文章目录
- 前言
- 一、为什么需要评价指标?
- 二、分类任务:从二分类到多分类的评价体系
-
- [2.1 二分类指标:准确率的陷阱与修正](#2.1 二分类指标:准确率的陷阱与修正)
-
- (1)准确率(Accuracy)
- (2)精确率(Precision,P)与召回率(Recall,R)
- (3)F1-Score:精确率与召回率的调和平均
- (4)ROC曲线与AUC:衡量模型的"区分能力"
- [(5)PR 曲线:类别不平衡下的"放大镜"](#(5)PR 曲线:类别不平衡下的“放大镜”)
- [2.2 多分类指标:宏平均、微平均与加权平均](#2.2 多分类指标:宏平均、微平均与加权平均)
-
- [(1)宏平均(Macro Average)](#(1)宏平均(Macro Average))
- [(2)微平均(Micro Average)](#(2)微平均(Micro Average))
- [(3)加权平均(Weighted Average)](#(3)加权平均(Weighted Average))
- 三、回归任务:预测值与真实值的"距离"度量
-
- [3.1 均方误差(MSE,Mean Squared Error)](#3.1 均方误差(MSE,Mean Squared Error))
- [3.2 平均绝对误差(MAE,Mean Absolute Error)](#3.2 平均绝对误差(MAE,Mean Absolute Error))
- [3.3 R²分数(R-Squared)](#3.3 R²分数(R-Squared))
- 四、目标检测:定位与分类的双重考验
-
- [4.1 交并比(IoU,Intersection over Union)](#4.1 交并比(IoU,Intersection over Union))
- [4.2 平均精度(AP,Average Precision)与mAP(Mean AP)](#4.2 平均精度(AP,Average Precision)与mAP(Mean AP))
-
- (1)单类别AP
- [(2)mAP(Mean Average Precision)](#(2)mAP(Mean Average Precision))
- 五、语义分割:像素级的"覆盖"与"准确"
-
- [5.1 交并比(IoU,像素级)](#5.1 交并比(IoU,像素级))
- [5.2 Dice系数(Dice Coefficient)](#5.2 Dice系数(Dice Coefficient))
- 六、生成任务:质量与多样性的平衡
-
- [6.1 Inception Score(IS)](#6.1 Inception Score(IS))
- [6.2 弗雷歇Inception距离(FID,Frechet Inception Distance)](#6.2 弗雷歇Inception距离(FID,Frechet Inception Distance))
- 七、指标选择的"黄金法则"
- 总结
前言
大多数同学在训练完一个模型之后就以为自己已经学会了这一项技能。实际上,在机器学习项目中,模型训练完成≠任务结束------如何判断模型是否"好用"?评价指标就成了最关键的"标尺"。它不仅能回答"模型准不准",更能帮我们定位问题(如过拟合、类别不平衡)、指导调优方向(如调整阈值、优化损失函数)。
本文将从任务类型出发,系统拆解分类、回归、目标检测、语义分割、生成任务等主流场景的常见评价指标,深入讲解原理、适用场景及避坑指南,助你彻底掌握"如何科学评估模型"。
一、为什么需要评价指标?
模型的核心目标是泛化能力------对未见过的数据做出正确预测。但"正确"是一个模糊概念,必须用具体指标量化。例如:
- 医疗诊断模型:"漏诊率"比"整体准确率"更关键;
- 推荐系统:"精确率"(推荐的相关性)比"召回率"(覆盖的数量)更重要;
- 目标检测:"定位误差"(边界框偏移)和"分类置信度"需同时考量。
评价指标的本质,是将模型的"能力"转化为可比较的数值,帮助我们:
- 对比不同模型(如ResNet vs. ViT的分类性能);
- 分析模型缺陷(如是否存在类别偏见);
- 调优超参数(如调整分类阈值平衡精确率与召回率)。
二、分类任务:从二分类到多分类的评价体系
分类是机器学习最基础的任务,根据类别数量可分为二分类 和多分类(含多标签分类)。其核心是衡量"预测类别与真实类别的匹配程度"。
2.1 二分类指标:准确率的陷阱与修正
(1)准确率(Accuracy)
-
原理 :正确预测的样本数占总样本数的比例。
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN其中,TP(真正例):正类预测为正类;TN(真负例):负类预测为负类;FP(假正例):负类预测为正类;FN(假负例):正类预测为负类。
-
陷阱:当类别高度不平衡时(如正类占1%),模型全猜负类也能得到99%的准确率,完全失效!
(2)精确率(Precision,P)与召回率(Recall,R)
-
精确率 :预测为正类的样本中,实际是正类的比例("查准率")。
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP + FP} Precision=TP+FPTP
场景:垃圾邮件过滤(避免误判正常邮件为垃圾邮件)。 -
召回率 :实际正类样本中,被正确预测的比例("查全率")。
R e c a l l = T P T P + F N Recall = \frac{TP}{TP + FN} Recall=TP+FNTP
场景:癌症筛查(避免漏诊阳性病例)。
(3)F1-Score:精确率与召回率的调和平均
- 原理 :平衡精确率和召回率,避免单一指标的极端化。
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall
适用:需要同时关注查准和查全的场景(如信息检索)。
(4)ROC曲线与AUC:衡量模型的"区分能力"
-
ROC曲线:以假正率(FPR = FP/(FP+TN))为横轴,真正率(TPR = Recall)为纵轴,反映不同分类阈值下的性能。
-
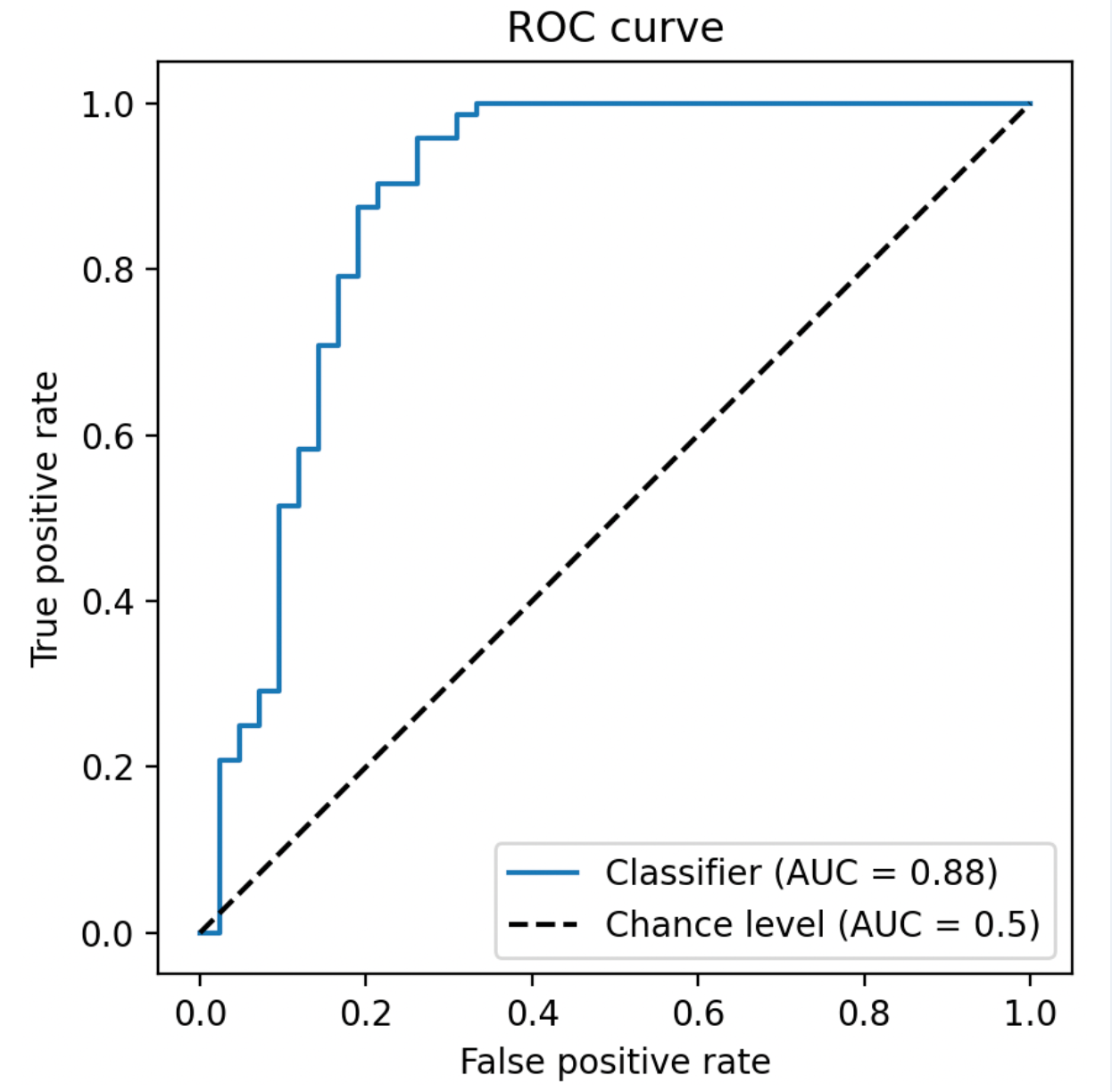
-
AUC(Area Under Curve) :ROC曲线下的面积,范围0,1。AUC=1表示完美区分,AUC=0.5表示随机猜测。
优势:不依赖具体阈值,综合评估模型对正负类的区分能力;对类别不平衡不敏感。
(5)PR 曲线:类别不平衡下的"放大镜"
-
横纵坐标:横轴 -- Recall(召回率,TPR),纵轴 -- Precision(精确率)。
-
绘制方式:
将模型输出的置信度从高到低排序,每取一个阈值计算一对 (Recall, Precision),连线即得 PR 曲线。
-
关键数值 -- AP(Average Precision):
PR 曲线下面积,等价于"不同召回率下精确率的平均值",越接近 1 表示模型越能把正类排在前面。
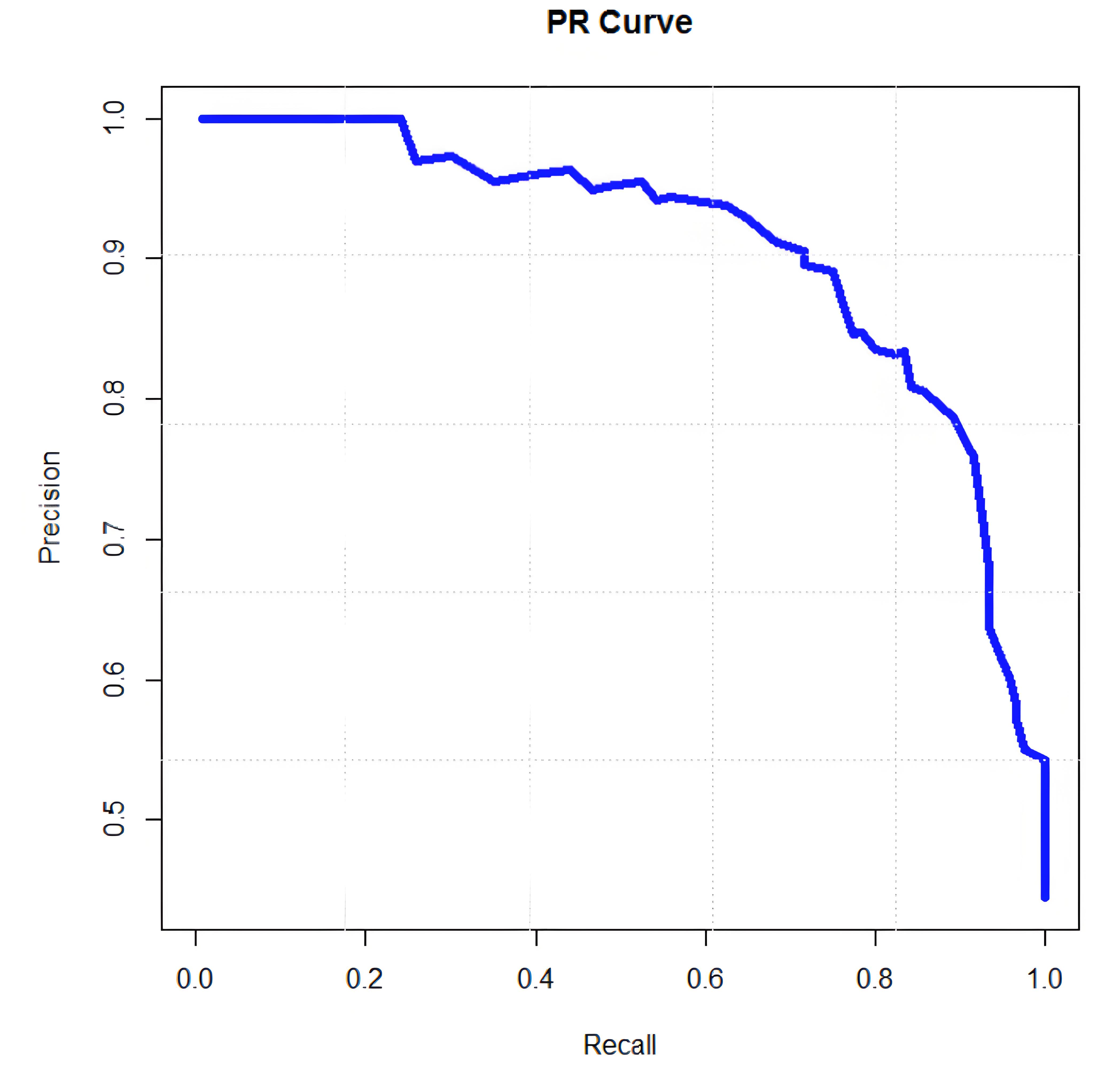
-
与 ROC 的区别:ROC 用 FPR 做横轴,对负例数量不敏感;PR 曲线则把"负例规模"从分母中剔除,因此在正负例悬殊(如 1:100)时,PR 曲线会把模型的轻微下滑放大,更容易暴露过拟合或阈值设置不当。
-
使用场景:
正负样本比例 ≥ 1:10 的稀疏正类任务(欺诈检测、罕见病筛查);
需要"把正类尽可能排在前面"的排序场景(信息检索、推荐系统)。
-
速读技巧:
曲线整体越靠近右上角越好;若曲线在 Recall 0.8 附近 Precision 骤降,通常说明模型在高置信段存在大量 FP,需要回溯特征或调高阈值。
2.2 多分类指标:宏平均、微平均与加权平均
多分类任务中,需将二分类指标扩展到多个类别,常见方法:
(1)宏平均(Macro Average)
- 对每个类别单独计算指标(如精确率),取算术平均。
- 特点:平等对待每个类别,小类别的影响与大类别相同。
(2)微平均(Micro Average)
- 先汇总所有类别的TP、FP、FN,再计算全局指标。
- 特点:大类别主导结果,反映整体性能。
(3)加权平均(Weighted Average)
- 按类别样本数加权计算指标,平衡类别不平衡的影响。
三、回归任务:预测值与真实值的"距离"度量
回归任务目标是预测连续值(如房价、温度),核心是衡量预测值与真实值的偏差。
3.1 均方误差(MSE,Mean Squared Error)
- 原理 :预测值与真实值差的平方的平均。
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2 - 特点:对异常值敏感(平方放大误差),梯度随误差增大而增大,适合优化。
3.2 平均绝对误差(MAE,Mean Absolute Error)
- 原理 :预测值与真实值绝对差的平均。
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n} \sum_{i=1}^n |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣ - 特点:对异常值鲁棒(绝对差不放大误差),但在0点不可导,优化难度略高。
3.3 R²分数(R-Squared)
- 原理 :模型解释的方差占总方差的比例。
R 2 = 1 − ∑ ( y i − y ^ i ) 2 ∑ ( y i − y ˉ ) 2 R^2 = 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2} R2=1−∑(yi−yˉ)2∑(yi−y^i)2
其中, y ˉ \bar{y} yˉ是真实值的均值。 - 解读:R²=1表示模型完美预测;R²=0表示模型仅能预测均值;R²<0表示模型比均值更差。
四、目标检测:定位与分类的双重考验
目标检测需同时完成"定位"(边界框位置)和"分类"(物体类别),评价指标需兼顾两者。
4.1 交并比(IoU,Intersection over Union)
- 原理 :预测边界框与真实边界框的交集面积,除以并集面积。
I o U = ∣ B p r e d ∩ B g t ∣ ∣ B p r e d ∪ B g t ∣ IoU = \frac{|B_{pred} \cap B_{gt}|}{|B_{pred} \cup B_{gt}|} IoU=∣Bpred∪Bgt∣∣Bpred∩Bgt∣ - 作用:衡量定位精度,常用阈值(如0.5)判断预测是否有效。
4.2 平均精度(AP,Average Precision)与mAP(Mean AP)
(1)单类别AP
- 对某一类别,按置信度排序所有预测框,计算不同召回率(Recall)下的精确率(Precision),绘制PR曲线,AP为PR曲线下的面积。
- 意义:综合评估该类别的定位与分类性能。
(2)mAP(Mean Average Precision)
- 对所有类别的AP取平均,是目标检测最核心的指标(如COCO数据集的mAP@0.5:0.95)。
- 变体 :
- mAP@0.5:IoU阈值为0.5时的mAP(类似PASCAL VOC标准);
- mAP@0.5:0.95:在IoU从0.5到0.95的10个阈值下分别计算mAP,再取平均(COCO更严格的标准)。
五、语义分割:像素级的"覆盖"与"准确"
语义分割需为每个像素分配类别,核心是衡量预测分割区域与真实区域的匹配程度。
5.1 交并比(IoU,像素级)
- 原理 :对每个类别,计算预测区域与真实区域的交集像素数,除以并集像素数。
I o U c = ∣ S c p r e d ∩ S c g t ∣ ∣ S c p r e d ∪ S c g t ∣ IoU_c = \frac{|S_c^{pred} \cap S_c^{gt}|}{|S_c^{pred} \cup S_c^{gt}|} IoUc=∣Scpred∪Scgt∣∣Scpred∩Scgt∣ - mIoU(Mean IoU):对所有类别的IoU取平均,是分割任务的核心指标。
5.2 Dice系数(Dice Coefficient)
- 原理 :2倍交集像素数,除以预测区域与真实区域的像素总数。
D i c e c = 2 ∣ S c p r e d ∩ S c g t ∣ ∣ S c p r e d ∣ + ∣ S c g t ∣ Dice_c = \frac{2|S_c^{pred} \cap S_c^{gt}|}{|S_c^{pred}| + |S_c^{gt}|} Dicec=∣Scpred∣+∣Scgt∣2∣Scpred∩Scgt∣ - 特点:与IoU正相关(Dice = 2IoU/(1+IoU)),但对分割区域的覆盖更敏感(尤其小目标)。
六、生成任务:质量与多样性的平衡
生成模型(如GAN、VAE)需评估生成样本的"真实性"(接近真实数据)和"多样性"(不重复)。
6.1 Inception Score(IS)
- 原理:用预训练的Inception模型计算生成样本的类别分布(清晰度)和与真实数据分布的KL散度(多样性)。
- 局限:无法检测模式崩溃(生成样本单一),且依赖Inception模型的特征。
6.2 弗雷歇Inception距离(FID,Frechet Inception Distance)
- 原理:计算生成样本与真实样本在Inception模型特征空间的弗雷歇距离(衡量两个分布的相似性)。
- 优势:比IS更可靠,广泛用于评估GAN的生成质量。
七、指标选择的"黄金法则"
- 任务导向:分类看精确率/召回率/F1,回归看MSE/MAE/R²,检测看mAP,分割看mIoU/Dice。
- 业务需求:医疗诊断关注召回率(减少漏诊),广告推荐关注精确率(减少误推)。
- 避免单一指标:结合多个指标(如分类同时看准确率、F1、AUC),全面诊断模型缺陷。
- 警惕陷阱:类别不平衡时不用准确率,小目标检测时关注mAP@0.5:0.95而非仅mAP@0.5。
总结
评价指标不是冰冷的数字,而是模型能力的"翻译官"。理解每个指标的原理和适用场景,才能在模型调优时"有的放矢"。下次训练完模型,不妨多问一句:"这个指标能真实反映我的需求吗?"------毕竟,好的模型,是为解决问题而生,而非为刷高指标而存在。