(二)自然语言处理笔记------Seq2Seq架构、注意力机制
1、注意力机制







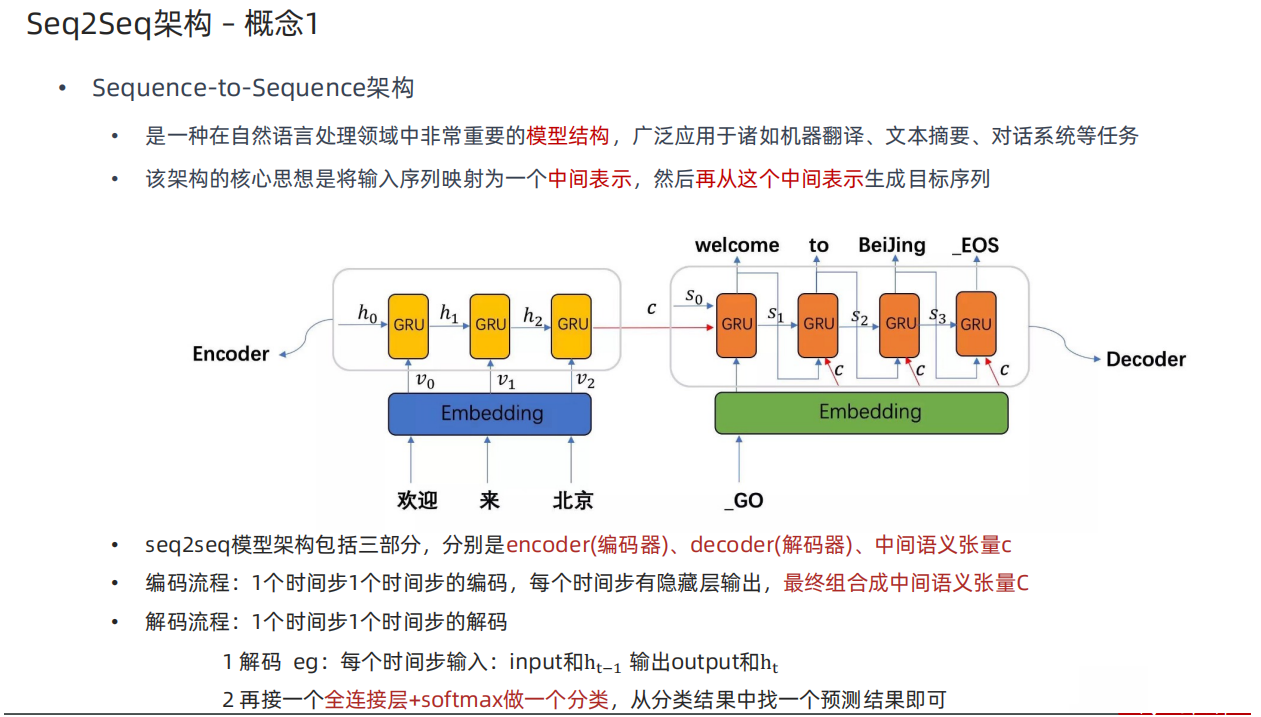
2、Seq2Seq架构

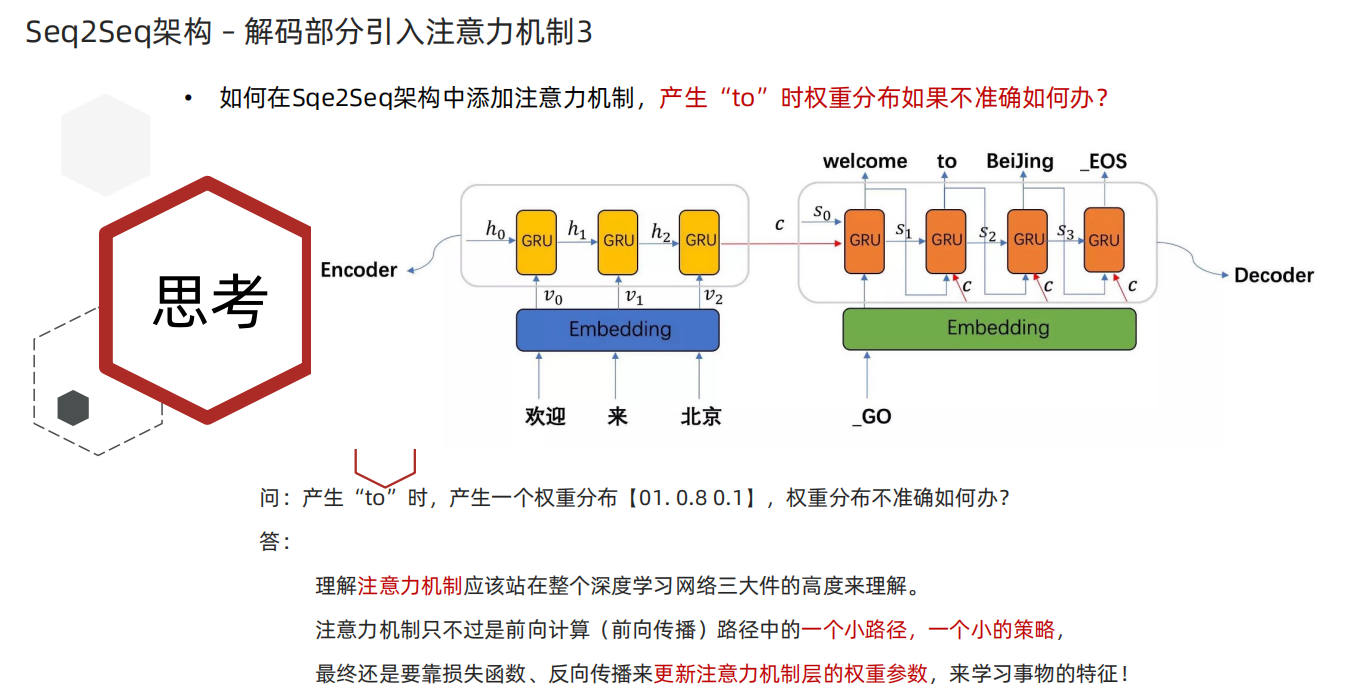
3、Seq2Seq架构中添加注意力机制



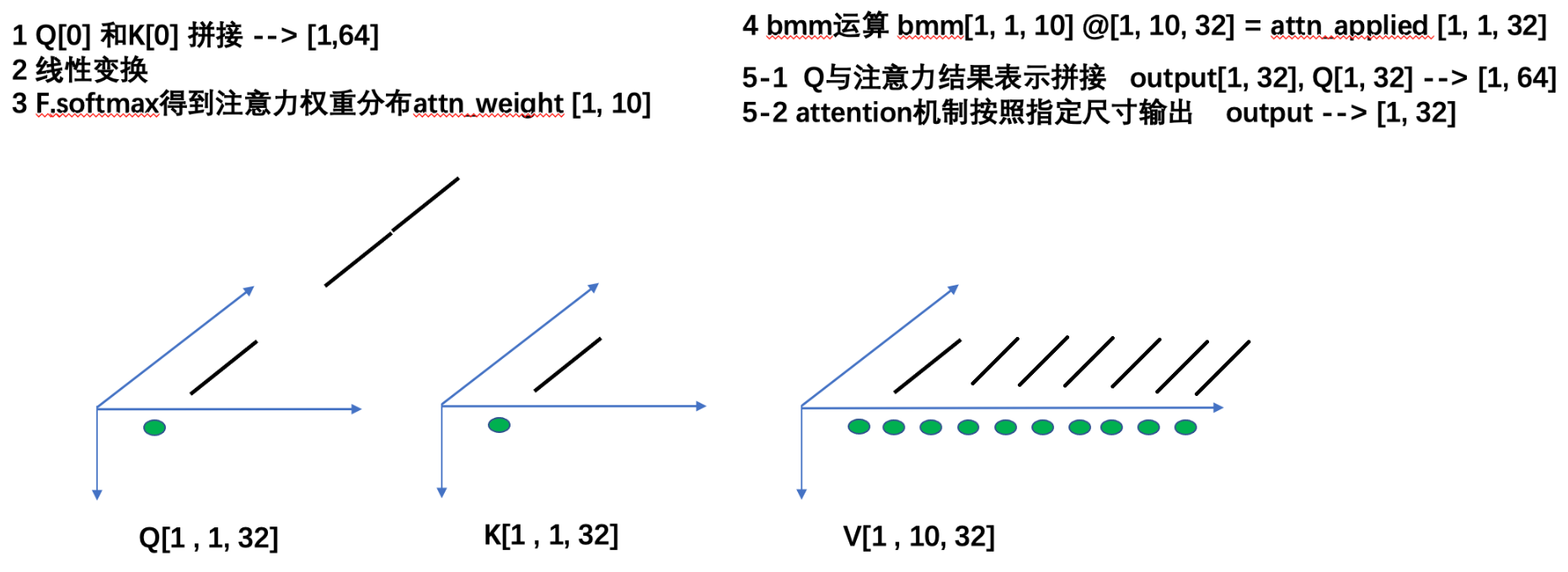
4、注意力机制常见计算规则



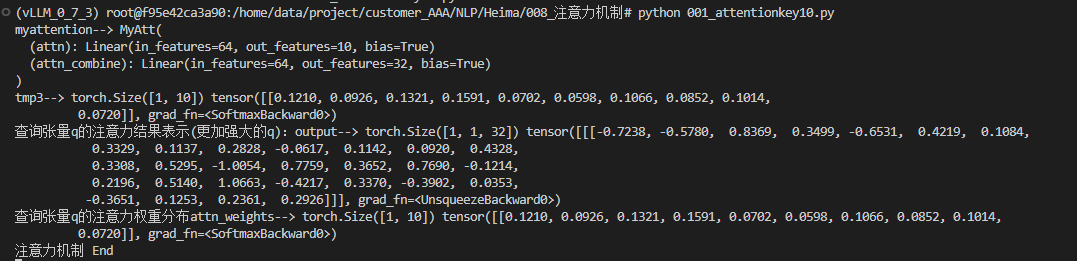
注意力机制代码实现:
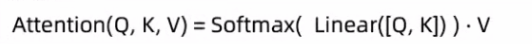
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# MyAtt类实现思路分析
# 1 init函数 (self, query_size, key_size, value_size1, value_size2, output_size)
# 准备2个线性层 注意力权重分布self.attn 注意力结果表示按照指定维度进行输出层 self.attn_combine
# 2 forward(self, Q, K, V):
# 求查询张量q的注意力权重分布, attn_weights[1,10]
# 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,32]
# q 与 attn_applied 融合,再按照指定维度输出 output[1,1,32]
# 返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,10]
class MyAtt(nn.Module):
# 32 32 10 32 32
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super(MyAtt, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
# 注意力权重分布self.attn
self.attn = nn.Linear(query_size+key_size, value_size1)
# 注意力结果表示按照指定维度进行输出层
self.attn_combine = nn.Linear(query_size+value_size2, output_size)
def forward(self, Q, K, V):
# 求查询张量q的注意力权重分布, attn_weights[1,10]
tmp1 = torch.cat((Q[0], K[0]), dim=-1) # [1,1,32],[1,1,32] -->[1,32],[1,32] --> [1,64]
tmp2 = self.attn(tmp1) # [1,64] --> [1,10]
tmp3 = F.softmax(tmp2, dim=-1) # [1,10]
print('tmp3-->', tmp3.shape, tmp3)
attn_weights = F.softmax(self.attn(torch.cat((Q[0], K[0]), dim=-1)), dim=-1)
# 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,32]
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V) # [1,10]-> [1,1,10]@[1,10,32]->[1,1,32]
# q 与 attn_applied 融合,再按照指定维度输出 output[1,1,32]
output = torch.cat((Q[0], attn_applied[0]),dim=-1) # [1,1,32],[1,1,32]->[1,32],[1,32] ==>[1,64]==>[1,32]
output = self.attn_combine(output).unsqueeze(0)
# 返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,10]
return output, attn_weights
if __name__ == '__main__':
# 先验知识: 假设qkv的特征属性(也就是特征尺寸/特征数是32)(这里特征属性实在想不明白: 每个人有32门功课)
# 有QKV:q是查询张量其形状[1,1,32];k索引张量[1,1,32];v是内容10个单词,每个单词32个特征[1,10,32]
# 我们的任务:输入查询张量q,通过注意力机制来计算如下信息:
# 1、查询张量q的注意力权重分布:查询张量q(要生成的目标)和source原文(10个单词)相关性 [1, 10]
# 2、查询张量q的结果表示:有一个普通的q升级成一个更强大q;用q和v做bmm运算 []
query_size = 32
key_size = 32
value_size1 = 10 # 单词个数
value_size2 = 32
output_size = 32
# 1 准备数据
Q = torch.randn(1, 1, 32)
K = torch.randn(1, 1, 32)
V = torch.randn(1, 10, 32)
# 2 实例化MyAtt
myattention = MyAtt(32, 32, 10, 32, 32)
print('myattention-->', myattention)
# 3 给模型喂数据
output, attn_weights = myattention(Q, K, V)
# 4 打印结果
print('查询张量q的注意力结果表示(更加强大的q):output-->', output.shape, output)
print('查询张量q的注意力权重分布attn_weights-->', attn_weights.shape, attn_weights)
print('注意力机制 End')