一、YOLO11分割数据集的核心特性
实例分割的核心是"既要识别目标类别,又要勾勒目标轮廓",这决定了YOLO11分割数据集与传统检测数据集的本质区别。在动手构建前,必须先明确其核心定义和格式规范。
1.1 分割数据集与检测数据集的核心差异
目标检测数据集仅需标注目标的边界框(x,y,w,h),而分割数据集在此基础上,还需要用像素级的掩码(Mask)精准描述目标的形状。形象地说,检测是"给目标画框",分割是"给目标涂色"。这种差异使得分割数据集能为YOLO11提供更细粒度的特征信息,支撑模型学习物体的边缘细节。
YOLO11之所以能高效处理分割任务,得益于其架构改进:引入BiFormer注意力机制捕捉边界特征,增强的C2PSA模块实现跨尺度像素建模,再配合CBAM通道-空间双重注意力,让模型能精准区分目标与背景。而这些能力的发挥,完全依赖于数据集提供的精准轮廓标注。
1.2 YOLO11分割数据集的标准格式
YOLO11采用"图像+文本标注"的轻量格式,无需复杂的二进制文件,每个图像对应一个同名的.txt标注文件,同时可搭配可选的掩码图像用于可视化。核心格式规范如下:
标注文件格式(归一化坐标):每一行代表一个目标实例,格式为 class_id x_center y_center width height segmentation_points...
各参数说明:
-
class_id:目标类别编号(从0开始,如0代表行人、1代表汽车)
-
x_center/y_center:目标轮廓中心点的x/y坐标(相对于图像宽度/高度归一化,范围0-1)
-
width/height:目标边界框的宽/高(同样归一化)
-
segmentation_points:轮廓点坐标对,格式为x1 y1 x2 y2 ... xn yn(所有坐标均归一化,点数越多轮廓越精准)
示例:一张包含"行人"(class_id=0)的图像,其标注可能为: 0 0.45 0.62 0.38 0.75 0.32 0.41 0.35 0.28 0.48 0.22 0.61 0.25 0.65 0.43 0.62 0.68 0.48 0.78 0.35 0.75
二、数据集准备
数据集质量直接决定模型性能,低质量数据(如标注模糊、场景单一)会导致模型泛化能力差。以下流程从数据采集到预处理,全程保障数据质量。
2.1 数据采集
分割任务对数据多样性要求极高,需覆盖实际应用中可能遇到的各种场景。核心原则是"全面性、代表性、无冗余"。
(1)数据来源渠道
-
公开数据集复用:优先使用成熟数据集的标注逻辑,如COCO(通用场景)、Cityscapes(城市场景)、Mask R-CNN官方数据集,可直接提取其中的分割标注并适配YOLO11格式。
-
实地采集:针对特定场景(如工厂巡检、农业病虫害识别),需自行拍摄。建议使用高清相机,按"多角度、多光照、多遮挡"原则采集------例如识别货架商品时,需包含正面、侧面、堆叠、被遮挡等多种状态。
-
视频抽帧:从监控视频中按固定间隔(如30帧抽1帧)提取图像,适合动态场景数据积累。可使用OpenCV实现自动化抽帧,代码示例如下:
python
import os
import cv2
def video_to_frames(video_path, output_dir, interval=30):
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
cap = cv2.VideoCapture(video_path)
frame_count = 0 # 视频总帧数
save_count = 0 # 保存的帧数
while True:
ret, frame = cap.read()
if not ret:
break # 视频读取完毕
# 按间隔保存帧
if frame_count % interval == 0:
save_path = os.path.join(output_dir, f"frame_{save_count:06d}.jpg")
cv2.imwrite(save_path, frame)
save_count += 1
frame_count += 1
cap.release()
print(f"成功提取 {save_count} 帧图像,保存至 {output_dir}")
# 调用示例:从交通视频中抽帧
video_to_frames("traffic.mp4", "./dataset/images/raw", interval=20)合成数据补充:对小目标或稀有场景(如火灾、故障设备),可使用Blender等工具生成3D合成图像及精准掩码,弥补真实数据不足。
(2)数据量与质量要求
数据量需根据类别复杂度调整,参考标准如下:
| 任务复杂度 | 类别数量 | 单类数据量(最低要求) | 图像分辨率建议 |
|---|---|---|---|
| 简单任务(如单一物体分割) | 1-3类 | 500-1000张 | 640×640 |
| 中等任务(如日常场景) | 4-10类 | 300-500张 | 1280×1280 |
| 复杂任务(如工业质检) | 10类以上 | 150-300张 | 1280×1280及以上 |
图像质量需满足:无严重模糊、光照均匀(需包含强光、逆光等极端情况)、背景多样化(避免单一背景导致过拟合)。
2.2 数据标注
分割标注的核心是"轮廓精准",手动标注效率低,需借助专业工具。以下是3款主流工具的对比及实操技巧:
(1)主流标注工具对比
| 工具名称 | 核心优势 | 适用场景 | 格式转换 |
|---|---|---|---|
| LabelMe | 开源免费、轻量、支持多边形标注 | 个人或小团队,中小规模数据集 | 可通过官方脚本导出为YOLO格式 |
| LabelStudio | 支持团队协作、多任务标注(检测+分割) | 企业级团队,大规模数据集 | 自定义导出模板,直接生成YOLO标注 |
| VGG Image Annotator | 浏览器端操作,无需安装,支持像素级掩码 | 快速原型标注,临时需求 | 需手动处理为YOLO格式 |
(2)LabelMe实操:从标注到YOLO格式导出
LabelMe是入门首选,步骤如下:
-
安装:pip install labelme
-
启动标注:命令行输入labelme,选择数据集图像目录
-
标注操作:点击左侧"Create Polygons",沿目标轮廓点击描点,闭合后输入类别名称(如"Car")
-
格式转换:标注完成后生成.json文件,使用以下脚本转换为YOLO格式:
python
import json
import os
import cv2
def labelme2yolo(labelme_dir, output_label_dir, class_mapping):
os.makedirs(output_label_dir, exist_ok=True)
# 遍历所有json标注文件
for json_file in os.listdir(labelme_dir):
if not json_file.endswith(".json"):
continue
# 读取json
with open(os.path.join(labelme_dir, json_file), 'r') as f:
data = json.load(f)
# 获取图像尺寸(用于坐标归一化)
img_h = data["imageHeight"]
img_w = data["imageWidth"]
# 生成标注文件(与图像同名)
label_txt = os.path.join(output_label_dir, json_file.replace(".json", ".txt"))
with open(label_txt, 'w') as f:
for shape in data["shapes"]:
class_name = shape["label"]
if class_name not in class_mapping:
continue # 跳过未定义类别
class_id = class_mapping[class_name]
# 提取轮廓点并归一化
points = shape["points"]
norm_points = []
for (x, y) in points:
norm_x = round(x / img_w, 6)
norm_y = round(y / img_h, 6)
norm_points.extend([norm_x, norm_y])
# 计算边界框(YOLO格式需要)
x_list = [p[0] for p in points]
y_list = [p[1] for p in points]
x_center = round((min(x_list) + max(x_list)) / (2 * img_w), 6)
y_center = round((min(y_list) + max(y_list)) / (2 * img_h), 6)
width = round((max(x_list) - min(x_list)) / img_w, 6)
height = round((max(y_list) - min(y_list)) / img_h, 6)
# 写入标注信息
line = f"{class_id} {x_center} {y_center} {width} {height} " + " ".join(map(str, norm_points)) + "\n"
f.write(line)
# 调用示例:将Car映射为1,Pedestrian映射为0
class_mapping = {"Car": 1, "Pedestrian": 0}
labelme2yolo("./labelme_annotations", "./dataset/labels/train", class_mapping)(3)标注精度控制技巧
-
轮廓描点:曲线部分每5-10像素描一个点,直线部分可适当稀疏,确保轮廓与目标边缘误差不超过2像素。
-
类别一致性:同一类目标名称统一(如避免"行人"和"Pedestrian"混用),可提前制定标注手册。
-
标注审核:随机抽取10%-20%的标注文件,用可视化工具检查------将标注的轮廓绘制在原图上,确认无漏标、错标。

三、训练过程
3.1、导入训练数据
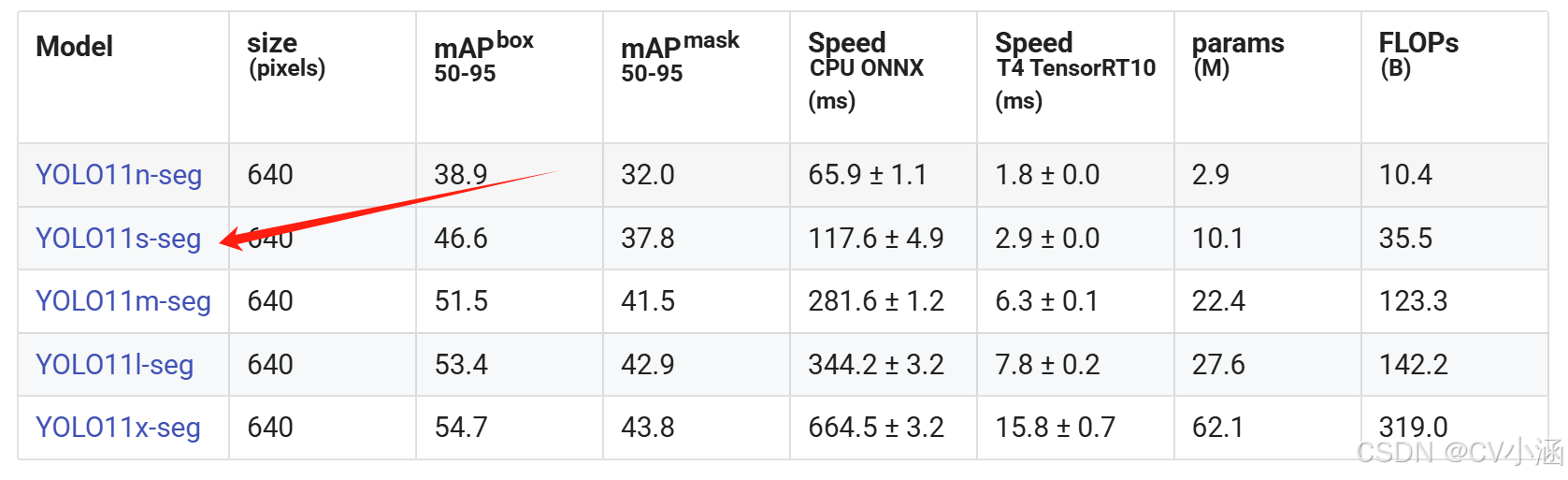
下载YOLO项目压缩包,解压在任意本地workspace文件夹中。
下载YOLO预训练分割模型,导入到ultralytics-main项目根目录下。
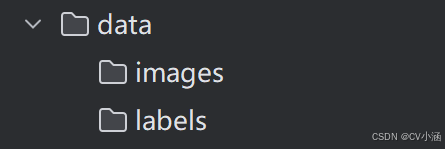
在ultralytics-main 项目根目录下,创建data文件夹,并在data文件夹下创建子文件夹:images、labels, 其中,将YOLO格式的TXT文件 手动导入到Annotations文件夹中,将JPG格式的图像数据导入到images文件夹中。
(注:数据集文件包中train、test、valid三个文件夹的images和labels合并)
data目录结构如下:
3.2、数据划分
首先在ultralytics-main目录下创建一个split.py文件,运行文件之后会在ultralytics-main目录下生成datasets文件夹,具体目录如下:
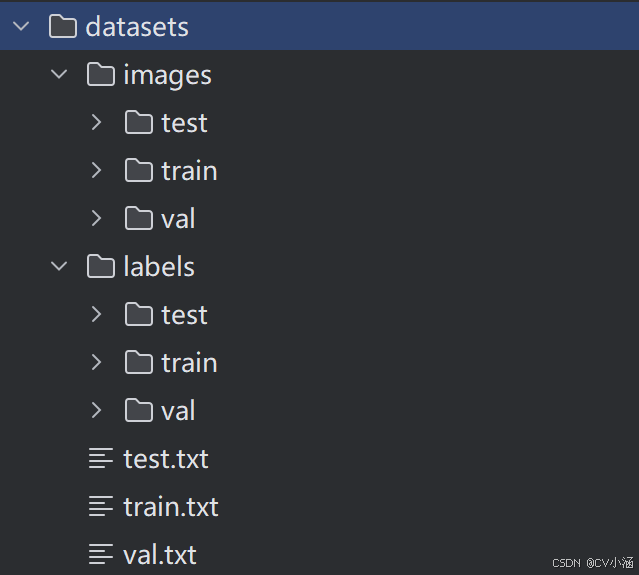
训练集、验证集、测试集已经完成划分。
python
import shutil
import random
import os
# 原始路径
image_original_path = "data/images/"
label_original_path = "data/labels/"
# 数据集划分比例(可以自定义)
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "datasets/images/train/")
train_label_path = os.path.join(cur_path, "datasets/labels/train/")
# 验证集路径
val_image_path = os.path.join(cur_path, "datasets/images/val/")
val_label_path = os.path.join(cur_path, "datasets/labels/val/")
# 测试集路径
test_image_path = os.path.join(cur_path, "datasets/images/test/")
test_label_path = os.path.join(cur_path, "datasets/labels/test/")
# 训练集目录
list_train = os.path.join(cur_path, "datasets/train.txt")
list_val = os.path.join(cur_path, "datasets/val.txt")
list_test = os.path.join(cur_path, "datasets/test.txt")
def del_file(path):
for i in os.listdir(path):
file_data = path + "\\" + i
os.remove(file_data)
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
else:
del_file(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
else:
del_file(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
else:
del_file(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
else:
del_file(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
else:
del_file(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
else:
del_file(test_label_path)
def clearfile():
if os.path.exists(list_train):
os.remove(list_train)
if os.path.exists(list_val):
os.remove(list_val)
if os.path.exists(list_test):
os.remove(list_test)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集:{}, 验证集:{}, 测试集:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.jpg'
srcLabel = label_original_path + name + ".txt"
if i in train:
dst_train_Image = train_image_path + name + '.jpg'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = val_image_path + name + '.jpg'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = test_image_path + name + '.jpg'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
main()3.3、修改数据集配置文件
以道路裂缝为例:
在ultralytics-main目录下创建一个data.yaml文件
python
path: ../datasets/images
train: train # 数据集路径下的train
val: val # 数据集路径下的val
test: test # 数据集路径下的test
# 标签个数
nc: 3
# Classes标签名称
names: ['Alligator_crack', 'Longitudinal_crack', 'Transverse_crack']3.4、执行命令
在ultralytics-main目录下创建一个train.py文件,运行
python
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO("yolo11s-seg.pt")
model.train(data=r'data.yaml',
imgsz=640,
epochs=100,
batch=16,
workers=0,
device='0'
)也可以在终端执行下述命令:
bash
yolo segment train data=data.yaml model=yolo11s-seg.pt epochs=200 imgsz=640 batch=16 workers=0 device=0