命令与动态库:从文件操作到程序链接的实践指南
- [Linux 下 C 程序编译:从预处理到动态链接的深度解析](#Linux 下 C 程序编译:从预处理到动态链接的深度解析)
-
- (1)预处理(进行宏替换))
- (2)编译(生成汇编)
- [(3) 汇编(生成机器可识别的代码)](#(3) 汇编(生成机器可识别的代码))
- (4)链接
- [Linux 下动态链接与函数调用原理:从符号解析到内存映射的深度剖析](#Linux 下动态链接与函数调用原理:从符号解析到内存映射的深度剖析)
- [Linux 动态库与静态库实战:链接方式对比与底层原理解析](#Linux 动态库与静态库实战:链接方式对比与底层原理解析)
-
- [(1) 库的基础概念:什么是静态库与动态库?](#(1) 库的基础概念:什么是静态库与动态库?)
- [(3) 链接方式的底层原理对比](#(3) 链接方式的底层原理对比)

Linux 下 C 程序编译:从预处理到动态链接的深度解析
(1)预处理(进行宏替换)
-
文件包含(#include):将指定文件内容嵌入当前代码,分两种形式。<头文件> 从系统标准库路径查找,"自定义头文件" 先从当前项目路径查找。
-
宏定义(#define):纯文本替换,无类型检查。不带参数的宏(如 #define PI 3.14)直接替换字面量;带参数的宏(如 #define MAX(a,b) ((a)>(b)?(a):(b)))需注意括号避免运算优先级问题。
-
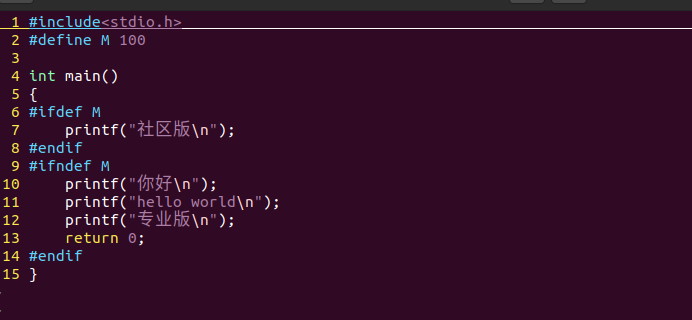
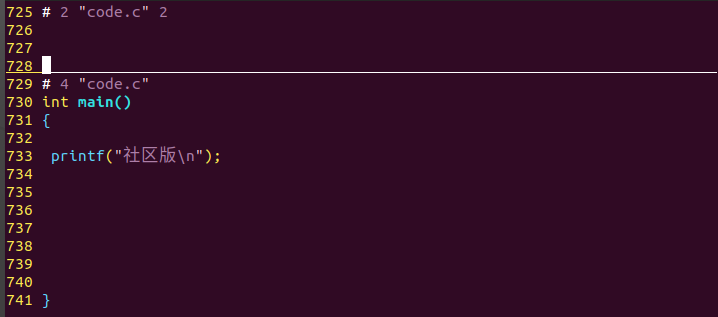
条件编译(#if/#ifdef/#ifndef 等):按条件保留或丢弃代码块,常用于跨平台适配、调试代码开关。例如 #ifdef DEBUG printf("调试信息"); #endif,编译时定义 DEBUG 才会保留该打印语句。
宏替换:
通过编译之后,code.i的文件中M会被替换定义好的100
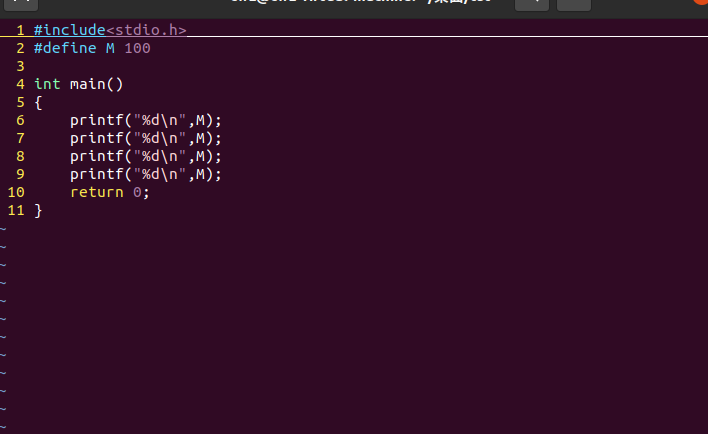
bash
gcc -E 编译的文件 -o code.i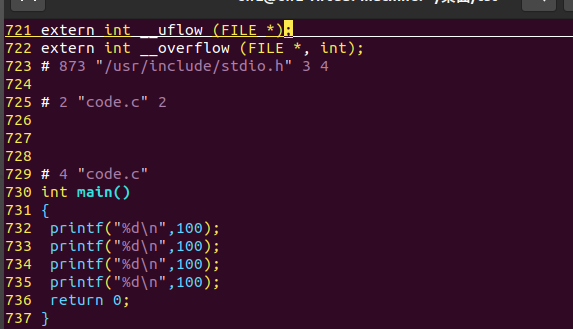
条件编译:
预处理之前:
预处理之后:
(2)编译(生成汇编)
将预处理后的代码转换为汇编代码(.s文件)
bash
gcc -S code.i -o code.scode.i 经过编译形成汇编 code.s
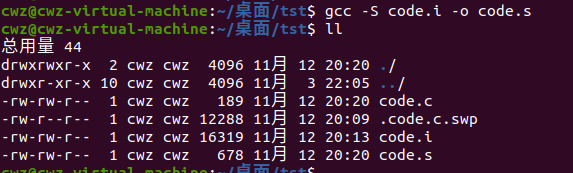
(3) 汇编(生成机器可识别的代码)
将汇编代码转换为二进制目标文件(机器码,不可直接执行)
bash
gcc -c code.s -o code.o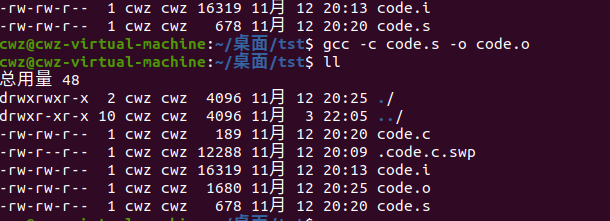
(4)链接
合并目标文件和依赖库,生成可执行程序
bash
gcc code.o -o aaa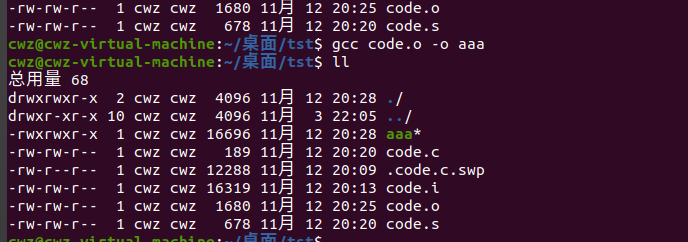
编译流程的完整阶段(从源代码到可执行文件)
bash
源代码(.c) → 预处理(Preprocessing) → 编译(Compilation) → 汇编(Assembly) → 链接(Linking) → 可执行文件自动完成多阶段流程:
bash
gcc code.c -o aaa直接从code.c - > aaa (中间过程跳过)
为什么要链接呢?
可执行文件要依赖多个库,如printf本身就是一个函数,我们需要引入包含这个函数定义的函数,才方便我们直接使用!!!
bash
ldd 可执行
这里显然需要C语言库的支持。
Linux 下动态链接与函数调用原理:从符号解析到内存映射的深度剖析
在 Linux 系统的程序运行机制中,动态链接与函数调用是保证程序模块化、可维护性与性能平衡的核心技术。本文将从符号解析、内存映射到实际运行的全流程,结合图示深度剖析其原理,让你彻底搞懂 Linux 程序是如何 "拼起来" 并执行的。
(1)动态链接的前置知识:为什么需要动态链接?
在理解动态链接前,先思考一个问题:程序为什么不把所有功能都静态打包?
静态链接(如gcc -static)会将所有依赖库的代码嵌入可执行文件,这会导致两个致命问题:
-
体积爆炸:多个程序依赖同一库时,会重复存储库代码,浪费磁盘空间;
-
更新困难:库升级后,所有依赖它的程序都要重新编译链接。动态链接则是 "按需共享" 的解决方案 ------多个程序共享同一份库的内存镜像,既节省空间,又能通过更新库文件实现 "一次升级,所有程序受益"。
(2)动态链接的核心流程:从符号解析到内存映射
1. 编译阶段:符号的 "标记与等待"
当我们用gcc编译动态链接的程序时(如gcc code.c -o code),编译器会做两件关键事:
-
标记 "外部符号":程序中调用的库函数(如printf)会被标记为 "未解析符号",记录在可执行文件的符号表中;
-
生成重定位表:标记哪些指令需要在加载时 "修正地址",因为库函数的实际内存地址在编译时是未知的。
2. 加载阶段:动态链接器的 程序启动时,Linux 的动态链接器(ld.so) 会接管控制权,完成 "符号拼图":
-
步骤 1:加载依赖库:读取可执行文件的.dynamic段,找到所有依赖的动态库(如libc.so.6),将它们加载到内存;
-
步骤 2:符号解析:遍历程序和库的符号表,将 "未解析符号"(如printf)与库中实际符号地址关联;
-
步骤 3:重定位:根据解析后的地址,修正程序中需要 "跳转到库函数" 的指令,让 CPU 能正确执行跨模块调用。
3. 运行阶段:内存映射
动态库加载到内存后,Linux 通过内存映射(mmap) 实现 "多程序共享同一份代码":
-
操作系统将库文件的.text段(代码区)映射到多个进程的虚拟内存中,物理内存只存一份,不同进程通过虚拟地址映射到同一块物理内存;
-
库的.data段(数据区)则是 "写时复制(COW)"------ 进程修改数据时才会复制一份,保证进程间数据隔离。
(3)函数调用的底层实现:从call指令到动态跳转
动态链接下的函数调用,比静态调用多了 "运行时地址修正" 的环节,以printf("hello")为例,拆解其执行流程:
1.编译时的 "占位符":gcc编译时,会生成一条call printf指令,但此时printf的地址是 "占位符"(重定位项);
2.加载时的 "地址填充":动态链接器解析到printf在libc.so.6中的实际地址后,将该地址写入call指令的 "目标地址" 字段;
3.运行时的 "指令执行":CPU 执行call指令,跳转到libc.so.6中printf的入口地址,执行打印逻辑。
Linux 动态库与静态库实战:链接方式对比与底层原理解析
在 Linux 程序开发中,库的链接方式(静态链接 vs
动态链接)直接影响程序的体积、性能和可维护性。本文将从实战出发,对比两种链接方式的差异,并深入底层原理,让你彻底掌握库链接的核心逻辑。
(1) 库的基础概念:什么是静态库与动态库?
-
静态库:以libxxx.a为后缀,编译时会被完整嵌入可执行文件。程序运行时不依赖外部库文件,可独立运行。
-
动态库:以libxxx.so为后缀,编译时仅记录 "依赖关系",运行时才会加载到内存。多个程序可共享同一份动态库的内存镜像。
动态库:
我们通过指令:ldd 可执行

默认给我们链接的就是动态库
查看可执行的属性:
bash
file aaa
这里可以看出来是动态(dynamically链接)
静态库:
要编译静态库,必须使用C语言库。如果没有该库,需要手动下载,因为多数编译器默认只提供动态库链接,不会自动下载C语言静态库。
通过静态库进行编译,需要很多空间比动态链接多太多了
(3) 链接方式的底层原理对比
| 维度 | 静态链接 | 动态链接 |
|---|---|---|
| 编译阶段 | 库代码被完整嵌入可执行文件 | 仅记录库的依赖关系,生成重定位表 |
| 运行阶段 | 无依赖,直接运行 | 需加载动态库到内存,解析符号 |
| 文件体积 | 可执行文件较大 | 可执行文件小,库文件共享 |
| 更新维护 | 库更新后需重新编译程序 | 库更新后,程序无需重新编译 |
| 内存占用 | 多个程序使用同一库时,内存重复加载 | 多个程序共享同一份库的内存镜像 |
| 启动速度 | 启动快(无额外加载步骤) | 启动稍慢(需动态链接器解析符号) |