一、下载模型仓库
bash
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.gitgithub不太稳定,可能连不上:

一般过一会再重试即可。
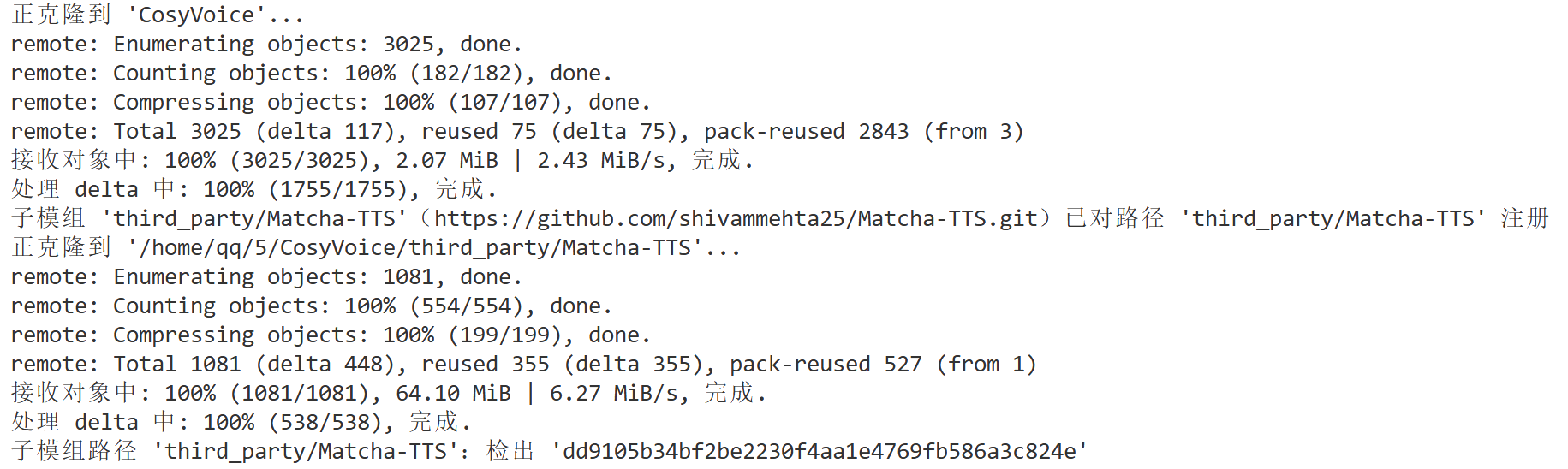
至此,该仓库就下载到当前路径下了:

二、下载模型权重
我是在魔塔社区下的CosyVoice2-0.5B(建议下载这个,因为后面的代码也是针对这个)
当然,也可以下载其他版本的:CosyVoice-300M、CosyVoice-300M-SFT、CosyVoice-300M-Instruct、CosyVoice-ttsfrd。
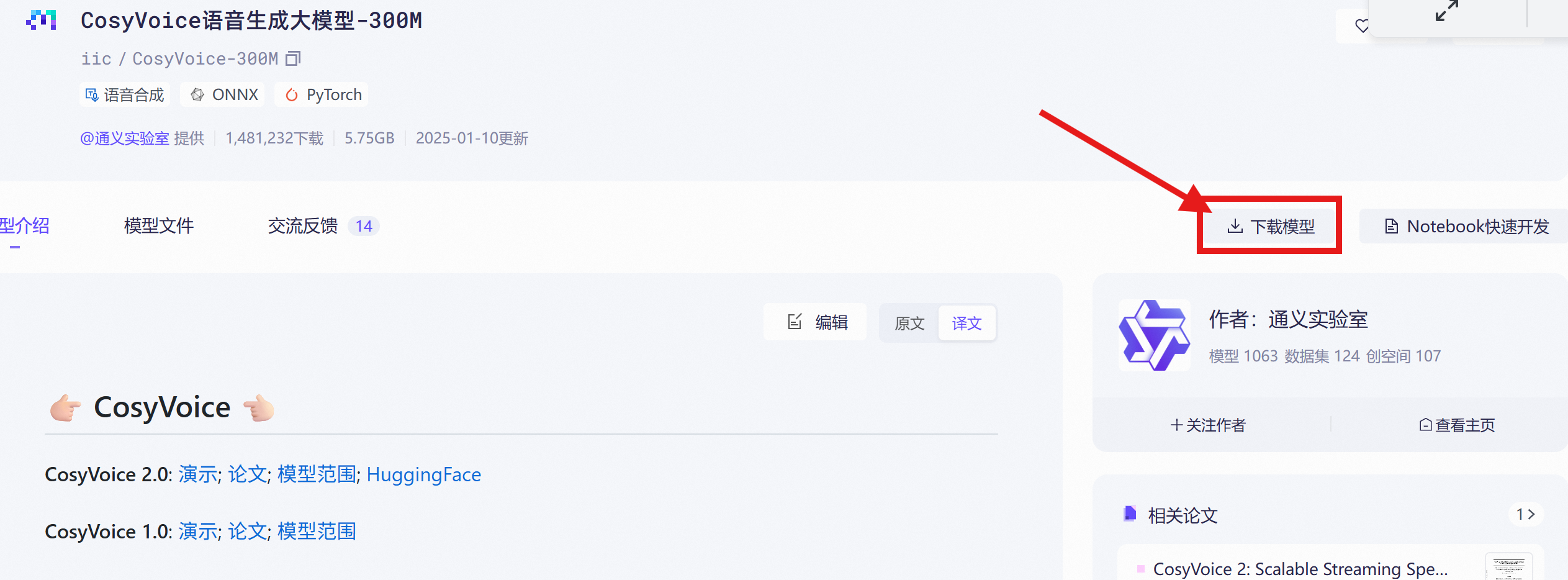
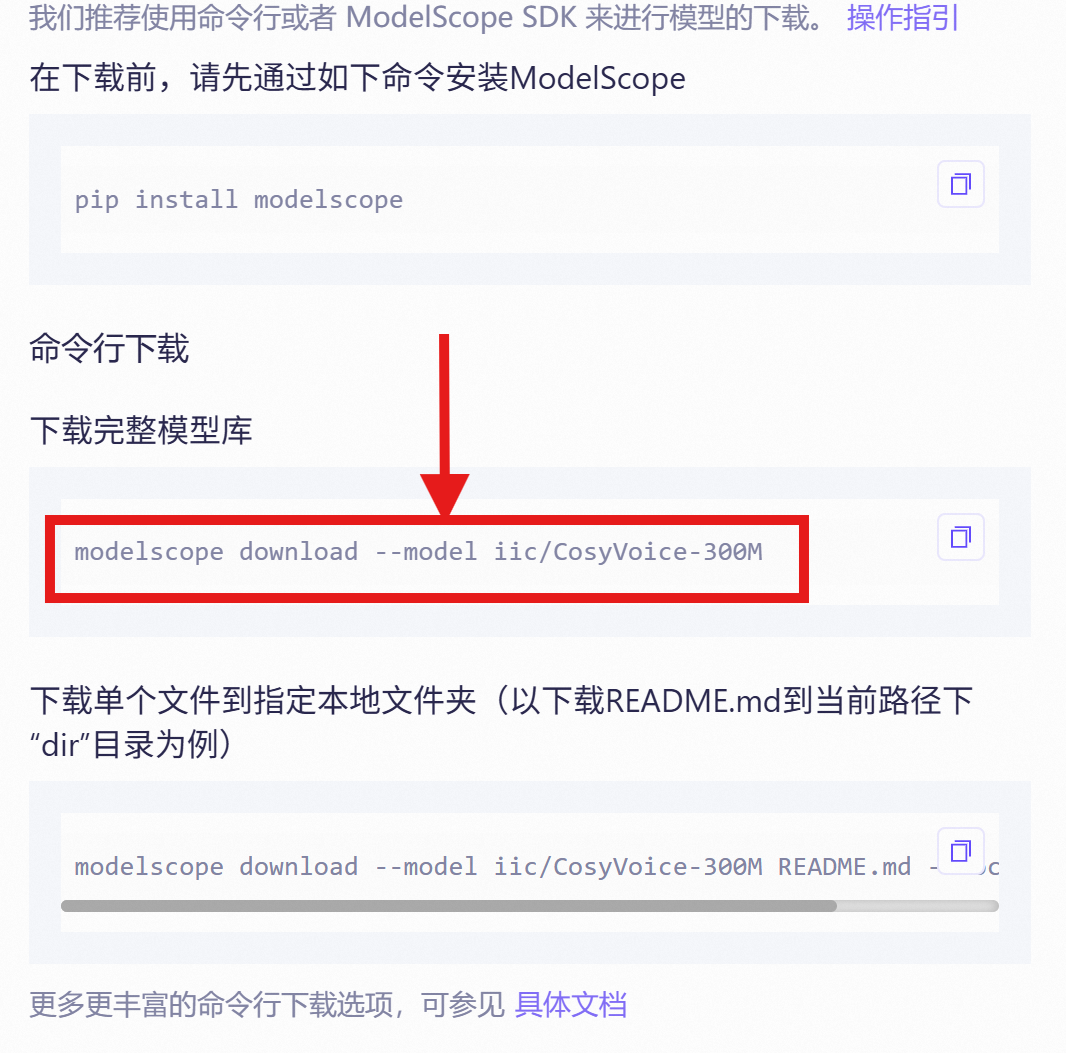
下载指令为
bash
modelscope download --model iic/CosyVoice2-0.5B这个指令是在上面的
魔塔社区官网获取的
下载完成。
注意圈出来的是默认下载路径(如果你下载的是CosyVoice2-0.5B,那么路径就是相应的CosyVoice2-0.5B)
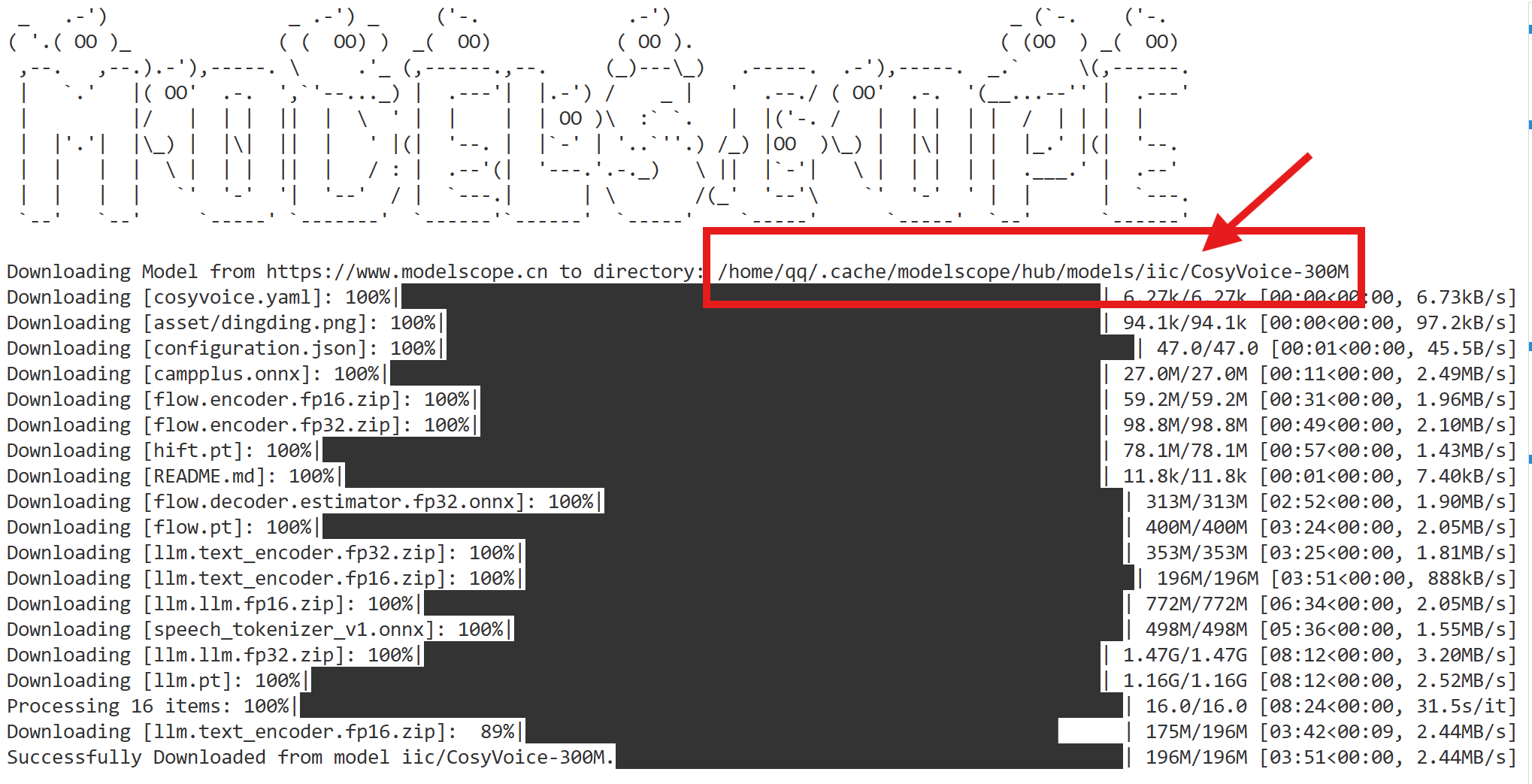
现在,到这个路径里,把刚下载好的模型移动到我们第一步下载的模型仓库CosyVoice路径下
也就是说,最终的路径应该为
CosyVoice/ # 模型仓库CosyVoice 文件夹
├── CosyVoice2-0.5B/ # 模型文件夹(你手动把它移动过来的)
├── ... # 模型仓库CosyVoice的其他文件
三、安装依赖包
进入模型仓库目录CosyVoice下,执行下面的指令
bash
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com漫长的等待......
四、使用模型
在当前仓库下,创建一个use.py文件。
新建一个文件夹output,以后生成的音频,都输出到这个文件夹。
CosyVoice/
├── CosyVoice2-0.5B/ # 模型文件夹(你手动把它移动过来的)
├── output/ # 你刚才创建的output文件夹(存放生成的音频)
├── use.py #你刚创建的
├── ... # 模型仓库CosyVoice的其他文件
下面展示多种玩法:
一、使用预训练的音色
python
import sys
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice2('CosyVoice2-0.5B', load_jit=False, load_trt=False, load_vllm=False, fp16=False)
# 上面第一个参数,是你下载好并且移动后的模型路径
# 因为我们现在在CosyVoice仓库下,而且刚就把模型移动到这里了,所以我们就在这里和模型同级,所以直接写模型文件夹名字即可
sentence = "你们不要再打了啦,这样打不死的"
for i, j in enumerate(cosyvoice.inference_zero_shot(sentence, '', '', zero_shot_spk_id='my_zero_shot_spk', stream=False)):
torchaudio.save('output/zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)跑起来时,会出现很多的下载信息,是正常的:
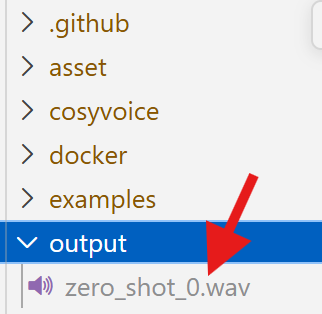
生成的音频在output文件夹里了(就是你刚才创建的文件夹)
二、音色克隆
录音,记得把后缀设为.wav,并且放到我们当前模型仓库文件夹下

假如我录音说的是"我是小猪佩奇",那么对应下面的代码中,也要写"我是小猪佩奇"
然后,你想让模型说的话,作为to_word
python
import sys
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice2('CosyVoice2-0.5B', load_jit=False, load_trt=False, load_vllm=False, fp16=False)
my_voice = load_wav('output/1.wav', 16000) # 第一个参数是你的录音文件,第二个是随机数
my_word = "我是小猪佩奇"
to_word = "这是我弟弟乔治"
for i, j in enumerate(cosyvoice.inference_zero_shot(to_word, my_word, my_voice, stream=False)):
torchaudio.save('output/zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)三、声音元素
可以添加 笑声laughter 和 emm......en,更自然
具体参考当前仓库下的cosyvoice/tokenizer/tokenizer.py中定义的声音元素
python
import sys
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice2('CosyVoice2-0.5B', load_jit=False, load_trt=False, load_vllm=False, fp16=False)
my_voice = load_wav('1.wav', 16000)
my_word = "我是小猪佩奇"
to_word = "这是我弟弟[en]乔治[laughter]"
for i, j in enumerate(cosyvoice.inference_cross_lingual(to_word, my_voice, stream=False)):
torchaudio.save('output/element{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)声音元素有:
python
LANGUAGES = {
"en": "english",
"zh": "chinese",
"de": "german",
"es": "spanish",
"ru": "russian",
"ko": "korean",
"fr": "french",
"ja": "japanese",
"pt": "portuguese",
"tr": "turkish",
"pl": "polish",
"ca": "catalan",
"nl": "dutch",
"ar": "arabic",
"sv": "swedish",
"it": "italian",
"id": "indonesian",
"hi": "hindi",
"fi": "finnish",
"vi": "vietnamese",
"he": "hebrew",
"uk": "ukrainian",
"el": "greek",
"ms": "malay",
"cs": "czech",
"ro": "romanian",
"da": "danish",
"hu": "hungarian",
"ta": "tamil",
"no": "norwegian",
"th": "thai",
"ur": "urdu",
"hr": "croatian",
"bg": "bulgarian",
"lt": "lithuanian",
"la": "latin",
"mi": "maori",
"ml": "malayalam",
"cy": "welsh",
"sk": "slovak",
"te": "telugu",
"fa": "persian",
"lv": "latvian",
"bn": "bengali",
"sr": "serbian",
"az": "azerbaijani",
"sl": "slovenian",
"kn": "kannada",
"et": "estonian",
"mk": "macedonian",
"br": "breton",
"eu": "basque",
"is": "icelandic",
"hy": "armenian",
"ne": "nepali",
"mn": "mongolian",
"bs": "bosnian",
"kk": "kazakh",
"sq": "albanian",
"sw": "swahili",
"gl": "galician",
"mr": "marathi",
"pa": "punjabi",
"si": "sinhala",
"km": "khmer",
"sn": "shona",
"yo": "yoruba",
"so": "somali",
"af": "afrikaans",
"oc": "occitan",
"ka": "georgian",
"be": "belarusian",
"tg": "tajik",
"sd": "sindhi",
"gu": "gujarati",
"am": "amharic",
"yi": "yiddish",
"lo": "lao",
"uz": "uzbek",
"fo": "faroese",
"ht": "haitian creole",
"ps": "pashto",
"tk": "turkmen",
"nn": "nynorsk",
"mt": "maltese",
"sa": "sanskrit",
"lb": "luxembourgish",
"my": "myanmar",
"bo": "tibetan",
"tl": "tagalog",
"mg": "malagasy",
"as": "assamese",
"tt": "tatar",
"haw": "hawaiian",
"ln": "lingala",
"ha": "hausa",
"ba": "bashkir",
"jw": "javanese",
"su": "sundanese",
"yue": "cantonese",
"minnan": "minnan",
"wuyu": "wuyu",
"dialect": "dialect",
"zh/en": "zh/en",
"en/zh": "en/zh",
}四、特制口音
如四川话、广东话(会自动生成粤语)
python
import sys
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice2('CosyVoice2-0.5B', load_jit=False, load_trt=False, load_vllm=False, fp16=False)
prompt_speech_16k = load_wav('./asset/zero_shot_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_instruct2('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '用广东话说这句话', prompt_speech_16k, stream=False)):
torchaudio.save('fangyan_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)五、官方代码
python
import sys
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice2('voice_model/CosyVoice2-0.5B', load_jit=False, load_trt=False, load_vllm=False, fp16=False)
# NOTE if you want to reproduce the results on https://funaudiollm.github.io/cosyvoice2 , please add text_frontend=False during inference
# zero_shot usage
prompt_speech_16k = load_wav('./asset/zero_shot_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)
# save zero_shot spk for future usage
assert cosyvoice.add_zero_shot_spk('希望你以后能够做的比我还好呦。', prompt_speech_16k, 'my_zero_shot_spk') is True
for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '', '', zero_shot_spk_id='my_zero_shot_spk', stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)
cosyvoice.save_spkinfo()
# fine grained control, for supported control, check cosyvoice/tokenizer/tokenizer.py#L248
for i, j in enumerate(cosyvoice.inference_cross_lingual('在他讲述那个荒诞故事的过程中,他突然[laughter]停下来,因为他自己也被逗笑了[laughter]。', prompt_speech_16k, stream=False)):
torchaudio.save('fine_grained_control_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)
# instruct usage
for i, j in enumerate(cosyvoice.inference_instruct2('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '用四川话说这句话', prompt_speech_16k, stream=False)):
torchaudio.save('instruct_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)
# bistream usage, you can use generator as input, this is useful when using text llm model as input
# NOTE you should still have some basic sentence split logic because llm can not handle arbitrary sentence length
def text_generator():
yield '收到好友从远方寄来的生日礼物,'
yield '那份意外的惊喜与深深的祝福'
yield '让我心中充满了甜蜜的快乐,'
yield '笑容如花儿般绽放。'
for i, j in enumerate(cosyvoice.inference_zero_shot(text_generator(), '希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)