专栏: 🎉《C++》

引言:
前面的文章我们已经讲了如何用gcc/g++编译器来编译代码,让我们的程序运行起来。今天我们再来分享一个自动化构建工具------make/Makefile,让我们从此可以一键化编译代码。然后实战完成第一个Linux系统程序------进度条。
目录
一、什么是自动化构建?
回顾前面我们使用gcc/g++编译代码的过程。
过来过去就这么几句指令:
编译:gcc -c code.c -o code.o / g++ -c code.cpp -o code.o
链接:gcc code.o -o code
运行:./code
这指令每次重复的写 还长。
而且很多时候源文件都不止几个。
这时候编链接的过程就会效率很低。
你要是一个一个的编译。

那能不能把这些重复的指令给他精简一下。
于是就有了自动化构建。
说人话就是:自动执行这些规则,以高效、可重复的方式生成目标文件。
只要你写好一个Makefile。
make指令一键就可以完成编译。

那接下来我们就开始写这个Makefile。
1.1、make/Makefile基本使用
首先:
make是一个指令;
Makefile是一个文件。
我先写一个简单的Makefile让大家见一见。
在当前目录下创建一个Makefile文件和一个code.c文件:
bash
// 指令:
touch Makefile
touch code.c然后在code.c中写一段简单的代码原来测试运行:
bash
#include<stdio.h>
int main()
{
printf("hello Linux!\n");
return 0;
}最后在Makefile中写好需要自动执行的指令:
bash
code:code.c # -----------依赖关系
gcc -o code code.c # -------依赖方法
PHONY:clean
clean: # --------依赖关系
rm -f code # -------依赖方法测试:
bash// 编译指令: make
bash// 运行指令: ./code
bash// 清理指令: make clean



看到这里:

可这是什么东西看不懂呀。
那接下来我就把这个东西给大家拆开了讲讲。
1.2、依赖关系与依赖方法
是的编译怎么还和依赖扯上关系了。
以下就是我们写的Makefile文件的内容:
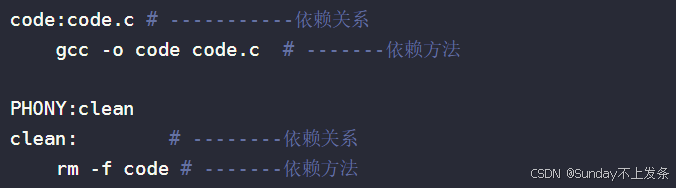
code:code.c 就是依赖关系。
即编译形成一个可执行程序code得依赖源文件code.c。
gcc -o code code.c 就是依赖方法。
即code.c 编译成可执行程序code依赖这句指令。
那这这句指令当然而然就是依赖的方法喽。
现在是不是 
一切都是那么的自然。
那么 clean 清理可执行程序我也懂了。
我们修改完代码重新编译那旧的肯定就要清理掉。
而清理就是删除文件理所应当依赖 rm 指令。
 孺子可教也。
孺子可教也。
那这个 PHONY:clean你猜一下是干啥的。
猜不出来就看下面。
***注意一点细节:***依赖方法前面的空格可是有讲究的。
必须以Tab键默认的空格数开头。
1.3、总被执行与ACM时间
你先试试这个呢:连续执行两次 make 指令。
这坑今天我先帮你踩了。


再试试make clean呢!

看出来没有:
即当我们在clean 前面加上PHONY:后make clean就可以总被执行了。
那为什么只在clean前面加呢?
因为clean是一个伪目标(即它不是生成具体文件的目标,而是执行清理动作的命令集合)。
加上PHONY:只是为了保证clean可以总被执行。
而对于编译:
编译器默认对老代码不做编译。
所以你连续make就会报错。
可是编译器又怎么知道我是不是老代码呢?
这就和我们之前提过的ACM时间(文件属性)扯上关系了。
我们可以通过 stat指令来查看文件详细信息:
【Access Time】:文件最后一次被访问(读取)的时间。
【Modify Time】:文件内容最后一次被修改的时间。
【Change Time】:文件元数据(如权限)最后一次被修改的时间。

这里编译器主要是根据文件的Modify 时间来判断的。
因为只要你修改文件内容就会改变Modify时间。
1.4、Makefile文件的迭代
这里我们继续引入几个东西。
Makefile文件中注释时采用 :#
1)变量
这个变量有点类似于我们给某个变量重命名。
bash
# ------------------Makefile文件----------------------------
# 定义变量
BIN=code
SRC=code.c
CC=gcc
RM=rm -f
FLAGS=-o
$(BIN):$(SRC)
$(CC) $(SRC) $(FLAGS) $(BIN)
.PHONY:clean
clean:
$(RM) $(BIN)即相当于我们用一个变量代表我们编译过程中的文件,选项和指令等。
这样更加灵活。
***注意:***在引用这些变量时需要用一个 $(变量)
2)@ 和 ^
@** 相当于(BIN),即指代可执行程序文件**。
\^**相当于 (SRC),即指代源文件**。
bash
# -------------------------Makefile文件----------------------------
# 定义变量
BIN=code
SRC=code.c
CC=gcc
RM=rm -f
FLAGS=-o
$(BIN):$(SRC)
$(CC) $(FLAGS) $@ $^ # $@---code; $^----code.c
.PHONY:clean
clean:
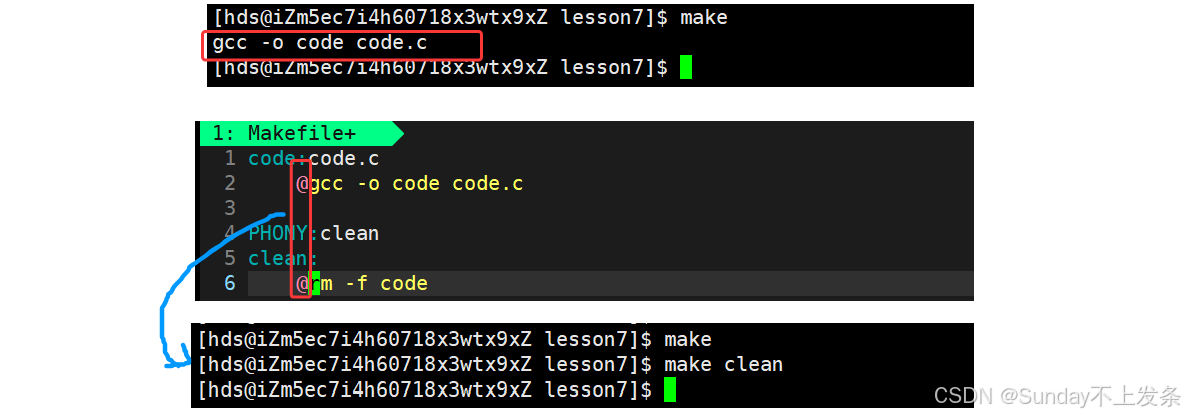
$(RM) $(BIN)3)@
每次当我们make 或make clean 时。
就会把Makefile文件中相关的指令打印出来。
如果你不想让这些指令被打印到屏幕上。
就可以在依赖方法的前面加上一个 @ 符号。
4)多文件编译
这也是我们最常见的场景。
那怎么实现多文件的自动化编译呢?
这里就得提到一个我们平时编译的一个习惯:
我们推荐都是先将源文件编译成目标文件。
然后统一将目标文件与动态库进行链接。
a. 我们首先得引入将源文件编译成目标文件的选项:-c ;
b. 定义目标文件的变量:OBJ;
b. 然后需要自动将源文件编译为目标文件;
需要用到几个新的写法:
(1)重新定义变量SRC和OBJ
bash// 源文件 // 两个中任选一个即可 SRC = $(shell ls *.c) SRC = $(wildcard *.c) // 目标文件 OBJ = $(SRC: .c = .o)(2)编译过程
bash%.o : %.c $(CC) $(FLAGS) $<%.o : %.c:表示将当前路径下的所有的 .o与 .c 文件展开。
$< :指代源文件。
这样便可以将当前路径下所有源文件逐个编译为对应的目标文件。
bash
# 定义变量
BIN=code
#SRC=$(shell ls *.c) # 显示当前命令下所有 .c 后缀的文件(两种写法)
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o) # SRC 内部的文件以.c为后缀的全部转为同名以.o为后缀的文件
CC=gcc
LFLAGS=-o
FLAGS=-c
RM=rm -f
$(BIN):$(OBJ)
@$(CC) $(LFLAGS) $@ $^ # $@---code; $^---code.o,即将code.o 编译为 code(可执行程序)
# 将多个源文件编译为对应的目标文件
%.o:%.c
@$(CC) $(FLAGS) $<
.PHONY:clean
clean:
@$(RM) $(OBJ) $(BIN)1.5、完成一个小而美的Makefile
我们最后可以再给我们的Makefile再加上一些提示信息:
如编译后可以打印出将xxx.c编译成了xxx.o 。
链接后可以打印出将xxx.o xxx.o链接成了xxx 。
于是我们就得到了最终一个小而美的Makefile:
bash
# 最终版本:支持多文件同时进行编译,即将多个目标文件进行链接
# 定义变量
BIN=code
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o) # SRC 内部的文件以.c为后缀的全部转为同名以.o为后缀的文件
CC=gcc
LFLAGS=-o
FLAGS=-c
RM=rm -f
$(BIN):$(OBJ)
@$(CC) $(LFLAGS) $@ $^ # $@---code; $^---code.o,即将code.o 编译为 code(可执行程序)
@echo "Linking ------ $^ to $@"
%.o:%.c # 将多个源文件编译为对应的目标文件
@$(CC) $(FLAGS) $< #
@echo "Compling ------ $< to $@"
.PHONY:clean
clean:
@$(RM) $(OBJ) $(BIN)
@echo "remove ------ $(OBJ) $(BIN)"老铁们  哈哈哈!!!
哈哈哈!!!
二、系统程序------进度条
2.1、回车与换行
回车:让光标回到但前行的最开始处。
换行:将光标切换到下一行最开始处。
你说这个谁不知道啊!
可是你讲这个跟进度条有什么关系。

我们今天要实现的进度条。
就是通过让一个字符串在同一行上面不断覆盖来完成的。
 这样说确实有点抽象。
这样说确实有点抽象。
实际就是先打印一个长度为1的字符串,
然后让字符串长度增加到2 。
再次打印时覆盖原来长度为1 的字符串。
循环100次...
那么不就相当于一个动态进度条嘛。
而我们要覆盖打印就要用到回车。
如果换行你不就扯呢嘛。
我们先用一个打印倒计时来练练手!
2.2、倒计时
直接上代码:
bash
#include<stdio.h>
#include<unistd.h> // sleep()函数头文件
int main()
{
int i = 0;
for(i = 10;i >= 0;i--)
{
printf("%-2d\r",i); // -2d表示打印宽带为2且左对齐
sleep(1);
}
return 0;
}
但我们运行后发现什么也没有。
这是为什么?
要知道我们打印东西时。
数据现在一个叫缓冲区的地方暂存着。
以前我们打印时结尾会加一个换行\n。
而**\n 能够刷新缓冲区**让我们打印出想要打印的内容。
回车**\r 则不会刷新缓冲区**。
所以就无法将数据打印到屏幕上。
这时候我们就可以用一个函数 fflush()来强制刷新缓冲区。
查手册可知:man 3 fflush
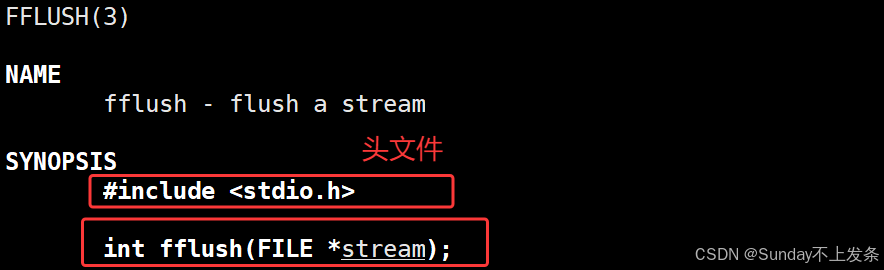
fflush函数需要一个FILE*类型的参数。
我们需要将数据打印到屏幕,所以这里的stream(流)就应该是stdout(标准输出流)。
改进代码:
bash
#include<stdio.h>
#include<unistd.h> // sleep()函数头文件
int main()
{
int i = 0;
for(i = 10;i >= 0;i--)
{
printf("%-2d\r",i); // -2d表示打印宽带为2且左对齐
fflush(stdout); // 强制刷新缓冲区
sleep(1); // 休眠1秒,便于观察
}
printf("\n"); // 最后换行
return 0;
}

2.3、进度条
1)我们通过改变字符串长度并覆盖打印来模拟进度条;
2)实时显示进度条的进度;
3)用光标旋转来模拟进度条的工作状态。
代码如下:
bash
#define N 101 // --------字符串总长,加上\0共101
#define CH '#' // ---------显示字符为'#'
void process_v1()
{
char buffer[N]; // 定义一个字符数组来显示进度条
memset(buffer,0,sizeof(buffer)); // 将数组内容初始化为全0
char lable[] ={"|/-\\"}; // 定义lable数组来显示进度条的工作状态
int len = strlen(lable);
int cnt = 0; // ----------- 计数器,表示当前的进度
while(cnt<=100)
{
// \r---回车,保证光标每次都能回到起始位置
printf("[%-100s][%d%%][%c]\r",buffer,cnt,lable[cnt % len]);
fflush(stdout); // 刷新缓冲区,将缓冲区的内容输出到显示器
buffer[cnt]=CH; // 每次向buffer数组写入一个 '#',代表进度加1
cnt++; // 计数器++
usleep(100000); //休眠100微秒
}
printf("\n"); // 换行同时刷新缓冲区
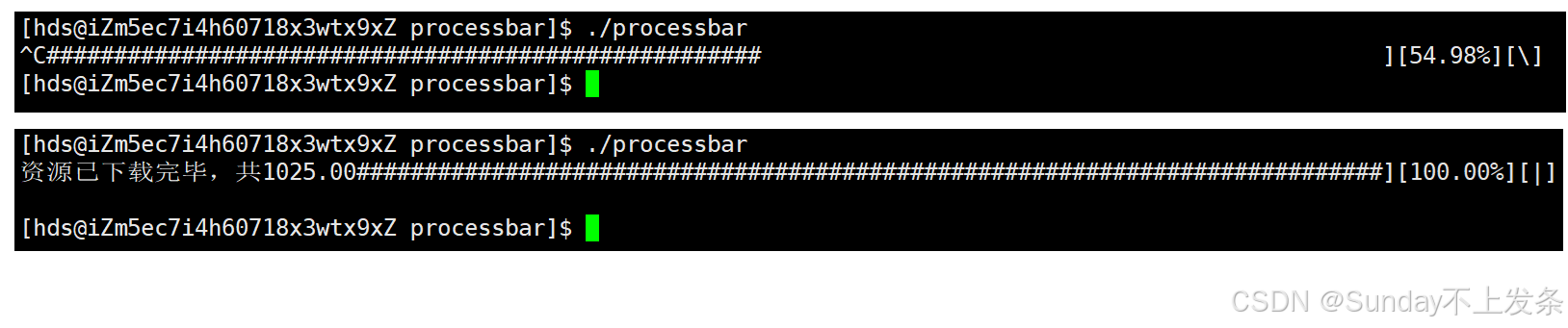
}效果如下:

进阶版本:与资源下载绑定
头文件:process.h
bash#include<stdio.h> #include<string.h> #include<unistd.h> void test(); // 函数声明 void process_v1(); // 函数声明process.c文件
bash#include"process.h" #define N 101 #define TYPE '#' void process_v2(double current, double total) { char buffer[N]; memset(buffer,0,sizeof(buffer)); char lable[]="|/-\\"; int len = strlen(lable); int num = (int)(current*100 / total); int i = 0; for(i = 0; i < num; i++) { buffer[i]=TYPE; // 初始化字符数组 } static int cnt = 0; double rate = current*100 / total; printf("[%-100s][%.2lf%%][%c]\r",buffer, rate, lable[cnt % len]); cnt++; fflush(stdout); }main.c文件
bash#include"process.h" void process_v2(double current, double total); // 函数声明 typedef void(*Fflush)(double,double); // 函数指针 #define total 1024.0 // 资源的大小 #define speed 1.0 // 网速 void download(Fflush process) { double current = 0; while(current <= total) { process(current, total); usleep(1000); // 模拟下载 current += speed; // 更新current,代表已经下载的资源 } printf("资源已下载完毕,共%.2lf\n",current); } int main() { download(process_v2); printf("\n"); return 0; }