在大语言模型如ChatGPT、GPT-4重塑自然语言处理范式,多模态模型征服图像、视频之后,人工智能的下一个前沿阵地正悄然浮现------结构化数据。
我们日常接触的金融风控、医疗诊断、商业决策,背后都依赖于海量的表格数据。然而,与NLP和CV领域的突飞猛进相比,表格数据处理似乎还停留在"手工作坊"时代:每个任务都需要专门的模型,每个数据集都要重新训练。
今天,这一切即将改变。
AGI之路的三大支柱
论文开篇就提出了一个深刻观点:通向通用人工智能的道路需要三大互补空间共同支撑:
- 语言空间: 大语言模型如GPT系列,处理文本和代码
- 物理世界: 多模态模型如V-JEPA,理解三维空间和具身推理
- 结构化数据: 表格基础模型,支撑证据驱动的量化决策
"将表格转换为自由文本会丢弃度量几何、物理单位和缺失模式,而这些对可靠预测至关重要。"论文中的这句话道出了关键------表格数据不是语言的附属品,而是拥有独特价值的重要模态。
LimitX横空出世
来自Stable AI与清华大学的LimitX团队提出了全新的大型结构化数据模型系列,并开源了前两个版本:LimitX-16M和LimitX-2M。
革命性突破:LimitX首次将结构化数据视为变量和缺失值的联合分布,使得分类、回归、缺失值填补、数据生成等任务,都能通过向单一模型提出查询来完成。
想象一下,一个既能预测股票走势,又能填补医疗记录缺失值,还能生成合成数据用于隐私保护的基础模型------这就是LimitX带来的变革。
技术解码
- 模型架构
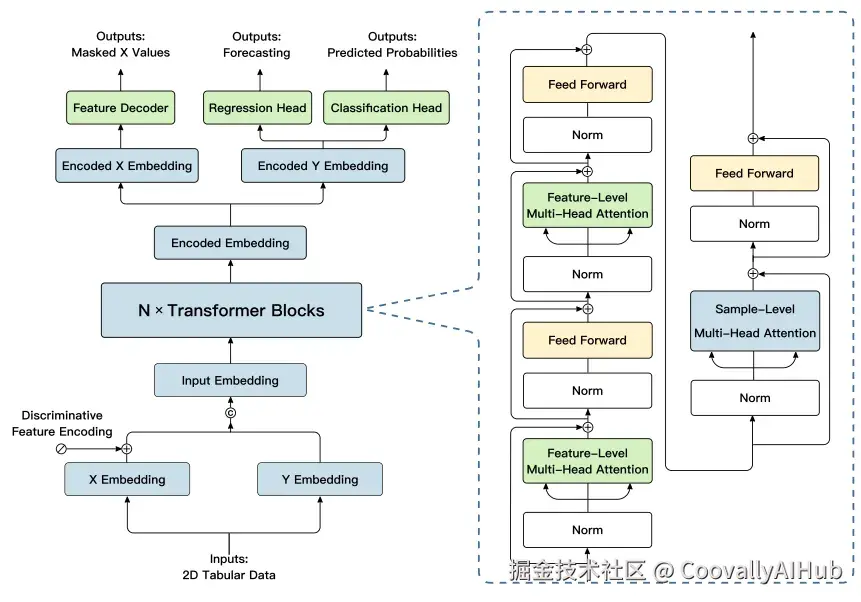
LimitX采用轻量级可扩展架构,将表格数据表示为样本-特征嵌入集合,并沿两个维度学习依赖关系:
- 特征维度(列与列之间)
- 样本维度(行与行之间)
特别值得一提的是判别性特征编码设计,这相当于给每个特征列一个独特的"身份证",让模型能够识别不同列的身份,同时保持参数高效。
- 预训练策略
LimitX采用上下文条件掩码建模进行预训练。简单来说,就是随机遮盖表格中的单元格,然后让模型根据上下文来预测被遮盖的内容。
这种方法巧妙地迫使模型掌握变量间各种条件依赖关系,从而有效地定义一个统一的数据联合模型。这就好比让学生通过完形填空来学习语言,既深入又全面。
- 高质量的合成数据生成
要训练强大的基础模型,需要海量多样化数据。团队采用分层结构因果模型生成合成数据,通过图感知采样和可解性感知采样,确保数据既多样又有代表性。
实战检验
团队在11个大型结构化数据基准上进行了全面评估,涵盖各种样本规模、特征维度、类别数量等现实场景。
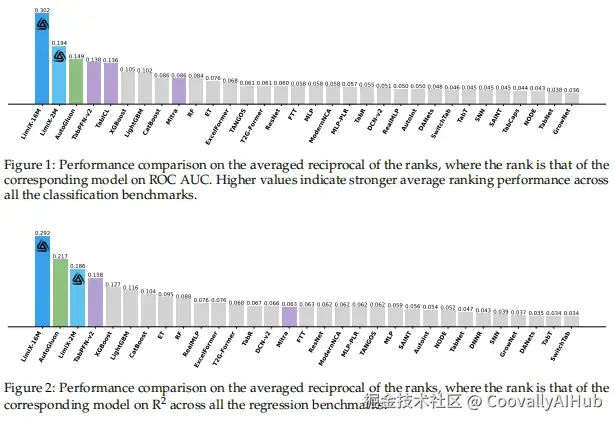
- 分类任务
在多个分类基准上,LimitX-16M展现出了统治级的表现:
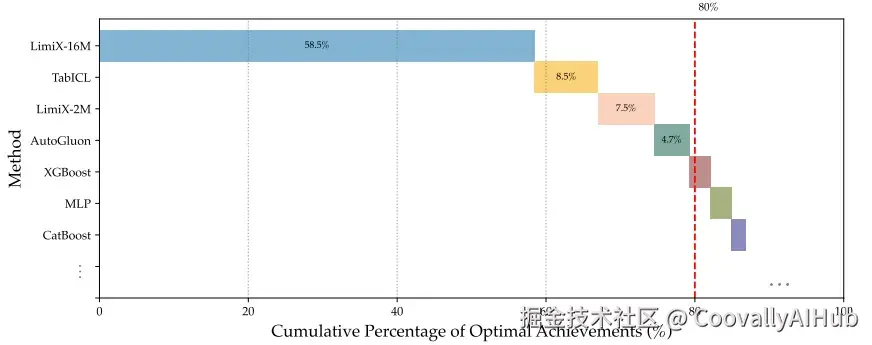
从关键差异图中可以清晰看到,LimitX-16M在统计显著性上显著优于所有基线方法:
令人惊喜的是,即使在计算资源受限的情况下,LimitX-2M仍然表现出色,证明了该方法的卓越效率。
- 回归任务
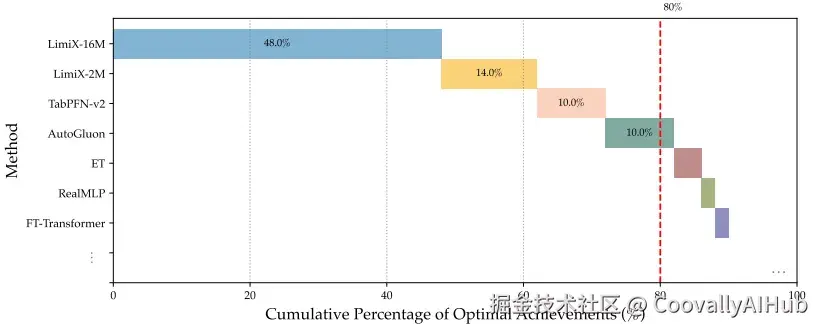
在回归任务中,LimitX-16M在R²和RMSE指标上同样领先, consistently outperforming 强大的基线如AutoGluon和XGBoost。
- 缺失值填补
传统深度学习方法填补缺失值需要在每个新数据集上重新训练,而LimitX是第一个通过上下文学习在未见过的数据集上执行缺失值填补的模型,无需任何额外训练。
- 数据生成
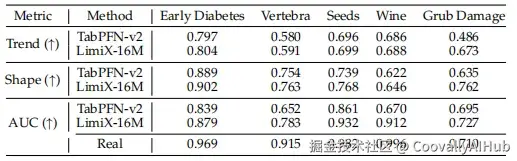
LimitX还能生成高质量的表格数据,在趋势、形状和下游分类性能等指标上均优于之前的方案。
有趣的是,在Grub Damage数据集上,使用LimitX生成数据训练的模型甚至比使用真实数据训练的模型表现更好!
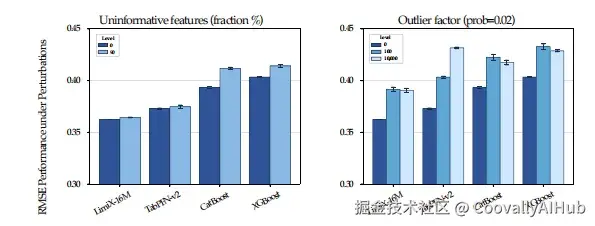
工业级鲁棒性
在实际应用中,模型需要应对各种噪声和异常。LimitX在添加不相关特征和异常值的严格测试中,展现了卓越的鲁棒性。
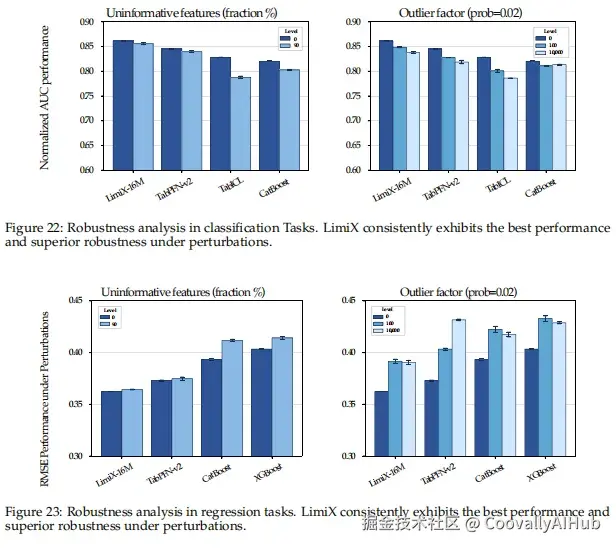
即使添加高达90%的不相关特征,LimitX的性能也几乎不受影响,而其他方法则显著下降。这种鲁棒性对于工业应用至关重要。
重大贡献
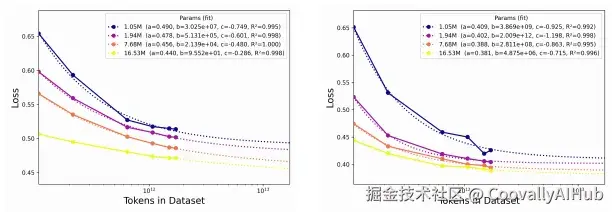
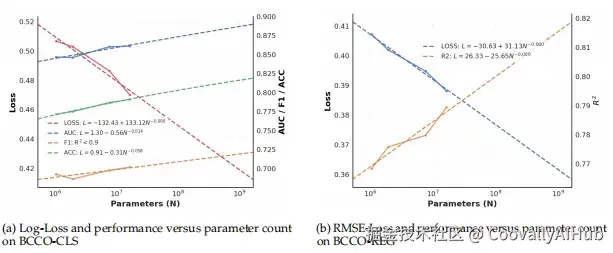
就像大语言模型一样,LimitX团队首次系统性地研究了表格基础模型的缩放定律,揭示了模型规模、数据量与性能之间的定量关系。
研究发现,表格基础模型同样遵循明确的幂律关系,为未来的模型缩放提供了宝贵的定量指导。这意味着我们终于可以科学地规划表格模型的发展路径,而不是盲目试错。
- 开源开放
ruby
论文地址:https://arxiv.org/pdf/2509.03505
GitHub:https://github.com/limix-ldm/Limix/
Hugging Face:https://huggingface.co/stableai-org/
ModelSCOPE:https://modelscope.cn/organization/stable-ai/所有LimitX模型都在Apache 2.0许可下公开可用,包括:
- 模型权重
- 训练代码
- 评估基准
预训练数据生成流程
这种开放精神将极大加速表格基础模型领域的发展,为后续研究奠定坚实基础。
展望未来
LimitX代表了表格数据处理范式的根本转变:从专门化的散装流水线,转向统一的、基础模型风格的表格学习。
正如论文结论所指出的:"这种方法为结构化数据学习提供了一条新的路径,实现了单一模型在多任务上的强大表现。"
表格基础模型的时代,已经到来。