参考资料:朝乐门。数据科学导论 M. 北京:人民邮电出版社,2020.
文章目录
-
- 六.大数据技术
-
- [1. Hadoop生态系统](#1. Hadoop生态系统)
- [2. 常用大数据计算框架](#2. 常用大数据计算框架)
- 3.大数据管理技术的类型
-
- [3.1 传统数据管理技术](#3.1 传统数据管理技术)
- [3.2 新兴大数据管理技术](#3.2 新兴大数据管理技术)
- [3.3 关系型数据库的优缺点](#3.3 关系型数据库的优缺点)
六.大数据技术
1. Hadoop生态系统
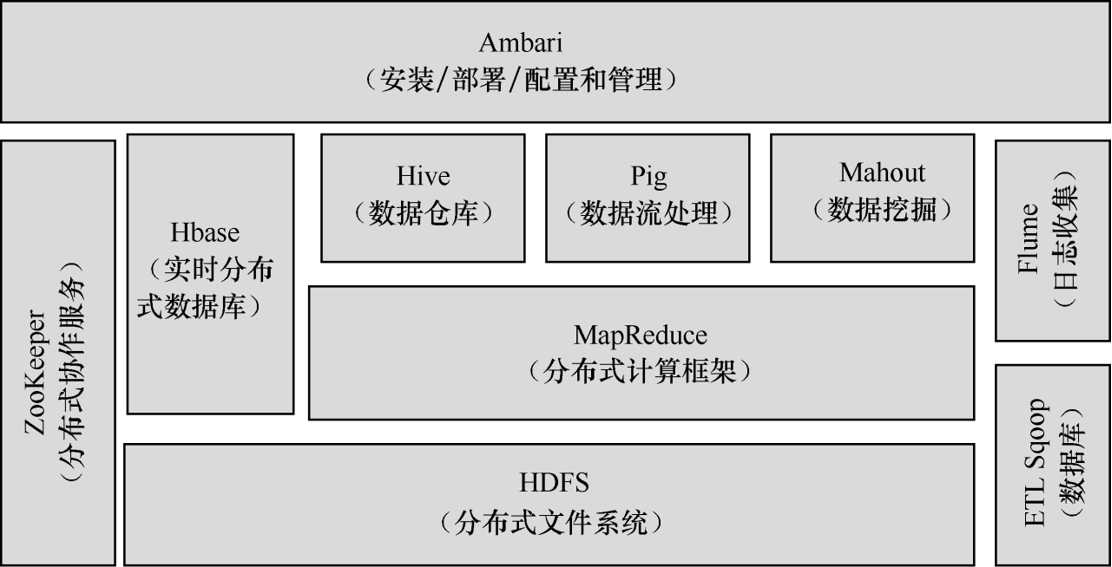
上图所示是Apache Hadoop生态系统,其核心是:HDFS和Hadoop MapReduce,分别代表Hadoop分布式文件系统和分布式计算系统
Hadoop生态系统是一套围绕着**"分布式存储 + 分布式计算"构建的大数据处理工具的集合,核心是解决"海量数据存不下、计算太慢的难题"**
- 分布式存储:"把数据拆成小块,分散存到多台机器"
- 分布式计算:"把计算任务拆成小任务,分散到多台机器并行算"
其整体可拆分为:核心组件 + 周边支持组件
核心1:分布式文件系统HDFS
作用:专门用来存储海量数据(比如 TB/PB 级数据)。它把数据拆分成小块,分散存储在多台服务器上(而非单台机器),既解决了 "单台机器存不下" 的问题,又能通过多机备份保证数据安全(比如一份数据存 3 份副本,某台机器坏了也不丢数据)。
核心2:分布式计算框架MapReduce
作用:对应HDFS的存储,负责计算,把复杂的计算任务拆分成两个阶段(Map 阶段 "拆分任务"、Reduce 阶段 "汇总结果"),分配到多台机器上并行计算,大幅提升处理速度
周边支撑组件:生态的 "功能扩展"(解决不同场景需求)
- 数据采集:Flume(收集日志数据,比如实时采集服务器的运行日志,输送到 HDFS 存储)
- 数据存储(非结构化 / 半结构化):HBase(分布式数据库,适合存非结构化数据,比如用户的实时交易记录,支持快速查询);
- 数据仓库 / 分析:Hive(把 HDFS 里的海量数据当成 "数据库表" 来操作,用 SQL 语句就能分析,不用写复杂的 MapReduce 代码,适合做离线数据分析)、Pig(用简单脚本处理数据,适合数据清洗);
- 数据挖掘:Mahout(提供机器学习算法,比如用它在海量用户数据中做推荐、分类,不用自己从零开发算法)
- 任务协调 / 管理:Zookeeper(协调分布式环境中的多台机器,比如监控机器状态、同步任务进度,保证整个生态组件稳定运行)、Ambari(可视化管理 Hadoop 集群,比如一键安装、配置、监控所有组件,不用手动操作每台机器);
2. 常用大数据计算框架
| 计算框架 | 提出者 | 特点 |
|---|---|---|
| MapReduce | 一种以主从结构(1 个主节点分配任务,多个从节点执行任务)的形式运行的分布式计算框架,是大数据时代 的基本计算框架之一 | |
| Tez | Apache | 一种构建在 Apache Hadoop YARN 之上的有向无环图(Directed Acyclic Graph,DAG)计算框架,可以拆分、组合 Map 和 Reduce 过程,进而减少 Map、Reduce 之间的文件存储和运行时间 |
| Spark | UC Berkeley | 一种大规模数据处理的通用引擎,不仅可以实现 MapReduce 的功能,而且运行速度更快、使用更为方便。目前,Spark 支持 Spark SQL 查询、流式处理、机器学习和复杂分析 |
| Storm | 一种以大数据流的实时处理为目的的开源框架,可以实时处理Hadoop 的批量任务 | |
| Druid | Metamarkets 等 | 一种主要为商务智能和 OLAP 设计的面向列的分布式数据存储 系统,可支持实时查询与分析海量数据 |
Tez:基于 Hadoop YARN(资源调度框架)构建,把 MapReduce 的 "固定两阶段" 改成 "有向无环图(DAG)"------ 可以根据需求拆分、组合 Map/Reduce 过程,减少中间结果在磁盘的存储和读取次数;
Spark:不仅能实现 MapReduce 的离线计算,还支持内存计算(中间结果存到内存,而非磁盘,速度比 MapReduce 快 10-100 倍);
Storm:专门针对 "大数据流的实时处理" 设计,采用 "流计算模式"------ 数据像 "水流" 一样实时进入系统,Storm 能毫秒 / 秒级处理,而不是像 MapReduce/Spark 离线计算那样 "等数据攒够了再算"
Druid:支持 "实时写入 + 实时查询",能快速响应多维度的聚合分析(比如 "按地区、时间、用户类型,实时查询某商品的销量")。
3.大数据管理技术的类型
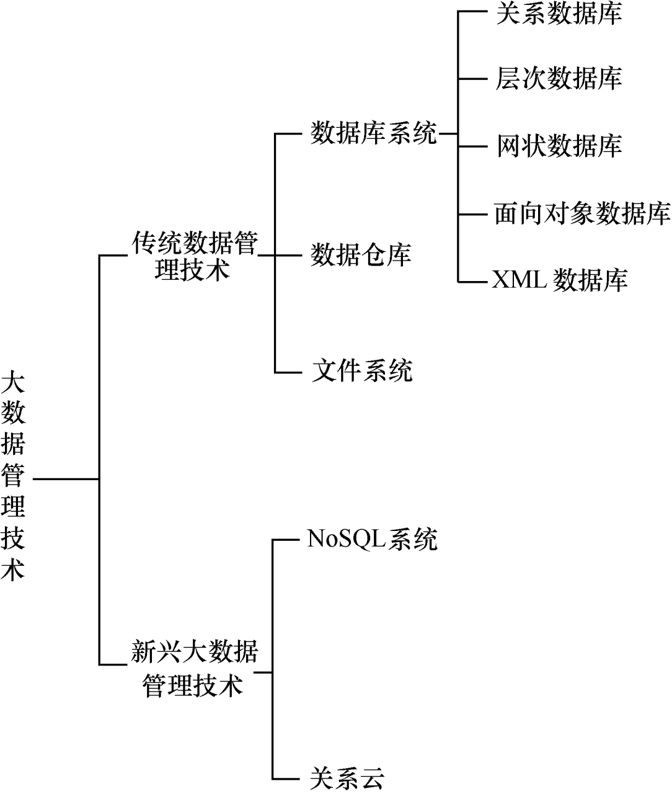
3.1 传统数据管理技术
适配小体量、结构化的数据
- 特点:数据需按固定 "表结构" 存储(比如用户表必须提前定义 "姓名、年龄、手机号" 等字段),支持复杂查询(如多表关联查询),数据一致性高(比如转账时 "扣款" 和 "到账" 必须同时成功或失败)。
3.2 新兴大数据管理技术
随着大数据时代到来(数据量激增、类型变复杂,如日志、图片、视频等非结构化数据),传统技术难以满足需求,因此出现了新兴大数据管理技术
3.3 关系型数据库的优缺点
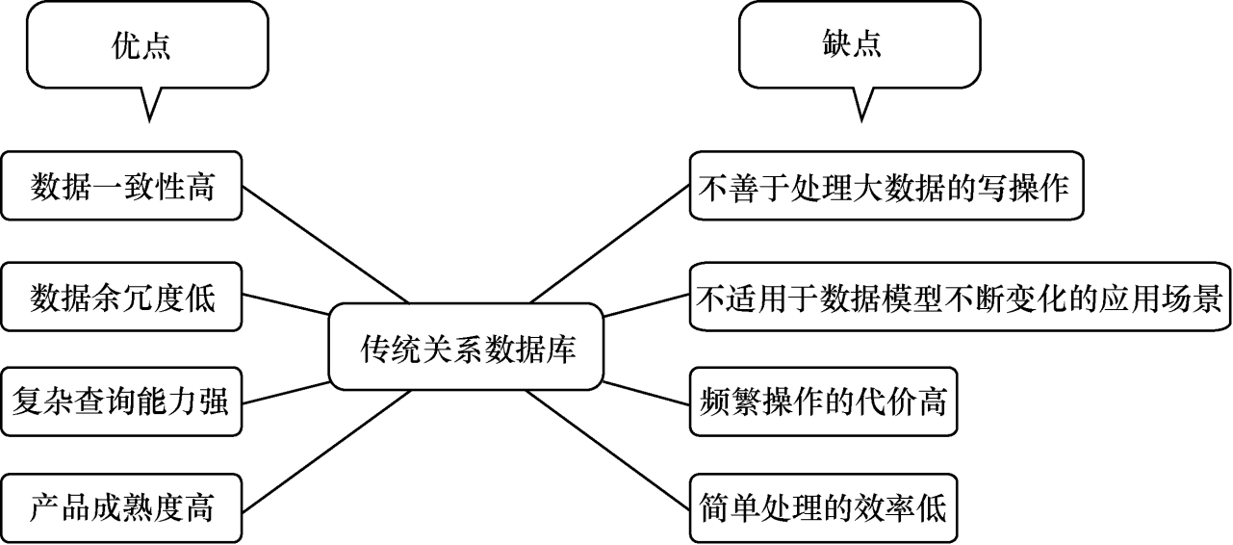
在大数据时代,传统关系数据库的优势与缺点日益凸显,如图 所示,使 NoSQL数据库和关系云等新兴大数据管理技术成为必要。
- NoSQL数据库:突破传统关系数据库的 "固定表结构" 限制,支持 "非结构化 / 半结构化数据"(比如存储用户行为日志、社交媒体评论、图片 URL 等);能横向扩展(通过增加服务器节点提升存储和处理能力,而非单台机器升级),适合海量数据场景;但会在一定程度上牺牲 "强一致性"(比如允许短时间内不同节点数据略有差异,后续同步)。
- 关系云:是 "能灵活扩缩容的传统关系数据库 "------ 既保留了传统数据库 "管结构化数据、查得准、数据稳" 的优点,又具备云计算 "能扛住大数据量、按需调资源" 的能力,专门适配 "需要传统数据库功能,又面临数据量增长" 的场景
- 它不是 "单台机器",而是云平台上的机器集群:数据会分散存储在多台机器上,计算任务也能多机并行处理,突破单机硬件限制;
- 支持按需扩缩容:比如电商 "双 11" 前订单量会暴涨,可提前在云平台上 "一键增加机器",提升存储和计算能力;"双 11" 后订单量下降,再 "释放多余机器",避免资源浪费(不用像传统模式那样,买一堆机器平时闲置)。
总结:
- 传统数据管理技术:管 "小而规整" 的数据,靠 "固定结构 + 强一致性" 取胜,适合传统业务;
- 新兴大数据管理技术:管 "大而杂乱" 的数据,靠 "灵活结构 + 弹性扩展" 取胜,适合大数据业务。