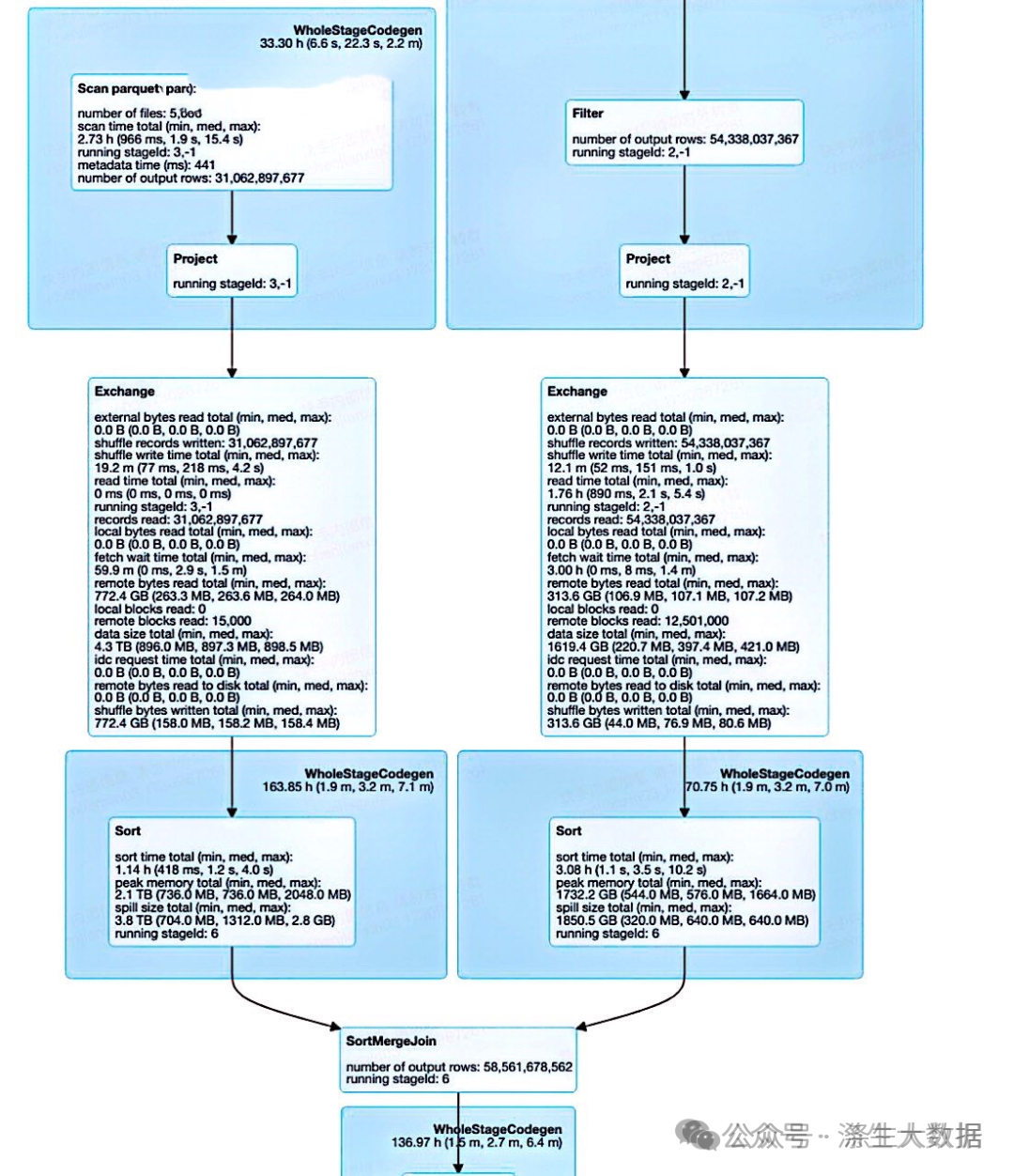
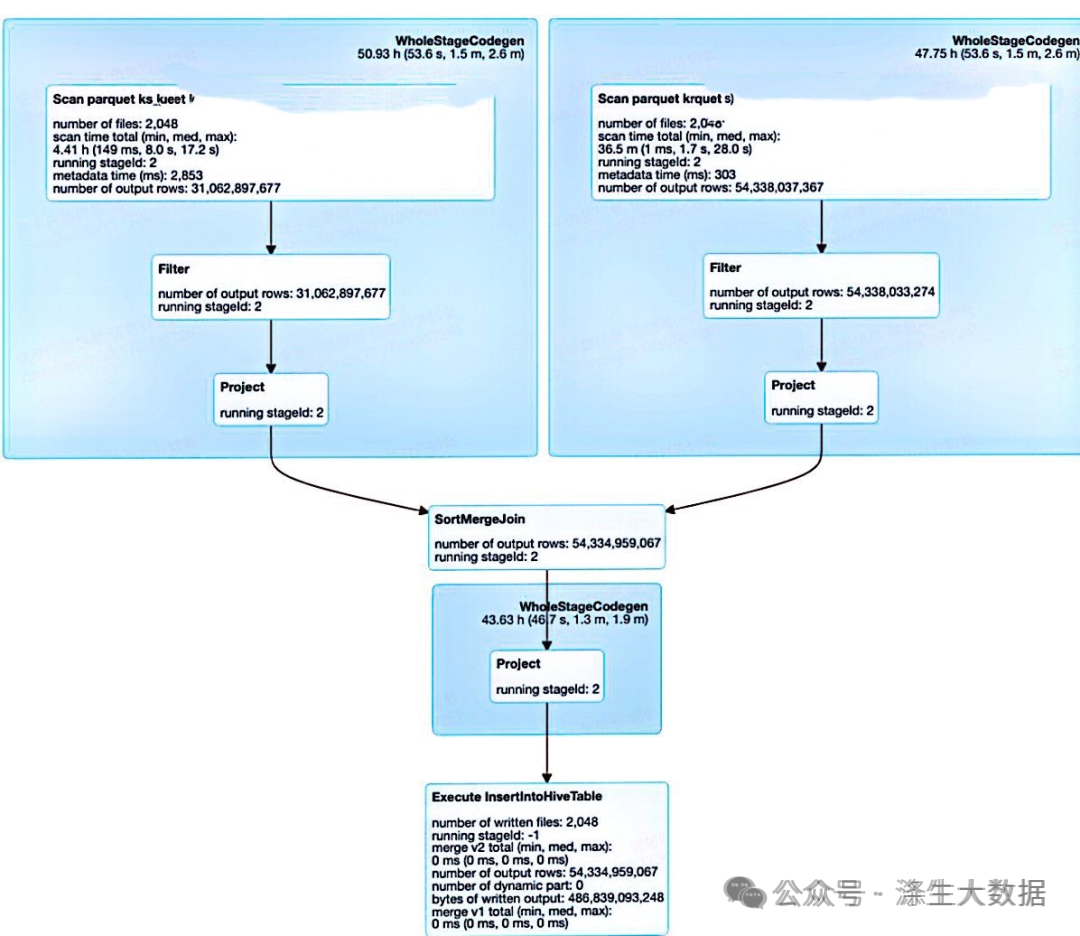
技术原理
今年校招面试spark的分桶表这块问的比较多一些,今天借此给小伙伴搞个案例讲讲哈!
分桶本质上是对文件的划分,其执行逻辑是对分桶key的hash值对桶个数取模,在大表join场景的主要优化逻辑在于通过预先设置分桶+排序,其执行效率得以提高有两个重要原因:避免走Shuffle以及不用在内存中保存Hash数据结构。
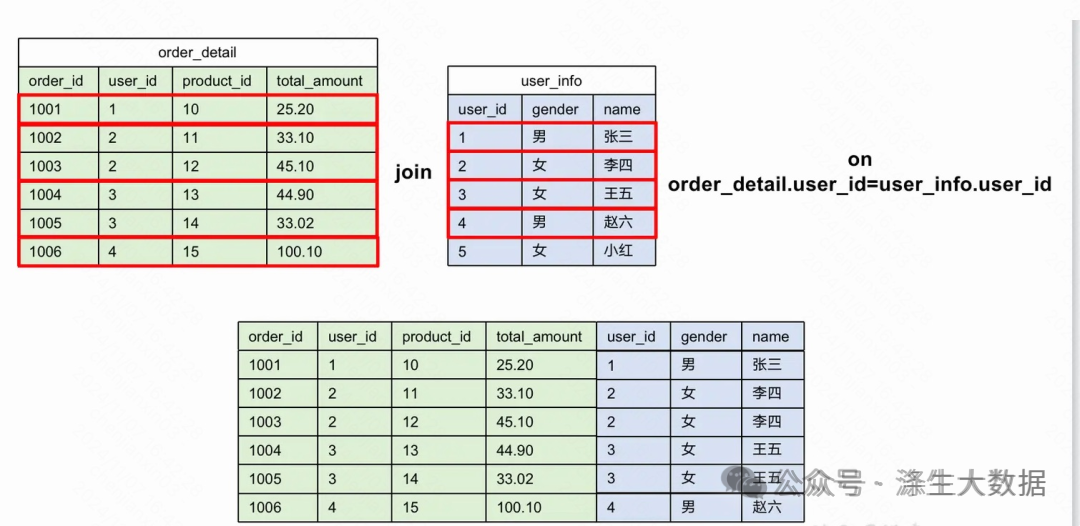
具体而言,可以参见下面实践指南,对于大表与大表JOIN,不管是不是分桶表,spark引擎通常都会走SMJ,对于非分桶表需要对关联字段进行hash(Exchange流程)和排序(Sort流程),这两步均比较耗时,但分桶表由于预先进行了这个操作,下游JOIN时会省略这两个步骤。
实践指南
-
本次测试的数据规模较大,两表数据条数均在百亿级别,数据量小的话请谨慎
-
分桶个数的设置平台最大设置2048个,并且必须是2的倍数,通常建议每256M一个桶
-
两个分桶表的桶必须成倍数关系,因为这样join的时候才能快速匹配
-
Bucket Join Key不支持字段别名,某些情况下会导致执行计划解析失败(经测试,会都走SMJ,无法利用好已经分桶和排序的特性)
结论
对于大表与大表JOIN,默认都会走SMJ,设置分桶表可以减少下游计算的资源,计算时间相比于非分桶表JOIN能节省大约39%。
环境准备
分桶表参数:两张表分桶均为2048个。单表的行数均在百亿级别。
运行环境参数:资源充足的情况下进行的测试。
分桶表创建
分桶表一:
sql
create table if not exists `table1` (
order_id BIGINT,
to_type STRING,
to_id BIGINT,
amount BIGINT,
platform_commission_amount BIGINT,
charge_type STRING,
official_account STRING,
pau_amt BIGINT
)
partitioned by (`p_date` STRING COMMENT '分区日期,yyyyMMdd')
CLUSTERED BY (order_id) SORTED BY (order_id) INTO 2048 BUCKETS
STORED AS parquet
;分桶表二:
sql
CREATE TABLE table2 (
order_id BIGINT,
type1 BIGINT,
type BIGINT,
id BIGINT,
test1_type STRING,
test2_source BIGINT
)
partitioned by (`p_date` STRING COMMENT '分区日期,yyyyMMdd')
CLUSTERED BY (order_id) SORTED BY (order_id) INTO 2048 BUCKETS
STORED AS parquet;Join测试
sql
set spark.sql.sources.bucket.generate.enabled=true;
insert overwrite table `table2` partition (p_date='20241030')
SELECT
t1.order_id,
type1 ,
type ,
id ,
test1_type ,
test2_source
FROM
table3 t1
join table4 t2 -- table3和 table4是非分桶表,结构和数据量级和table1和 table2一致
on t1.p_date = '20241029' and t2.p_date = '20241029'
and t1.order_id=cast(t2.settlement_unit_value as bigint)
;
insert overwrite table `table2` partition (p_date='20241031')
SELECT
t1.order_id,
type1 ,
type ,
id ,
test1_type ,
test2_source
FROM
table1 t1
join table2 t2
on t1.p_date = '20241029' and t2.p_date = '20241029'
and t1.order_id=t2.order_id测试结果:
非分桶表:1901 seconds,分桶表:1105 seconds,时间缩短41.8%。
Left Join 测试
sql
set spark.sql.sources.bucket.generate.enabled=true;
insert overwrite table `table2` partition (p_date='20241030')
SELECT
t1.order_id,
type1 ,
type ,
id ,
test1_type ,
test2_source
FROM
table3 t1
left join table4 t2 -- table3和 table4是非分桶表,结构和数据量级和table1和 table2一致
on t1.p_date = '20241029' and t2.p_date = '20241029'
and t1.order_id=cast(t2.settlement_unit_value as bigint)
;
insert overwrite table `table2` partition (p_date='20241031')
SELECT
t1.order_id,
type1 ,
type ,
id ,
test1_type ,
test2_source
FROM
table1 t1
left join table2 t2
on t1.p_date = '20241029' and t2.p_date = '20241029'
and t1.order_id=t2.order_id测试结果:
非分桶表:1541.296 seconds,分桶表:932.977 seconds,时间缩短39%。
非插入测试
sql
set spark.sql.sources.bucket.generate.enabled=true;
SELECT
t1.order_id,
type1 ,
type ,
id ,
test1_type ,
test2_source
FROM
table3 t1
left join table4 t2 -- table3和 table4是非分桶表,结构和数据量级和table1和 table2一致
on t1.p_date = '20241029' and t2.p_date = '20241029'
and t1.order_id=cast(t2.settlement_unit_value as bigint)
;
SELECT
t1.order_id,
type1 ,
type ,
id ,
test1_type ,
test2_source
FROM
table1 t1
left join table2 t2
on t1.p_date = '20241029' and t2.p_date = '20241029'
and t1.order_id=t2.order_id测试结果:
非分桶表:1021.062 seconds,分桶表:633.202 seconds,时间缩短38%。
DAG图对比