
新模型技术报告已同步发布:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2/resolve/master/assets/paper.pdf
开源DeepSeek-V3.2
text
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-V3.2
ModelScope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2DeepSeek-V3.2-Speciale
text
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
ModelScope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Speciale一、研究背景:开源与闭源的差距正在拉大
任务定义与研究动机
近几个月来,AI领域出现了一个令人担忧的趋势:尽管开源社区在不断进步,但闭源模型(如GPT-5、Gemini-3.0-Pro)的性能提升速度明显更快,开源与闭源之间的差距不是在缩小,而是在扩大。
DeepSeek团队通过分析发现,开源模型存在三个关键缺陷:
- 架构效率瓶颈:传统的注意力机制在处理长序列时效率极低,限制了模型的部署和训练
- 训练资源不足:开源模型在后训练(post-training)阶段的计算投入严重不足
- 智能体能力落后:在实际部署的AI Agent场景中,开源模型的泛化能力和指令遵循能力明显弱于闭源模型
核心贡献
DeepSeek-V3.2的三大突破:
- DeepSeek Sparse Attention (DSA) :一种高效的稀疏注意力机制,将计算复杂度从O(L2)\mathcal{O}(L^2)O(L2)降低到O(Lk)\mathcal{O}(Lk)O(Lk),同时保持长文本性能
- 可扩展的强化学习框架:后训练计算预算超过预训练成本的10%,使DeepSeek-V3.2达到GPT-5的水平
- 大规模智能体任务合成管线:生成1,800+环境和85,000+复杂提示,显著提升工具使用能力
更令人惊讶的是,高算力版本DeepSeek-V3.2-Speciale在2025年国际数学奥林匹克(IMO)和国际信息学奥林匹克(IOI)中均达到金牌水平,性能与Gemini-3.0-Pro持平。
二、相关工作
推理模型的里程碑
推理模型(如DeepSeek-R1、OpenAI o1)的发布标志着大语言模型的重要转折点,在可验证领域实现了性能飞跃。然而,近几个月闭源模型(Anthropic Claude、Google Gemini、OpenAI GPT)的发展速度明显快于开源社区(MiniMax、MoonShot、ZhiPu-AI等)。
注意力机制的演进
传统的全注意力机制(Vanilla Attention)在长序列处理上存在瓶颈。虽然已有一些稀疏注意力方案,但DeepSeek-V3.2的DSA通过闪电索引器(Lightning Indexer)和细粒度token选择机制实现了更优的效率-性能平衡。
强化学习在后训练中的应用
现有开源模型普遍在后训练阶段投入不足。DeepSeek-V3.2采用GRPO(Group Relative Policy Optimization)算法,并通过一系列创新(无偏KL估计、离策略序列掩码等)实现了稳定的大规模RL训练。
三、核心技术突破
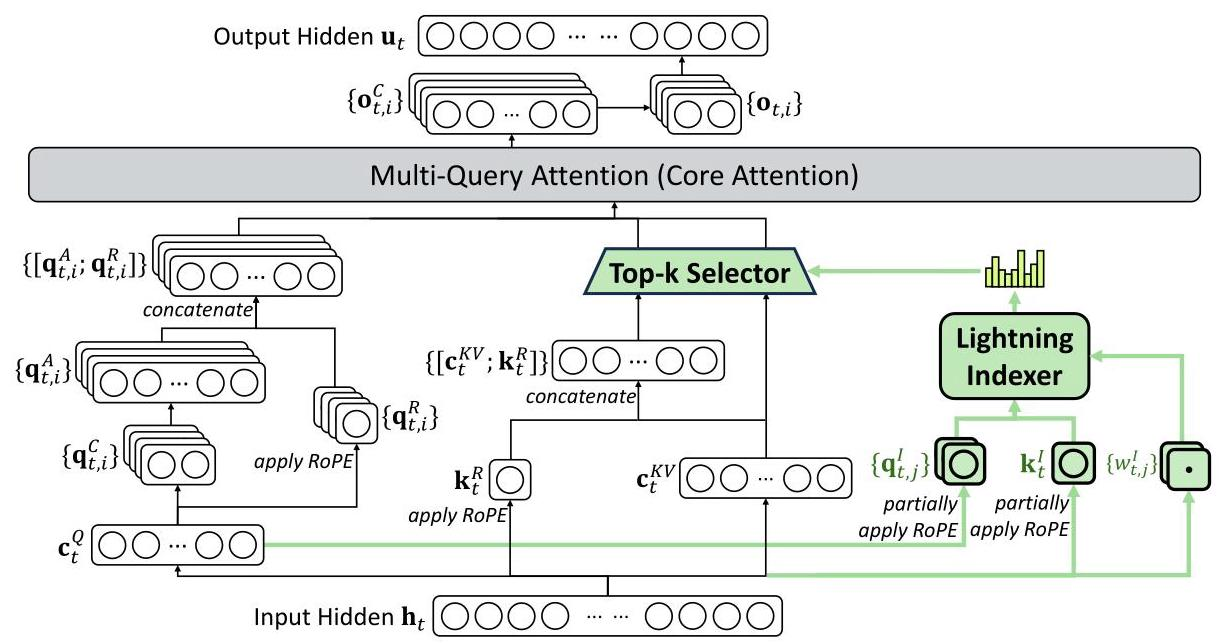
3.1 DeepSeek Sparse Attention (DSA)
DSA是DeepSeek-V3.2的架构核心,包含两个关键组件:
(1)闪电索引器(Lightning Indexer)
索引器通过计算查询token ht\mathbf{h}_tht 与前序token hs\mathbf{h}_shs 之间的索引分数来决定选择哪些token:
It,s=∑j=1HIwt,jI⋅ReLU(qt,jI⋅ksI) I_{t,s} = \sum_{j=1}^{H^I} w_{t,j}^I \cdot \text{ReLU}({\mathbf{q}}_{t,j}^I \cdot {\mathbf{k}}_s^I) It,s=j=1∑HIwt,jI⋅ReLU(qt,jI⋅ksI)
其中HIH^IHI是索引头的数量,ReLU激活函数的选择是为了提升吞吐量。索引器使用FP8精度,计算效率极高。
(2)细粒度Token选择机制
基于索引分数,只检索top-k个key-value条目,然后计算注意力输出:
ut=Attn(ht,{cs∣It,s∈Top-k(It,:)}) {\mathbf{u}}_t = \text{Attn}({\mathbf{h}}t, \{{\mathbf{c}}s | I{t,s} \in \text{Top-k}(I{t,:})\}) ut=Attn(ht,{cs∣It,s∈Top-k(It,:)})
持续预训练策略
DSA的训练分两阶段:
- 密集预热阶段:冻结主模型参数,仅训练索引器1000步(21亿tokens),通过KL散度对齐索引器与主注意力分布:
LI=∑tDKL(pt,:∥Softmax(It,:)) \mathcal{L}^I = \sum_t \mathbb{D}{\text{KL}}(p{t,:} \parallel \text{Softmax}(I_{t,:})) LI=t∑DKL(pt,:∥Softmax(It,:))
- 稀疏训练阶段 :引入token选择机制,训练15000步(9437亿tokens),学习率7.3×10−67.3 \times 10^{-6}7.3×10−6,每个查询选择2048个key-value tokens
3.2 可扩展的强化学习框架
DeepSeek-V3.2采用GRPO算法,并引入多项创新确保训练稳定性:
(1)无偏KL估计
传统K3估计器在πθ≪πref\pi_\theta \ll \pi_{\text{ref}}πθ≪πref时会产生有偏梯度。新方法使用重要性采样比修正:
DKL(πθ(oi,t)∥πref(oi,t))=πθ(oi,t∣q,oi,<t)πold(oi,t∣q,oi,<t)(πref(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−logπref(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−1) \mathbb{D}{\text{KL}}(\pi\theta(o_{i,t}) \parallel \pi_{\text{ref}}(o_{i,t})) = \frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\text{old}}(o_{i,t}|q,o_{i,<t})} \left(\frac{\pi_{\text{ref}}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})} - \log\frac{\pi_{\text{ref}}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})} - 1\right) DKL(πθ(oi,t)∥πref(oi,t))=πold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)(πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1)
(2)离策略序列掩码(Off-Policy Sequence Masking)
对负优势且策略偏离过大的样本进行掩码,阈值由δ\deltaδ控制:
Mi,t={0if A^i,t<0 and 1∣oi∣∑t=1∣oi∣logπold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)>δ1otherwise M_{i,t} = \begin{cases} 0 & \text{if } \widehat{A}{i,t} < 0 \text{ and } \frac{1}{|o_i|}\sum{t=1}^{|o_i|}\log\frac{\pi_{\text{old}}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})} > \delta \\ 1 & \text{otherwise} \end{cases} Mi,t={01if A i,t<0 and ∣oi∣1∑t=1∣oi∣logπθ(oi,t∣q,oi,<t)πold(oi,t∣q,oi,<t)>δotherwise
(3)保持路由(Keep Routing)
对于MoE模型,保留推理时的专家路由路径,在训练时强制使用相同路由,避免参数子空间突变。
(4)保持采样掩码(Keep Sampling Mask)
保留top-p/top-k采样时的截断掩码,确保新旧策略共享相同的动作子空间。
3.3 工具使用中的思考链整合
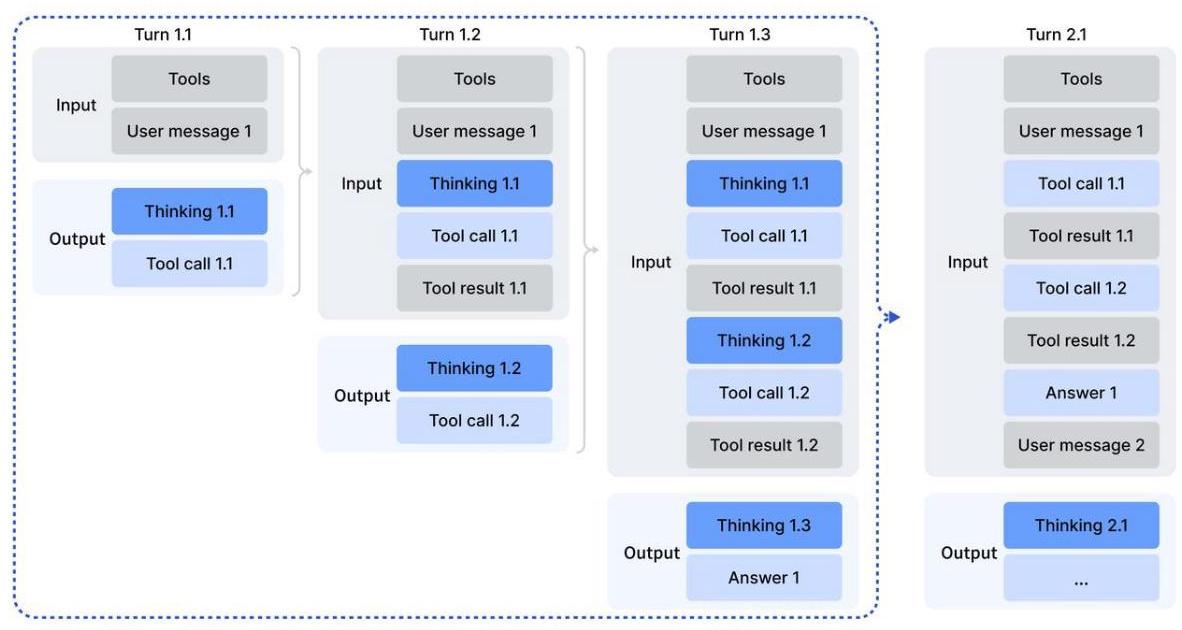
(1)思考上下文管理
针对工具调用场景,设计了特殊的上下文管理策略:
- 只有在新用户消息到来时才丢弃历史推理内容
- 如果只是工具输出追加,则保留推理轨迹
- 工具调用历史始终保留
(2)冷启动机制
通过精心设计的提示词,将推理能力与工具使用无缝结合。不同任务类型对应不同的系统提示词,引导模型在推理过程中执行多次工具调用(见附录表6-8)。
(3)大规模智能体任务合成
构建了四类智能体任务:
| 任务类型 | 任务数量 | 环境类型 | 提示词来源 |
|---|---|---|---|
| 代码智能体 | 24,667 | 真实 | 提取 |
| 搜索智能体 | 50,275 | 真实 | 合成 |
| 通用智能体 | 4,417 | 合成 | 合成 |
| 代码解释器 | 5,908 | 真实 | 提取 |
通用智能体合成示例:一个自动环境合成智能体生成1,827个任务导向环境,例如旅行规划任务(需要在大组合空间中搜索满足所有约束的方案,但验证给定方案是否满足约束相对简单)。
四、实验效果
4.1 主要基准测试结果
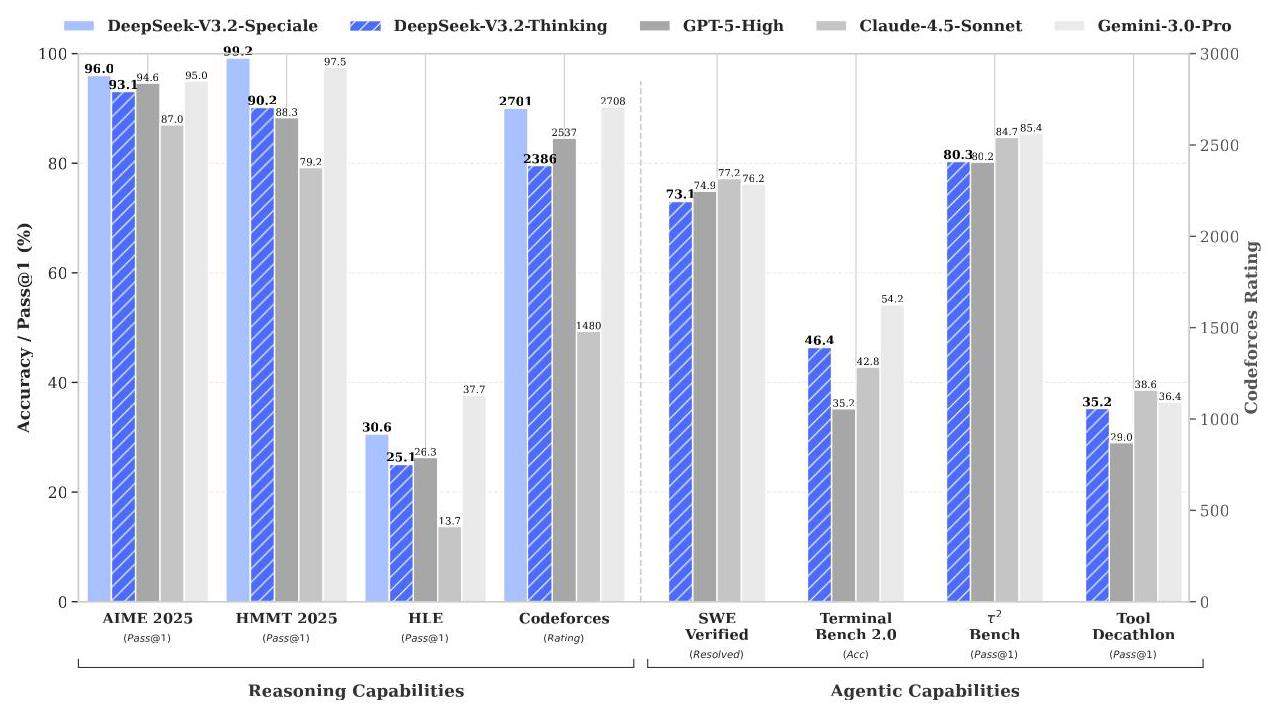
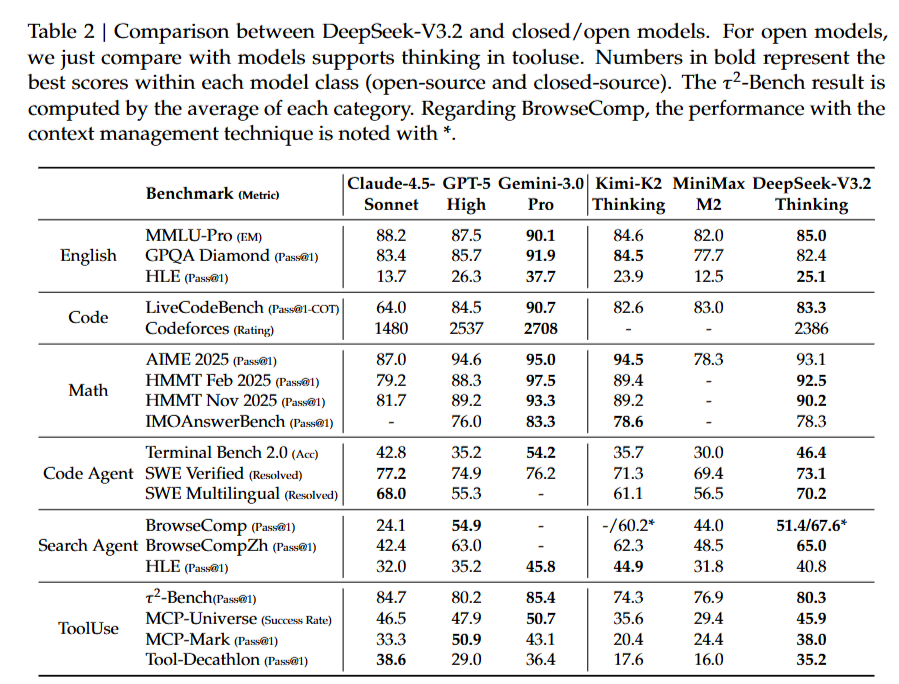
在32个基准测试中,DeepSeek-V3.2在推理、代码、数学、智能体等多个维度达到GPT-5水平:
推理任务:
- MMLU-Pro: 85.0(GPT-5: 87.5)
- GPQA Diamond: 82.4(GPT-5: 85.7)
- HLE文本题: 25.1(GPT-5: 26.3)
代码任务:
- LiveCodeBench: 83.3(GPT-5: 84.5)
- Codeforces评分: 2386(GPT-5: 2537)
数学任务:
- AIME 2025: 93.1%(GPT-5: 94.6%)
- HMMT Feb 2025: 92.5%(GPT-5: 88.3%)
- HMMT Nov 2025: 90.2%(GPT-5: 89.2%)
代码智能体:
- SWE-Verified解决率: 73.1%(领先多数开源模型)
- Terminal Bench 2.0: 46.4%(开源最佳)
搜索智能体:
- BrowseComp: 51.4%(无上下文管理)→ 67.6%(有上下文管理)
- BrowseCompZh: 65.0%
工具使用:
- τ²-Bench: 80.3(大幅领先开源模型)
- MCP-Universe成功率: 45.9%
- Tool-Decathlon: 35.2
4.2 DeepSeek-V3.2-Speciale:冲击金牌
通过放松长度约束并增加计算预算,Speciale版本在顶级竞赛中达到金牌水平:
| 竞赛 | 成绩 | 奖牌等级 |
|---|---|---|
| IMO 2025 | 35/42 | 金牌 |
| CMO 2025 | 102/126 | 金牌 |
| IOI 2025 | 492/600(第10名) | 金牌 |
| ICPC World Final 2025 | 10/12(第2名) | 金牌 |
在多个基准上,Speciale甚至超越Gemini-3.0-Pro:
- HMMT Feb 2025: 99.2% vs 97.5%
- LiveCodeBench: 88.7% vs 90.7%
- Codeforces: 2701 vs 2708
!表3:推理模型性能与效率对比
但代价是token效率较低:例如AIME任务Speciale需要23k tokens,而Gemini仅需15k。
4.3 合成任务的有效性验证
挑战性验证:随机抽取50个合成任务测试:
- DeepSeek-V3.2-Exp: 12% Pass@1
- Claude-4.5-Sonnet: 34% Pass@1
- GPT-5: 62% Pass@1
证明合成任务确实具有挑战性。
泛化能力验证:仅在合成任务上进行RL训练,在真实基准上取得显著提升:
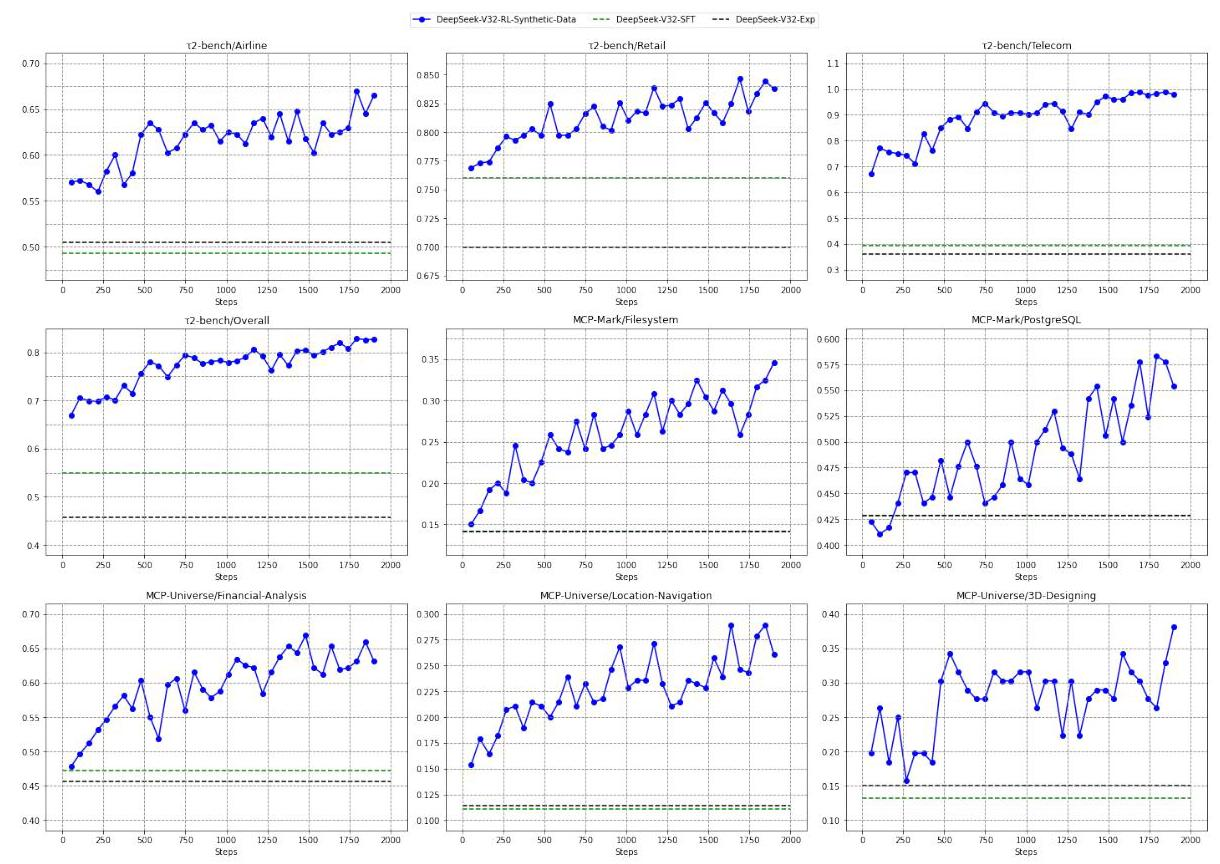
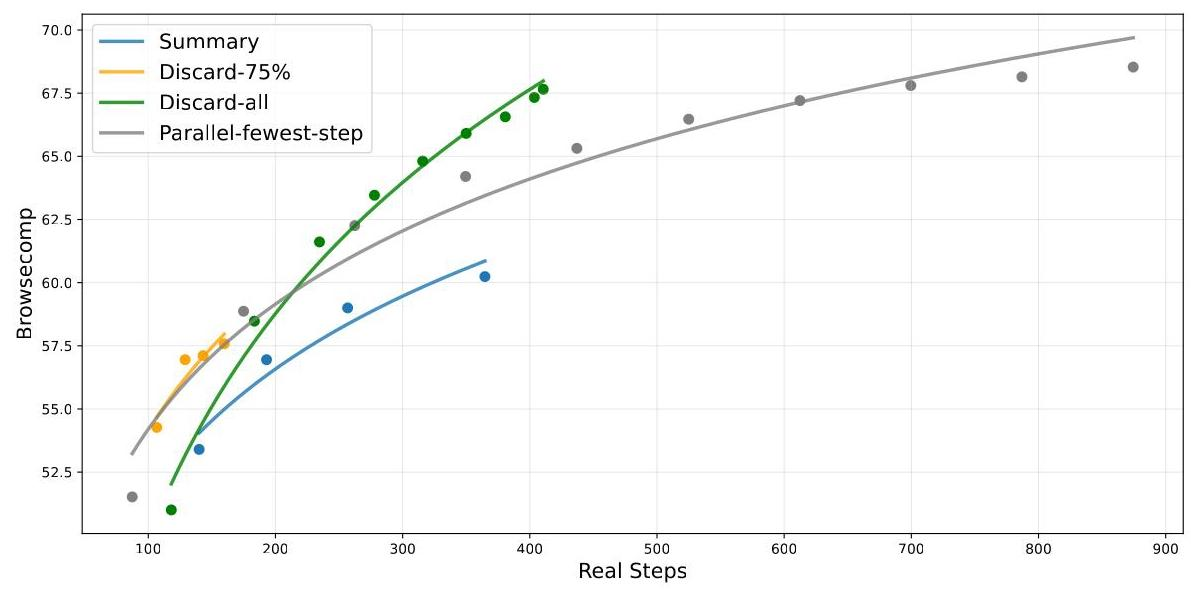
4.4 上下文管理的威力
针对搜索智能体经常超出128K上下文限制的问题,设计了三种策略:
- Summary:总结溢出轨迹后重启
- Discard-75%:丢弃前75%的工具调用历史
- Discard-all:重置上下文(类似Anthropic的new context工具)
结果显示,简单的Discard-all策略将BrowseComp性能从53.4%提升至67.6%,与并行扩展效果相当但步数更少。
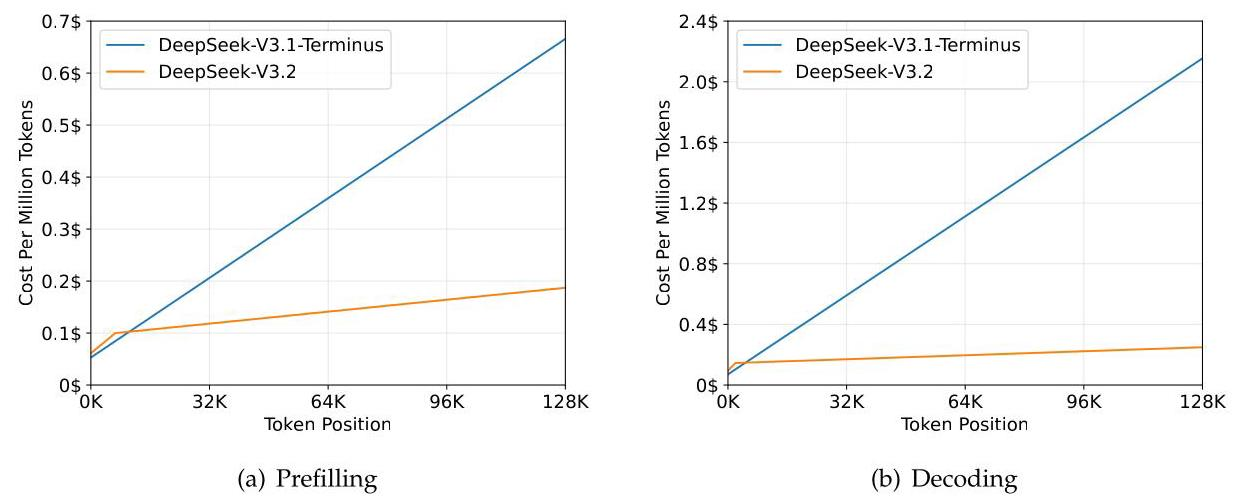
4.5 推理成本分析
DSA显著降低长文本推理成本。在H800集群上(租赁价格2美元/GPU小时),随着token位置增加,DeepSeek-V3.2的成本增长远低于V3.1-Terminus。
五、论文总结:开源追赶闭源的范式
DeepSeek-V3.2的成功表明:
- 架构效率是开源模型竞争力的关键:DSA证明稀疏注意力可以兼顾效率与性能
- 后训练计算预算值得大幅提升:10%的投入带来质的飞跃,仍有继续扩展空间
- 合成数据在智能体训练中潜力巨大:精心设计的合成任务可以有效提升泛化能力
- 测试时计算扩展不可忽视:上下文管理等策略可显著提升实际性能
这项工作不仅缩小了开源与闭源的差距,更重要的是为开源社区提供了一条可行的追赶路径:通过架构创新降低成本,通过增加后训练投入提升能力,通过数据合成突破瓶颈。DeepSeek-V3.2证明,开源大模型完全有可能在保持成本优势的同时,达到与顶尖闭源模型相媲美的性能水平。