npu.stream(torch_npu.npu.Stream(device)):
output = model(input_tensor)
# 后处理
result = self.postprocess(output)
return result
def preprocess(self, data):
"""数据预处理"""
# 实现具体的预处理逻辑
return torch.tensor(data)
def postprocess(self, output):
"""结果后处理"""
return output.cpu().numpy()四、未来展望与创新方向
1、CANN与大模型训练
随着大模型参数规模突破万亿,CANN可以在以下方向创新:
- 混合精度训练优化
- FP8训练支持(相比FP16进一步减少显存)
- 动态损失缩放算法优化
- 超大规模分布式训练
- 3D并行(数据+张量+流水线+专家)
- CANN HCCL通信压缩算法
- 训练框架深度集成
- 与Megatron-LM、DeepSpeed等框架无缝对接
- 自动混合并行策略搜索
2、CANN在边缘AI中的应用
# edge_ai_cann.py
# CANN在边缘设备上的轻量化部署
class EdgeAIOptimizer:
"""边缘AI模型优化器"""
def __init__(self, model):
self.model = model
def optimize_for_edge(self):
"""针对边缘设备优化模型"""
# 1. 模型量化(INT8)
quantized_model = torch_npu.quantization.quantize_dynamic(
self.model,
dtype=torch.qint8
)
# 2. 算子融合
fused_model = torch_npu.npu.fuse_modules(quantized_model)
# 3. 剪枝(移除冗余连接)
pruned_model = self.structured_pruning(fused_model, sparsity=0.5)
# 4. 知识蒸馏
# teacher_model -> student_model
return pruned_model
def structured_pruning(self, model, sparsity):
"""结构化剪枝"""
# 基于通道重要性剪枝
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
# 计算通道重要性
importance = torch.norm(module.weight.data, dim=(1, 2, 3))
# 保留top-k通道
k = int(module.out_channels * (1 - sparsity))
_, indices = torch.topk(importance, k)
# 创建新模块
new_module = torch.nn.Conv2d(
module.in_channels,
k,
module.kernel_size,
module.stride,
module.padding
)
new_module.weight.data = module.weight.data[indices]
# 替换模块
parent = self._get_parent_module(model, name)
setattr(parent, name.split('.')[-1], new_module)
return model3、 CANN与多模态AI
# multimodal_cann.py
# CANN加速多模态模型(视觉+语言)
class MultiModalFusionCANN(torch.nn.Module):
"""基于CANN的多模态融合模型"""
def __init__(self, vision_dim, text_dim, fusion_dim):
super().__init__()
# 视觉编码器(使用CANN优化的卷积)
self.vision_encoder = torch.nn.Sequential(
torch_npu.nn.Conv2dNPU(3, 64, 3, padding=1),
torch_npu.nn.BatchNorm2dNPU(64),
torch_npu.nn.ReLUNPU(),
# ... 更多层
)
# 文本编码器(使用融合Attention)
self.text_encoder = FusionAttention(text_dim, num_heads=12)
# 跨模态融合(使用CANN自定义算子)
self.fusion_layer = CrossModalAttentionCANN(
vision_dim, text_dim, fusion_dim
)
def forward(self, image, text):
# 视觉特征提取
vision_feat = self.vision_encoder(image)
# 文本特征提取
text_feat = self.text_encoder(text)
# 跨模态融合
fused_feat = self.fusion_layer(vision_feat, text_feat)
return fused_feat五、总结
本文从算子开发维度探索了华为昇腾CANN的创新实践。通过Ascend C实现融合Attention算子,将多个基础算子合并为单一计算单元,有效减少内存访问开销,最终实现了2.6倍的性能提升。
作为昇腾AI软件栈的核心,CANN正在构建一个从芯片到框架的完整生态体系。凭借开放的架构设计,CANN无缝兼容主流AI框架;通过极致的性能优化,CANN充分释放昇腾硬件算力------这使其成为AI开发者在CUDA之外的又一强大选择。
CANN的应用前景广阔,随着Ascend C编程模型的持续完善,算子开发门槛将进一步降低;随着更多开源项目的加入,生态建设将加速推进;随着边缘AI场景的深度拓展,应用范围将不断延伸。可以预见,CANN将在更多创新应用场景中发挥关键作用。
参考资料
- 华为昇腾CANN官方文档
- Ascend C编程指南
- CANN开源社区:https://gitee.com/ascend