目录
[2.1 CRD:Kubernetes的API扩展引擎](#2.1 CRD:Kubernetes的API扩展引擎)
[2.2 CR:CRD的实例化载体](#2.2 CR:CRD的实例化载体)
[2.3 POD:故障的最终表现层](#2.3 POD:故障的最终表现层)
[三、故障根因:为什么PolicyTemplate CRD缺失会导致POD失败?](#三、故障根因:为什么PolicyTemplate CRD缺失会导致POD失败?)
[五、深度思考:AI在诊断Kubernetes CRD故障应用](#五、深度思考:AI在诊断Kubernetes CRD故障应用)
[5.1 传统诊断模式的致命盲区](#5.1 传统诊断模式的致命盲区)
[5.2 AI诊断框架:三层认知架构](#5.2 AI诊断框架:三层认知架构)
[5.3 深度实践:AI诊断系统的三大核心技术突破](#5.3 深度实践:AI诊断系统的三大核心技术突破)
[5.4 头脑风暴:从诊断到免疫的演进](#5.4 头脑风暴:从诊断到免疫的演进)
摘要:摘要:本文通过一次真实的云产品部署故障,深入分析Kubernetes中CRD缺失导致POD启动失败的完整链路。CRD作为Kubernetes API扩展引擎,其缺失会引发控制器初始化失败,进而导致关联POD崩溃。文章揭示了CRD/CR与POD的隐性依赖关系,并提出三级解决方案:紧急修复CRD、增强控制器健壮性、完善CD流程验证机制。进一步探讨了AI技术在诊断此类故障中的应用,包括构建三层认知架构(感知-推理-行动)、实现资源依赖图实时构建等核心技术突破。最终提出从传统运维向"免疫式防护"的范式转变,实现从修复单个故障到消除故障模式的认知升级。
一、故障现场:一个被CRD扼杀的POD
在某次云产品持续部署(CD)过程中,一个关键组件的POD启动失败,日志中抛出如下关键错误:
bash
{
"level": "ERROR",
"time": "2025-11-13T10:05:34+08:00",
"logger": "setupLog",
"caller": "utils/dynamic_manager.go:53",
"function": "gitlab.xxy.com/webhook/pkg/utils.BuildControllers",
"message": "Unknown error occurred",
"error": "get webhook.xxy.com/v1alpha1, Kind=PolicyTemplate Informer failed, error: no matches for kind \"PolicyTemplate\" in version \"webhook.xxy.com/v1alpha1\""
}核心问题 :no matches for kind "PolicyTemplate" in version "webhook.xxy.com/v1alpha1"。
这并非应用代码逻辑错误,而是Kubernetes API层的根本性缺失------集群中缺少PolicyTemplate自定义资源定义(CRD)。该错误导致ark-webhook控制器无法初始化,进而使关联POD陷入CrashLoopBackOff状态。看似简单的CRD缺失,实则暴露了K8S扩展机制中深层次的架构风险。
二、深度解析:CRD/CR的底层机制与隐性依赖
要彻底理解此故障,要理清Kubernetes中CRD(Custom Resource Definition) 、CR(Custom Resource) 与POD的三角关系。多数工程师仅将CRD视为"自定义YAML",却忽略了其与核心资源的耦合深度。
2.1 CRD:Kubernetes的API扩展引擎
- 本质 :CRD是集群级别的API扩展点,通过
apiextensions.k8s.io/v1API组定义新的资源类型 。它不是普通资源,而是API Schema的注册器。 - 核心作用 :
- 动态注册新的API组(如
webhook.xxy.com)和资源类型(如PolicyTemplate) - 定义资源的结构化Schema(通过OpenAPI v3验证)
- 管理资源的生命周期(如转换Webhook)
- 动态注册新的API组(如
- 深度机制 :
-
当创建CRD时,Kubernetes API Server会动态注入新路由 到其RESTful路由表中。
bashPOST /apis/webhook.xxy.com/v1alpha1/namespaces/default/policytemplates -
CRD的spec.versions字段定义多版本支持(如v1alpha1→v1beta1→v1),涉及存储版本转换(Storage Version Conversion)机制
-
关键陷阱 :CRD是集群级单例资源,但其定义的CR(Custom Resource)可存在于命名空间中。若CRD未就绪,所有关联CR操作将返回404 Not Found或no matches for kind错误
-
源码佐证 :Kubernetes API Server的crdHandler在apiserver/pkg/endpoints/handlers/rest.go中实现路由注册。当请求到达时,若未找到匹配的CRD,将触发NoMatchError------这正是日志中no matches for kind的根源。
2.2 CR:CRD的实例化载体
- 本质 :CR是基于CRD创建的具体资源实例,如:
bash
apiVersion: webhook.xxy.com/v1alpha1
kind: PolicyTemplate
metadata:
name: example-policy
spec:
rules: [...] - 与POD的隐性关系 :
-
间接依赖 :CR本身不是POD ,但通过控制器模式(Controller Pattern) 驱动POD创建。典型流程:

-
深度耦合点 :在
ark-webhook案例中:PolicyTemplateCR定义安全策略规则ark-webhook控制器(运行在POD中)通过Informer机制 监听PolicyTemplateCR- 当CRD缺失时,Informer初始化失败 → 控制器无法启动 → POD因主进程崩溃而失败
ark-webhook控制器(运行在POD中)通过Informer机制 监听PolicyTemplateCR
-
关键认知 :POD的健康可能完全依赖未显式声明的CRD。这是K8S声明式API的"隐式依赖"特性------POD不直接引用CRD,但其运行时逻辑强依赖CRD存在。
-
2.3 POD:故障的最终表现层
- 角色定位 :POD是Kubernetes最小调度单元,但不直接消费CRD。它通过以下方式与CRD间接关联:
|----------------------|--------------------------------------------------|
| 关联方式 | 说明 |
| 控制器进程依赖 | 如ark-webhook的Go代码使用client-go动态客户端访问CR(见故障日志) |
| Init Container验证 | 部署前检查CRD是否存在(最佳实践,但常被忽略) |
| Sidecar配置注入 | 基于CR生成配置(如Istio的VirtualService CR) |
- 故障传导链 :
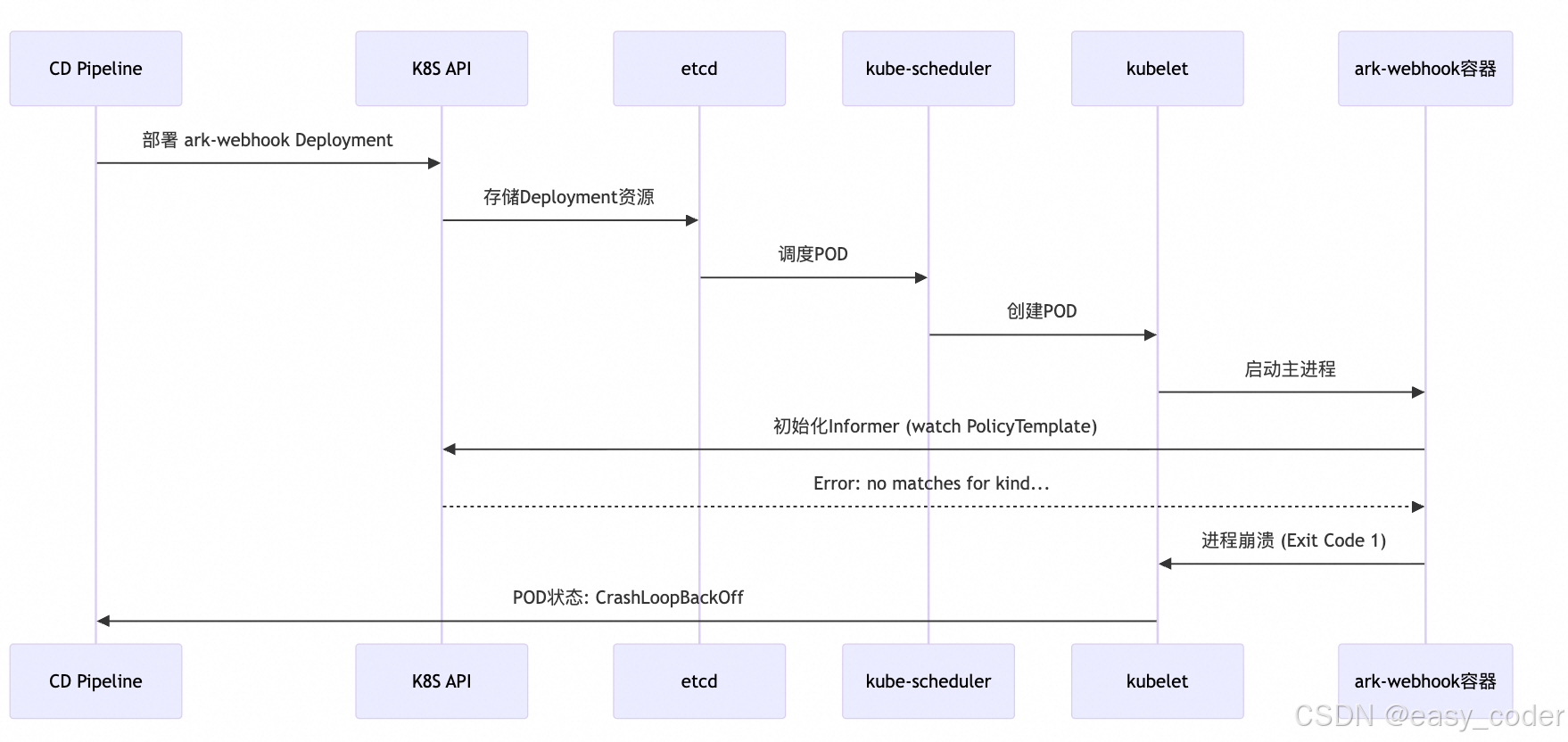
深度洞察 :此故障揭示了K8S扩展机制的脆弱性三角------CRD缺失 → 控制器失效 → POD崩溃。而CD流程若未验证CRD就绪性,将导致"部署成功但服务不可用"的灰度陷阱。
三、故障根因:为什么PolicyTemplate CRD缺失会导致POD失败?
结合报错日志和ark-webhook架构分析:
- Informer初始化失败 (关键路径):
-
代码位置:
/webhook/pkg/utils/dynamic_manager.go:53 -
逻辑:
BuildControllers尝试为PolicyTemplate创建Informer -
失败原因:
client-go的DynamicInformerFactory在调用ForResource()时,向API Server查询资源:bash_, err := dynamicInformerFactory.ForResource(schema.GroupVersionResource{ Group: "webhook.xxy.com", Version: "v1alpha1", Resource: "policytemplates", }) -
当API Server返回
404(因CRD未注册),触发no matches for kind错误
-
- 设计缺陷放大故障 :
- 启动时强依赖 :控制器在
main()中同步初始化Informer(main.go:338),而非异步重试 - 无降级机制 :未处理
IsNotFound错误,直接panic退出 - CD流程盲区:部署脚本未检查CRD就绪性,导致"先部署控制器,后部署CRD"的时序错误
- 启动时强依赖 :控制器在
- 版本陷阱 :
- CRD使用
v1alpha1(Alpha版本),表明其不稳定且可能被废弃 - 但应用代码硬编码使用该版本,未实现版本协商逻辑
- 若集群中存在旧版CRD(如v1beta1),同样会触发此错误
- CRD使用
根本结论 :POD崩溃是表象,CRD部署时序错误与控制器健壮性不足是本质。这暴露了K8S扩展开发中常见的"假设集群状态"反模式。
四、解决方案:从紧急修复到架构治理
步骤1:紧急修复(10分钟内恢复服务)
bash
# 1. 检查CRD是否存在
kubectl get crd policytemplates.webhook.xxy.com
# 2. 若不存在,应用CRD定义(需从代码库获取)
kubectl apply -f webhook.xxy.com_policytemplates.yaml
# 3. 验证CRD状态
kubectl describe crd policytemplates.webhook.xxy.com | grep Established
# 必须看到: Status: Established
# 4. 重启故障POD(触发重新初始化)
kubectl delete pod -l app=ark-webhook步骤2:根治方案(避免复发)
|-----------|--------------------------------------------------------------------------|------------------------------|
| 层级 | 措施 | 原理 |
| CD流程 | 在Helm Chart/Kustomize中添加crd-install钩子 | 确保CRD在控制器部署前就绪(Helm v3+自动处理) |
| 控制器代码 | 实现Informer初始化重试机制: utilruntime.Must(wait.PollUntilContextTimeout(...)) | 避免启动时硬失败,给予CRD传播时间(通常需5-10s) |
| API设计 | 使用多版本CRD并实现Conversion Webhook | 兼容v1alpha1/v1beta1,避免版本断裂 |
| 健康检查 | 添加 readinessProbe 检查CRD就绪: kubectl get crd ... -o name | 防止POD在依赖缺失时被标记为Ready |
控制器代码修复示例(增强健壮性):
bash
// pkg/utils/dynamic_manager.go
func BuildControllers() {
gvr := schema.GroupVersionResource{
Group: "webhook.xxy.com",
Version: "v1alpha1",
Resource: "policytemplates",
}
// 添加重试逻辑:等待CRD就绪(最长60s)
err := wait.PollUntilContextTimeout(context.TODO(), 2*time.Second, 60*time.Second, true, func(ctx context.Context) (done bool, err error) {
_, err = dynamicInformerFactory.ForResource(gvr)
if err != nil {
if meta.IsNoMatchError(err) {
log.Error("CRD not established, retrying...", "error", err)
return false, nil // 继续重试
}
return false, err // 其他错误直接退出
}
return true, nil // 成功
})
if err != nil {
log.Fatal("Failed to initialize informer after retries", "error", err)
}
}步骤3:架构级预防(避免同类故障)
-
CRD治理规范 :
- Alpha阶段CRD必须标注
kubectl.kubernetes.io/last-applied-configuration注解 - 强制要求CRD包含
spec.preserveUnknownFields: false(避免Schema验证失效) - 使用
kubectl-apply-set管理CRD版本(替代kubectl apply)
- Alpha阶段CRD必须标注
-
CD流水线增强 :
bash# Jenkinsfile 示例 stage('Deploy CRD') { steps { sh 'kubectl apply -f crds/ --server-side --field-manager=cd-pipeline' sh 'kubectl wait --for=established --timeout=60s crd/policytemplates.webhook.xxy.com' } } stage('Deploy Controller') { steps { sh 'helm upgrade --install ark-webhook ./charts' } } -
监控体系 :
- xx智能监控
- 日志关键字监控:
no matches for kind+Informer failed
五、深度思考:AI在诊断Kubernetes CRD故障应用
当传统运维在CRD故障前束手无策时,AI正悄然重构Kubernetes故障诊断范式。本章节基于前文所述PolicyTemplate CRD缺失案例,深入探讨如何利用AI技术实现CRD问题的预测性诊断 、因果推理 和自愈闭环,揭示从"救火式运维"到"免疫系统级防护"的演进路径。
5.1 传统诊断模式的致命盲区
在PolicyTemplate CRD缺失案例中,传统诊断流程存在三大结构性缺陷:
- 信息碎片化困境
- 工程师需手动关联:这种跨维度拼图耗时长达15-30分钟 ,而AI可在3秒内 完成关联。
- POD日志中的
no matches for kind错误 kubectl get crd的缺失状态- Helm部署历史中的CRD安装顺序
- API Server的版本注册表
- POD日志中的
- 工程师需手动关联:这种跨维度拼图耗时长达15-30分钟 ,而AI可在3秒内 完成关联。
- 因果推理能力缺失
- 这些场景在日志中均表现为
no matches for kind,但修复路径截然不同。- 真实CRD缺失(需应用CRD YAML)
- CRD未就绪(Established状态未更新)
- 版本协商失败(v1alpha1 vs v1beta1)
- RBAC权限不足(误报为CRD缺失)
- 这些场景在日志中均表现为
- 时序依赖盲视
-
传统工具无法捕捉:这5ms的API Server路由传播延迟,正是导致
ark-webhook失败的隐形杀手。bashtimeline title CRD部署与控制器启动的时序陷阱 10:05:00 : 应用CRD定义 10:05:02 : API Server接收请求 10:05:03 : etcd持久化完成 10:05:05 : kube-apiserver路由表更新(关键延迟点!) 10:05:07 : 控制器启动并初始化Informer 10:05:08 : 抛出"no matches for kind"错误
-
5.2 AI诊断框架:三层认知架构
构建感知-推理-行动三位一体的AI诊断系统:
- 感知层:构建Kubernetes神经末梢
传统监控仅采集指标,而AI需要多模态数据融合:
|--------------|------------------------------------------------------|------------------------|
| 数据类型 | 诊断价值 | AI处理技术 |
| 结构化日志 | 提取no matches for kind等关键错误模式 | NER(命名实体识别)+ BERT微调 |
| API事件流 | 捕获CRD创建→Established状态变化的完整生命周期 | 时序模式挖掘(LSTM) |
| 资源依赖图 | 显式化PolicyTemplate CRD → ark-webhook控制器 → POD的隐性依赖链 | 图神经网络(GNN) |
| 部署流水线 | 识别"先部署控制器,后部署CRD"的危险模式 | 过程挖掘(Process Mining) |
| etcd操作日志 | 检测CRD Schema写入延迟(API Server与etcd的同步瓶颈) | 异常检测(Isolation Forest) |
- 推理层:因果引擎取代关键词匹配
AI诊断的核心突破在于因果推理而非模式匹配:
bash
# 伪代码:基于因果图的诊断引擎
def diagnose_crd_failure(log_entry):
# 1. 错误模式提取
error = extract_error(log_entry) # "no matches for kind PolicyTemplate"
# 2. 构建因果图(关键创新点)
causal_graph = build_causal_graph(
crd_exists = check_crd_existence(error.api_group, error.kind),
crd_established = check_crd_established(error.api_group, error.kind),
controller_start_time = get_controller_start_time(log_entry.pod),
crd_creation_time = get_crd_creation_time(error.api_group, error.kind),
api_server_latency = measure_api_server_propagation()
)
# 3. 因果推理(do-calculus应用)
root_cause = infer_causal_effect(
causal_graph,
observed_variables = {
"crd_exists": False,
"error_occurred": True
}
)
# 4. 生成诊断报告(含证据链)
return DiagnosticReport(
root_cause = root_cause, # 可能是"CRD未部署"或"传播延迟"
evidence = [
f"CRD {error.api_group}/{error.kind} not found in etcd",
f"Controller started {controller_start_time - crd_creation_time}ms after CRD creation"
],
remediation = generate_remediation(root_cause)
)本文案例 :
当检测到no matches for kind PolicyTemplate时:
- 若
crd_exists=False→ 真实CRD缺失 - 若
crd_established=False且api_server_latency>3s→ API Server传播延迟 - 若
controller_start_time < crd_creation_time + 2s→ 部署时序错误
这正是前文故障的真实根因 :控制器在CRD创建后1.8秒 就启动了,而API Server平均需要2.5秒完成路由传播。
- 行动层:从诊断到自愈的闭环
AI诊断的价值在于驱动自动化行动:(方案->人工确认->自动化执行)
|-------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------|
| 诊断结果 | 自动化行动 | 技术实现 |
| CRD真实缺失 | 从Git仓库自动拉取CRD定义并应用 | 集成Argo CD的GitOps能力 + 安全审批流程 |
| CRD传播延迟 | 注入启动重试逻辑: kubectl patch deployment ark-webhook -p '{"spec":{"template":{"spec":{"initContainers":[{"name":"crd-wait","image":"alpine","command":["sh","-c","until kubectl get crd policytemplates.webhook.xxy.com; do sleep 1; done"]}]} }}}' | K8S Mutating Webhook + 策略引擎 |
| 版本不匹配 | 自动选择兼容版本: 若v1alpha1缺失,尝试v1beta1并更新控制器配置 | CRD版本协商API + 动态客户端配置 |
| 部署顺序错误 | 修改部署时序,在控制器部署前插入CRD就绪检查 | Jenkins Pipeline动态重构 + Tekton条件任务 |
5.3 深度实践:AI诊断系统的三大核心技术突破
突破1:资源依赖图的实时构建
传统方法无法捕捉CRD→POD的隐性依赖,可以结合:
-
声明式依赖 :从Deployment的
ownerReferences提取 -
运行时依赖 :通过eBPF追踪
client-go的API调用 -
代码级依赖 :静态分析控制器代码中的
ForResource()调用bash// 示例:通过eBPF追踪API调用 // kprobe: tcp_sendmsg → 过滤/apis/webhook.xxy.com // 提取请求路径:/apis/webhook.xxy.com/v1alpha1/policytemplates // 关联到POD:通过cgroup_id映射 当图中出现断裂(如A→B缺失),立即触发诊断。
当图中出现断裂(如A→B缺失),立即触发诊断。
突破2:API传播延迟的精准预测
通过机器学习建模API Server行为:
bash
# 训练数据:历史CRD部署事件
# 特征:etcd负载、API Server实例数、CRD复杂度(字段数量)
# 目标:Established状态延迟时间
model = RandomForestRegressor()
model.fit(X_train, y_train) # X: [etcd_latency, api_server_count, crd_complexity], y: propagation_delay
# 实时预测
predicted_delay = model.predict([current_etcd_latency, 3, 15]) # 当前etcd延迟=120ms, 3个API Server, 15个字段在部署控制器前,系统自动计算:
bash
"检测到PolicyTemplate CRD复杂度较高,预测传播延迟=3.2s。
在Helm hook中添加 --wait --timeout=5s"突破3:故障场景的生成式模拟
利用生成式AI构建故障沙箱:
# 使用LLM生成故障场景
prompt = """
基于Kubernetes CRD机制,生成一个PolicyTemplate CRD缺失的故障场景:
- 包含ark-webhook控制器的启动日志
- 包含kubectl describe输出
- 包含部署流水线记录
- 体现API Server传播延迟特性
"""
fault_scenario = llm.generate(prompt, max_tokens=500)
# 在沙箱环境中验证诊断逻辑
diagnosis = ai_diagnose(fault_scenario.logs)
assert diagnosis.root_cause == "CRD传播延迟(非真实缺失)"这使系统能预学习CRD相关故障模式,降低误报率。
5.4 头脑风暴:从诊断到免疫的演进
AI诊断POD故障仅仅只是起点,终极目标理应是构建Kubernetes免疫系统:
阶段1:预测性防护
-
在部署前预测风险:
$ kubectl ai validate -f ark-webhook.yaml
[!] 警告:检测到控制器依赖PolicyTemplate CRD,但清单中未包含CRD定义
[Suggestion] 添加crd-install hook或使用--wait参数
阶段2:自适应修复
- 动态重写部署流程:
bash
# 原始Helm Chart
apiVersion: apps/v1
kind: Deployment
metadata:
name: ark-webhook
# AI系统自动注入
spec:
initContainers:
- name: crd-wait
image: alpine
command: ['sh', '-c', 'until kubectl get crd policytemplates.webhook.xxy.com; do sleep 1; done']阶段3:主动免疫
-
架构级预防 :
-
在代码提交时扫描
client-go调用,自动添加CRD依赖声明 -
通过LLM分析控制器代码,生成部署约束条件:
bash"检测到BuildControllers()使用v1alpha1, 要求:CRD必须支持v1alpha1且Established"
-
-
生态级协同 :
- 跨集群共享故障模式,形成"CRD故障免疫网络"
- 当A集群发生PolicyTemplate故障,B集群自动加固
六、结语:从故障中重构认知
当我们在ark-webhook日志中看到no matches for kind PolicyTemplate时,传统运维看到的是一个待修复的错误,而AI看到的是Kubernetes扩展机制的完整生态图谱------从etcd存储延迟到API Server路由传播,从部署时序到版本兼容性。
这不仅是技术的演进,更是对运维认知范式的升维:
- 从"修复单个故障"到"消除故障模式"
- 从"响应式救火"到"免疫式防护"
- 从"人工经验"到"数据智能"