我们发布了 rwkv7_train_simplified.py ,演示 RWKV-7 "Goose" 架构的训练全过程,无需任何外部训练框架。
脚本将基于 2 层 RWKV-7 模型(仅 30860 个参数)训练"数字翻转 "任务:给定随机数字(例如168,以逗号结尾),模型输出其反转(例如861#以#结尾)。这个任务可测试模型的长距离建模能力。
整个训练脚本约 400 行代码:
- 训练环境与超参数设置
- 自定义 CUDA 算子 (WindBackstepping)
- RWKV 核心的 Time Mix 机制 (RWKV_Tmix_x070)
- 生成"数字翻转"训练数据的代码 (batch)
- RWKV 的 Channel Mix 模块 (FFN)
- RWKV 的模型结构定义 (MODEL)
- 训练代码 (优化器与反向传播)
- 模型效果评估
下面我们将对每个模块进行带注释的详细介绍。
1. 环境与超参数设置
Line 1 ~ 28负责训练环境与超参数设置,包括:
- 导入所有必需的库(如
torch,wandb,numpy等) - 设置全局随机种子(
set_seed_all(42))以确保实验的可复现性 - 定义整个脚本所需的核心超参数,例如词汇表大小 (
V)、嵌入维度 (C)、批次大小 (B)、序列长度 (T) 和学习率 (lr0,lr1)
python
import random, torch, os, math, time
import numpy as np
import wandb, datetime
from types import SimpleNamespace
import torch, random
from torch import nn
import torch.nn.functional as F
from torch.nn.utils import clip_grad_norm_
from torch.utils.cpp_extension import load
# 设置所有随机种子以确保可复现性
def set_seed_all(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
random.seed(seed)
np.random.seed(seed)
set_seed_all(42) # 使用固定种子 42
device = 'cuda' # 使用 GPU 训练
MyModule = torch.jit.ScriptModule
MyFunction = torch.jit.script_method
# 全局超参数
V = 12 # 词汇表大小:0-9 数字 + ,(逗号) + #(井号)
C = 32 # 嵌入维度 (n_embd) = 32 (非常小,仅用于演示)
B = 256 # 批次大小
T = 129 # 序列长度
steps = 10000 # 训练步数
lr0 = 4e-3 # 初始学习率
lr1 = 1e-6 # 最终学习率(余弦退火)
DIGIT_MAX = 60 # 任务特定参数:输入数字的最大位数2. 自定义 CUDA 算子
Line 51 ~ 65 (WindBackstepping) 是加速 RWKV-7 架构训练性能的 CUDA 核心代码:
- 动态编译和加载自定义的 C++/CUDA 算子源代码(
wkv7_cuda_fp32.cu) - 定义了
WindBackstepping类,一个自定义的torch.autograd.Function - 实现了 RWKV-7 高效的、分块的(chunked)并行前向传播,以及一个配套的自定义反向传播算法
RUN_CUDA_RWKV7g 是调用此 CUDA 核心的 Python 包装器,负责处理张量的形状(reshape)。
python
HEAD_SIZE = 16 # 每个头的维度。用于语言模型 (LM) 时应为 64
CHUNK_LEN = 16 # CUDA 处理的块长度
# 编译 CUDA 核心,定义了头大小、块长度、优化级别等
flags = ['-res-usage', f'-D_C_={HEAD_SIZE}', f"-D_CHUNK_LEN_={CHUNK_LEN}", "--use_fast_math", "-O3", "-Xptxas -O3", "--extra-device-vectorization"]
# 加载 cuda 目录的算子,为简化,本文的训练只支持 fp32 精度
load(name="wind_backstepping", sources=[f'cuda/wkv7_cuda_fp32.cu', 'cuda/wkv7_op_fp32.cpp'], is_python_module=False, verbose=False, extra_cuda_cflags=flags)
# 自定义的 PyTorch 自动求导函数
class WindBackstepping(torch.autograd.Function):
@staticmethod
def forward(ctx, w,q,k,v,z,b): # ctx 用于保存反向传播所需的数据
B,T,H,C = w.shape # 获取维度
assert T%CHUNK_LEN == 0 # 输入长度必须是 CHUNK_LEN 的倍数
assert all(i.dtype==torch.float32 for i in [w,q,k,v,z,b]) # 为简化,本文的训练只支持 fp32 精度
assert all(i.is_contiguous() for i in [w,q,k,v,z,b]) # 连续内存
y = torch.empty_like(v)
s = torch.empty(B,H,T//CHUNK_LEN,C,C, dtype=torch.float32,device=w.device)
sa = torch.empty(B,T,H,C, dtype=torch.float32,device=w.device)
torch.ops.wind_backstepping.forward(w,q,k,v,z,b, y,s,sa)# 调用编译好的 CUDA 前向核心
ctx.save_for_backward(w,q,k,v,z,b,s,sa) # 保存反向传播所需的张量
return y
@staticmethod
def backward(ctx, dy): # dy 是 y 的梯度
assert all(i.dtype==torch.float32 for i in [dy])
assert all(i.is_contiguous() for i in [dy])
w,q,k,v,z,b,s,sa = ctx.saved_tensors # 取出前向传播中保存的张量
dw,dq,dk,dv,dz,db = [torch.empty_like(x) for x in [w,q,k,v,z,b]] # 为输入的梯度分配空间
torch.ops.wind_backstepping.backward(w,q,k,v,z,b, dy,s,sa, dw,dq,dk,dv,dz,db) # 调用编译好的 CUDA 反向核心
return dw,dq,dk,dv,dz,db # 返回所有输入的梯度
# 包装函数,用于处理各种形状
def RUN_CUDA_RWKV7g(q,w,k,v,a,b):
B,T,HC = q.shape
q,w,k,v,a,b = [i.view(B,T,HC//16,16) for i in [q,w,k,v,a,b]] # 匹配 16 head size
# q,w,k,v,a,b = [i.view(B,T,HC//64,64) for i in [q,w,k,v,a,b]] # 训练语言模型用的 64 head size
return WindBackstepping.apply(w,q,k,v,a,b).view(B,T,HC)3. RWKV-7 时间混合模块
Line 66 ~ 180 (RWKV_Tmix_x070)是 RWKV7 的核心模块 "Tmix" (Time-mixing),负责在时间维度上混合信息:
- 使用线性复杂度的递归状态更新,替代 Transformer 中二次复杂度的自注意力计算
- 引入时间混合(Time-Mixing)机制,通过可学习的插值参数混合当前和历史信息
下图是 RWKV7 论文(arxiv.org/pdf/2503.14... Time Mix(循环模式)结构,
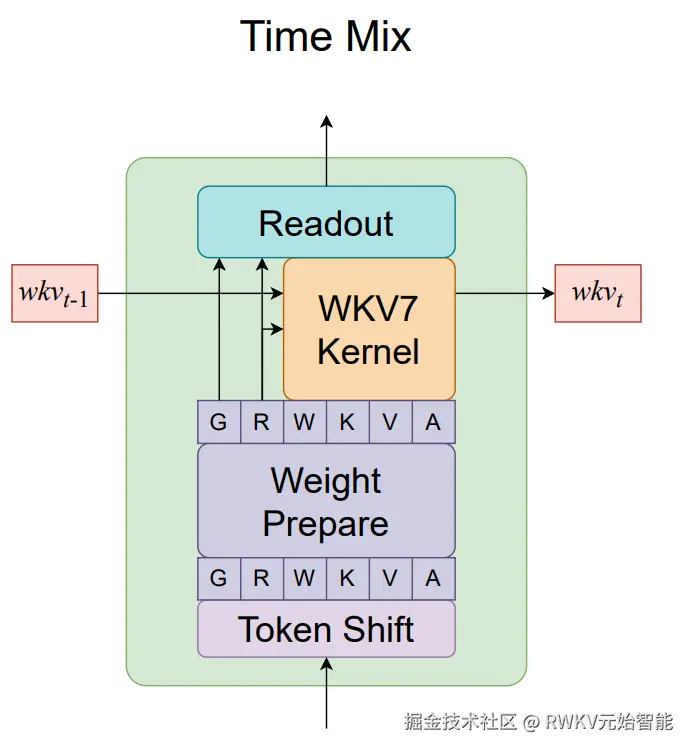
与之对应的是 RWKV_Tmix_x070 的 def forward 代码(并行模式)。
python
class RWKV_Tmix_x070(MyModule):
def __init__(self, args, layer_id):
super().__init__()
self.args = args
self.layer_id = layer_id
self.head_size = args.head_size
self.n_head = args.dim_att // self.head_size
assert args.dim_att % self.n_head == 0
H = self.n_head
N = self.head_size # N = Head Size
C = args.n_embd # C = n_embd = dim_att
with torch.no_grad(): # 初始化阶段,不需要梯度
# === 初始化 "Time-Mixing" 参数 (用于 x 和 x[t-1] 之间的插值) ===
ratio_0_to_1 = layer_id / (args.n_layer - 1)
ratio_1_to_almost0 = 1.0 - (layer_id / args.n_layer)
# 从 0 到 1 的向量,形状 (1, 1, C)
ddd = torch.ones(1, 1, C)
for i in range(C):
ddd[0, 0, i] = i / C
# x_r, x_w, ... 是可训练的参数,用于混合 x 和 x[t-1]
self.x_r = nn.Parameter(1.0 - torch.pow(ddd, 0.2 * ratio_1_to_almost0))
self.x_w = nn.Parameter(1.0 - torch.pow(ddd, 0.9 * ratio_1_to_almost0))
self.x_k = nn.Parameter(1.0 - torch.pow(ddd, 0.7 * ratio_1_to_almost0))
self.x_v = nn.Parameter(1.0 - torch.pow(ddd, 0.7 * ratio_1_to_almost0))
self.x_a = nn.Parameter(1.0 - torch.pow(ddd, 0.9 * ratio_1_to_almost0))
self.x_g = nn.Parameter(1.0 - torch.pow(ddd, 0.2 * ratio_1_to_almost0))
# 正交初始化辅助函数
def ortho_init(x, scale):
with torch.no_grad():
shape = x.shape
if len(shape) == 2:
gain = math.sqrt(shape[0] / shape[1]) if shape[0] > shape[1] else 1
nn.init.orthogonal_(x, gain=gain * scale)
elif len(shape) == 3:
gain = math.sqrt(shape[1] / shape[2]) if shape[1] > shape[2] else 1
for i in range(shape[0]):
nn.init.orthogonal_(x[i], gain=gain * scale)
else:
assert False
return x
# === 初始化 W (time_decay) 和 A (in-context LR) ===
www = torch.zeros(C) # 用于 time_decay (W)
zigzag = torch.zeros(C) # 锯齿形模式,用于模拟头内位置
linear = torch.zeros(C) # 线性模式
for n in range(C):
linear[n] = n / (C-1) - 0.5 # 线性从 -0.5 到 0.5
# 锯齿波,在每个 head (N) 内部从 -1 到 1
zigzag[n] = ((n % N) - ((N-1) / 2)) / ((N-1) / 2)
zigzag[n] = zigzag[n] * abs(zigzag[n]) # 使其更集中在 0 附近
# time_decay 的基准值 (www)
www[n] = -6 + 6 * (n / (C - 1)) ** (1 + 1 * ratio_0_to_1 ** 0.3)
# === W (Time Decay) 的 LoRA-like 参数 ===
D_DECAY_LORA = 8 # 语言模型用 max(32, int(round( (2.5*(C**0.5)) /32)*32))
self.w1 = nn.Parameter(torch.zeros(C, D_DECAY_LORA)) # (C, D)
self.w2 = nn.Parameter(ortho_init(torch.zeros(D_DECAY_LORA, C), 0.1)) # (D, C)
self.w0 = nn.Parameter(www.reshape(1,1,C) + 0.5 + zigzag*2.5) # (1,1,C) 基准
# === A (Alpha) 的 LoRA-like 参数 ===
D_AAA_LORA = 8 # 语言模型用 max(32, int(round( (2.5*(C**0.5)) /32)*32))
self.a1 = nn.Parameter(torch.zeros(C, D_AAA_LORA))
self.a2 = nn.Parameter(ortho_init(torch.zeros(D_AAA_LORA, C), 0.1))
self.a0 = nn.Parameter(torch.zeros(1,1,C)-0.19 + zigzag*0.3 + linear*0.4) # 基准
# === V (Value) 残差混合的 LoRA-like 参数 ===
D_MV_LORA = 8 # 语言模型用 max(32, int(round( (1.7*(C**0.5)) /32)*32))
self.v1 = nn.Parameter(torch.zeros(C, D_MV_LORA))
self.v2 = nn.Parameter(ortho_init(torch.zeros(D_MV_LORA, C), 0.1))
self.v0 = nn.Parameter(torch.zeros(1,1,C)+0.73 - linear*0.4) # 基准
# === G (Gate) 的 LoRA-like 参数 ===
D_GATE_LORA = 8 # 语言模型用 max(32, int(round( (5*(C**0.5)) /32)*32))
self.g1 = nn.Parameter(torch.zeros(C, D_GATE_LORA))
self.g2 = nn.Parameter(ortho_init(torch.zeros(D_GATE_LORA, C), 0.1))
# === K (Key) 和 R (Receptance) 的额外参数 ===
self.k_k = nn.Parameter(torch.zeros(1,1,C)+0.71 - linear*0.1)
self.k_a = nn.Parameter(torch.zeros(1,1,C)+1.02)
self.r_k = nn.Parameter(torch.zeros(H,N)-0.04) # (Heads, Head_Size)
# === 核心组件 ===
# Time-shift: (1, -1) padding 在时间维度 (T) 上实现 x[t-1]
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
# R, K, V, O 线性投影层
self.receptance = nn.Linear(C, C, bias=False)
self.key = nn.Linear(C, C, bias=False)
self.value = nn.Linear(C, C, bias=False)
self.output = nn.Linear(C, C, bias=False)
# 归一化:按头 (H) 分组的 GroupNorm,eps=64e-5 是一个非标准但有效的值
self.ln_x = nn.GroupNorm(H, C, eps=64e-5)
# 初始化 R, K, V, O 的权重
self.receptance.weight.data.uniform_(-0.5/(C**0.5), 0.5/(C**0.5))
self.key.weight.data.uniform_(-0.05/(C**0.5), 0.05/(C**0.5)) # K 的初始化范围更小
self.value.weight.data.uniform_(-0.5/(C**0.5), 0.5/(C**0.5))
self.output.weight.data.zero_() # 输出层初始化为 0 (重要技巧)
@MyFunction
def forward(self, x, v_first):
B, T, C = x.size()
H = self.n_head
# 1. Token Shift 模块,接受输入
xx = self.time_shift(x) - x # xx = x[t-1] - x[t]
# 线性插值 (Lerp): x + (x[t-1] - x[t]) * mix_param
xr = x + xx * self.x_r
xw = x + xx * self.x_w
xk = x + xx * self.x_k
xv = x + xx * self.x_v
xa = x + xx * self.x_a
xg = x + xx * self.x_g
# 2. Weight Prepare 模块,接收 Token Shift 输出,并生成 G, R, W, K, V, A 向量
r = self.receptance(xr) # (B,T,C)
w = -F.softplus(-(self.w0 + torch.tanh(xw @ self.w1) @ self.w2)) - 0.5 # W (time_decay): 通过 LoRA 计算并用 softplus 钳位到 (-inf, -0.5)
k = self.key(xk) # (B,T,C)
v = self.value(xv) # (B,T,C)
if self.layer_id == 0:
v_first = v # 第一层:存储 v
else:
v = v + (v_first - v) * torch.sigmoid(self.v0 + (xv @ self.v1) @ self.v2) # 后续层:将 v 与第一层的 v_first 混合
a = torch.sigmoid(self.a0 + (xa @ self.a1) @ self.a2) # A (Alpha): (B,T,C) "in-context learning rate"
g = torch.sigmoid(xg @ self.g1) @ self.g2 # G (Gate): (B,T,C) 输出门
# 3. WKV7 Kernel 模块,接收 wkv_t-1(上一步的状态)和 R, W, K, V, A,然后输出新的状态 wkv_t 和一个结果给 "Readout"
kk = k * self.k_k # (B,T,C)
kk = F.normalize(kk.view(B,T,H,-1), dim=-1, p=2.0).view(B,T,C)# L2 归一化 (在 head 维度上)
k = k * (1 + (a-1) * self.k_a)
x = RUN_CUDA_RWKV7g(r, w, k, v, -kk, kk*a) # CUDA 并行计算所有时间步的结果 x
# 4. "Readout" 模块,接收 WKV7 Kernel 的输出,也接收来自 "Weight Prepare" 的 G 和 R 向量,最后生成最终输出
x = self.ln_x(x.view(B * T, C)).view(B, T, C)
x = x + ((r.view(B,T,H,-1)*k.view(B,T,H,-1)*self.r_k).sum(dim=-1, keepdim=True) * v.view(B,T,H,-1)).view(B,T,C)
x = self.output(x * g)# 应用输出门并投影
return x, v_first # 返回输出和 v_first4. 生成"数字翻转"训练数据的代码
Line 183 ~ 193定义了 batch 函数,一个动态的数据生成器。由于这是一个简单的演示脚本,我们不从磁盘加载训练数据,而是即时创建"数字翻转"数据:生成随机数n,跟一个逗号,然后是该数字的反向序列,最后是结束符#。例如582,285#。
模型将以"预测下一个 token"的方式学习这个序列,从而学会这个算法。
python
# 词表:'0'-'9' (token 0-9), ',' (token10), '#' (token11)
TOK = {**{str(i):i for i in range(10)}, ',':10, '#':11}
M = 10**DIGIT_MAX - 1
def _digits(n): return [TOK[c] for c in str(n)]
def batch(B,T, device=None):
if device is None: device = 'cuda' if torch.cuda.is_available() else 'cpu'
s = []
for _ in range(B):
a = []
while len(a) < T:
k = random.randint(1,DIGIT_MAX); lo = 0 if k==1 else 10**(k-1); n = random.randint(lo, 10**k-1)
nn = _digits(n)
a += nn + [TOK[',']] + nn[::-1] + [TOK['#']]
s.append(a[:T])
return torch.tensor(s, device=device, dtype=torch.long)5. Channel-Mixing(FFN) 模块
Line 200 ~ 214 (FNN) 是 RWKV 架构的另一个标准组件 Channel-mixing 模块,负责在通道(嵌入)维度上混合信息,功能上等同于 Transformer 中的前馈网络 (FFN)。
与 Time Mix 模块类似,Channel-Mixing 也采用了 time_shift 技巧来引入前一时间步的信息,并使用 Squared ReLU (relu(..)**2) 作为激活函数。
python
class FFN(nn.Module):
def __init__(self, C):
super().__init__()
# 同样使用 time_shift 技巧
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
self.x_k = nn.Parameter(torch.zeros(1, 1, C)) # FFN 的 time-mix 参数
self.key = nn.Linear(C, C * 4, bias=False) # 放大层
self.value = nn.Linear(C * 4, C, bias=False) # 缩小层
with torch.no_grad():
self.value.weight.data.zero_() # value 层权重初始化为 0
nn.init.orthogonal_(self.key.weight.data, gain=(4**0.5)) # key 层正交初始化
def forward(self, x):
xx = self.time_shift(x) - x # 1. Time-Mix
x = x + xx * self.x_k
x = torch.relu(self.key(x)) ** 2 # 2. FFN 计算 (Squared ReLU)
return self.value(x)6. 模型定义
Line 216 ~ 256(MODEL) 的 MODEL 类是完整的 RWKV 神经网络模型。它将前面定义的所有构建模块(nn.Embedding、LayerNorm、RWKV_Tmix_x070 和 FFN)组装在一起。
本文的模型是 2 层 RWKV 网络,和 RWKV-7 论文的架构定义一致(由于这里是极小的模型,因此没有在 Embedding 后面加 LayerNorm):
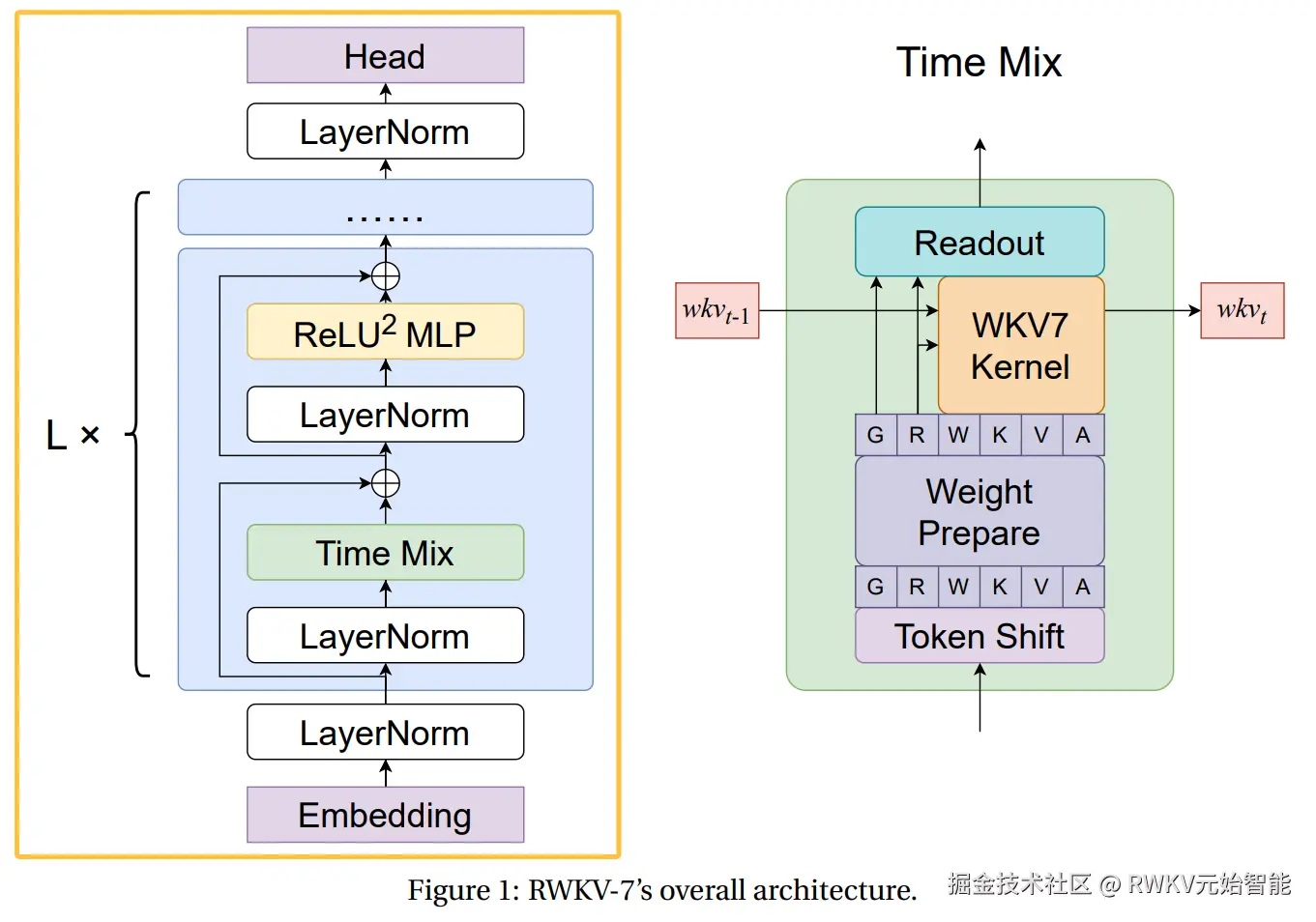
python
class MODEL(nn.Module):
def __init__(s): # 使用 's' 代替 'self'
super().__init__()
args = SimpleNamespace()
args.n_head = C//HEAD_SIZE
args.head_size = HEAD_SIZE
args.n_embd = C
args.dim_att = C
args.n_layer = 2 # 2 层模型
# 词嵌入层
s.e=nn.Embedding(V,C)
# --- 第 1 层 ---
s.ln1a=nn.LayerNorm(C)
s.ln1b=nn.LayerNorm(C)
s.rwkv1=RWKV_Tmix_x070(args,0) # layer_id = 0
s.ffn1=FFN(C)
# --- 第 2 层 ---
s.ln2a=nn.LayerNorm(C)
s.ln2b=nn.LayerNorm(C)
# s.ln2c=nn.LayerNorm(C) #
s.rwkv2=RWKV_Tmix_x070(args,1) # layer_id = 1
s.ffn2=FFN(C)
# --- 输出 ---
s.lno=nn.LayerNorm(C)
s.o=nn.Linear(C,V) # 输出到词汇表
def forward(s,x):
x = s.e(x) # (B,T) -> (B,T,C)
# 模型结构: x = x + FFN(LN(x + Tmix(LN(x))))
# 第 1 层,v_first 初始化为空
xx, v_first = s.rwkv1(s.ln1a(x), torch.empty_like(x))
x = x + xx
x = x + s.ffn1(s.ln1b(x))
# 第 2 层,传入 v_first
xx, v_first = s.rwkv2(s.ln2a(x), v_first)
x = x + xx
x = x + s.ffn2(s.ln2b(x))
# 输出,ln -> Head
x = s.o(s.lno(x)) # (B,T,C) -> (B,T,V)
return x
model=MODEL().to(device)7. 训练代码 (优化器与反向传播)
Line 258 ~ 314是训练配置和训练过程的代码,主要包含:
- 初始化
AdamW优化器 - 将模型参数分为
decay(embedding 和权重矩阵)和no_decay(LayerNorm 和 bias) - 设置
CosineAnnealingLR(余弦退火)学习率调度器,在训练过程中平滑地降低学习率
python
# 分离需要权重衰减 (decay) 和不需要 (no_decay) 的参数
wdwd,decay,no_decay,fixed=[],[],[],[]
wdwd_names,decay_names,no_decay_names,fixed_names=[],[],[],[]
for n,p in model.named_parameters():
if not p.requires_grad: continue
# 权重矩阵和嵌入层使用权重衰减
if ('.weight' in n or 'emb' in n) and ('ln' not in n):
decay.append(p); decay_names.append(n)
else:
# bias, LayerNorm 参数不使用权重衰减
no_decay.append(p); no_decay_names.append(n)
print('decay', decay_names)
print('no_decay', no_decay_names)
# AdamW 优化器,为两组参数设置不同的 weight_decay
opt = torch.optim.AdamW(
[
{"params": decay, "weight_decay": 0.1},
{"params": no_decay, "weight_decay": 0.0},
],
lr=lr0
)
# 学习率调度器:余弦退火
sch=torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=steps, eta_min=lr1)
# Wandb 设置,建议提前登录 WandB(https://wandb.ai/)
args = SimpleNamespace()
trainer = SimpleNamespace()
args.my_timestamp = datetime.datetime.today().strftime("%Y-%m-%d-%H-%M-%S")
print("Login to wandb...")
wandb.init(
project="Test",
name=args.my_timestamp,
config=args,
save_code=False,
)然后进入主训练循环,迭代 steps 次。在每一步中,它获取一批数据,执行模型前向传播、计算交叉熵损失(Cross-Entropy)、执行反向传播、梯度裁剪(clip_grad_norm_),并更新模型权重。
训练结束后,脚本会保存模型(out.pth)
ini
token_per_step = B*(T-1) # 每一步处理的 token 数量 (不包括最后一个终止符 #)
for step in range(steps):
# 1. 获取数据并准备输入 (x) 和目标 (y)
x=batch(B,T); y=x[:,1:]; x=x[:,:-1]
# 2. 前向传播
z=model(x) # (B, T-1, V)
# 3. 交叉熵计算损失
loss=F.cross_entropy(z.reshape(-1,V),y.reshape(-1))
# 4. 记录学习率和 loss 的日志
trainer.my_lr = sch.get_last_lr()[0]
trainer.my_loss = loss.item()
print(f'{step+1}/{steps}', 'loss', round(trainer.my_loss,4), 'lr', trainer.my_lr)
# 计算吞吐量 (kt/s)
t_now = time.time_ns()
kt_s = 0
try:
t_cost = (t_now - trainer.my_time_ns) / 1e9
kt_s = token_per_step / t_cost / 1000
except:
pass
trainer.my_time_ns = t_now
# 5. 记录到 Wandb
lll = {"loss": trainer.my_loss, "lr": trainer.my_lr, "Mtokens": (step+1) * token_per_step / 1e6}
if kt_s > 0:
lll["kt/s"] = kt_s
wandb.log(lll, step=step+1)
# 6. 反向传播和优化
opt.zero_grad(set_to_none=True); loss.backward() # set_to_none=True 更快
clip_grad_norm_(model.parameters(), max_norm=1.0) # 梯度裁剪
opt.step(); sch.step() # 更新权重和学习率
torch.save(model.state_dict(),"out.pth") #保存模型权重
print('#'*100) 8. 模型效果评估
Line 317 ~ 393进入评估循环,生成 5 个数字样本,打印模型的预测 (pred) 与真实值 (gold) 的对比,以及最终的 token 准确率。
simple check是检查整个序列,对应训练时的 loss。correct check是检查"数字翻转"任务的准确率(只检查翻转后的结果是否正确)。
python
print('simple check (NOTE: here random inputs are considered for diff too, for simplicity)')
with torch.no_grad():
S='0123456789,#' # Token ID 到字符的映射表
for SAMPLE in range(5):
x=batch(1,129); y=x[:,1:]; z=model(x[:,:-1]).argmax(-1)
xx=''.join(S[t] for t in x[0,:-1].tolist()) # 输入字符串 (in)
yy=''.join(S[t] for t in y[0].tolist()) # 真实目标字符串 (gold)
zz=''.join(S[t] for t in z[0].tolist()) # 模型预测字符串 (pred)
zy=''.join('.' if z[0,i].item()==y[0,i].item() else '^' for i in range(y.size(1)))
print('in ',xx)
print('gold',yy)
print('pred',zz)
print('diff',zy)
print('#'*100)
print('#'*100)
print('correct check (only check results)')
with torch.no_grad():
S = '0123456789,#'
COMMA = S.index(',') # 逗号的 Token ID (10)
HASH = S.index('#') # 井号的 Token ID (11)
for SAMPLE in range(5):
x = batch(1, 129)
y = x[:, 1:]
logits = model(x[:, :-1])
z = logits.argmax(-1)
x_ids = x[0].tolist() # 完整输入 Token 列表
L = len(x_ids)
region_char = [False] * L # 初始化掩码,标记每个位置是否在"翻转区域"
mode = 0
# 遍历原始输入序列 x,确定哪些 Token 是在预测区
for j, tok in enumerate(x_ids):
if mode == 1:
region_char[j] = True
if tok == COMMA:
mode = 1
elif tok == HASH:
mode = 0
mask = region_char[1:]
y_ids = y[0].tolist()
z_ids = z[0].tolist()
# 统计掩码区域内的准确率
n_tokens = sum(mask)
if n_tokens > 0:
n_correct = sum(
1 for i, m in enumerate(mask) if m and y_ids[i] == z_ids[i]
)
acc = n_correct / n_tokens
else:
n_correct = 0
acc = float('nan') # 避免除以零
# 生成带空格的掩码输出,只显示翻转预测区的结果
gold_masked = ''.join(S[y_ids[i]] if mask[i] else ' ' for i in range(len(y_ids)))
pred_masked = ''.join(S[z_ids[i]] if mask[i] else ' ' for i in range(len(z_ids)))
diff_masked = ''.join(
('.' if y_ids[i] == z_ids[i] else '^') if mask[i] else ' '
for i in range(len(y_ids))
)
print('in ', xx)
print('gold ', gold_masked) # 只显示翻转预测区的目标
print('pred ', pred_masked) # 只显示翻转预测区的预测
print('diff ', diff_masked) # 只显示翻转预测区的差异
print(f'correct {n_correct}/{n_tokens} acc {acc:.3f}')
print('#' * 100)训练指南
1. 克隆GitHub 仓库
arduino
https://github.com/BlinkDL/RWKV-LM.git2. 安装 pytorch 和其他依赖
bash
# 可以用最新的 torch + cuda,请根据自己的 CUDA 版本修改
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu129
pip install wandb ninja --upgrade3. 启动训练
bash
cd RWKV-LM/RWKV-v7/train_temp/
python rwkv7_train_simplified.py如果你登录了 wandb,会看到如下画面,训练约耗时三分钟:
训练结束后会自动进行数字翻转测试:
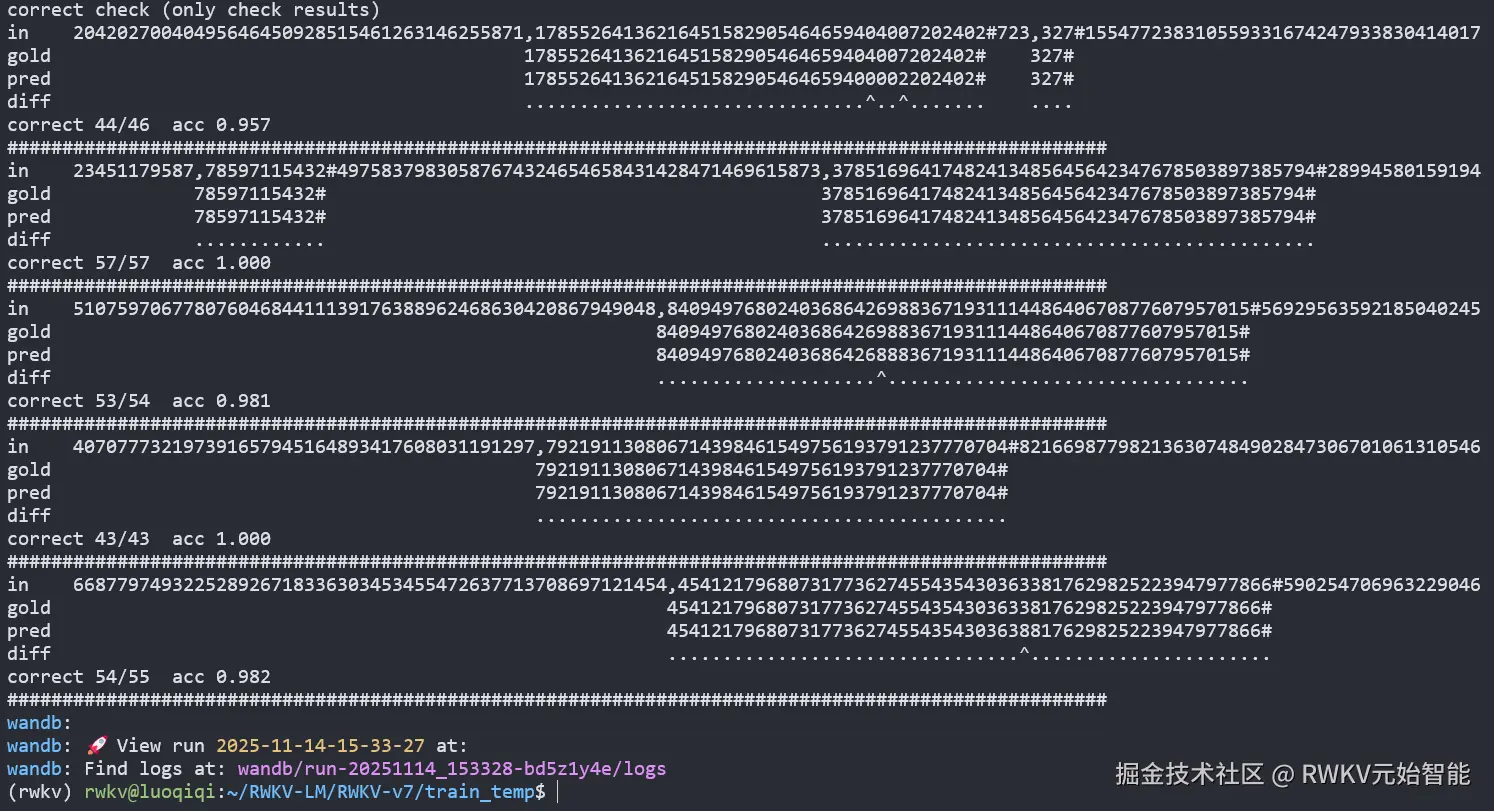
测试结果显示,2 层 RWKV 模型(仅 30860 个参数)在数字翻转任务有良好的准确率(若加入最新 ROSA 机制会显著更强:RWKV7+ROSA用40K参数颠倒60位数字输入)。
加入 RWKV 社区
欢迎大家加入 RWKV 社区,可以从 RWKV 中文官网了解 RWKV 模型,也可以加入 RWKV 论坛、QQ 频道和 QQ 群聊,一起探讨 RWKV 模型。
- 📖 RWKV 中文文档:www.rwkv.cn
- 💬 RWKV 论坛:community.rwkv.cn/
- 🐧 QQ 频道:pd.qq.com/s/9n21eravc | QQ 应用内测群:332381861
- 📺 BiliBili 视频教程:space.bilibili.com/35466890969...