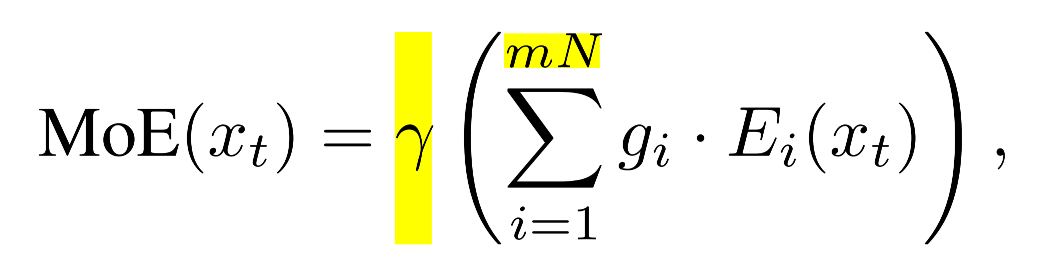美团大模型之前很少被关注过,但是近期推出的龙猫大模型很受关注,来简单总结下龙猫做了什么样的事情。
总的来说,LongCat-Flash是一个 560B的模型(28层、64个attention head),每个token激活18.6B~31.3B(平均27B)参数。 模型在30天内完成超过20T个token的训练,同时推理速度可达每秒100 token,成本低至每百万个token输出只需0.7美元。
为了让LongCat-Flash具有Agent智能,首先在混合数据集上进行大规模pre-train,随后针对推理、代码、指令开展针对性的中后期的post-train,并通过合成数据和工具使用任务进一步增强。
先来简单体验一下(https://longcat.chat/),能感受到生成速度还是非常快的,并且给出了详细的思考过程,以及中间写Python代码去调用,涉及到了Agent推理方式。

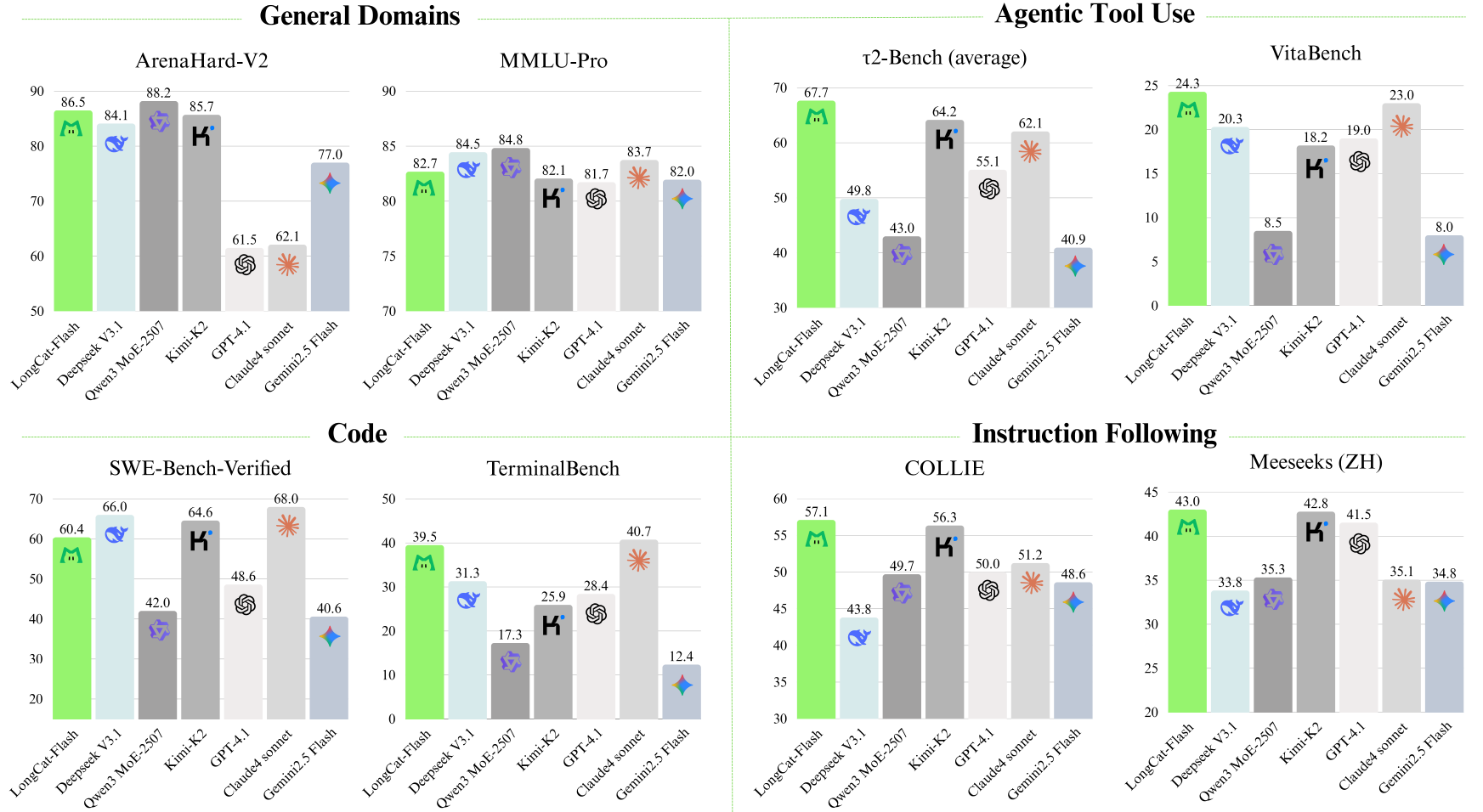
从各个任务的效果上来看,还是很具有竞争力了。
模型结构优化
LongCat-Flash是高效且强大的MoE架构模型,提出两大方面的优化:1)计算效率;2)Agent能力。
零计算专家(Zero-computation Experts)
出发点是 "并非所有token的预测难度都相同" ,所以提出在MoE模块中引入零计算专家机制,根据token的显著性动态分配计算资源。
零计算专家是identity映射函数,直接返回其输入, 不进行任何额外的计算,因此其计算成本几乎为零。
模型每层包含512个FFN专家和256个零计算专家,每个token会激活其中12个专家(注意是从两类中随机选取,是一个动态分配资源的设计)。从实验数据中的激活参数量可以感受到------每个token激活18.6B~31.3B(平均27B)参数。
计算预算控制
为激励模型 学习上下文相关的计算资源分配策略(按需分配) ,若不加限制,模型往往无法充分利用零计算专家,导致资源利用率低下。
LongCat-Flash通过改进 无辅助损失策略 中的专家偏置机制来实现这一目标:引入专家特定的偏置项,能根据专家近期使用情况动态调整路由评分,同时与模型的训练目标解耦。
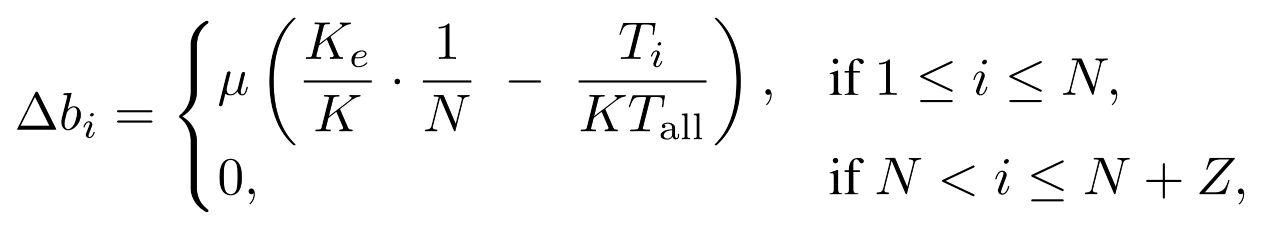
总体思想就是希望 FFN专家能够均衡地分担计算任务, 不过这个公式设计确实比较值得思考。
更新方法基于控制理论中的PID控制器(proportional-integral-derivative),这里还不太懂什么意思。
负载均衡控制
前面实现了语料级的计算预算控制,为了防止专家并行时,组间序列层面出现极端失衡,LongCat-Flash引入了 设备级负载均衡机制。

Shortcut-connected MoE(ScMoE)
大规模MoE模型的效率主要受限于通信开销,使用专家并行时,在开始计算前,必须先将token路由到指定专家,通信延迟成为瓶颈,导致GPU利用率低下。
为了解决这个问题,LongCat-Flash提出ScMoE架构,使前一个block的FFN运算与当前MoE层的dispatch/combine通信并行,从而形成更大的重叠窗口。
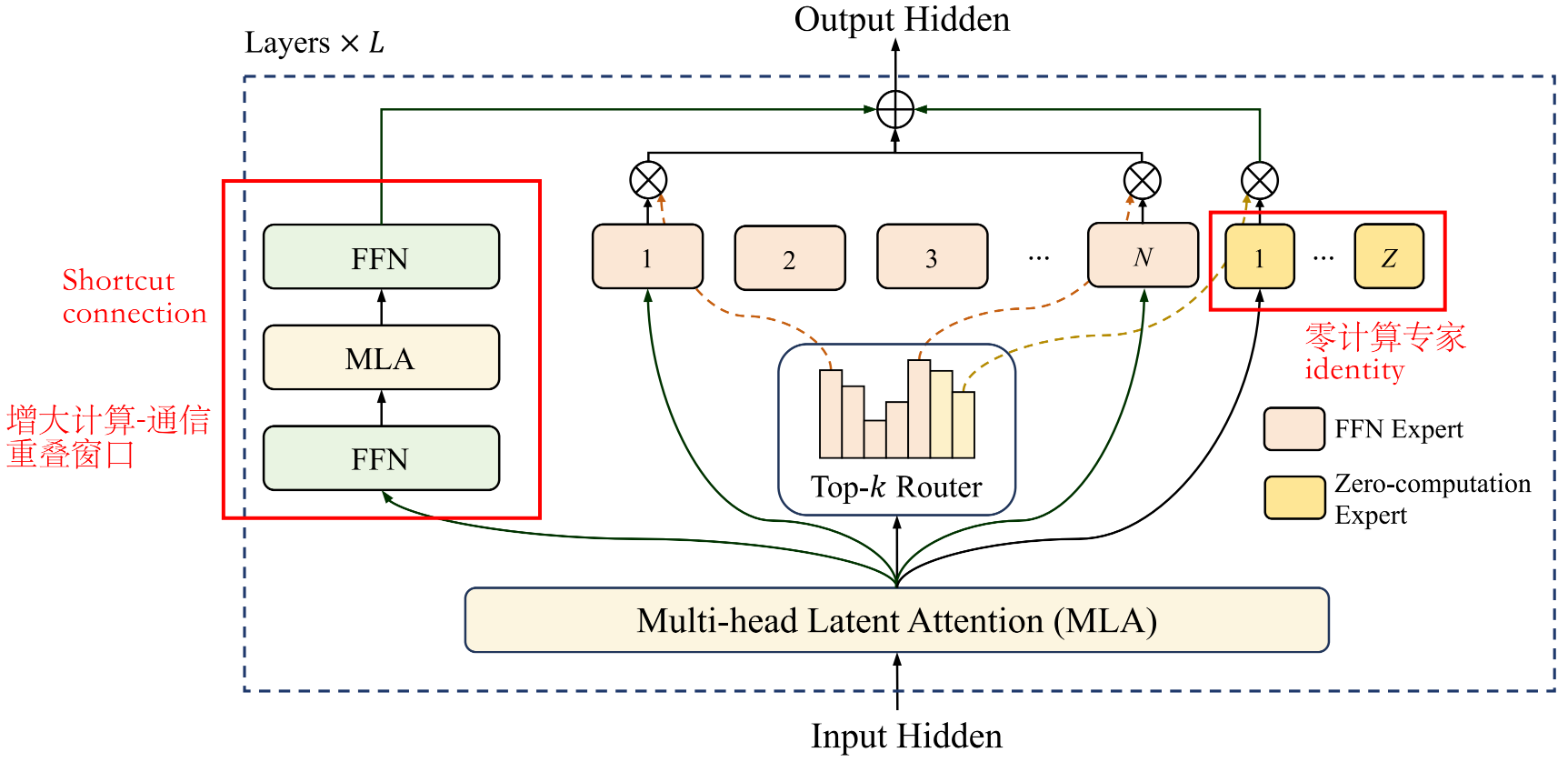
整体的结构就是在MoE的基础上增加了一个旁路(shortcut),由 FFN->MLA->FFN 组成。
模型可扩展性优化:方差对齐
LongCat-Flash发现特定模块的方差不对齐是导致这种大模型scale up效果不佳的关键因素。
MLA的缩放校准
对于MLA,非对称低秩分解时存在固有的方差失衡问题。具体而言,来自QKV三者的tensor维度大小不同(d的大小),而其方差正比于维度大小,所以方差失衡会导致注意力分数的计算在初始化时变得不稳定,进而影响模型性能。
LongCat-Flash计算了如下的放缩校准因子,并补充到MLA计算过程中:
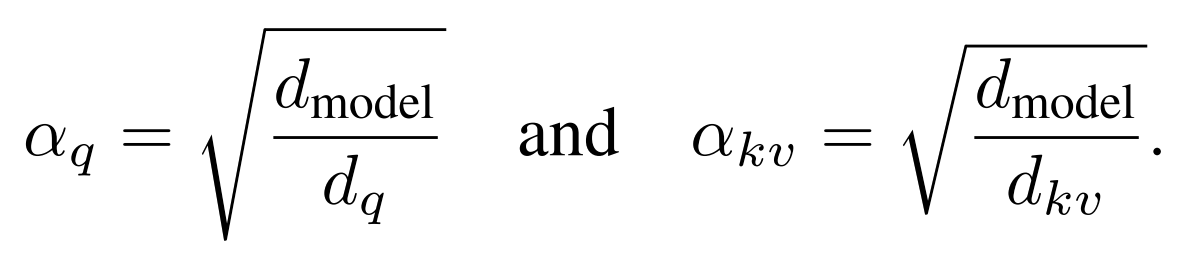
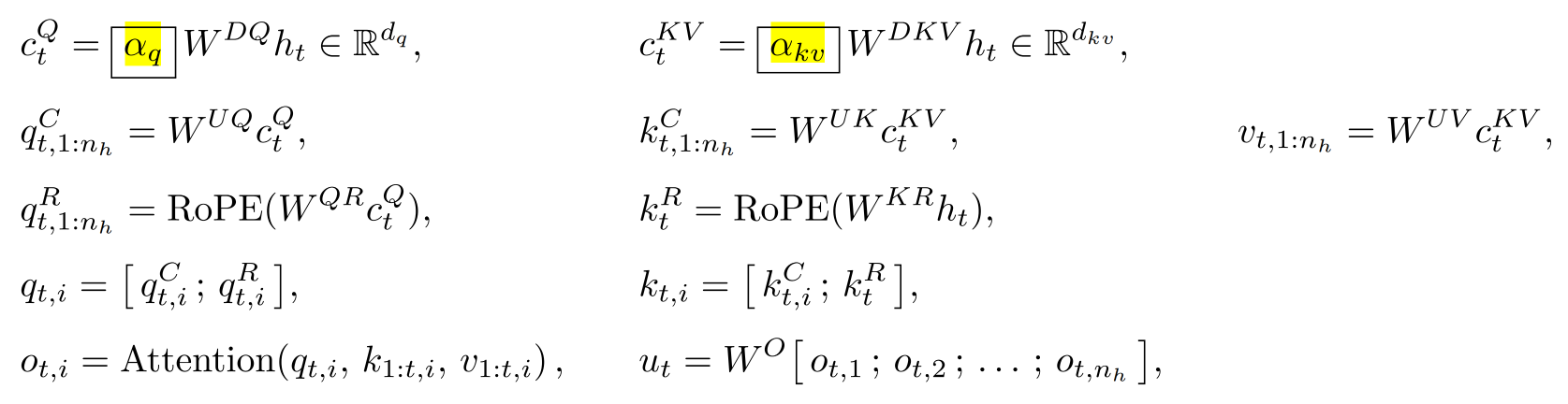
MoE专家初始化的方差补偿
LongCat-Flash采用了DeepSeek-MoE中的细粒度专家策略,将每个专家划分为m个更细粒度的子专家,以提升组合灵活性和知识专长。但是对架构的设计非常敏感,所以提出方差补偿机制,用于抵消专家分割导致的初始化方差缩减问题。方差缩减源于下面两点:
- 门控稀释:将每个原始N个专家拆分为m个更细粒度的专家后,专家总数将扩展为mN。这种扩展机制导致Softmax将概率权重分散到更大的专家池中,从而按比例降低了单个门控值gi的数值大小,并且方差也渐小。
- 维度缩减:每个细粒度专家的中间隐藏维度缩减m倍,同样也导致单个专家的输出方差降低m倍。
为了抵消这个问题,保持MoE层在初始化时的输出方差与切分前一致,模型在聚合专家输出后应用了一个补偿缩放因子:
γ = m ⋅ m = m \gamma = \sqrt{m\cdot m}= m γ=m⋅m =m