源代码仓库
https://gitee.com/zirui-shu/programsJS逆向爬虫解析
内容说明
本文将在
爬虫进阶 JS逆向基础超详细,解锁加密数据_js 逆向 腾讯表在线表格文档-CSDN博客![]() https://blog.csdn.net/h860818/article/details/154149865?spm=1001.2014.3001.5502的基础上进一步讲解JS逆向的应用,对于一些基础的部分不再讲解,如有需要可以看看我的文章补补基础。
https://blog.csdn.net/h860818/article/details/154149865?spm=1001.2014.3001.5502的基础上进一步讲解JS逆向的应用,对于一些基础的部分不再讲解,如有需要可以看看我的文章补补基础。
1.分析网页
我们这次要爬取的是:
新股频道-提供新股申购,新股发行一览表,新股申购新规等投资行情信息_同花顺金融网![]() https://data.10jqka.com.cn/ipo/xgsgyzq/
https://data.10jqka.com.cn/ipo/xgsgyzq/ 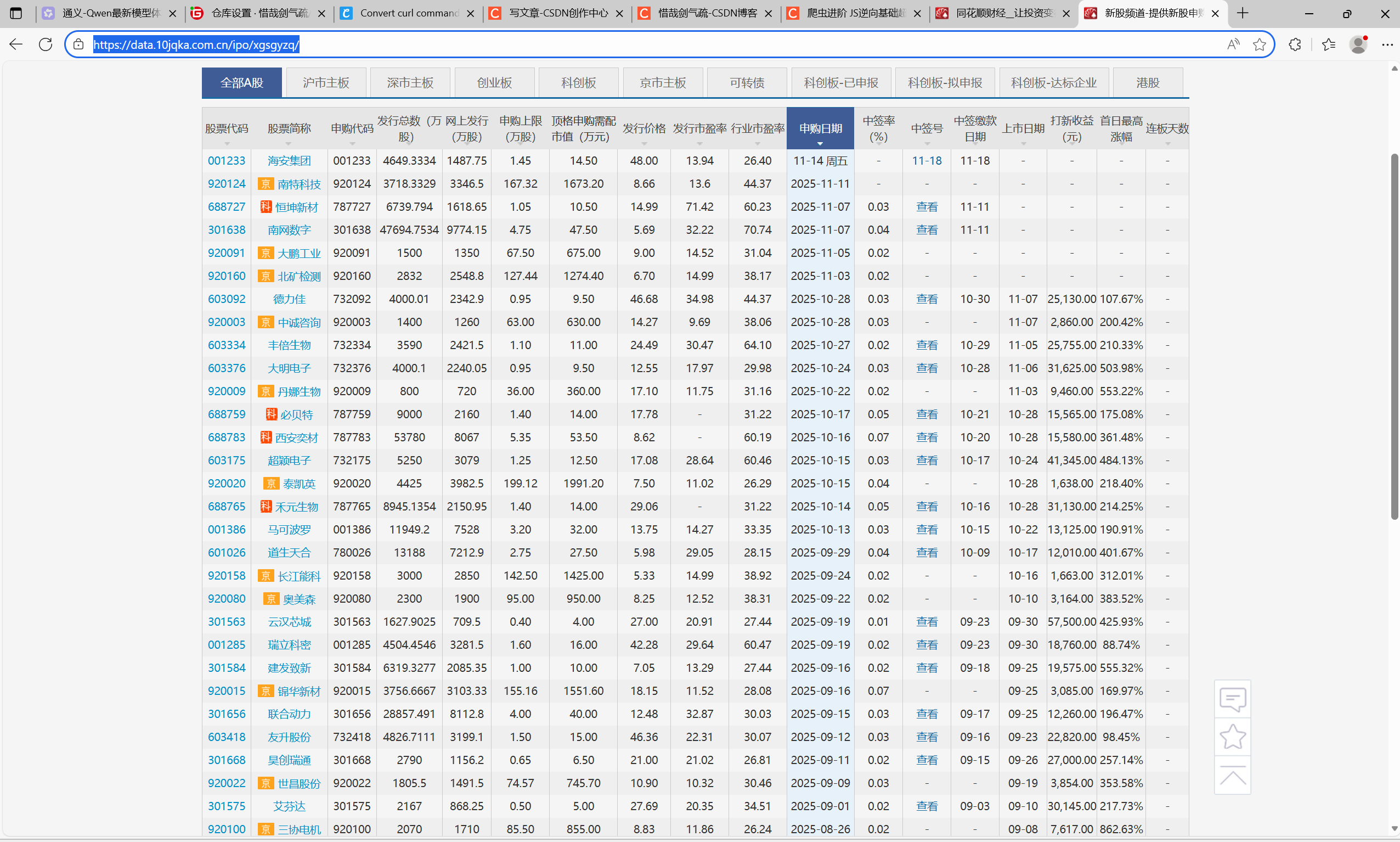
目标是图中的表格数据。
发现目标:
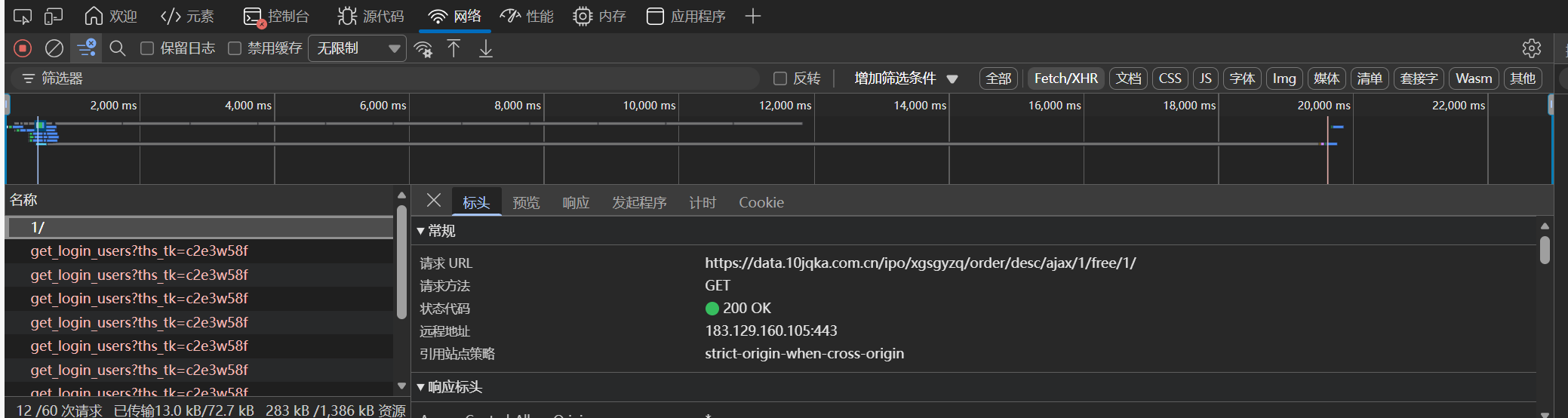
将目标的cURL复制到前文所提过的懒人工具,在运行后得到输出:
"D:\Program Files\python\3.11.9\python.exe" D:\PythonProject\Crawler\同花顺\main.py
<html><body>
<script type="text/javascript" src="//s.thsi.cn/js/chameleon/chameleon.min.1762957.js"></script> <script type="text/javascript" src="//s.thsi.cn/js/chameleon/chameleon.1.7.min.1762957.js"></script> <script src="//s.thsi.cn/js/chameleon/chameleon.1.7.min.1762957.js" type="text/javascript"></script>
<script language="javascript" type="text/javascript">
window.location.href="//data.10jqka.com.cn/ipo/xgsgyzq/order/desc/ajax/1/free/1/";
</script>
</body></html>
进程已结束,退出代码为 0(不过有时能得出结果,是服务器坏了?)
显而易见,单纯的爬虫肯定是爬不了了。对文件仔细分析之后,发现该文件的Cookie有个特点:

其中HttpOnly这一项是空的,也就是说我们从cURL中复制过来的Cookie(也就是网页生成的Cookie)是用不了的,我们需要自己通过JS逆向破解Cookie的值。
其他值还好,主要是v的值不对。所以,接下来的JS逆向过程主要围绕着获取v值展开。
2.获取v值
首先,我们写一个JS脚本的钩子函数,在触碰到v的时候对网页进行debug操作:
(function () {
'use strict';
var cookieTemp = '';
Object.defineProperty(document, 'cookie', {
get: function () {
return cookieTemp;
},
set: function (val) {
if(val.indexOf('v') !== -1){
debugger;
}
console.log('Hook捕获到cookie设置->', val);
cookieTemp = val;
return val;
}
});
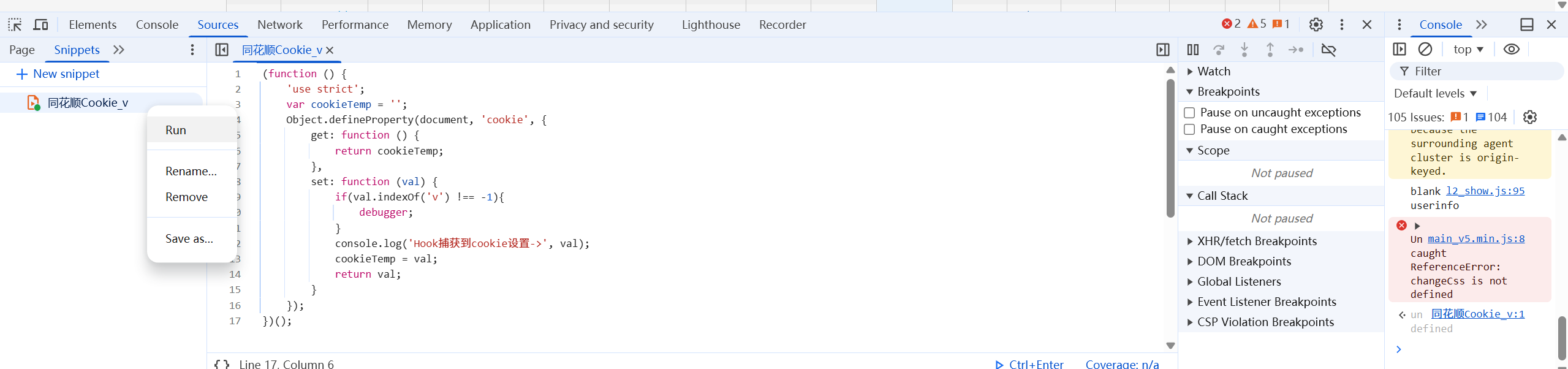
})();将这段代码复制到Source->Snippets->New snippet,构建一个新的JS脚本,并且右键文件点击执行,出现绿色标志就算成功了:
再出现绿色标志后,在原页面下方切换表格页数,进入到debug页面:
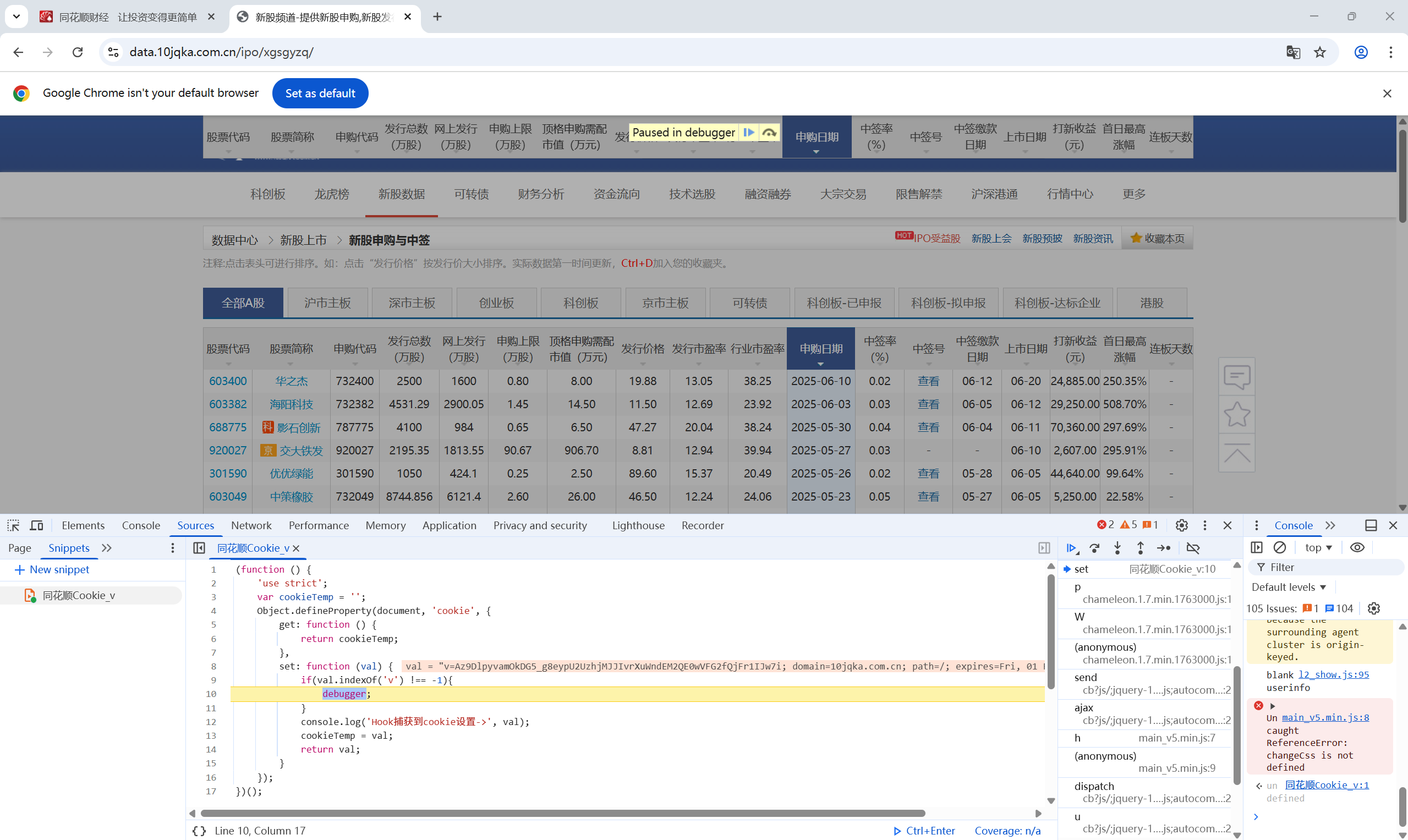
我们JS文件的右边部分有多个函数,这些就是跟v生成相关的函数。点击这些函数一个个查看,发现生成Cookie的函数:
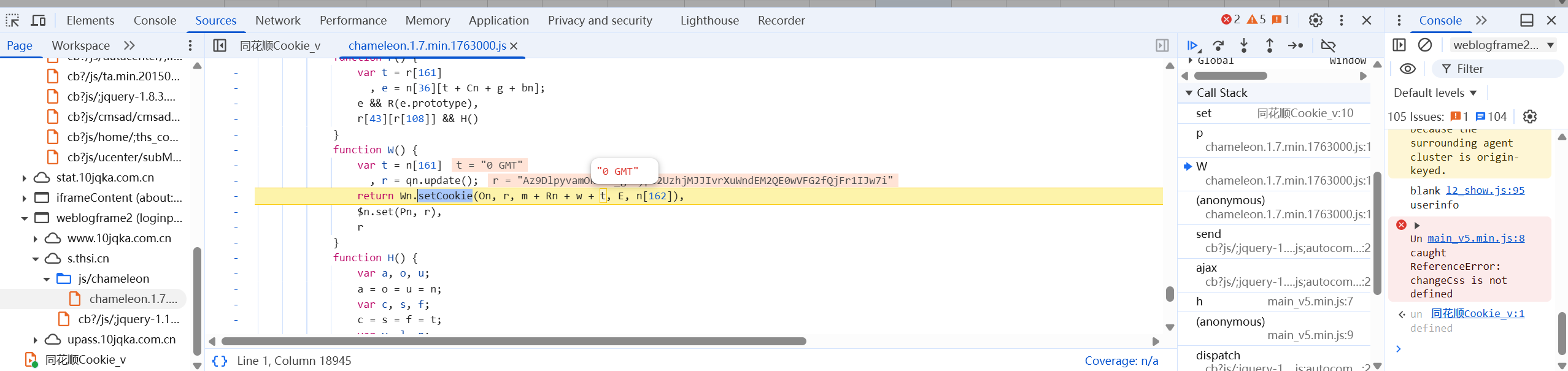
注意到目前涉及到的两个函数都是在同一个文件夹之下,干脆把整个JS文件全复制下来,并且使用全局变量在外部调用W()获取它的返回值:
window = global
......
function W() {
var t = n[161]
, r = qn.update();
return Wn.setCookie(On, r, m + Rn + w + t, E, n[162]),
$n.set(Pn, r),
r
}
window.outerW = W
......
cookie_v = window.outerW();
console.log(cookie_v);执行JS文件后就报错了:
ReferenceError: document is not defined这就涉及到了另外一个问题:Node.js环境跟浏览器中的环境是不一样的。在浏览器之中,有一些自带的原生函数或方法在Node.js里是不存在的,还有一些变量如window,document 等等。我们接下来要做的就是给JS文件补浏览器环境。
【附】补浏览器环境变量及监视代码
这段代码相对来说较为固定,是段通用的死代码,看看就够了:
function get_environment(proxy_array) {
for (var i = 0; i < proxy_array.length; i++) {
handler = '{\n' +
' get: function(target, property, receiver) {\n' +
' console.log("方法:", "get ", "对象:", ' +
'"' + proxy_array[i] + '" ,' +
'" 属性:", property, ' +
'" 属性类型:", ' + 'typeof property, ' +
// '" 属性值:", ' + 'target[property], ' +
'" 属性值类型:", typeof target[property]);\n' +
' return target[property];\n' +
' },\n' +
' set: function(target, property, value, receiver) {\n' +
' console.log("方法:", "set ", "对象:", ' +
'"' + proxy_array[i] + '" ,' +
'" 属性:", property, ' +
'" 属性类型:", ' + 'typeof property, ' +
// '" 属性值:", ' + 'target[property], ' +
'" 属性值类型:", typeof target[property]);\n' +
' return Reflect.set(...arguments);\n' +
' }\n' +
'}'
eval('try{\n' + proxy_array[i] + ';\n'
+ proxy_array[i] + '=new Proxy(' + proxy_array[i] + ', ' + handler + ')}catch (e) {\n' + proxy_array[i] + '={};\n'
+ proxy_array[i] + '=new Proxy(' + proxy_array[i] + ', ' + handler + ')}')
}
}
proxy_array = ['window', 'document', 'location', 'navigator', 'history', 'screen', 'aaa', 'target']
get_environment(proxy_array);这段代码的作用就是补齐浏览器的一些变量,并且在调用时记录过程,相当于给整个文件装一个**【监控】。**
接下来再运行整个JS文件,输出:
方法: get 对象: document 属性: head 属性类型: string 属性值类型: undefined
方法: get 对象: document 属性: getElementsByTagName 属性类型: string 属性值类型: undefined对于前面,我们有一个document 的head 属性及getElementByTagName未定义。将document的json格式数据打印出来:
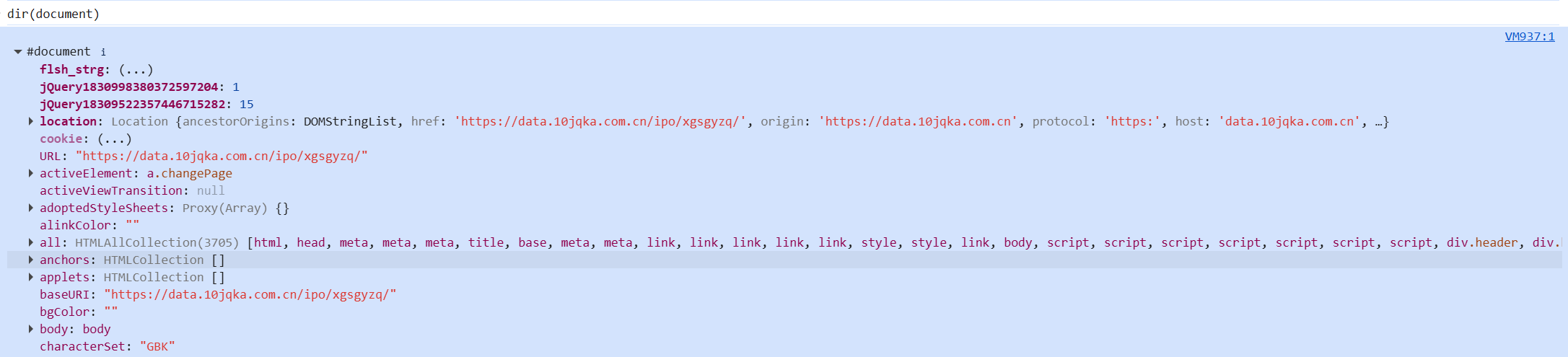
找出其中的对应变量及函数补全:
document = {
head: {
tagName: "HEAD"
},
getElementsByTagName: function (tagName) {
console.log('方法:', 'getElementsByTagName', '对象:', 'document', '属性:', tagName, '属性类型:', typeof tagName)
},
}再运行:
方法: get 对象: window 属性: document 属性类型: string 属性值类型: object
方法: get 对象: window 属性: addEventListener 属性类型: string 属性值类型: undefined通过同样的方式补全,在此不过多赘述:
window.addEventListener = function (tagName) {
console.log('方法:', 'addEventListener', '对象:', 'window', '属性:', tagName, '属性类型:', typeof tagName)
}
TypeError: e[85].createElement is not a function将方法输入到控制台,得:
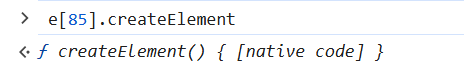
native code 说明是本地方法,还是要补环境,也就是在document里添加方法:
createElement: function (tagName) {
console.log('方法:', 'createElement', '对象:', 'document', '属性:', tagName, '属性类型:', typeof tagName)
},输出:
方法: set 对象: window 属性: addEventListener 属性类型: string 属性值类型: undefined
方法: get 对象: window 属性: document 属性类型: string 属性值类型: object
方法: get 对象: window 属性: addEventListener 属性类型: string 属性值类型: function
方法: createElement 对象: document 属性: div 属性类型: string
D:\PythonProject\Crawler\同花顺\test.js:762
y = n[101] in e[85].createElement(r[94]) ? Hn(r[95], n[102]) : o + i + u in n[83] ? c + s + J + Y : q + z;
^
TypeError: Cannot use 'in' operator to search for 'onwheel' in undefined从错误代码可以看出,虽然我们添加了对应的方法,但是需要一个返回值才能使用in 关键字。正好【监控】 记录下了调用document.createElement('div'),我们利用控制台输出:
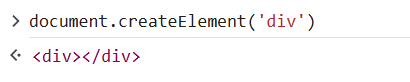
这其实就是一个标签,没有任何内容。我们在原来的函数中在这种情况下添加返回值:
createElement: function (tagName) {
console.log('方法:', 'createElement', '对象:', 'document', '属性:', tagName, '属性类型:', typeof tagName)
if (tagName === 'div') {
return {
tagName: "DIV"
}
}
},(返回一个空对象也是可以的)
后续读者可以自行调试,补充其余环境:
addEventListener: function (tagName) {
console.log('方法:', 'addEventListener', '对象:', 'document', '属性:', tagName, '属性类型:', typeof tagName)
}
//document方法
documentElement: {
baseURI: "https://data.10jqka.com.cn/market/longhu/code/688141/",
clientHeight: 151,
clientWidth: 1594,
offsetHeight: 3098,
offsetWidth: 1594,
tagName: "HTML"
},
//document属性
location = {
hostname: "data.10jqka.com.cn",
protocol: "https:"
}成功返回v值:
方法: set 对象: window 属性: addEventListener 属性类型: string 属性值类型: undefined
方法: get 对象: window 属性: document 属性类型: string 属性值类型: object
方法: get 对象: window 属性: addEventListener 属性类型: string 属性值类型: function
方法: createElement 对象: document 属性: div 属性类型: string
方法: addEventListener 对象: document 属性: DOMMouseScroll 属性类型: string
方法: addEventListener 对象: document 属性: mousemove 属性类型: string
方法: addEventListener 对象: document 属性: touchmove 属性类型: string
方法: addEventListener 对象: document 属性: click 属性类型: string
方法: addEventListener 对象: document 属性: keydown 属性类型: string
方法: get 对象: window 属性: addEventListener 属性类型: string 属性值类型: function
方法: set 对象: window 属性: outerW 属性类型: string 属性值类型: undefined
方法: get 对象: window 属性: CHAMELEON_LOADED 属性类型: string 属性值类型: undefined
方法: get 对象: window 属性: location 属性类型: string 属性值类型: object
方法: get 对象: window 属性: location 属性类型: string 属性值类型: object
方法: get 对象: window 属性: location 属性类型: string 属性值类型: object
方法: get 对象: window 属性: location 属性类型: string 属性值类型: object
方法: set 对象: window 属性: CHAMELEON_LOADED 属性类型: string 属性值类型: undefined
方法: get 对象: window 属性: outerW 属性类型: string 属性值类型: function
方法: get 对象: window 属性: location 属性类型: string 属性值类型: object
方法: get 对象: window 属性: location 属性类型: string 属性值类型: object
A44KrQ0na-yqLN_IgJzVYFl33mVQD1IJZNMG7bjX-hFMGy51IJ-iGTRjVvyL3.构建基础爬虫代码
结合之前的懒人爬虫基本框架,修改Cookie的v值,并且根据不同页数的相似文件名构建完整爬虫代码(读者自行实现):
import requests
import execjs
with open('Cookie_v.js', 'r', encoding='utf-8') as f:
js_code = f.read()
v = execjs.compile(js_code).call('window.outerW')
print(v)
cookies = {
'Hm_lvt_722143063e4892925903024537075d0d': '1762603973',
'HMACCOUNT': '481441E951CF8E41',
'Hm_lvt_929f8b362150b1f77b477230541dbbc2': '1762603973',
'Hm_lvt_78c58f01938e4d85eaf619eae71b4ed1': '1762603973',
'Hm_lvt_69929b9dce4c22a060bd22d703b2a280': '1762603973',
'Hm_lvt_60bad21af9c824a4a0530d5dbf4357ca': '1762604015',
'Hm_lvt_f79b64788a4e377c608617fba4c736e2': '1762604016',
'historystock': '603382',
'spversion': '20130314',
'Hm_lpvt_722143063e4892925903024537075d0d': '1762870790',
'Hm_lpvt_929f8b362150b1f77b477230541dbbc2': '1762870790',
'Hm_lpvt_69929b9dce4c22a060bd22d703b2a280': '1762870791',
'Hm_lpvt_60bad21af9c824a4a0530d5dbf4357ca': '1762953261',
'Hm_lpvt_f79b64788a4e377c608617fba4c736e2': '1762953261',
'Hm_lpvt_78c58f01938e4d85eaf619eae71b4ed1': '1762953261',
'v': v,
}
headers = {
'accept': 'text/html, */*; q=0.01',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'hexin-v': 'AwrmV3u4V1Ezrtv9TIvx8E4lW_up-45VgH8C-ZRDtt3oR6SlfIveZVAPUgpn',
'priority': 'u=1, i',
'referer': 'https://data.10jqka.com.cn/ipo/xgsgyzq/',
'sec-ch-ua': '"Chromium";v="142", "Microsoft Edge";v="142", "Not_A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0',
'x-requested-with': 'XMLHttpRequest',
# 'cookie': 'Hm_lvt_722143063e4892925903024537075d0d=1762603973; HMACCOUNT=481441E951CF8E41; Hm_lvt_929f8b362150b1f77b477230541dbbc2=1762603973; Hm_lvt_78c58f01938e4d85eaf619eae71b4ed1=1762603973; Hm_lvt_69929b9dce4c22a060bd22d703b2a280=1762603973; Hm_lvt_60bad21af9c824a4a0530d5dbf4357ca=1762604015; Hm_lvt_f79b64788a4e377c608617fba4c736e2=1762604016; historystock=603382; spversion=20130314; Hm_lpvt_722143063e4892925903024537075d0d=1762870790; Hm_lpvt_929f8b362150b1f77b477230541dbbc2=1762870790; Hm_lpvt_69929b9dce4c22a060bd22d703b2a280=1762870791; Hm_lpvt_60bad21af9c824a4a0530d5dbf4357ca=1762953261; Hm_lpvt_f79b64788a4e377c608617fba4c736e2=1762953261; Hm_lpvt_78c58f01938e4d85eaf619eae71b4ed1=1762953261; v=AwrmV3u4V1Ezrtv9TIvx8E4lW_up-45VgH8C-ZRDtt3oR6SlfIveZVAPUgpn',
}
response = requests.get(f'https://data.10jqka.com.cn/ipo/xgsgyzq/order/desc/ajax/1/free/1/', cookies=cookies,headers=headers).text
print(response)【附】服务器拉黑小技巧
如图,当我们的页面在点击目标文件后出现这种情况,怎么刷新界面都没有反应,大概率就是被列为爬虫拉黑了。我们可以换一个浏览器解决问题。