
🔥个人主页:爱和冰阔乐
📚专栏传送门:《数据结构与算法》 、【C++】 、【Linux】
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

🏠博主简介

文章目录
- 前言
- 一、如何理解条件编译
-
- [1.1 定义](#1.1 定义)
- [1.2 作用](#1.2 作用)
- 二、编译先编译为汇编的原因
-
- [2.1 原因及语言发展史](#2.1 原因及语言发展史)
- [2.2 编译器使用什么语言来编写](#2.2 编译器使用什么语言来编写)
- 三、库
-
- [3.1 库的概念](#3.1 库的概念)
- [3.2 库的定义](#3.2 库的定义)
- [3.3 动态链接和静态链接](#3.3 动态链接和静态链接)
- [3.4 动静态库](#3.4 动静态库)
- [3.5 sudo权限问题](#3.5 sudo权限问题)
- [四、自动化构建工具 ------make / Makefile](#四、自动化构建工具 ——make / Makefile)
-
- [4.1 背景](#4.1 背景)
- [4.2 依赖关系与依赖方法](#4.2 依赖关系与依赖方法)
- [4.3 定义变量](#4.3 定义变量)
- 总结
前言
本文是在上篇文章的编译等内容进行进行展开,从条件编译的巧妙运用,到编译器背后的工作原理,再到动静态库的本质区别,以及自动化构建工具的使用技巧,下面便让和我们来探究下其中的奥秘吧
一、如何理解条件编译
1.1 定义
在C语言中便介绍了预处理中的条件编译,那么什么是条件编译?
理解:通过 预处理指令 告诉编译器 "哪些代码要编译,哪些不要",这些指令在编译的 "预处理阶段" 执行(早于代码编译和链接),最终被处理后的代码才会进入真正的编译流程
下面我们通过代码来回顾下
cpp
#include<stdio.h>
#define M
int main()
{
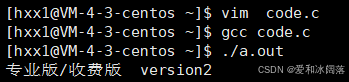
#ifndef M
printf("社区版/免费版 version1\n");
#else
printf ("专业版/收费版 version2\n");
#endif
}
除了在代码中我们可以通过#define设置条件编译以外,我们同样可以在Linux的命令行中对原文件进行动态添加宏(进行宏定义或者设置初始值)
bash
#D后面紧挨的便是宏
#将-DM解释为#define M 100 插入到代码中
gcc code.c -o code -DM
gcc code.c -o code -DM=100
./code
注意:预处理的主要作用便是将头文件展开,将注释去掉,宏替换,条件编译,在这里我们便可以得出预处理的本质便是修改编辑我们的文本代码
1.2 作用
通过以上介绍我们复习了条件编译,那么条件编译有什么用途?
在平时我们用过的vs2022,idea等等软件中,它们都分为免费版/社区办或者专业版/付费版,这两者的区别便是存在功能的差异或者支持的功能点多与少,那么在这些软件开发的公司中维护这些软件需要维护几份源代码?
其实我们仔细思考便知道,大部分专业版通过阉割/裁剪便得到了免费版,因此在公司中只需维护一份源代码,那么怎么让代码编译未不同版本,这便就是条件编译的用途了,我们可以把软件中免费版和专业版都有的功能放在一个模块里,收费的功能放在别的模块里,通过条件编译进行代码的维护,因此便可以让公司维护一份源码,对外可以实现多份软件的目的
二、编译先编译为汇编的原因
2.1 原因及语言发展史
在编译时是先把C语言生成汇编,然后汇编成二进制,那么为什么需要先把C语言先翻译成汇编语言,而不是直接翻译为二进制,更加快捷,这里便需要提到计算机语言的发展史了,在1946年世界上出现了第一台计算机 埃尼阿克,我们是使用开关来控制计算机。在五六十年代出现了打孔编程(有孔认为是1,没孔为0)即二进制编程,由于二进制的效率太低了,后来人们便发明了汇编语言,而在汇编语言出现后,便需要 编译器,因为汇编语言是一种文本,我们需要编译器将汇编语言翻译成二进制,其后又出现了C语言这类的编译语言,因为机器只认识二进制,所以我们也需要编译器将其翻译为二进制。
那么这时候便有了疑惑,我们是直接将C语言编译为二进制,还是先将C语言编译为汇编,再将其编译为二进制,我们站在巨人的肩膀上回顾历史,便知道是先翻译为汇编。
原因:C语言翻译为汇编是文本和文本之间的翻译,相比于直接翻译为二进制难度会大大降低,其次,在产生C语言前便有了汇编,汇编在C语言出来前便可以独立翻译为二进制,我们只需将C语言翻译为汇编,即前人栽树后人乘凉,如果我们直接将C语言翻译为二进制,没有了前人的肩膀,难度大大提升,举个简单的例子,C++是在C语言基础上发明的,如果想要将C++翻译为二进制也是重新开始,难度会很大。
2.2 编译器使用什么语言来编写
汇编语言有了,那么想要生成汇编语言的编译器便需要知道其是用什么实现的?
汇编语言 or 二进制???
首先我们假设编译器是由汇编语言来写的,那么编译器怎么被编译成二进制?这里我们可以先使用二进制来写个二进制版的汇编编译器(将汇编一个个翻译为二进制),我们便可以通过二进制编译汇编语言了,那么这时我们再用汇编语言来写一个汇编编译器 ,将汇编语言写的编译器通过二进制版的编译器编译便大功告成,那么二进制写的编译器便可以淘汰了
同理,C语言编译器先是通过汇编语言来实现,再拿C语言重新编译新的编译器,最后拿汇编语言的编译器对C语言编译器进行编译,便可以得到C语言版的编译器,其他语言如C++/Java/Python均是该流程
以上过程有个专业名词叫:编译器的自举的过程。
三、库
3.1 库的概念
举个简单的例子,在C语言发明出来时需要配备一些基本的函数,如printf(打印),字符串拼接等功能函数,若如没有这些接口,那么每个程序员档用到这些方法时,都需要自己来造轮子,可能导致该程序只需10分钟写完,实现printf函数便花了9分钟,严重浪费了人力资源
因此这里便出现了库,库就是一套方法或者数据集,为我们开发提供最基本的保证(基本接口,功能,加速二次开发)
在Linux中我们可以通过 ls /usr/lib64 查看在系统中各类的库
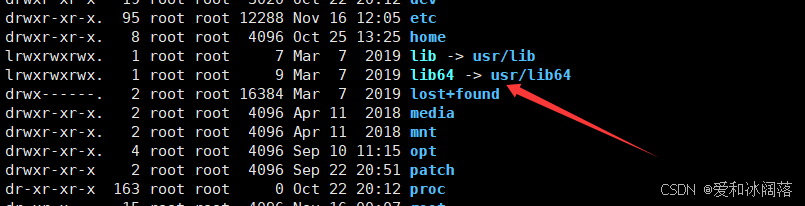
Linux中存在的库
在Windows电脑中同样存在很多库,如下:

3.2 库的定义
在 C 语言开发中,库(Library) 是经编译封装的可复用代码集合,包含函数、数据结构、宏定义等核心逻辑,旨在实现功能模块化、代码复用与开发效率提升 ------ 开发者无需关注库内部实现细节,仅通过调用库提供的接口(API)即可快速集成所需功能,同时避免重复编码。
在Linux系统中,库分为动态库与静态库,它们的格式分别为lib(名字).so和 lib(名字).a ,举个简单的例子,C语言的动态库便为libc.so
注意:在Windows系统中动态库是以 .dll 为后缀 ,静态库是以 .lib 为后缀
3.3 动态链接和静态链接
在我们的实际开发中,不可能将所有代码放在⼀个源⽂件中,所以会出现多个源⽂件,⽽且多个源⽂件之间不是独⽴的,⽽会存在多种依赖关系,如⼀个源⽂件可能要调⽤另⼀个源⽂件中定义的函数,但是每个源⽂件都是独⽴编译的,即每个*.c⽂件会形成⼀个*.o⽂件,为了满⾜前⾯说的依赖关系,则需要将这些源⽂件产⽣的⽬标⽂件进⾏链接,从⽽形成⼀个可以执⾏的程序。这个链接的过程就是静态链接。静态链接的缺点很明显:
- 浪费空间:因为每个可执⾏程序中对所有需要的⽬标⽂件都要有⼀份副本,所以如果多个程序对同⼀个⽬标⽂件都有依赖,如多个程序中都调⽤了printf()函数,则这多个程序中都含有printf.o,所以同⼀个⽬标⽂件都在内存存在多个副本;
- 更新⽐较困难:因为每当库函数的代码修改了,这个时候就需要重新进⾏编译链接形成可执⾏程序。但是静态链接的优点就是,在可执⾏程序中已经具备了所有执⾏程序所需要的任何东西,在执⾏的时候运⾏速度快。
动态链接的出现解决了静态链接中提到问题。动态链接的基本思想是把程序按照模块拆分成各个相对独⽴部分,在程序运⾏时才将它们链接在⼀起形成⼀个完整的程序,⽽不是像静态链接⼀样把所有程序模块都链接成⼀个单独的可执⾏⽂件。动态链接其实远⽐静态链接要常⽤得多
⽐如我们查看下 hello 这个可执⾏程序依赖的动态库,会发现它就⽤到了⼀个c动态链接库:
bash
$ ldd hello
linux-vdso.so.1 => (0x00007fffeb1ab000)
libc.so.6 => /lib64/libc.so.6 (0x00007ff776af5000)
/lib64/ld-linux-x86-64.so.2 (0x00007ff776ec3000)
# ldd命令⽤于打印程序或者库⽂件所依赖的共享库列表。 通过以上的了解,我们便可以给静态链接和动态链接下个定义
静态链接:指在 编译链接 阶段,将程序依赖的静态库(.a/.lib)中所需的代码(函数、数据结构等)完整复制并嵌入到目标可执行文件中 。最终生成的可执行文件不依赖外部库,可独立运行。
其的核心过程为:
- 编译器将源代码(.c)编译为目标文件(.o);
- 链接器(ld)分析目标文件的依赖,找到对应的静态库(如 libc.a、libhxx.a);
- 从静态库中提取程序所需的代码片段,与目标文件合并,生成单一的可执行文件;
- 可执行文件运行时,无需加载外部库,所有依赖逻辑已内置。
举例:
bash
# 编译时指定静态库libhxx.a,完成静态链接
gcc main.c -o main_static -L./lib -lhxx -static # -static强制静态链接动态链接:动态链接是指在 程序运行时(或加载时),才将程序依赖的动态库(.so/.dll)加载到内存中,与可执行文件 "动态绑定"。可执行文件中仅存储动态库的 "引用信息"(如库文件名、函数地址偏移),不包含库的实际代码,其的核心过程为:
- 编译器将源代码编译为目标文件,链接器仅在可执行文件中写入动态库的依赖信息(不复制库代码);
- 程序运行时,操作系统的动态链接器(如 Linux 的 ld-linux.so、Windows 的 loader)会:
- 查找并加载依赖的动态库到内存;
- 解析可执行文件中的引用,将函数调用映射到内存中动态库的实际地址;
- 多个程序可共享同一内存中的动态库副本(无需重复加载)
3.4 动静态库
动态库在定义格式上是以so结尾,其会在内部实现方法,我们会将自己的程序中使用的库方法和动态库通过 动态链接 起来(让程序能找到库中方法的地址)并形成可执行程序
动态库的特点便是在执行方法时,需要跳转到库中执行,完成后返回程序,且其被多个程序共享,一旦确实便会导致所有程序无法执行,举个简单的例子:某个中学的附近有一个网吧,该校的学生全在这上网,一旦该网吧倒闭,那么该校的所有学生无法上网。
总结:
- 动态库在程序运行时才被加载到内存,本质是将语言层面上的公共代码,在内存中未来只出现一次
- 多个程序可共享同一库文件,不占用程序自身的可执行文件体积
静态库在定义格式上是以.a为结尾,其在使用到库中的方法时,会将其拷贝到自己的程序中(相当于库的方法属于自己了)即 静态链接,静态库只有在链接的时候有用,一旦形成可执行程序,静态库就可以不再需要
总结:静态库在编译链接阶段会被完整嵌入到目标程序中,程序运行时无需依赖外部库文件,可独立执行,但会导致可执行文件体积增大
动静态库的对比:
- 动态库形成的可执行程序体积一定很小
- 可执行程序对静态库的依赖小,动态库不能缺少
- 程序运行需要加载到内存中,静态链接的会在内存中出现大量重复代码(动态库需要被加载到内存中,静态库不需要,其在编译时便加载到程序中)
- 动态链接比较节省内存和磁盘资源
下面我们通过代码来感受可执行程序在gcc默认的是动态链接
bash
vim code.c
#include<stdio>
int main()
{
printf("hello world\n");
return 0;
}
gcc code.c -o code
./code
ldd code
file code

gcc编译默认的是动态链接的,如果想要进行静态链接,就必须和动态库在Linux存在(/usr/lib/64/lib.so.6),即C静态库必须存在,且gcc默认是动态链接,想要进行静态链接需要加上 -static 选项
bash
gcc code.c -o code -static
由上我们便知道在Linux系统中不存在C语言的静态库,因此我们就需要在Linux中安装其的静态库
bash
sudo yum install -y glibc-static
#sudo执行成功后系统提醒输入该账号的密码,注意不是root密码
#检验是否安装成功
ls /usr/lib64/libc.a -l
#使用静态库进行编译
gcc code.c -o code -static出现complete即安装成功
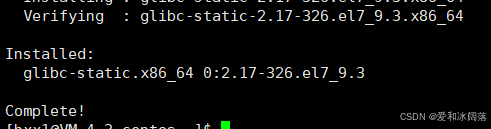
在系统中搜索静态库

形成code-static可执行程序,仔细发现,静态库形成的文件大小将近是动态库的100倍,而这不过只有一个printf函数,因此系统更喜欢使用动态库
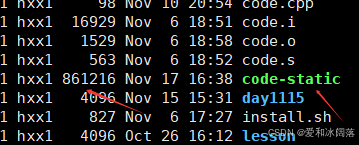
同样C++在Linuxg++编译时使用的也是动态库,如若使用静态同样需要配置
bash
sudo yum install libstdc++-static
g++ code.cpp -o codecpp-static -static3.5 sudo权限问题
在介绍权限时我们便提到了想要进行下载等只有root账号有该权限时可以在普通账号下通过sudo来提权,当时给大家留了个疑问,为什么sudo是要输入当前普通账号的密码而不是root账号,下面便一一给大家解释
首先我们需要在系统中查看 /etc/sudoers,然后进入该文件中
bash
ls /etc/sudoers -l
vim /tex/sudoers
进入sudoers时我们发现在左下角显示 noperm(没有权限)
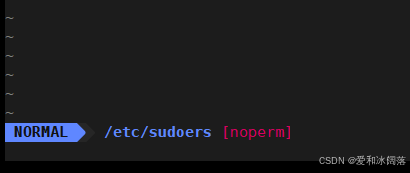
因此需要切换为超级用户,进入sudoers,在100行root下添加普通用户即可
bash
su -
#输入root账号的密码
vim /etc/sudoers
#添加普通用户
hxx1 ALL=(ALL) ALL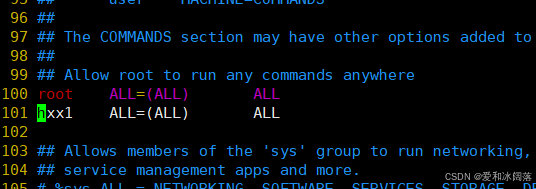
然后按 ctrl+d 便可以回到普通用户中,即可使用sudo进行提权
四、自动化构建工具 ------make / Makefile
4.1 背景
- 会不会写makefile,从⼀个侧⾯说明了⼀个⼈是否具备完成⼤型⼯程的能⼒
- ⼀个⼯程中的源⽂件不计数,其按类型、功能、模块分别放在若⼲个⽬录中,makefile定义了⼀系列的规则来指定,哪些⽂件需要先编译,哪些⽂件需要后编译,哪些⽂件需要重新编译,甚⾄于进⾏更复杂的功能操作
- makefile带来的好处就是------------"⾃动化编译",⼀旦写好,只需要⼀个make命令,整个⼯程完全⾃动编译,极⼤的提⾼了软件开发的效率。
- make是⼀个命令⼯具,是⼀个解释makefile中指令的命令⼯具,⼀般来说,⼤多数的IDE都有这个命令,⽐如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可⻅,makefile都成为了⼀种在⼯程⽅⾯的编译⽅法。
make是⼀条命令,makefile是⼀个⽂件,两个搭配使⽤,完成项⽬⾃动化构建
4.2 依赖关系与依赖方法
bash
touch code.c
vim code.c
#在code.c中编写代码
#include<stdio.h>
int main()
{
printf("hello world\n");
return 0;
}
touch Makefile
vim Makefile
#在Makefile中编写代码
code:code.c
gcc -o code code.c
#编译不再使用gcc,使用make即可,其会在1当前目录下寻找Makefile文件,根据Makefile文件推导要形成的文件,自动执行该方法,自动编译
make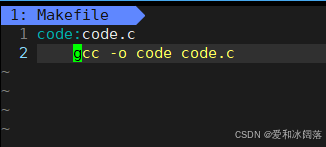

下面我们便来解释在Makefile中写的代码的含义吗,我们把第一行称为依赖关系,第二行必须以 Tab 建开头,后面的 代码被称为依赖方法。
那么什么是依赖关系与依赖方法,举个通俗易懂的例子,到月底了,小明没有钱了,于是便给他的爸爸打了电话说:爸,我是你儿子,然后挂掉了电话,在小明爸爸的心理可能有一万个emmm不好发作,小明也没有要到钱。在该故事中,小明对其父亲只表明了依赖关系。
那么什么是依赖方法,小明继续给老爸打电话:爸,我是你儿子(表明依赖关系),我这个月钱快没了,给我发点钱(依赖方法),这里需要注意,依赖关系和依赖方法均不可匹配错误,如打给父亲的电话打给了舍友的父亲(依赖关系错误),再如,小明说:爸,我是你儿子,你帮我考试(依赖方法匹配错误)
当依赖关系和依赖方法都具备且正确时就可以达到目的,在该代码中,code依赖于code.c,通过gcc方法形成可执行(依赖方法),两个合在一起便可以实现编译工作
make命令在扫描Makefile文件时候,是从上往下扫描,默认形成第一个目标文件(后面的命令需要手动执行),下面我们通过代码来了解下
bash
touch myproc.c
vim myproc.c
#include<stdio.h>
int main()
{
printf("hello wrold\n");
return 0;
}
#在该目录下生成Makefile
touch Makefile
vim Makefile
myproc:myproc.c
#注意必须以Tab开头
gcc -o myproc myproc.c
.PHONY:clean
#clean依赖的是空文件
clean:
#必须以Tab开头
rm -f myproc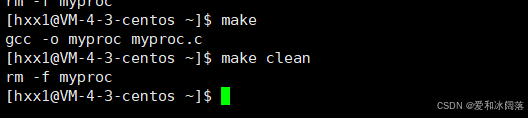
因此在Makefile中我们需要的可执行程序一般都放到最前面
在编写clean指令时,我们加入了.PHONY:clean ,那么它是什么,我们试着删掉它,发现clean指令依旧可以执行,下面我们便来揭开 PHONY的神秘面纱
PHONY是伪目标申明的意思,表示对应的依赖方法和依赖关系总是被执行,因此PHONY修饰的clean总是被执行
4.3 定义变量
Makefile还允许我们定义变量,如下
bash
#BIN是变量,myproc是变量的内容
BIN=myproc
.PHONY:test
test:
#依赖方法,回显该命令,$里面的BIN替换为变量的内容
echo $(BIN)
#不回显命令
@echo $(BIN)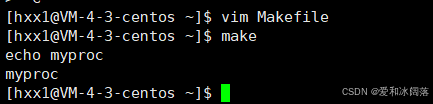
如若不想将命令回显出来,只需在命令前加上 @ 即可,只会执行该方法

通过上面的简单描述后,我们便可以自己写个简单变量版的Makefile,这样的好处便是如若想要将目标文件换个名字只需修改BIN即可,其他均不需要进行改动
方法1:
bash
BIN=myproc
CC=gcc
SRC=myproc.c
FLAGS=-o
RM=rm -f
#依赖关系
$(BIN):$(SRC)
#依赖方法
$(CC) $(FLAGS) $(BIN) $(SRC)
#依赖方法,其中$@代表的是其的最终目标文件,$^则代表的依赖的众多文件列表,因此我们只需下面写法即可
$(CC) $(FLAGS) $@ $^
.PHONY:
clean:
$(RM) $(BIN)
.PHONTY:test
test:
@echo $(BIN)
@echo $(CC)
@echo $(SRC)
@echo $(FLAGS)
@echo $(RM)方法2:
在如下代码中,%类似于Makefile下的通配符,%.o 即是把当前路径下所有的 .o依次展开,同理%.c也是如此,%c是批量将所有 .c 文件编译为对应的 .o 文件
bash
BIN=myproc
CC=gcc
SRC=myproc.c
OBJ=myproc.o
LFLAGS=-o
FLAGS-c
RM=rm -f
$(BIN):$(OBJ)
$(CC) $(LFLAGS) $@ $^
#如若文件很多,因此便需要如下写法,%.o:%.c,将当前所有文件展开
%.O:%.C
#依次进行编译
$(CC) $(FLAGS) $<
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN) 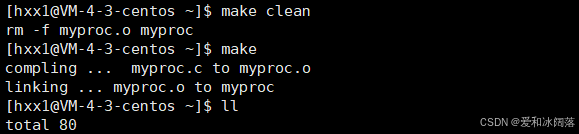
Makefile如若除了只是上述两种写法,那么和gcc编译又有什么区别,因此在Makefile可以直接执行命令行的指令,格式为 $(shell +命令)
bash
SRC=$(sahell ls)除此之外Makefile其内部支持函数
bash
#默认把当前目录下的.c文件通配出来
SRC=$(wildcar *.c)因此如若以后完成一个大的项目,有很多的源文件就不需要将所有文件名手写到Makefile中,只需按上面两种方法即可
因此我们通过不断完善便可以得到最后的小而美的Makefile
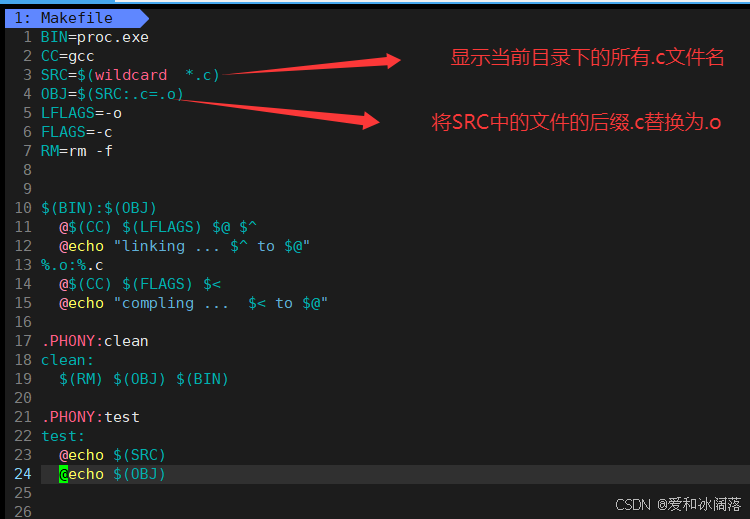
总结
坚持到这里,已经很棒啦,希望读完本文可以帮读者大大更好了解Linux的内容!!!如果喜欢本文的可以给博主点点免费的攒攒,你们的支持就是我前进的动力🎆
资源分享:
【Linux工具链】从跨平台适配到一键部署:yum多架构支持+Vim远程编辑+gcc交叉编译,解决多场景开发效率瓶颈